
Atençăo: por essa ediçăo ser muito antiga năo há arquivo PDF para download.Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.
JDBC Ponta a Ponta
Parte 1:De conceitos essenciais a configuraçőes e consultas
Aprenda os fundamentos de uma APIs mais importante do Java
A tecnologia de bancos de dados relacionais é talvez a mais importante em todos os tempos para os Sistemas de Informaçăo. Os bancos de dados mais populares do mercado, desde bancos leves como o HSQLDB, passando pelos livres “convencionais” como MySQL até os pesos-pesados como Oracle săo, com poucas exceçőes, banco de dados relacionais.Desde os primórdios do Java, a importância dos bancos de dados foi reconhecida,e a versăo 1.1 do JDK já trazia como componente padrăo a API JDBC.
Por meio do JDBC,uma aplicaçăo Java pode se conectar a qualquer banco relacional,submeter comandos SQL para execuçăo e recuperar os resultados gerados pela execuçăo desses comandos.além disso,o JDBC permite acesso aos metadados do banco de dados (também conhecido como “catalogo”) permitindo a construçăo de ferramentas para administraçăo do próprio banco e apoiando o desenvolvimento de sistemas.
Embora versőes posteriores do Java tenham trazido alguns novos recursos ao JDBC (veja o quadro”Versőes da API JDBC”),os recursos presentes já nas primeiras versőes da API atendem plenamente ŕs necessidades da maioria das aplicaçőes,mesmo quando há demandas fortes de performance e de suporte a recursos avançados como dados multimídia.O melhor de tudo é que a compatibilidade retroativa foi preservado - ao contrário de APIs como Swing e coleçőes, que mudaram bastante do Java 1.1 para o Java 2.Entăo aplicaçőes Java baseadas nas primeiras versőes do JDBC năo necessitam de modificaçőes para adaptaçăo a versőes mais recentes da JVM ou do JDK.
Mesmo o desenvolvedor que utiliza mecanismo de persistęncia objeto-relacional como Hibernate e EJB 3,ou que a prefere frameworks relacionais como iBatis ou Spring JDBC (veja links) necessita de um conhecimento abrangente da API JDBC e de conceitos de bancos de dados relacionais em geral.Afinal, todos esses frameworks e bibliotecas usam o JDBC como base para comunicaçăo com banco de dados.
Esta série sobre JDBC atende a dois públicos distintos.Para os iniciantes,que nunca tiveram contato com o JDBC,esta primeira parte apresenta os fundamentos da API.Já para os desenvolvedores com alguma experięncia prévia com JDBC,a segunda parte,na próxima ediçăo,apresenta recursos que fazem a diferença entre uma aplicaçăo “de brinquedo” e uma aplicaçăo profissional como transaçőes,o uso de PreparedStatements,e dicas de segurança.
Os exemplos serăo todos executados sobre o HSQLDB, para que năo seja necessário instalar e administrar um banco mais sofisticado.Mas funcionam sem alteraçőes em qualquer outro banco de dados – foram testados MySQL,PostgreSQL,FireBird e Oracle.Como năo haveria espaço suficiente para apresentar os procedimentos para inicializaçăo de todas esses bancos,nesta parte focamos no HSSQLDB, e na segunda mostraremos como executar os exemplos (das duas partes) no MySQL e PostgreSQL,os dois bancos de dados livres mais populares.
Drivers JDBC
Para acessar um banco relacional, uma aplicaçăo Java necessita,além da própria máquina virtual, de um driver JDBC.Este driver é em geral fornecido junto com o banco de dados ou com um download separados pelo próprio fornecedor do banco,sem custo adicional.
Se vocę vem de outros ambientes, como VB e o Delphi, vai se surpreender ao descobrir que o JDBC năo necessita de nenhuma configuraçăo prévia, nem que seja instalado um cliente nativo do banco de dados para funcionar. Drivers JDBC săo na grande maioria simples biblioteca Java – arquivo JAR que podem ser copiados para qualquer sistema operacional. Năo há necessidade de editar arquivos de configuraçăo nem de executar algum painel de controle administrativo.
Ř “Drivers JDBC escritos inteiramente em Java săo conhecidos como drivers Tipo 4 (Type 4).”
Existem no mercado alguns drivers que utilizam códigos nativo (via JNI) para aproveitar código dos clientes nativos proprietários do banco de dados. Mas eles em geral tęm performance inferior, e săo mais pesados e menos estáveis do que os escritos inteiramente em Java para o mesmo banco.
Drivers que usam códigos nativos tęm o overhead de traduzir objetos Java para estruturas de dados e tipos nativos do sistema operacional. Já drivers puro-Java pode usufruir dos recursos avançados de conectividade de rede, geręncia de memória e segurança embutidas no Java.
A Figura 1 compara um driver JDBC escrito inteiramente em Java com drivers que usam códigos nativo. A mesma figura compara drivers JDBC com mecanismo nativo de acesso a bancos de dados, tomando como referencia o popular ODBC do Windows.É utilizado como exemplo o driver JDBC do Oracle.A figura ficaria praticamente igual se em vez de ODBC fosse utilizado o dbExpress do Delphi, o ADO.NET da Microsoft,ou tecnologia similares.
Para compilar uma aplicaçăo Java que acessa um banco de dados via JDBC,năo é necessário ter nenhum drivers JDBC, năo é necessário ter nenhum driver JDBC instalado nem configuraçăo no seu IDE.Mas para executar a aplicaçăo,as classes do driver devem estar no classpath.Isto significa que uma mesma aplicaçăo pode ser executada utilizando qualquer banco de dados que deseje, contanto que a aplicaçăo seja escrita usando apenas comando SQL padronizados,ou entăo encapsulando com cuidado comandos que utilizam sintaxes proprietárias de cada banco.
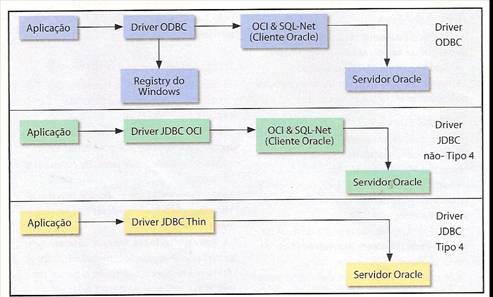
Figura 1.Drivers JDBC Tipo 4 versus drivers ODBC do (os drivers JDBC OCI e Thin săo ambos fornecidos pela Oracle,no mesmo pacote
O banco de dados de exemplo
Como indicado na introduçăo, os exemplos os exemplos deste artigo utilizam o HQSLDB,um banco de dados livre escrito inteiramente em Java,mas foram testados e funcionam com vários bancos.Năo entraremos em muitos detalhes sobre HQSLDB,pois ele já foi descoberto extensamente em ediçőes anteriores da Java Magazine.Apresentaremos aqui apenas o suficiente para criar o banco de dados de exemplo e executar as aplicaçőes criadas neste artigo.
Baixe o arquivo hqsldb_1_8_0_7.zip de hqsldb.sf.net e descompacte em uma pasta qualquer,por exemplo c:\java ou /home/usuário no Linux.O resultado será a criaçăo de um diretório chamado hqsldb,contendo a documentaçăo,classes Java e fontes HQSLDB existe o arquivohsqldb.jar que contém tanto o driver JDBC quanto o próprio servidor do banco de dados.Este é um caso raro:em geral o driver JDBC é fornecido em um pacote JAR ŕ parte,mas o uso embarcado do HQSLDB justifica este empacotamento atípico.
O HQSLDB pode ser executado como um servidor de rede, aceitando conexőes TCP/IP da mesma forma que o MySQL ou Oracle, ou entăo no chamado modo standalone,onde o banco de dados fica embutido dentro da aplicaçăo Java e acessa diretamente os arquivos de dados.Para a aplicaçăo,os dois modos săo indiferente.A aplicaçăo apenas indica ou o caminho para um arquivo local,ou a URL para um servidor remoto.
Vamos entăo configurar o classpath do sistema operacional para incluir o driver do HSQLDB.Usuários Windows podem digitar o comando a seguir em um prompt de comandod do MS-DOS:
setCLASSPATH=%CLASSPATH%;c:\java\hsqldb\lib\hsqldb.jar
Utilize este mesmo prompt de comando para executar os exemplos deste artigo. Caso a janela seja fechada, a configuraçăo do classpath será perdida.
Usuários Linux podem usar o comando:
exportCLASSPATH=
$CLASSPATH:/home/lozano/hsqldb/lib/hsqldb.jar
E, da mesma forma que no Windows, também devem ser executados os exemplos no mesmo shell onde foi configurado o classpath.Em ambos os casos,altere o diretório de instalaçăo do HSQLDB conforme sua preferęncia.
O arquivo hsqldb.jar contém ainda um pequeno aplicativo de administraçăo do banco de dados chamdo DataBase Manager.Todos os bancos de dados fornece uma interface similar para execuçăo de comandos SQL.Um detalhe é que a fornecida pelo HSQLDB é escrita em Java e pode ser usada com outros bancos.
A Listagem 1 apresenta a seqüęncia de comando SQL que cria o banco de dados de exemplo e insere alguns dados de teste.Nosso banco de dados contém um resumo de informaçőes sobre vendas de produtos de uma rede de lojas varejistas.







