ify>Clique aqui para ler todos os artigos desta ediçăo
Alta disponibilidade com SQL Server 2000 Log Shipping Parte II: Log Shipping na versăo Standard
Paulo Ribeiro
Vimos na primeira parte dessa matéria que log shipping pode ser definido como um processo automático de geraçăo, envio e restauraçăo de transaction log backups entre pelo menos dois servidores.
Fomos apresentados ao log shipping na versăo Enterprise, que possui essa feature embutida no Enterprise Manager, inclusive com interface para monitoramento. A questăo que ficou em aberto e que será o objeto dessa matéria é como trabalhar com log shipping nas versőes mais populares do SQL Server 2000: a Standard e o Desktop Engine (MSDE).
Os bastidores do log shipping
Um processo de log shipping pode ser resumido em tręs fases:
• Realizaçăo de backups no servidor primário (database e log);
• Cópia dos arquivos de backup para o servidor secundário;
• Restauraçăo dos arquivos de backup no servidor standby.
Se quiséssemos criar e manter um servidor standby bastaria executar essas tręs etapas – backup local, cópia do arquivo de backup e restauraçăo – para que pudéssemos usufruir de todas as vantagens de um servidor standby, correto?
A afirmaçăo está parcialmente correta, vamos explicar por que: backups consecutivos devem ser restaurados em modo NORECOVERY até que o último backup tenha sido aplicado. Nessa condiçăo, um database fica apto para utilizaçăo somente quando o último backup de log for executado e o recovery aplicado. Uma das grandes vantagens de um servidor standby é que a base nesse servidor pode ser utilizada para acessos de leitura, mas se executássemos simplesmente backups e restauraçőes convencionais a base standby năo poderia ser utilizada até que o recovery fosse aplicado. Como resolvemos essa situaçăo? É o que veremos
a seguir.
Como executar uma restauraçăo em modo standby
A restauraçăo em modo standby resume-se a uma informaçăo adicional no comando RESTORE: a cláusula STANDBY, cuja finalidade é deixar o database disponível para leituras após cada restauraçăo. Para manter o database em um estado consistente, transaçőes em aberto năo săo restauradas: serăo mantidas em um repositório temporário, fora dos limites do database – o UNDOFILE.
O papel do arquivo de UNDO é armazenar temporariamente transaçőes em aberto, mantendo-as em um arquivo ŕ parte para posterior aplicaçăo. Suponha que a transaçăo A foi iniciada ŕs 10h20min e concluída ŕs 10h45min. Ŕs 10h30min foi executado o backup de log 1 e ŕs 10h50min o backup de log 2. A transaçăo A foi registrada, portanto, em dois backups de log. Na restauraçăo em modo standby, uma transaçăo năo pode ser restaurada “parcialmente”, pois isso fere um princípio básico do mundo transacional, conhecido por “atomicidade”: ou a transaçăo é efetivada como um todo ou năo será aplicada. Voltando ao nosso exemplo, ao término do backup de log 1, a transaçăo A – que năo foi finalizada – năo será restaurada parcialmente no database standby, sendo copiada para um repositório temporário – o arquivo de UNDO. Assim que a restauraçăo do backup de log 2 iniciar, antes de qualquer coisa o arquivo de UNDO será lido e a “parte inicial” da transaçăo A será aplicada.
Com o término da restauraçăo desse backup, a transaçăo A estará integralmente registrada no database standby. Assim como aconteceu com a transaçăo A, se existir alguma transaçăo em aberto ao término da segunda restauraçăo, essa(s) transaçăo(őes) será(ăo) registrada(s) no arquivo de UNDO para posterior aplicaçăo.
Agora que entendemos como funciona o processo de restauraçăo standby, vamos dar mais um passo a frente iniciando a configuraçăo de log shipping.
Como criar uma configuraçăo de log shipping
Além dos tręs passos descritos no item “Os bastidores do Log Shipping”, é necessário estabelecer mecanismos de controle para que o procedimento de manutençăo do database standby possa ser executado automaticamente. Precisamos garantir, por exemplo, que a restauraçăo dos arquivos respeite a ordem cronológica dos backups. Săo necessárias também as filas de envio e restauraçăo para que um mesmo arquivo năo seja copiado e/ou restaurado várias vezes.
Adicionando esses controles e reescrevendo o procedimento, teríamos o seguinte cenário para criar um database standby:
• Execute um backup full do database de produçăo; armazene-o preferencialmente em um disco local e específico para essa finalidade;
• Registre a execuçăo do backup em um arquivo de controle;
• Crie um job para efetuar backups de log periódicos do database de produçăo, armazene-os também em um disco local;
• Crie um job no servidor standby para ler o arquivo de controle e executar as cópias dos arquivos de backup para o servidor standby;
• Crie um job no servidor standby para efetuar as restauraçőes dos arquivos de backup copiados no item anterior.
Agora que vocę já sabe exatamente o que fazer – e percebeu que vai dar um pouco de trabalho – vamos ao que interessa. A Microsoft já desenvolveu um procedimento para o SQL Server 7.0, baseado no SQLMaint (utilitário para criaçăo dos planos de manutençăo), que automatiza todo o processo de manutençăo de servidores standby (ver Nota 1). Na versăo Enterprise essas rotinas foram embutidas como uma feature do próprio Enterprise Manager, mas nada impede que vocę usufrua de servidores standby na versăo Standard do SQL Server 2000, basta seguir uma receita, conforme veremos a seguir.
Nota 1. Scripts para criaçăo do log shipping
Os scripts utilizados nessa matéria foram extraídos do Microsoft BackOffice Resource 4.5 Resource Kit, mas vocę poderá fazer o download no site da SQL Magazine.
Criando um database standby passo-apasso
Passo 1: Planejamento
Para execuçăo do log shipping em sua totalidade serăo necessários pelo menos dois servidores:
• o servidor primário responde pelo database de produçăo;
• o secundário (ou standby) é o clone, ou seja, aquele onde será restaurada e mantida atualizada uma cópia do database de produçăo.
No exemplo dessa matéria, \\SrvSQLMag é o servidor primário, \\SrvSQLMag_STB o servidor standby. O nome do database é dbTeste (ver Figura 1).
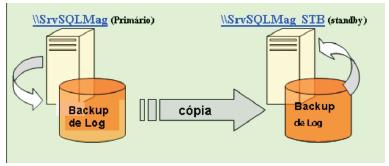
Figura 1. Servidores participantes do log shipping.
...







