Nesse artigo veremos
· Geraçăo das classes de nosso sistema DataCar;
· O que é Mapeamento Objeto-Relacional;
· Implementaçăo de Relacionamentos.
Qual a finalidade
· Permitir a construçăo do núcleo do sistema.
Quais situaçőes utilizam esses recursos?
· As classes criadas aqui farăo parte do núcleo do sistema que será todo orientado a objetos. Aprenderemos que um sistema OO inicia-se pelas classes, diferentemente do que já estamos acostumados, ou seja, começar pelo banco de dados. Também veremos o padrăo DAO.
Resumo do DevMan
Nesta parte do curso aprenderemos um pouco sobre mapeamento objeto relacional (O/R), persistęncia de dados e também sobre o padrăo DAO.
Acredito que uma boa parte dos programadores de hoje em dia ainda desenvolvem suas aplicaçőes de modo procedural ou procedimental. E isso é uma enorme barreira para quem deseja se aventurar e desenvolver sistemas totalmente orientados a objetos. Há um salto bastante enorme de conceito entre Programaçăo Procedural e Programaçăo Orientada a Objetos. O primeiro grande passo a se tomar é entender que um sistema OO nasce de classes e năo do banco de dados como estamos acostumados a fazer em nosso dia-a-dia. Veremos em nosso sistema DataCar como romper essa barreira e entender completamente o ciclo de um software OO.
Na primeira parte do artigo vimos como criar e testar usando o DUnit nossa primeira classe do sistema. Nesta parte do artigo vamos abordar o seguinte problema: “como vamos salvar nossos objetos?”. Solucionar essa dúvida implica entrar em dois assuntos, mapeamento objeto relacional e estratégia de persistęncia. Abordemos entăo o primeiro assunto.
Mapeamento objeto-relacional e desencontro objeto-relacional
O mapeamento objeto-relacional é, de forma resumida, a tarefa de se dizer a um sistema onde determinada classe será salva em um banco de dados relacional, como uma herança pode ser representada, como identificar um objeto dentro do SGBD. Existe uma diferença entre classes e tabelas, a essa diferença dá-se o nome de (desencontro objeto-relacional ou impedância objeto-relacional).
Essencialmente a programaçăo Orientada a Objetos é diferente da programaçăo Orientada a Dados. Quando se programa pensando em objetos levamos em conta seu comportamento e seus dados, diferentemente em um desenvolvimento centrado a dados, levamos em conta apenas a melhor forma de se armazenar os dados, a lógica do negócio envolvido fica separada dos dados.
Mesmo tendo um banco de dados relacional podemos unir dados e comportamento em classes, isto através do mapeamento relacional.
A importância dos OIDs
Para minimizar o impacto do desencontro objeto-relacional, temos que manter um paralelo em alguns aspectos aos bancos de dados relacionais, a exemplo disso temos os OIDs, que săo identificadores de objetos.
Como nossos objetos serăo salvos em um banco relacional devemos disponibilizar uma forma de encontrá-los. Um OID identifica um único objeto em meio a tantos outros, ele representa a “chave-primária” do nosso banco relacional.
O uso de OIDs facilita a busca de objetos e também o relacionamento entre os objetos. Isso porque quando todas as tabelas utilizam o mesmo tipo de coluna para manter suas chaves, o desenvolvimento de código genérico para lidar com elas é facilitado.
Existem algumas consideraçőes sobre as características de um OID:
· Um OID năo deve ter significado para as regras de negócio: Existe um fato que pode passar despercebido ao modelarmos nossas tabelas. Qualquer coluna de uma tabela que tem significado para as regras do negócio, pode sofrer mudanças, isso porque as regras de negócio podem mudar. Colocar campos que contém significado como chaves é erro que deve ser evitado. Imaginem a situaçăo onde para identificar uma venda é utilizado como chave primária um número que representa a Nota Fiscal. Inicialmente o número da nota fiscal contém apenas números, porém mudam-se as regras de negócio e agora o número de uma NF pode conter letras também. O tipo da coluna que armazena esse valor deverá ser mudado em todas as tabelas, seja onde é chave primária seja onde é chave estrangeira. Uma simples mudança de tipo torna-se um pesadelo. Sendo assim um OID năo deve ter significado algum para os negócios, ele deve ser apenas um número seqüencial que identifica um único objeto em meio a outros;
· Nível de unicidade de um OID: Um outro fator que deve ser considerado ao utilizar OIDs está em sua unicidade, ele pode ser único para o universo todo de objetos, ou pode ser único apenas em meio ŕ classe que pertence. Vamos explicar melhor. Vocę pode ter, por exemplo, um objeto Aluno que recebe um OID número 5400. Esse número é único em meio a todos os registros do banco de dados. Năo existe outro registro com esse OID. Agora, o número 5400 pode também ser único apenas entre os objetos de tipo Aluno, existirăo outros registros com esse número, porém pertencerăo a outras tabelas/classes. Ao utilizar OIDs deve-se escolher entre essas duas opçőes, levando em consideraçăo que se escolher a primeira, a coluna que conterá o valor do OID deverá suportar inteiros longos, isso porque vocę poderá ter bilhőes, trilhőes de registros em todo o banco de dados.
Mapeamento básico
Ao mapear classes para tabelas, nem sempre uma classe representa uma tabela e vice-versa. É papel do mapeamento indicar o que representa o que, só assim sua camada de persistęncia saberá para onde salvar seus objetos e de quais tabelas obter os dados que os compőem. Vamos aplicar o mapeamento básico em nosso modelo de classes.
· Atributos săo mapeados para colunas: Um atributo de uma classe pode ser mapeado para 0 ou mais colunas de uma tabela. Vocę deve estar se perguntando por que 0 (zero)? Zero porque em uma classe nem todos os atributos săo persistidos (salvos em meio físico). Um exemplo disso pode ser uma classe Aluno que possui um atributo data de nascimento e idade. Data de nascimento é persistido, porém Idade năo, porque é um atributo calculado, seu valor é obtido de forma dinâmica portanto năo precisa ser salvo;
· Mapeando classes para tabelas: Em situaçőes simples geralmente classes săo mapeadas diretamente para tabelas, exemplo:
Classe TDespesa -> Tabela DESPESA
Porém existem situaçőes mais complexas, por exemplo, quando nossos objetos utilizam herança para alcançar a realidade do negócio. Para demonstrar como mapear uma herança, tomemos por base o diagrama de classes da Figura 1.
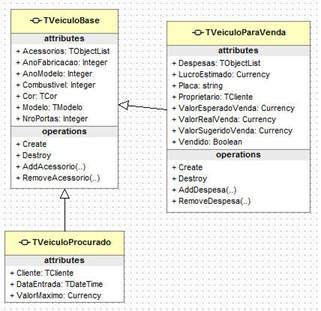
Figura 1. Herança
Existem tręs formas básicas para se implementar a herança, que é um conceito de orientaçăo a objetos, a um banco de dados relacional:
1. Uma tabela para toda hierarquia de classe ...







