


Este artigo tem o objetivo de introduzir o leitor em práticas que o levarăo ŕ configuraçăo de um ambiente simples, buscando ensinar a parte principal do modelo de replicaçăo assíncrona e semi-síncrona entre servidores de bancos de dados MySQL localizados em máquinas diferentes.
Para que serve:
Para que o administrador de bancos de dados (DBA) que utilize o MySQL possa ter o caminho das pedras para aumentar o seu poder de processamento com a divisăo do workload em máquinas diferentes. Para isso, será necessário que o mesmo saiba escalar o ambiente horizontalmente.
Em que situaçăo o tema é útil:
O tema se faz útil no sentido de que o DBA e o engenheiro de software poderăo guiar os seus projetos no sentido de melhor atender as demandas de uma aplicaçăo quando esta atingir tamanhos ainda năo imaginados, pois empresas crescem e os sistemas devem acompanhar esse crescimento.
Neste artigo, iremos abordar mais uma soluçăo possível quando se utiliza um servidor de bancos de dados tăo flexível quanto o MySQL. Săo muitas as possibilidades, que daria para escrever uma revista inteira somente com o assunto mais quente no momento na comunidade de usuários do MySQL: escalabilidade ou Scale-Out. Quente por que algumas das maiores empresas de internet utilizam o MySQL como o principal de produto de armazenamento e manipulaçăo direta de dados, tais como Facebook, Yahoo!, Google, Twitter, Zappos, Amazon, Banco BMG, Lojas Americanas, NASA, Catho, Imasters e Smart GEO. Todas estas empresas tęm testemunhos muito positivos em relaçăo ŕ utilizaçăo do MySQL, ao suporte e consultoria que lhe săo oferecidos pela Oracle e estăo se adaptando para escalar mais ainda os seus aplicativos no sentido de garantir que haja escalabilidade no cruzamento Tecnologia da Informaçăo x Negócios.
Desde a última conferęncia de usuários do MySQL, a MySQL User Conference, que acontece todo ano na cidade de Santa Clara na Califórnia, Edward Screeven, que atualmente é o executivo que está no comando do MySQL, anunciou um recurso muito interessante o qual já nos deu a possibilidade de trabalhar melhor questőes ligadas ŕ escalabilidade horizontal. Com isso, com a nova versăo do MySQL que está em preparaçăo pela Oracle, contaremos com a semi-synchronous replication que acaba com o problema do atraso (delay) na entrega da informaçăo. Tais problemas aparecem em empresas por problemas de má configuraçăo do MySQL ou ainda problemas de latęncia na rede LAN/WAN que está utilizando.
Aproveitando essa deixa, vamos falar de conteúdo prático e como vamos conceber nosso ambiente no contexto desse artigo. Além das máquinas que serăo utilizadas, adicionaremos nessa segunda parte do artigo mais um componente bastante interessante que faz uma espécie de balanceamento de carga (load-balacing) entre servidores de bancos de dados MySQL SLAVE, ou seja, vamos o utilizar MySQL Proxy, cujo seu papel em nosso ambiente será explicado ao longo deste artigo. Além disso, nosso modelo de replicaçăo contará com quatro máquinas, sendo uma rodando uma instância do MySQL que será a MASTER, outras duas máquinas que serăo os SLAVEs, e finalmente a última máquina que somente rodará o MySQL Proxy. Talvez vocę esteja se perguntando: “uma máquina somente para o mysql-proxy?”. É isso mesmo! Pois ela receberá muitas conexőes requisitando dados e terá que rotear as consultas para o servidor menos ocupado, ou seja, ele será o carrasco que fará os SLAVEs trabalharem sem parar.
Topologia e Configuraçőes
Utilizaremos a topologia que tem o nome de topologia em árvore, utilizando um MASTER e dois SLAVEs, ficando da seguinte forma, descrita na Figura 1.
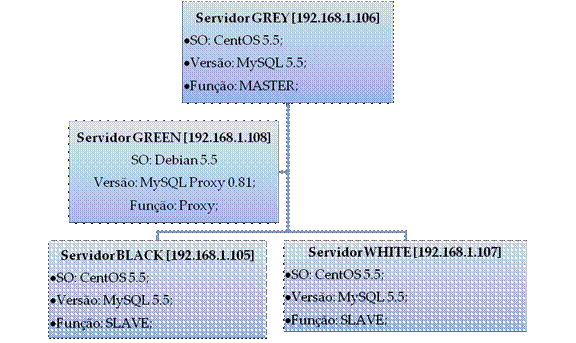
Figura 1.
Configuraçăo dos ServidoresTodas as máquinas foram previamente criadas em um host (hospedeiro) rodando o sistema operacional CentOS versăo 5.5. Dentro do CentOS, o software de virtualizaçăo escolhido foi o Oracle VirtualBox, por ser uma opçăo leve, intuitiva, amigável e de fácil configuraçăo. Para mais informaçőes sobre o Oracle VirtualBox, acesse www.virtualbox.org.
Após instalar e atualizar os sistemas operacionais, efetuar as configuraçőes de rede e colocar a coisa para funcionar, baixe o pacote “.tar” que reúne todos os pacotes de MySQL que deverăo ser instalados (instale somente o client, o server e o shared). A nossa primeira listagem (Listagem 1) nos mostrará os comandos Linux para a instalaçăo dos pacotes.
Listagem 1. ...

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.