Para que serve:
O objetivo do artigo é divulgar as principais mudanças realizadas na API JPA 2.0 focando, principalmente, nos problemas encontrados pelos desenvolvedores que usaram ou tentaram usar a versăo 1.0 da API.
Em que situaçăo o tema útil:
O tema é relevante tanto para usuários da API JPA 1.0 quanto para quem pretende usar um framework de persistęncia de dados em suas aplicaçőes. Para quem já usa JPA, a versăo 2.0 oferece recursos que aumentam muito a flexibilidade da modelagem objeto-relacional, valendo realmente a pena a migraçăo para essa versăo. Para quem deseja optar por um framework, a JPA 2.0 se apresenta como uma API madura que segue o rigor das especificaçőes da plataforma Java e atende a maioria das necessidades de persistęncia dos sistemas novos e legados.
Desde seu lançamento em 2006, a API de persistęncia da plataforma Java – JPA (Java Persistence API) – sempre recebeu diversas críticas sobre as capacidades de mapeamento objeto-relacional oferecidas pela API em comparaçăo com o poder dos frameworks de persistęncia já conhecidos do mercado. Apesar de ter tido boa aceitaçăo (exatamente por ser um dos padrőes da plataforma Java), usuários de JPA tiveram que recorrer muitas vezes aos recursos particulares dos frameworks para alcançar os resultados esperados, especialmente no mapeamento de objetos para sistemas legados. Para eliminar de vez tais limitaçőes, em dezembro de 2009 foi lançada a JPA 2.0 que trouxe inúmeros novos recursos para atender a maioria das necessidades de mapeamento objeto-relacional dos sistemas. Neste artigo conheceremos as principais mudanças tanto nos recursos de mapeamento, quanto nas novas APIs e na linguagem de consulta JPQL.
O lançamento da JPA – Java Persistence API (versăo 1.0), em Maio de 2006, representou um passo importante da plataforma Java em relaçăo ŕ persistęncia de dados (veja o quadro “JPA 1.0”). A API JPA é utilizada nas aplicaçőes Java para permitir a gravaçăo/leitura de objetos em bancos de dados relacionais de forma transparente. Essa técnica é conhecida como ORM (Object Relational Mapping) e já era utilizada por frameworks de persistęncia proprietários como Hibernate, TopLink, Kodo, entre outros.
Se compararmos o tempo de existęncia dos frameworks de persistęncia com a JPA, vamos perceber que essa API demorou para ser criada na plataforma Java. Mas essa demora acabou por trazer alguns benefícios, entre eles, a capacidade de utilizarmos implementaçőes de diferentes fornecedores, năo ficando presos a um framework em particular, e a flexibilidade de utilizarmos esses recursos de persistęncia tanto em aplicaçőesque rodam dentro de servidores quanto em aplicaçőes stand-alone.
Desde seu lançamento, muitas empresas, com visăo de futuro, foram motivadas a migrar suas aplicaçőes para JPA e acabaram enfrentando alguns problemas. Por ser a primeira versăo, o principal objetivo da especificaçăo de JPA foi o de disponibilizar os recursos básicos necessários para a persistęncia de dados. O resultado foi que cerca de 10 a 20% dos recursos dos frameworks já existentes năo foram inseridos na versăo 1.0. Isso obrigou as pessoas a utilizarem a API JPA combinada com outros frameworks de persistęncia que já possuíam recursos diferenciados para o mapeamento de objetos, principalmente para bancos de dados legados.
Na versăo 2.0, lançada em Dezembro de 2009 juntamente com o Java EE 6, a API JPA surge muito mais madura. Além de reduzir as restriçőes para oferecer maior flexibilidade no desenvolvimento do modelo de objetos, a API incorporou a maioria dos recursos existentes nos frameworks proprietários que faziam falta na versăo 1.0, sendo que grande parte das melhorias foram feitas para atender ŕs necessidades de mapeamento dos sistemas legados. Tais mudanças objetivaram principalmente a possibilidade das aplicaçőes Java se tornarem mais independentes de frameworks proprietários.
JPA 2.0 foi especificada pela JSR 317 do Java EE 6 e sua implementaçăo de referęncia é o EclipseLink, disponibilizado no servidor GlassFish V3 (veja o quadro “TopLink x EclipseLink”). Por ser considerada uma das especificaçőes mais maduras do Java EE 6, seus recursos já podem ser utilizados nas aplicaçőes Java, desde que a implementaçăo JPA utilizada já suporte essa nova especificaçăo.
Neste artigo vamos abordar as principais mudanças na API JPA 2.0, em particular, as melhorias realizadas no modelo de mapeamento objeto-relacional, os novos recursos adicionados ŕ JPA Query Language e as APIs de MetaModel e Criteria.
JPA 1.0
JPA é utilizado nas aplicaçőes Java para permitir o armazenamento de dados em bancos de dados relacionais sem a necessidade de escrever código JDBC (Java Database Connectivity), utilizar componentes EJB Entity Beans ou ficar preso a um framework de persistęncia proprietário
Por meio de JPA, o programador delega as operaçőes de manipulaçăo de tabelas para um framework de persistęncia que implementa a API JPA.
Utilizando recursos de ORM (Object Relational Mapping), o programador cria mapeamentos das classes Java e seus relacionamentos para as tabelas do banco de dados. Esses mapeamentos permitem que um framework, que suporte JPA (como Hibernate, Oracle TopLink, Kodo, OpenJPA, entre outros), faça as devidas inserçőes, buscas, exclusőes e alteraçőes nos dados da aplicaçăo nas tabelas do banco de dados, quando for solicitado. Dessa forma, o código da aplicaçăo fica independente de frameworks de persistęncia, pois todo o código utilizado para manipular o banco de dados passa a ser da API JPA.
A grande vantagem dessa API é que ela permite a troca do framework de persistęncia, e consequentemente do sistema de gerenciamento de banco de dados (SGBD), de forma transparente para a aplicaçăo, ou seja, podemos optar por soluçőes de implementaçăo diferentes de acordo com o perfil do projeto ou do banco de dados.
TopLink x EclipseLink
Para o JPA 1.0, a Oracle oferece o Oracle TopLink (versăo comercial), e o Oracle TopLink Essentials, que é a implementaçăo de referęncia da JPA 1.0.
O EclipseLink corresponde ŕ parte “open source” do código desenvolvido para a versăo 11g do Oracle TopLink. Isso significa que o EclipseLink substituiu o produto “Oracle TopLink Essentials” e também se tornou a implementaçăo de referęncia da versăo JPA 2.0, sendo distribuído juntamente com o servidor de aplicaçőes GlassFish V3.
Aos poucos todos os recursos desenvolvidos para o Oracle TopLink estăo sendo convertidos para o EclipseLink.
Sem dúvida alguma, as questőes relacionadas ao mapeamento objeto-relacional foram as que mais sofreram melhorias na versăo 2.0 da JPA.
Além de melhorar alguns mapeamentos que eram limitados na JPA 1.0, a nova versăo criou outros recursos de mapeamento com base no que já existia nos frameworks de persistęncia proprietários como Hibernate, visando atender ŕs necessidades da maioria dos usuários.
A seguir apresentamos alguns dos principais recursos de mapeamento OR que foram disponibilizados na JPA 2.0.
Na JPA 1.0, quando uma entidade tem um relacionamento 1:N ou N:N com outras entidades, podemos usar coleçőes para representar o relacionamento e mapear essas coleçőes para o banco de dados usando as anotaçőes @ManyToMany ou @OneToMany.
No entanto, além das coleçőes que representam relacionamentos entre as entidades, é possível que uma classe também possua coleçőes de tipos básicos, como coleçőes de String, Integer, Float, etc., e esse tipo de coleçăo năo pode ser mapeado com JPA 1.0.
Com JPA 2.0, podemos fazer o mapeamento de coleçőes de tipos básicos usando as anotaçőes @ElementCollection e @CollectionTable.
A anotaçăo @ElementCollection permite definir que os elementos da coleçăo de tipos básicos devem ser armazenados numa tabela ŕ parte da tabela da entidade, por exemplo:
@Entity @Table(name=“pessoas”)
class Pessoa{
@Id private long id;
private String nome;
@ElementCollection
private Collection<String> apelidos;
…
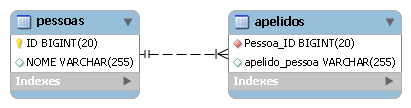
}Nesse exemplo, os apelidos de uma pessoa devem ser armazenados em uma tabela separada da tabela de pessoas. Essa tabela extra armazena uma String para o apelido e uma chave indicando de qual pessoa é aquele apelido. Como JPA trabalha com configuraçőes default, o nome dessa tabela (Pessoa_apelidos) é definido automaticamente em funçăo do nome da entidade Pessoa e do atributo apelidos. Mas se quisermos controlar o nome da tabela e o nome da coluna que vai armazenar o apelido, podemos usar as anotaçőes @CollectionTable e @Column, como no exemplo a seguir:
@Entity @Table(name=“pessoas”)
class Pessoa{
@Id private long id;
private String nome;
@ElementCollection
@CollectionTable(name=“apelidos”)
@Column(name=“apelido_pessoa”)
Collection<String> apelidos;
}Agora o nome da tabela onde os apelidos da pessoa săo armazenados passa a ser “apelidos”, e a coluna do apelido nessa tabela passa a se chamar “apelido_pessoa”. As tabelas utilizadas nesse mapeamento podem ser vistas na Figura 1.
Além das coleçőes de tipos básicos, JPA 2.0 também suporta coleçőes de tipos embeddable. Tipos embeddable săo classes com atributos que precisam ser persistidos mas năo săo consideradas entidades, pois seus objetos dependem de uma outra entidade, ou seja, năo fazem sentido sozinhos.
Com JPA 1.0, podemos mapear um tipo embeddable de forma que os atributos dessa classe sejam armazenados na mesma tabela da entidade que o utiliza. Por exemplo:
@Embeddable
public class Endereco {
private String rua;
private int numero;
...
}
@Entity @Table(name=“clientes”)
public class Cliente {
@Id private long id;
private String nome;
@Embedded
private Endereco endereco;
…
}Nesse mapeamento, a tabela “clientes” deve possuir colunas para armazenar o id e o nome do cliente, e também a rua e o numero do endereço. Ou seja, além dos dados da entidade Cliente, os dados do embeddable Endereco também săo armazenados na tabela “clientes”.
Com JPA 2.0, podemos criar coleçőes de tipos embeddable e mapeá-las usando a anotaçăo @ElementCollection, assim como fazemos com as coleçőes de tipos básicos. O exemplo a seguir ilustra esse mapeamento:
@Entity @Table(name = “clientes”)
public class Cliente {
@Id private long id;
private String nome;
@ElementCollection
@CollectionTable(name=“cliente_enderecos”)
private Collection<Endereco> endereco;
…
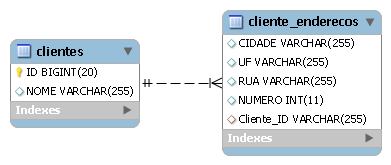
}Assim, a tabela “clientes” guarda apenas o id e nome do cliente, enquanto a tabela “cliente_enderecos” guarda rua, numero e a chave para o cliente. Veja na Figura 2 as tabelas necessárias para esse mapeamento.
Para customizar também o nome das colunas da tabela da coleçăo, podemos usar as anotaçőes @AttributeOverrides e @AttributeOverride. O trecho de código da Listagem 1 define o nome das colunas a serem utilizadas para os atributos rua e numero:
Listagem 1. Mapeamento da coleçăo de embeddable com customizaçăo nos nomes das colunas.
@ElementCollection @CollectionTable(name = “cliente_enderecos”)
@AttributeOverrides(value = {
@AttributeOverride(name = “rua”, column = @Column(name = “END_RUA”)),
@AttributeOverride(name = “numero”, column = @Column(name = “END_NUMERO”))
})
private Collection<Endereco> enderecos; Para representar o relacionamento 1:N ou N:M, podemos definir os atributos com os tipos Collection, Set, List ou Map. A escolha do tipo de coleçăo depende das características individuais de cada tipo e das necessidades do projeto em questăo. Por exemplo, se usarmos uma coleçăo de tipo Set, a característica mais evidente é que ela năo aceita elementos duplicados. Já a coleçăo List trabalha com o conceito de índices, enquanto Map usa pares de chave e valor.
No caso especial do tipo List, até a JPA 1.0, podíamos usar a anotaçăo @OrderBy(“nomeAtributo ASC/DESC”) para definir a ordem que os objetos armazenados deveriam ser apresentados na coleçăo. Ao usar essa anotaçăo, a JPA se encarrega de ordenar os elementos na coleçăo List quando os objetos săo recuperados do banco de dados para a memória. No entanto, se reorganizarmos essa ordem, ela năo é persistida para o banco de dados, já que ela é estabelecida em funçăo de atributos da classe associada.
Com JPA 2.0, podemos ordenar uma lista de objetos como quisermos na memória e, depois, persistir essa ordem no banco de dados para futuras recuperaçőes. Para isso, podemos usar a anotaçăo @OrderColumn com mapeamentos @OneToMany ou @ManyToMany, da seguinte forma:
@Entity @Table(name = “cursos”)
public class Curso {
@Id private long id;
private String nome;
@OneToMany
@OrderColumn(name=“ordem_matricula”)
List<Matricula> matriculas;...
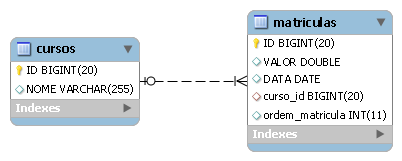
}As tabelas desse mapeamento săo ilustradas na Figura 3. Aqui, a tabela que armazena as matrículas do curso tem uma coluna a mais chamada “ordem_matricula”. Essa coluna armazena a posiçăo (índice) de cada elemento da lista de matrículas. Dessa forma, sempre que recuperarmos as matrículas de um curso, a ordem estabelecida na lista é mantida.
O uso de coleçőes de tipo Map (coleçăo de pares chave-valor) é bastante restrito na JPA 1.0 e, por isso, esse foi um dos recursos de mapeamento que mais foram aprimorados na nova especificaçăo.
Na JPA 1.0, o mapeamento de mapas só é possível se os valores do Map forem entidades e as chaves forem as chaves primárias dos objetos valores.
Na JPA 2.0, os mapas podem ter chaves e valores de tipos básicos, embeddable ou entidades. Para suportar essas alteraçőes, novas anotaçőes foram criadas, tais como:
Quando os valores do Map săo entidades, podemos usar as anotaçőes @ManyToMany ou @OneToMany para mapear o relacionamento. Se os valores săo tipos básicos ou embeddable, devemos usar @ElementCollection, como fazemos com as coleçőes Set e List.
A organizaçăo das tabelas do banco de dados para atender ao mapeamento de coleçőes Map depende diretamente dos tipos das chaves e valores armazenados. Por isso, considerando que há tręs tipos de chaves e tręs tipos de valores (que săo entidades, tipos básicos e tipos embeddable), săo nove combinaçőes possíveis de mapeamento de Map.
Neste artigo, optamos por exemplificar o uso de Map com apenas dois dos casos mais comuns. Para ver outras formas de mapeamento, aconselhamos a leitura da especificaçăo ou do livro referenciado ao final deste artigo.
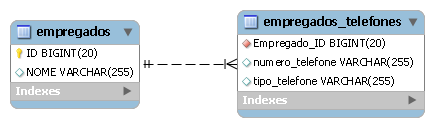
Veja na Listagem 2 um exemplo de mapeamento Map<String, String>. A Figura 4 ilustra as tabelas desse relacionamento.
Listagem 2. Mapeamento de coleçăo Map<String, String>.
@Entity @Table(name=“empregados”)
public class Empregado {
@Id private long id;
String nome;
@ElementCollection
@CollectionTable(name=“empregados_telefones”)
@MapKeyColumn(name=“tipo_telefone”)
@Column(name=“numero_telefone”)
private Map<String, String> numeroTelefones;
...
}Nesse exemplo, como os valores do Map săo de tipo String (tipo básico), mapeamos a coleçăo com @ElementCollection, e usamos @CollectionTable para definir o nome da tabela da coleçăo. Como as chaves do Map também săo de tipo String, usamos a anotaçăo @MapKeyColumn para definir o nome da coluna que vai armazenar a chave. A anotaçăo @Column define o nome da coluna para o valor do Map. Repare nas tabelas que, para esse caso, a chave do Map fica armazenada dentro da tabela da coleçăo definida com a anotaçăo @CollectionTable.
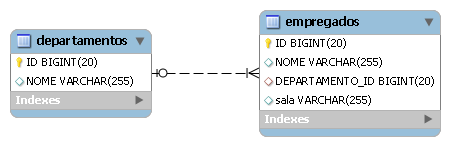
Se mudarmos o tipo de valor do Map, temos um outro caso de mapeamento. O exemplo da Listagem 3 ilustra o mapeamento de um Map<String, Empregado>. As tabelas săo apresentadas na Figura 5.
Listagem 3. Mapeamento de coleçăo Map<String, Empregado>.
@Entity @Table(name=“departamentos”)
class Departamento {
@Id private long id;
private String nome;
@OneToMany(mappedBy=“departamento”)
@MapKeyColumn(name=“sala”)
private Map<String, Empregado> empregados;
...
}
@Entity @Table(name=“empregados”)
public class Empregado {
@Id private long id;
private String nome;
@ManyToOne
private Departamento departamento;
...
}Nesse exemplo, as chaves do Map continuam sendo de tipo básico (String), mas o objeto valor é uma entidade (Empregado). Conforme dissemos anteriormente, o objeto valor define que tipo de anotaçăo podemos utilizar: quando o valor é um tipo básico, mapeamos com @ElementCollection (exemplo anterior); e quando é uma entidade, usamos @OneToMany ou @ManyToMany. Nesse exemplo, temos um relacionamento 1:N porque um departamento tem muitos empregados, por isso, usamos @OneToMany. Chaves de tipos básicos permitem usar a anotaçăo @MapKeyColumn que, nesse caso, é armazenada dentro da tabela dos objetos valores.
Se o nosso modelo de dados tivesse o relacionamento N:M, ou seja, um departamento tem muitos empregados e um empregado pode estar em vários departamentos, o relacionamento com o Map deveria usar @ManyToMany e @JoinColumn para a tabela de junçăo. Nesse caso, o @MapKeyColumn estaria definindo a chave dentro da tabela de junçăo.
Em relacionamentos @OneToMany e @OneToOne trabalhamos com o conceito de objetos pais (aqueles que contęm) e filhos (aqueles que săo contidos). Em muitos casos, os objetos filhos năo podem existir sozinhos e nem serem associados a outros objetos pais. Por exemplo, a avaliaçăo de um aluno năo pode existir sem o aluno e também năo pode ser associada a outro aluno. Isso significa que se o relacionamento entre esses objetos for “quebrado” por algum motivo, por exemplo, uma avaliaçăo é desassociada do aluno, o objeto da avaliaçăo (objeto filho) precisa ser excluído, caso contrário ele se tornará um objeto órfăo.
O suporte de JPA 1.0 para evitar objetos órfăos está limitado ao recurso de cascade: quando o relacionamento suporta CascadeType.REMOVE, ao remover o objeto pai, os objetos filhos também săo excluídos. Mas se quisermos excluir um (ou mais) dos objetivos filhos, temos que “quebrar” o relacionamento e excluir o objeto filho manualmente.
Na JPA 2.0, podemos simplesmente adicionar um atributo orphanRemoval = true nos relacionamentos @OneToMany e @OneToOne quando quisermos que o objeto filho seja automaticamente excluído quando o seu relacionamento com o objeto pai for “quebrado”.
Este recurso também é útil quando removemos o objeto pai. Mesmo quando năo estamos usando CascadeType.REMOVE, a presença do atributo orphanRemoval faz com que as entidades filhas sejam excluídas ao excluir o objeto pai.
Na Listagem 4 ilustramos o relacionamento @OneToMany bidirecional usando o atributo orphanRemoval.
Listagem 4. Mapeamento 1:N com orphanRemoval.
@Entity @Table(name=“funcionarios”)
public class Funcionario {
@Id private long id;
@OneToMany(mappedBy = “funcionario”, cascade = CascadeType.ALL, orphanRemoval = true)
private Collection<Atividade> atividades;…
}
@Entity @Table(name=“atividades”)
public class Atividade {
@Id private long id;
@ManyToOne @JoinColumn(name = “funcionario_id”)
private Funcionario funcionario;
…
}Usando o atributo orphanRemoval, podemos excluir uma atividade do funcionário apenas removendo-a da coleçăo de atividades, ou seja, muito mais simples do que retirar o objeto da coleçăo e ainda ter que excluí-lo manualmente. O trecho de código da Listagem 5 ilustra esse processo (considere que em é um objeto do EntityManager).
Listagem 5. Trecho de código que exclui objeto órfăo automaticamente.
Funcionario f = em.find(Funcionario.class, new Long(1));
Atividade extra = null;
for (Atividade e : f.getAtividades()) {
if (e.getMinutos()==10) extra = e;
}
em.getTransaction().begin();
f.removeAtividade(extra);
em.getTransaction().commit();Na JPA 1.0, os dados da entidade podem ser acessados de duas formas diferentes: via atributos, quando usamos anotaçőes sobre os atributos da entidade; ou via métodos @getters, quando as anotaçőes săo feitas sobre esses métodos. Em tempo de execuçăo, a JPA verifica onde está a anotaçăo da chave primária (no atributo ou método anotado com @Id) e usa essa forma de acesso para os demais atributos da classe. Somente uma das formas de acesso é válida, o que significa que se usarmos acesso via atributo e, para algum dado em particular, fizermos a anotaçăo no método, essa anotaçăo é simplesmente ignorada.
Apesar de ser de pouco conhecimento dos programadores, a performance de acesso aos dados das entidades é melhor quando é feita via atributos ao invés de métodos. Mas eventualmente, precisamos que a JPA acesse os métodos para permitir a realizaçăo de validaçőes ou formataçőes antes de enviar os dados para o banco de dados. Se isso for necessário, devemos usar a forma de acesso via métodos em toda a classe.
Com JPA 2.0, é possível mesclar as duas formas de acesso na mesma entidade, isto é, podemos utilizar anotaçőes em atributos e em métodos de acordo com nossas necessidades.
Para exemplificar, vamos mapear uma classe Pessoa com os atributos nome e id, sendo que o atributo nome deve ser armazenado com caracteres maiúsculos. Para ter melhor performance, vamos optar pelo acesso via atributos, mas como o atributo nome tem uma regra de negócios vinculada, teremos que usar o acesso via método @getter para esse campo, visando garantir que a regra será executada ao salvar os dados no banco de dados.
Para utilizar este recurso de mapeamento devemos realizar tręs passos:
1. Definir junto ŕ entidade qual é o padrăo de acesso para a classe. Se escolhermos atributos, devemos anotar a classe com @Access(AccessType.FIELD), e se escolhermos métodos, a anotaçăo deve ser @Access(AccessType.PROPERTY).
@Entity @Access(AccessType.FIELD)
public class Pessoa { ... }2. Anotar o atributo nome com @Transient para que JPA năo considere esse atributo nas operaçőes de persistęncia, já que optamos pelo acesso via atributos (field) por default.
@Transient private String nome; 3. Anotar o método getNome() com @Access(AccessType.PROPERTY) para que a JPA utilize esse método como mapeamento para a coluna nome nas operaçőes de persistęncia.
@Column(name=“nome”)
@Access(AccessType.PROPERTY)
public String getNome() {
return nome == null ? “” : nome.toUpperCase();
}Assim, JPA utiliza acesso via atributos para os dados da entidade Pessoa, mas usa o método getNome() para a propriedade nome, dando mais flexibilidade ao modelo.
Este recurso pode auxiliar na performance, mas sobretudo nos mapeamentos de classes embutidas que podem ter acessos diferentes do padrăo das classes que as utilizam. O mesmo vale para classes filhas que possuem formas de acesso diferentes das classes măes.
Uma das principais reclamaçőes dos usuários de JPA 1.0 que fizeram mapeamento para banco de dados legado foi o caso dos relacionamentos @OneToMany unidirecional.
Com JPA 1.0, a única forma de mapear esse relacionamento é usando uma tabela de junçăo, mas o comum nos sistemas legados é usar chave estrangeira. Essa deficięncia de JPA leva o programador ŕ necessidade de reorganizar as tabelas (e os dados) para criar a tabela de junçăo exigida no mapeamento, ou de recorrer a algum recurso particular do framework de persistęncia utilizado.
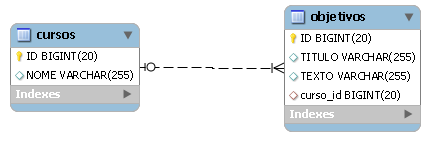
Para eliminar esse problema, JPA 2.0 passou a permitir o relacionamento @OneToMany unidirecional usando chave estrangeira também. No exemplo a seguir, a classe Curso tem um relacionamento 1:N unidirecional com a classe Objetivo, portanto a tabela de objetivos é quem armazena a chave para o curso (sem tabela de junçăo). Podemos fazer esse mapeamento usando @OneToMany na coleçăo de objetivos do curso e @JoinColumn para estabelecer a coluna que irá guardar a chave do curso na tabela de objetivos (ver Listagem 6). As tabelas para esse mapeamento podem ser vistas na Figura 6.
Listagem 6. Mapeamento 1:N unidirecional usando chave estrangeira.
@Entity @Table(name=“objetivos”)
public class Objetivo {
@Id private long id;
private String titulo;
private String texto;
...
}
@Entity @Table(name=“cursos”)
public class Curso {
@Id private long id;
private String nome;
...
@OneToMany @JoinColumn(name=“curso_id”)
Set<Objetivo> objetivos;
}Na mesma linha do problema descrito na seçăo anterior, o mapeamento JPA para bases de dados legadas também apresenta dificuldades com relacionamentos @OneToOne e @ManyToOne. Em geral, esse tipo de relacionamento pode ser resolvido usando apenas chaves estrangeiras, mas há casos nos sistemas legados onde săo utilizadas tabelas de junçăo.
Para contornar esse problema, JPA 2.0 passou a permitir o uso da anotaçăo @JoinTable também em mapeamentos @OneToOne e @ManyToOne unidirecional e bidirecional.
Para fazer consultas com JPA, podemos usar a JPA Query Language (JPQL). Nessa linguagem, as instruçőes de consulta săo escritas de forma muito semelhante ao padrăo SQL (Structured Query Language), incluindo palavras como select, from, where, etc., porém săo baseadas nos conceitos de orientaçăo a objetos. A implementaçăo JPA utilizada transforma essas instruçőes JPQL em instruçőes SQL para que elas possam ser executadas no banco de dados. A vantagem em usar JPQL ao invés de SQL, que também é permitido via JPA, é que evitamos a transiçăo entre objeto e modelo relacional, que é responsabilidade do framework de persistęncia.
Na JPA 2.0, a Query Language foi atualizada para suportar os novos recursos de mapeamento listados anteriormente, oferecendo mais flexibilidade nas consultas e, principalmente, facilitando o trabalho com polimorfismo, que era uma das suas principais deficięncias na versăo 1.0. Detalhes sobre as mudanças mais significativas săo listados a seguir.
Dado um modelo de herança representado por uma classe Treinamento e suas subclasses: Core, HandsOn e Carreira, se quisermos recuperar todos os treinamentos sem especificar seus tipos usando JPA 1.0, podemos utilizar a query:
SELECT t FROM Treinamentos tSe quisermos recuperar somente treinamentos de tipo Core, podemos usar:
SELECT c FROM Core cCom JPA 2.0, podemos realizar consultas especificando um ou mais tipos de entidades usando o operador TYPE na cláusula WHERE. A query a seguir permite recuperar somente objetos dos tipos Core e HandsOn:
SELECT t FROM Treinamentos t WHERE TYPE(t) IN (Core, HandsOn) JPA 2.0 oferece o operador CASE para permitir a inclusăo de lógica condicional ŕ instruçăo de acesso ao banco de dados. Usando esse operador podemos montar consultas e atualizaçőes baseadas em condiçőes.
Reconsiderando a hierarquia de classes Treinamento, Core, HandsOn e Carreira da seçăo anterior, podemos usar o operador CASE para retornar o nome e o tipo do curso com a query apresentada na Listagem 7.
Listagem 7. Exemplo de uso do operador CASE para uma consulta.
SELECT t.nome,
CASE
WHEN TYPE(t) = Core THEN "Curso Core"
WHEN TYPE(t) = HandsOn THEN "Curso Hands-On"
ELSE ‘Nao especificado’
END
FROM Treinamento t; Essa instruçăo fará com que uma lista de treinamentos seja retornada com dois valores: o nome do treinamento, considerando que há um atributo nome na classe Treinamento, e a descriçăo do treinamento, que pode ser “Curso Core”, “Curso Hands-On” ou “Năo especificado”.
Agora, supondo uma classe Funcionario com os atributos nome (String), salario (double) e avaliacao (int), podemos fazer a atualizaçăo nos dados de um funcionário usando o operador CASE conforme o código da Listagem 8.
Listagem 8. Exemplo de uso do operador CASE para uma atualizaçăo.
UPDATE Funcionario f
SET f.salario =
CASE f.avaliacao
WHEN 1 THEN f.salario * 1.05
WHEN 2 THEN f.salario * 1.02
ELSE f.salario * .95
ENDEssa instruçăo permite mudar o salário de cada funcionário de acordo com o valor de suas avaliaçőes: se for 1, o salário é multiplicado por 1.05; se for 2, o salário é multiplicado por 1.02, e para qualquer outro valor, o salário é multiplicado por 0.95.
Com o suporte de JPA 2.0 para a criaçăo de listas ordenadas persistentes usando a anotaçăo @OrderColumn, a JPQL ganhou uma funçăo chamada INDEX que permite identificar o índice de um objeto dentro da coleçăo ordenada. Para entender como essa funçăo pode ser utilizada, vamos analisar o relacionamento entre as classes Curso e Estudante, sendo que o curso possui uma lista ordenada de estudantes que corresponde ŕ lista de espera para o curso (ver Listagem 9).
Listagem 9. Mapeamento de lista ordenada de forma persistente.
@Entity public class Curso {
@Id Integer id;
String nome;
@OrderColumn @ManyToMany List<Estudante> listaEspera;
…
}
@Entity public class Estudante {
@Id Integer id;
String nome;
…
}Para recuperar os nomes dos cinco primeiros estudantes da lista de espera do curso, podemos usar a funçăo INDEX na instruçăo de SELECT, como exibe a Listagem 10.
Listagem 10. Consulta sobre a lista ordenada usando a funçăo INDEX.
SELECT e.nome
FROM Curso c JOIN c.listaEspera e
WHERE c.nome = "Matemática"
AND INDEX(e) < 5Assim como no caso das listas ordenadas, a JPQL foi ampliada para fornecer suporte ao trabalho com coleçőes do tipo Map com a criaçăo dos operadores KEY, VALUE e ENTRY.
Para exemplificar, reveja o mapeamento da classe Empregado com um Map de telefones apresentado na seçăo “Mapeamento de Maps”. Podemos realizar a seguinte consulta para recuperar os nomes e os números de telefone de cada um dos empregados:
SELECT e.nome, tel
FROM Empregado e JOIN e.numeroTelefones telO resultado dessa consulta é uma lista com nomes e números de telefone de cada empregado. Isso significa que, por padrăo, sempre que fazemos uma busca em um Map, o resultado retornado é o valor do Map e năo sua chave. Para ficar mais claro, podemos usar o operador VALUE da seguinte forma:
SELECT e.nome, VALUE(tel)
FROM Empregado e JOIN e.numeroTelefones telUsando essa instruçăo podemos recuperar o mesmo resultado da consulta anterior, porém, está mais explícito que queremos o valor do Map e năo sua chave. O operador KEY, por sua vez, nos permite recuperar a chave do Map, por exemplo:
SELECT e.nome, KEY(tel), VALUE(tel)
FROM Empregado e JOIN e.numeroTelefones tel
WHERE KEY(tel) IN ("Trabalho", "Celular") Agora recuperamos os nomes dos empregados, os tipos e os números dos telefones caso o tipo do telefone seja “Trabalho” e/ou “Celular”. Repare que os operadores KEY e VALUE podem ser utilizados tanto com a cláusula SELECT quanto com as cláusulas WHERE e HAVING.
Se desejarmos obter o par chave-valor, podemos usar o operador ENTRY.
A Criteria API é, sem dúvida nenhuma, um dos recursos mais esperados pelos desenvolvedores. Com esta API podemos criar queries dinâmicas, padronizadas e efetuar a validaçăo das mesmas em tempo de compilaçăo. Vamos ver como funciona esta API na JPA 2.0.
Começaremos com um exemplo para entender a sintaxe e a utilizaçăo da Criteria API. Eis um exemplo de uma query com JPA 1.0, onde queremos buscar todos os clientes com o nome “Mariana”:
SELECT c
FROM Cliente c
WHERE c.nome = "Mariana" A query demonstrada utiliza recursos JPQL em formato de String. Este formato de construçăo de queries pode acarretar em dois problemas:
1. Permite a utilizaçăo de sintaxe proprietária de alguma linguagem SQL, e nesta situaçăo podemos perder a portabilidade entre diferentes fornecedores de bancos de dados;2. Permite a existęncia de erros na sintaxe da JPQL, e neste caso o erro só será descoberto no momento de execuçăo da query.
Para evitar a utilizaçăo de sintaxe proprietária do banco de dados, a Criteria API faz uso padronizado das palavras reservadas do banco de dados, como SELECT, FROM e WHERE. Veja no exemplo da Listagem 11 que năo colocamos mais em formato de texto as palavras SELECT, FROM, etc.
Listagem 11. Exemplo de query utilizando Criteria API.
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Cliente> c = cb.createQuery(Cliente.class);
Root<Cliente> emp = c.from(Cliente.class);
c.select(emp).where(cb.equal(emp.get(“nome”), “Mariana”)); Aparentemente a query ficou com mais linhas e mais complexa, mas vamos entender o que aconteceu e vocę perceberá que năo é tăo complexo assim. Para auxiliar nesta compreensăo vamos traçar paralelos entre a versăo JPQL e a versăo baseada na Criteria API.
As palavras reservadas de JPQL como SELECT, FROM e WHERE correspondem respectivamente aos métodosselect(), from() e where().
O atributo class da entidade Cliente, utilizado no método from(), substitui o identificador da classe no JPQL.
Já o atributo nome, utilizado no método where(), foi inserido no método get() substituindo o trecho “c.nome”.
Em uma macro visăo temos que a interface CriteriaBuilder é a principal porta de entrada na Criteria API, tendo como objetivo ser uma fábrica de objetos que ligados formarăo uma consulta (select) ao banco de dados. Para obtermos uma instância desta interface basta chamar o método getCriteriaBuilder() da interface EntityManager.
A interface CriteriaBuilder também possui métodos para a construçăo de expressőes condicionais, operadores e funçőes de JPQL na cláusula WHERE.
Outra interface importante na consulta com Criteria API é a interface CriteriaQuery, que pode ser obtida através da chamada do método createQuery() da interface CriteriaBuilder. A interface CriteriaQuery é responsável pelos métodos select(), from() e where().
O primeiro passo na construçăo das queries é obter o objeto CriteriaBuilder, a partir de um EntityManager. O objeto CriteriaBuilder possui métodos para a criaçăo do objeto CriteriaQuery, que define por sua vez a entidade principal a ser utilizada na query – em nosso exemplo utilizamos a classe Cliente.
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Cliente> c = cb.createQuery(Cliente.class); O próximo passo é estabelecer a raiz da consulta, ou seja, a classe principal da cláusula FROM. Para isso utilizamos o método from() a partir da interface CriteriaQuery. Isso equivale ŕ declaraçăo de uma variável de identificaçăo, e formará a base para expressőes que será utilizada como o caminho para o resto da consulta.
Root<Cliente> emp = c.from(Cliente.class); A próxima etapa prevę a cláusula SELECT, passando a raiz da consulta no método select(). Com esta informaçăo sabemos quais săo os objetos que retornarăo no resultado da execuçăo da query.
c.select(emp) O último passo é construir a cláusula WHERE, passando por uma expressăo composta a partir de métodos de CriteriaBuilder que representam as expressőes condicionais de JPQL. Quando estas expressőes săo necessárias, como acessar o atributo nome, o método get() do objeto raiz é usado para criar o acesso ao atributo que será utilizado na expressăo onde combinaremos com o valor do parâmetro que queremos buscar.
where(cb.equal(emp.get(“nome”), “Mariana”)); O uso de Criteria API pode parecer menos vantajoso que escrever JPQL, porém deve ser levado em consideraçăo que esta API traz vantagens para o código, como: padronizaçăo na sintaxe da query, e a possibilidade de validaçăo da query em tempo de compilaçăo (quando combinada com MetaModel API).
Quando construímos queries com JPQL, normalmente utilizamos objetos String para inserir as informaçőes nas queries. Se por um engano escrevermos o nome da classe ou qualquer outra informaçăo errado, este erro só será descoberto em tempo de execuçăo.
Por exemplo, se escrevermos em uma String a palavra “Clente” ao invés de Cliente para referenciar a entidade no meio da String, a exceçăo ocorrerá somente em tempo de execuçăo, pois o compilador Java năo é hábil suficiente para entender este engano.
Com o recurso MetaModel é possível criarmos queries fortemente tipadas, ou seja, queries que serăo avaliadas em tempo de compilaçăo.
Para conseguirmos criar queries fortemente tipadas com JPA 2.0, devemos criar classes que irăo auxiliar o compilador Java.
Sendo assim, para cada entidade a ser utilizada em queries fortemente tipadas, temos que criar uma nova classe que servirá como um modelo “macro”, para que o compilador obtenha informaçőes dos atributos X tipo de dados X mapeamento. Veja o exemplo da entidade de Cliente na Listagem 12 e a nova classe MetaModel na Listagem 13.
Listagem 12. Classe da entidade de cliente.
public class Cliente implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = “id”, nullable = false)
private Integer id;
@Basic(optional = false)
@Column(name = “nome”, nullable = false, length = 45)
private String nome;
@OneToMany(cascade = CascadeType.ALL, mappedBy = “pessoa”)
private Collection<Endereco> enderecoCollection;
}Listagem 13. Classe MetaModel de cliente.
@StaticMetamodel(Cliente.class)
public class Cliente_ {
public static volatile SingularAttribute<Cliente, Integer> id;
public static volatile SingularAttribute<Cliente, String> nome;
public static volatile CollectionAttribute<Cliente, Endereco> project;
}Agora podemos escrever a query fortemente tipada, utilizando a classe auxiliar de MetaModel Cliente_ (Listagem 14).
Listagem 14. Exemplo de query utilizando Criteria API e MetaModel.
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Object> c = cb.createQuery();
Root<Cliente> emp = c.from(Cliente.class);
c.select(emp).where(cb.equal(emp.get(Cliente_.nome), “Mariana”)); Neste exemplo, mapeamos os atributos da classe de entidade Cliente com seus respectivos tipos, a partir da classe auxiliar Cliente_. Alterando a consulta podemos perceber que o método get() do objeto raiz ao invés de utilizar uma String (“nome”) utiliza um atributo estático da classe auxiliar de MetaModel, e por este motivo o conteúdo da query poderá ser validado em tempo de compilaçăo.
O processo de criaçăo e manutençăo das classes de MetaModel exige atençăo, pois todas as alteraçőes realizadas sobre as entidades devem ser refletidas nestas classes. Para auxiliar e facilitar este processo, é possível efetuá-lo de maneira automática utilizando a diretiva de compilaçăo –processor, conforme o modelo:
javac -processor org.eclipse.persistence.internal.jpa.modelgen.CanonicalModelProcessor -proc:only -classpath …Este recurso é muito interessante se pensarmos no beneficio de termos a construçăo de queries sem erros de sintaxe e com o uso de recursos de autocomplete das IDEs.
JPA 2.0 é uma das especificaçőes do Java EE 6 que teve mais tempo para ser produzida. Em virtude disso, muitas melhorias foram realizadas. Citamos neste artigo algumas das principais alteraçőes, mas certamente, há muito mais recursos nessa nova especificaçăo. Por isso, para quem tiver mais interesse recomendamos fortemente a leitura da JSR 317.
Apenas para citar, houve melhorias nas APIs (por exemplo, adiçăo de novos métodos nas classes EntityManager, EntityManagerFactory e Query), nos recursos de cache de segundo nível (Second Level Cache), nos recursos de locking (Optimistic Locking), em outros aspectos de mapeamento como a inclusăo de recursos de validaçăo de dados (Bean Validation), entre outras.
Uma melhoria que apesar de simples merece destaque é a padronizaçăo das propriedades de configuraçăo do jdbc no arquivo persistence.xml. Usando JPA 2.0, as propriedades podem ser definidas de acordo com a Listagem 15.
Listagem 15. Trecho do persistence.xml com propriedades padronizadas.
<property name=“javax.persistence.jdbc.url” value=“jdbc:mysql://host:3306/<database>” />
<property name=“javax.persistence.jdbc.user” value=“<user>” />
<property name=“javax.persistence.jdbc.password” value=“<password>” />
<property name=“javax.persistence.jdbc.driver” value=“<driver name>” />Conforme percebemos neste artigo, a API JPA 2.0 está totalmente madura, pois essa nova versăo incorporou a maioria dos recursos utilizados nos frameworks de persistęncia mais comuns e, principalmente, resolveu as limitaçőes que a versăo 1.0 apresentava em relaçăo aos sistemas legados.
Para quem quer colocar em prática, o mercado já oferece duas implementaçőes para a JPA 2.0: EclipseLink, que é a RI (Reference Implementation), e Hibernate 3.5, que foi lançado recentemente. Ambas as implementaçőes podem ser utilizadas tanto dentro de servidores Java EE quanto em ambientes de aplicaçăo desktop. Vale a pena experimentar. Os exemplos deste artigo foram feitos usando IDE Eclipse e EclipseLink em ambiente desktop.
Para finalizar, vale ressaltar que os recursos adicionados ŕ JPA 2.0 mantęm compatibilidade com a versăo anterior. Assim, aplicaçőes que já utilizam JPA 1.0 continuam funcionando sem necessidade de alteraçăo ao migrar para a versăo 2.0.

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.