Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.

Clique aqui para ler todos os artigos desta ediçăo
Mineraçăo de Dados: Introduçăo e Aplicaçőes
Bancos de dados relacionais săo responsáveis por armazenar e recuperar dados de forma eficiente. No entanto, somente estas atividades năo garantem a continuidade dos negócios. Nos dias de hoje, cada vez mais é necessário que se tire um proveito maior dos dados. Surge a tríade dado, informaçăo e conhecimento. O dado é algo bruto, é a matéria-prima da qual podemos extrair informaçăo. Informaçăo é o dado processado, com significado e contexto bem definido. O computador, em essęncia, serve para transformar dados em informaçőes. Por fim, o conhecimento é o uso inteligente da informaçăo, é a informaçăo contextualizada e utilizada na prática. Dessa forma, a qualidade da informaçăo sustenta o conhecimento.
Os bancos relacionais, quando bem projetados, permitem a extraçăo de diversas informaçőes usando SQL. O mecanismo é simples: elabora-se um problema, é realizado um mapeamento para a linguagem de consulta, e esta consulta é submetida ao SGBD. Observe que esse processo resolve questőes que necessariamente devem ser definidas, ou seja, as informaçőes extraídas săo respostas a uma consulta previamente estruturada. No entanto, dados armazenados podem esconder diversos tipos de padrőes e comportamentos relevantes que a princípio năo podem ser descobertos utilizando-se SQL. Além disso, por mais que o analista seja criativo, ele irá apenas conseguir elaborar diversas questőes de forma que se tenham resultados práticos no final. Neste contexto está inserida a aplicabilidade da mineraçăo de dados.
Para exemplificar, considere um cadastro com aproximadamente 500.000 clientes de uma loja de roupas. Através do uso de técnicas de mineraçăo foi descoberto que 7% desses clientes săo casados, estăo na faixa etária compreendida entre 31 e 40 anos e possuem pelo menos dois filhos. Uma campanha de marketing direcionada a esse grupo de clientes poderia ser realizada objetivando o aumento no consumo de produtos infantis. Note que inicialmente năo foi elaborada uma questăo do tipo “identifique os clientes casados com faixa etária entre 31 e 40 anos e que possuem pelo menos dois filhos”. O próprio processo de mineraçăo identificou a pergunta e a resposta.
Assim, mineraçăo de dados pode ser definida como o processo automatizado de descoberta de novas informaçőes a partir de grandes massas de dados. A mineraçăo de dados é uma área extensa, interdisciplinar e envolve o estudo de diversas técnicas (ver figura 1).
|
Mineraçăo de Dados |
|
Banco de Dados |
|
Estatística |
|
Outras Disciplinas |
|
Inteligęncia Artificial |
|
Otimizaçăo |
|
Visualizaçăo |
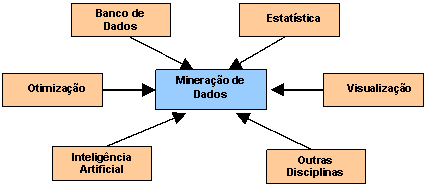
Figura 1
Nota
A mineraçăo de dados năo ocorre somente em bancos de dados relacionais. Hoje em dia pode-se trabalhar com diversas fontes tais como textos, arquivos de log, data warehouses, entre outras.
Para que o conceito seja melhor entendido, vejamos o seguinte exemplo (retirado do livro DataMining: Técnicas e Aplicaçőes para o Marketing Direto, Fernanda Cristina Naliato do Amaral, Ed. Berkeley, 2001): tomemos uma base de dados de empréstimos pessoais. O tipo de conhecimento que se deseja extrair é como identificar os mutuários negligentes. Uma vez consultado um analista de dados, este considerou que os dados mais representativos do conhecimento desejado săo fornecidos pelos atributos salário, débito e regularidade de pagamento. De posse dessas informaçőes, pode-se formar o gráfico da figura 2, que mostra o conjunto de dados usado, composto de 14 amostras.
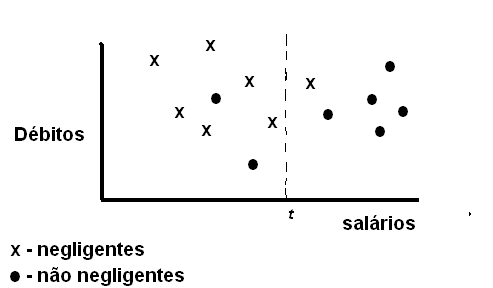
Figura 2
Cada ponto no gráfico representa um mutuário a quem foi dado um empréstimo por um banco particular, em algum momento no passado. No eixo horizontal, tem-se o salário do mutuário; no vertical, seu débito mensal (hipoteca, pagamento de carro, etc).
Os dados foram classificados em duas classes: os mutuários representados por X, que estăo em débito com o pagamento dos empréstimos, e os representados por O, em dia com o banco. A partir do gráfico da figura 2, tenta-se definir padrőes onde as pessoas consideradas negligentes estejam separadas das pessoas năo negligentes.
O padrăo linear t representa apenas parte da realidade, uma vez que nem sempre ele é verdadeiro. Ao examinarmos a figura 2, chegamos a seguinte regra:
Se salário>t, entăo mutuário é bom pagador.
Note que a regra nem sempre é verdadeira: visualmente, podemos notar que existem casos em que mesmo um cliente com um salário > t năo é um bom pagador. A proposta é encontrar o padrăo que retrata de forma mais fiel o conhecimento apresentado nos dados. Para isso, além do padrăo linear, existem outras técnicas mais complexas, que podem ser visualizadas na figura 3.
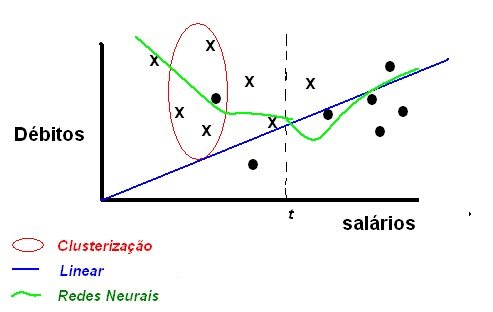
Figura 3
KDD e Mineraçăo de Dados
Em diversos livros e artigos, a mineraçăo de dados é vista como parte de um processo maior, denominado KDD - Knowledge Discovery in Database - que significa descoberta de conhecimento em bases de dados. Este processo é dividido em seis etapas e envolve duas grandes fases: preparaçăo de dados (destaque em azul) e sua mineraçăo (destaque em verde) (ver figura 4).

Figura 4
O processo de KDD é iniciado através da compreensăo do domínio da aplicaçăo e o estabelecimento dos objetivos a serem obtidos. Nesta fase, as questőes em potencial para a mineraçăo săo identificadas. Dependendo do problema a ser minerado e da massa de dados disponível, haverá a escolha do tipo de técnica a ser trabalhada. A questăo a ser minerada e a própria técnica a ser trabalhada definem qual parte da massa de dados inicial vai ser utilizada e, para isso, selecionada.
No próximo passo é realizada a limpeza através de um pré-processamento dos dados. Nesta fase săo eliminadas eventuais incompletudes, problemas de tipagem, repetiçăo de registros etc.
Nota
Alguns estudos mostram que a etapa de limpeza dos dados pode tomar até 80% do tempo necessário para todo o processo de descoberta de conhecimento. Ela também é considerada uma das etapas mais importantes para o sucesso do processo como um todo.
Os dados pré-processados passam ainda por uma transformaçăo com o objetivo de facilitar seu uso pelas técnicas de mineraçăo. Nesta fase, o uso de data warehouse (DW) torna-se bastante útil, pois nessas estruturas o pré-processamento dos dados já existe (para mais informaçőes sobre data warehouse, leia o artigo de Patrícia Barbalho, na ediçăo 3 da revista). Ou seja, as informaçőes já estăo consolidadas num formato mais estatístico e menos transacional.
Dando continuidade ao processo, chega-se ŕ fase de mineraçăo, a qual começa com a escolha dos algoritmos a serem aplicados. Essa escolha depende do objetivo do processo de KDD. Ao final do processo, o sistema que efetuou a mineraçăo poderá gerar relatórios das descobertas, que passam pela interpretaçăo dos analistas envolvidos. A partir das informaçőes identificadas é possível utilizá-las, transformando-as assim em conhecimento.
Alguns elementos que fornecem apoio ao processo de KDD săo:
·Data warehouse: transforma e consolida informaçőes inicialmente localizadas em diferentes plataformas e bases de dados. Ele facilita o processo KDD porque realiza um pré-processamento dos dados visando integridade, consistęncia e limpeza dos mesmos;
·Ferramentas de visualizaçăo de dados: facilitam a interpretaçăo dos resultados gerados pelo processo KDD. Uma ferramenta bem projetada evidencia, de maneira clara e resumida, a informaçăo extraída (ler os artigos sobre as ferramentas FMDB e TreeMiner, nesta ediçăo);
·Estatística: está presente em diversos algoritmos de data mining;
·Inteligęncia artificial: muitos algoritmos da IA săo utilizados para descobrir padrőes no meio da massa de dados histórica.
Tarefas e Técnicas em Mineraçăo de Dados
Descobrir padrőes e tendęncias escondidos em grandes massas de dados năo é um processo trivial. Em mineraçăo de dados este processo envolve o uso de diversas tarefas e técnicas. As tarefas săo classes de problemas, que foram definidas através de estudos na área. As técnicas săo grupos de soluçőes (algoritmos) para os problemas propostos nas tarefas. Cada tarefa apresenta várias técnicas, e algumas técnicas podem ser utilizadas para solucionar tarefas diferentes.
As classes de tarefas básicas săo:
·Classificaçăo: consiste em examinar as características de um objeto (ou situaçăo) e atribuir a ele uma classe pré-definida. Ou seja, esta tarefa objetiva a construçăo de modelos que permitam o agrupamento de dados em classes. Essa tarefa é considerada preditiva, pois uma vez que as classes săo definidas, ela pode prever automaticamente a classe de um novo dado. Por exemplo, uma populaçăo pode ser dividida em categorias para avaliaçăo de concessăo de crédito com base em um histórico de transaçőes de créditos anteriores. Em seguida, uma nova pessoa pode ser enquadrada, automaticamente, em uma categoria de crédito específica, de acordo com suas características.
·Associaçăo: estuda um padrăo de relacionamento entre itens de dados. Por exemplo, uma análise das transaçőes de compra em um supermercado pode encontrar itens que tendem a ocorrerem juntos em uma mesma compra (como café e leite). Os resultados desta análise podem ser úteis na elaboraçăo de catálogos e layout de prateleiras de modo que produtos a serem adquiridos na mesma compra fiquem próximos um do outro. Essa tarefa é considerada descritiva, ou seja, ela é usada para identificar padrőes em dados históricos.
·Clusterizaçăo (segmentaçăo): as informaçőes podem ser particionadas em classes de elementos similares. Neste caso, nada é informado ao sistema a respeito das classes existentes. O próprio algoritmo descobre as classes a partir das alternativas encontradas na base de dados, agrupando assim um conjunto de objetos em classes de objetos semelhantes. Por exemplo, uma populaçăo inteira de dados sobre tratamento de uma doença pode ser dividida em grupos baseados na semelhança de efeitos colaterais produzidos; acessos a web realizados por um conjunto de usuários em relaçăo a um conjunto de documentos podem ser analisados para revelar clusters ou categorias de usuários. Essa tarefa é considerada descritiva.
·Estimativa (regressăo): objetiva definir um valor (numérico) de alguma variável desconhecida a partir dos valores de variáveis conhecidas. Exemplos de aplicaçőes săo: estimar a probabilidade de um paciente sobreviver dado o resultado de um conjunto de diagnósticos de exames; predizer quantos carros passam em determinado pedágio, tendo alguns exemplos contendo informaçőes como: cidades mais próximas, preço do pedágio, dia da semana, rodovia em que o pedágio está localizado, entre outros. Essa tarefa é considera preditiva.
Nota: Classificaçăo versus clusterizaçăo
Na tarefa de classificaçăo, os registros săo subdivididos e colocados em classes pré-definidas. Já na clusterizaçăo, năo há necessidade que se definam essas classes, pois estas săo identificadas durante o processo, de forma automática. Neste caso, os registros săo agrupados com base em similaridades. Na clusterizaçăo, năo há atributo especial. A importância de cada atributo em geral é considerada equivalente ŕ dos demais.
Entre as principais técnicas, podemos destacar as árvores de classificaçăo, redes neurais, algoritmos genéticos, algoritmo de Bayes, entre outros.
Serăo apresentados quatro exemplos associados ŕs tarefas acima. Para cada um deles será utilizada uma técnica específica.
Um exemplo envolvendo classificaçăo
O objetivo desta tarefa é construir um modelo que seja capaz de gerar classificaçőes para novos objetos ou novos dados (tarefa preditiva). Para isso, devem ser considerados dois tipos de atributos que caracterizam o objeto: atributos preditivos, cujos valores irăo influenciar no processo de determinaçăo da classe; e atributos objetivos, que indicam a classe a qual o objeto pertence. Assim, a classificaçăo visa descobrir algum tipo de relacionamento entre os atributos preditivos e objetivos.
A principal técnica utilizada para a tarefa de classificaçăo é a árvore de classificaçăo (classification tree). Vejamos um exemplo que utiliza esta técnica: imagine uma aplicaçăo que analisa dados de clientes, visando a aprovaçăo ou năo (atributo objetivo) de crédito para empréstimo pessoal. Neste banco de dados, existem pessoas adimplentes e inadimplentes sendo cada classe caracterizada por algum tipo de padrăo. Neste processo, os clientes do banco de dados cujo campo resultado venham a ter o valor năo, representarăo os inadimplentes. Para poder preencher esse campo, serăo consideradas as características dos clientes (atributos preditivos) existentes no banco. Normalmente, um analista indica quais săo os atributos relevantes para a prediçăo – neste exemplo, os atributos preditivos săo cargo e tempo. Observe que é um exemplo meramente ilustrativo e que num processo real outros atributos também deveriam ser considerados. O processo pode ser dividido em duas fases:
·Fase I: um modelo é construído, descrevendo um conjunto pré-determinado de classes (neste caso, SIM ou NĂO). Em seguida, um conjunto de treinamento é analisado por um algoritmo de classificaçăo, que gera como saída um modelo baseado numa árvore de classificaçăo (ver figura 5).
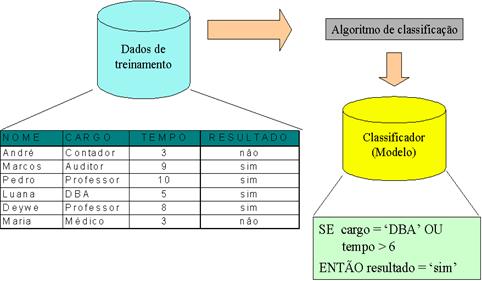
Figura 5
·Fase II: o modelo gerado pela fase I é utilizado para classificaçăo. Depois disso, é realizado um teste de acurácia e se esta for aceitável, as regras poderăo ser utilizadas para a classificaçăo de novos casos (ver figura 6).
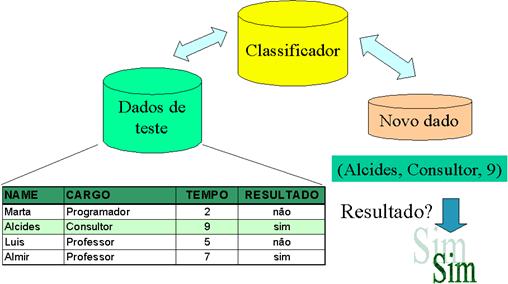
Figura 6
NOTA: Árvore de Classificaçăo
A técnica árvore de classificaçăo tem esse nome por se tratar, de fato, de uma árvore de decisăo – um formato comum de representaçăo de modelos SE-ENTĂO. A representaçăo gráfica de uma árvore de decisăo lembra a de uma pirâmide invertida. Por exemplo, para o modelo gerado anteriormente, podemos ter a representaçăo visual da figura 7. Cada caminho possível em uma árvore de decisăo é chamado de regra de decisăo (decision rule).
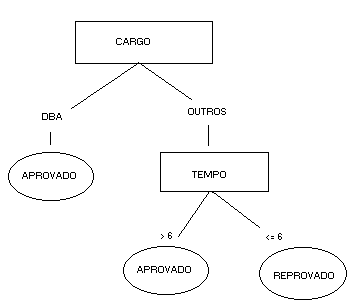
Figura 7
NOTA
Os algoritmos utilizados em data mining (incluindo os algoritmos de construçăo de árvores de classificaçăo) săo complexos e envolvem matemática, estatística e muitas vezes inteligęncia artificial. Para maiores informaçőes sobre a construçăo desses algoritmos consulte as referęncias indicadas no final deste artigo.
BOX: Aplicaçăo de Classificaçăo no Marketing Direto
Vejamos um bom exemplo de como a técnica de árvore de classificaçăo pode ser útil. Imagine uma empresa que quer aumentar a venda de telefones celulares. Com isto, temos:
1) Através do histórico de compradores da empresa, pode-se criar duas classes: i) pessoas que já compraram pelo menos um telefone celular e ii) pessoas que nunca compraram este tipo de aparelho.
2) Em seguida, cria-se um modelo contendo atributos preditivos (tais como classe social, estilo de vida, regiăo demográfica, entre outros). Com este modelo, define-se um conjunto de treinamento contendo dados de compradores e năo-compradores de celular;
3) Gera-se a árvore de classificaçăo. Após esse passo, a empresa poderá identificar novos clientes como potenciais compradores (ou năo) de celular, e de tempos em tempos formar uma base de clientes que devem receber mala-direta ou mailing sobre promoçăo de celulares.
Além da árvore de classificaçăo, a classificaçăo Bayes também se destaca com uma das técnicas utilizadas para resolver esta tarefa. A classificaçăo Bayes utiliza classificaçőes estatísticas baseadas no teorema de Bayes (http://en.wikipedia.org/wiki/Bayes%2527_theorem). Para maiores informaçőes, consulte as referęncias indicadas no final deste artigo.
Veremos agora um exemplo prático de utilizaçăo de árvores de classificaçăo utilizando o aplicativo Weka. Esta ferramenta é implementada em Java e está disponível para download em http://www.cs.waikato.ac.nz/~ml/weka/index.html. A ferramenta trabalha com diversas técnicas de data mining.
NOTA
A Weka é composta de dois pacotes: i) ferramentas para manipulaçăo interativa de algoritmos de data mining; ii) classes Java que encapsulam esses algoritmos. Dessa forma, é possível utilizar essas classes para embutir os algoritmos de data mining em programas escritos em Java – o desenvolvedor pode criar seu próprio data mining explorer!
A ferramenta pode ser utilizada de duas formas: através de linha de comando ou de uma interface gráfica. Ao iniciar, escolha a opçăo Explorer para entrar na interface gráfica (figura 8). A tela principal é apresentada na figura 9. Maiores detalhes sobre o uso da ferramenta através de linha de comando podem ser obtidos na documentaçăo que acompanha o produto.

Figura 8
O objetivo deste exemplo é gerar uma árvore que auxilie na tomada de decisăo entre jogar ou năo jogar tęnis a depender das condiçőes climáticas. Para este exemplo, utilizamos a tabela weather.arff disponibilizada pela própria ferramenta. Para selecionar o arquivo, clique no botăo Open File. O conteúdo deste arquivo pode ser visualizado na listagem 1. Neste exemplo, os atributos outlook, temperature, humidity e windy serăo preditivos, e o atributo play será objetivo. Neste caso, o atributo objetivo especifica apenas duas classes: YES e NO, que indicam se o tempo está bom ou năo para jogo.
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature real
@attribute humidity real
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
Listagem 1
NOTA
ARFF (Attribute-Relation File Format) é um formato padrăo de arquivos texto, utilizado para representar datasets. Para saber como transformar uma tabela para o formato ARFF, consulte a página http://www.cs.waikato.ac.nz/~ml/weka/arff.html. A ferramenta WEKA também lę bases de dados através de JDBC.
No destaque 1 da figura 9 vemos os atributos da tabela. Clique sobre cada atributo para visualizar como ele influencia no resultado total da tabela (destaque 2 da figura 9).
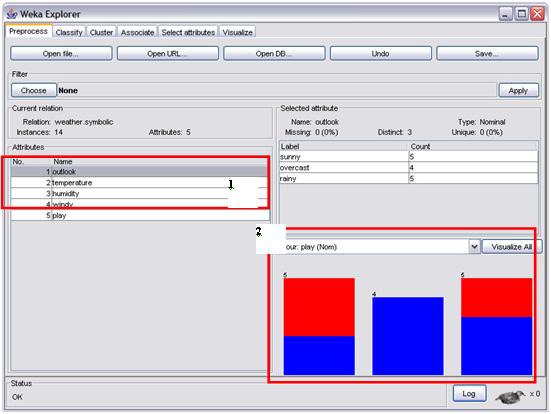
|
1 |
|
|
Figura 9
Para gerar a árvore de classificaçăo, clique na aba classify. Tendo feito isto, clique no botăo Choose e selecione o algoritmo a ser utilizado (destaque 1 da figura 10). Neste exemplo, usaremos o J4.8 (figura 11). O atributo classificador (atributo objetivo) é selecionado como mostrado no destaque 2 da figura 10. Por último, clique no botăo Start – a árvore de classificaçăo gerada pode ser visualizada no destaque 3 da figura 10. A partir de agora, a árvore pode ser usada para identificar novos casos. Por exemplo, se tivermos uma condiçăo climática como a seguir:
outlook: rainy;
temperature: 80;
humidity: 65;
Windy: False.
Seguindo a árvore de classificaçăo, temos que o dia será bom para jogo. Veja a representaçăo gráfica da árvore na figura 12. Para obter esse gráfico, clique com o botăo inverso do mouse sobre o item trees.J48, gerado dentro do Result List, e selecione a opçăo Visualize Tree.
Nota
O algoritmo J4.8 é a implementaçăo da ferramenta Weka para a técnica C4.5 decision tree (um tipo de árvore de classificaçăo). A ferramenta oferece também implementaçőes para outras técnicas de classificaçăo, tais como Naive Bayes e M5.
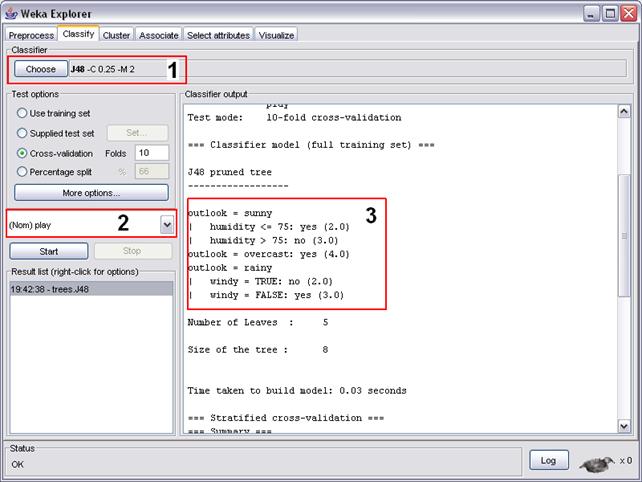
Figura 10
Figura 11
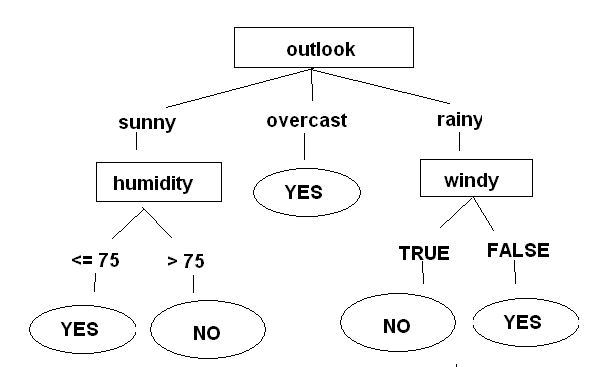
Figura 12
Um exemplo envolvendo associaçăo
Os problemas de associaçăo săo solucionados através da técnica de regra de associaçăo. Existem diversos algoritmos baseados nessa técnica: apriori, DHP, ABS, sampling, dentre outros.
Genericamente, uma regra de associaçăo é representada pela notaçăo X?Y (X implica em Y), onde X e Y săo conjuntos de itens distintos. Neste caso, um item é representado por um dos conceitos existentes no domínio da aplicaçăo. O objetivo desta técnica é representar, com determinado grau de certeza, uma relaçăo existente entre o antecedente e o conseqüęnte de uma regra de associaçăo. A associaçăo é uma tarefa descritiva, ou seja, ela visa identificar padrőes em dados históricos.
Imagine um banco de dados contendo milhares de registros de transaçőes de compras. Para o nosso exemplo consideraremos 10 transaçőes desse banco de dados (ver tabela 1).
|
IDTRANSAÇĂO |
ITENS COMPRADOS |
|
1 |
café, leite, manteiga, păo |
|
2 |
milho, morango, păo |
|
3 |
café, leite, farinha, cerveja |
|
4 |
biscoito, café, carne, leite, presunto, vinho |
|
5 |
adoçante, biscoito, peixe, queijo, vinho |
|
6 |
adoçante, café, leite, păo |
|
7 |
biscoito, milho, presunto, tomate |
|
8 |
café, mel, leite, macarrăo |
|
9 |
frango, mel, tomate |
|
10 |
biscoito, café, cerveja, leite, refrigerante |
Tabela 1
O objetivo aqui é saber se determinado produto X implica na compra do produto Y. Esta implicaçăo é avaliada através de dois fatores: suporte e confiança.
Considere a regra café ? leite.
O suporte de uma regra representa o percentual das transaçőes em que tal regra aparece. No exemplo, existem 10 transaçőes. Note que os itens café e leite aparecem juntos em 60% das transaçőes (transaçőes 1, 3, 4, 6, 8 e 10).
Considere agora a regra biscoito ? vinho.
Os itens biscoito e vinho aparecem juntos em apenas 20% das transaçőes (transaçőes 4 e 5).
A regra café ? leite possui 60% de suporte e a regra biscoito ? vinho possui 20% de suporte. Quando o suporte for baixo, a regra pode năo ser relevante uma vez que aparece apenas em uma pequena parte das transaçőes.
Já o fator confiança, ao invés de considerar todas as transaçőes, trabalha apenas com as que possuem o antecedente da regra. Assim, a confiança é calculada dividindo-se o número de vezes em que o conseqüente da regra aparece pela quantidade dessas transaçőes. Por exemplo: o item café aparece seis vezes na base de dados de transaçăo (transaçőes 1, 3, 4, 6, 8 e 10). Para a regra café ? leite, a confiança é de 100%, ou seja, em todas as compras de café, há a compra de leite.
Já o item biscoito aparece quatro vezes na base de dados de transaçăo (transaçőes 4, 5, 7 e 10). Para a regra biscoito ? vinho, a confiança é de 50%, já que as transaçőes 7 e 10 năo contęm vinho. Isto significa que uma em cada duas transaçőes contendo biscoito também contém vinho.
Um algoritmo de extraçăo de regras de associaçăo deve gerar regras que possuam suporte e confiança especificados pelo usuário. Observe que as regras podem ser compostas por um ou mais itens. Dependendo do tamanho da base de dados e dos fatores de suporte e confiança, inúmeras regras săo geradas. Essas regras devem ser avaliadas pelo usuário especialista, para que somente as mais relevantes possam ser utilizadas na tomada de decisăo.
BOX – Uso de associaçăo para incrementar vendas
Tendo a regra a seguir:
{cerveja, X } => {batatas fritas}
Podemos concluir que:
a) Cerveja como antecedente: O analista pode descobrir quais produtos perderăo vendas se o estoque de cerveja acabar, ou se a venda de cervejas for interrompida (neste caso, batatas).
b) Cerveja como antecedente e batatas como conseqüente: Pode ser usado para visualizar quais produtos (neste exemplo, X) podem ser vendidos com cerveja para incrementar a venda de batatas!
Vejamos um exemplo de utilizaçăo de regras de associaçăo com a ferramenta Weka. Neste caso, utilizaremos a tabela weather.nominal.arff. Para gerar as regras de associaçăo, clique na aba Associate. Vocę perceberá que o algoritmo apriori já aparece previamente selecionado (na área Associator). A implementaçăo deste algoritmo na ferramenta Weka apresenta algumas particularidades:
•O algoritmo tenta gerar dez regras de associaçăo;
•O valor de confiança default é de 90%;
•O valor de suporte mínimo começa com 100%, e vai diminuindo 5% até que 10 regras sejam formadas, ou que o valor de suporte chegue a 10% (o que acontecer primeiro);
•As regras geradas săo ordenadas de acordo com o valor de confiança.
•O algoritmo trabalha apenas com valores categóricos nominais (strings); portanto, se vocę possui uma tabela com valores numéricos, será necessário convertę-los em categorias. Observe que o arquivo weather.nominal.arff é uma versăo transformada do arquivo weather.arff. Neste arquivo, por exemplo, os valores numéricos do campo temperature foram convertidos para hot, mild e cool.
Obs: Para configurar os parâmetros, clique sobre o nome do algoritmo apriori, na área Associator.
Para iniciar o processo, clique no botăo Start. Feito isto, săo geradas dez regras de associaçăo, apresentadas no destaque da figura 13. Vamos analisar o resultado:
•O símbolo => faz a divisăo entre o antecedente e o consequente; Por exemplo, na regra 1 temos que humidade normal (humidity=normal) e tempo sem vento (windy=false) implicam em um dia bom para jogo (play=yes). Ou seja, esses tręs valores em conjunto ocorrem com bastante freqüęncia;
•O número que aparece antes do símbolo => indica o suporte da regra. Por exemplo, a regra 1 ocorre quatro vezes – aproximadamente 28,6%, já que a tabela possui um total de catorze registros;
•O número que aparece no final da regra indica quantas vezes o consequente aparece para cada ocorręncia do antecedente. Ou seja, na regra 1 temos que, das quatro ocorręncias de humidity=normal e windy=false, temos quatro resultados play=Yes. Ou seja, a confiança é de 100%. De fato, as dez regras apresentam confiança de 100%;
•O número entre parenteses é o valor efetivo da confiança, ou seja, 100% (1).
As regras de associaçăo podem ser utilizadas por um analista para geraçăo de novos conhecimentos. Por exemplo, podemos concluir com a regra 1 que, independente de outras variáveis climáticas, um dia com humidade normal e sem vento sempre é um bom dia para jogar tęnis.
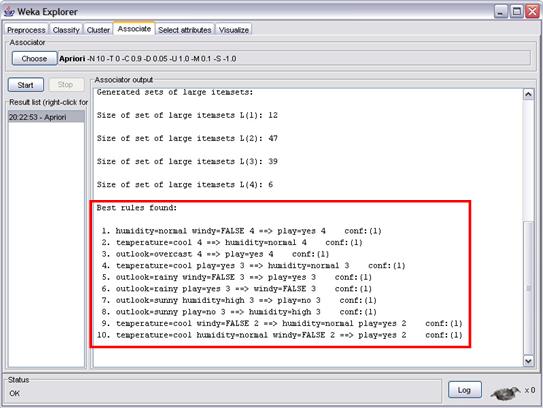
Figura 13
Um exemplo envolvendo clusterizaçăo
A tarefa de clusterizaçăo é descritiva, ou seja, ela visa identificar padrőes em uma massa de dados. A principal diferença entre a classificaçăo e a clusterizaçăo é que nesta última as classes năo săo previamente definidas. A idéia é que o algoritmo de clusterizaçăo identifique automaticamente comportamentos similares em uma base de dados, dividindo a massa de informaçăo em clusters. Após o processo de clusterizaçăo, o analista deve estudar os padrőes identificados a fim de determinar se eles podem ser transformados em conhecimento estratégico.
A figura 14 representa, hipoteticamente, os dados de uma tabela mapeados para um espaço bidimensional. Uma técnica de clusterizaçăo poderia identificar tręs clusters nessa tabela, conforme mostrado na figura 15. Observe que a clusterizaçăo năo responde porquę os padrőes existem, ela apenas os identifica.
Figura 14
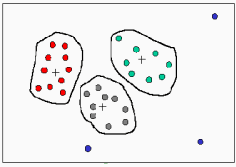
Figura 15
As técnicas de clusterizaçăo mais populares săo:
·Particionamento: O algoritmo mais conhecido para esta técnica é o K-means. Basicamente, o particionamento divide o dataset em grupos, chamados clusters. A técnica é baseada no seguinte princípio:
1) O dataset é tratado como um vetor, e cada informaçăo é considerada um ponto vetorial (como na figura 14). Dessa forma, o algoritmo trabalha com distâncias entre os pontos – ou seja, um conjunto de pontos próximos será considerado um cluster. Para plotar os dados como pontos vetoriais e calcular a distância entre eles é usada uma funçăo de distância. As funçőes de distância mais utilizadas săo a funçăo Euclidiana e a funçăo Manhattan. Para maiores informaçőes sobre essas funçőes, consulte a referęncia indicada ao final do artigo.
2) É necessário definir o número de clusters que serăo criados. Esse número é chamado K, por isso o nome K-means. Como exemplo, vamos definir o número de clusters como 3. O algoritmo inicia com uma divisăo aleatória da matriz em 3 clusters (figura 16).
3) Em seguida, o algoritmo plota um ponto chamado centroid no meio (mean) de cada cluster. Veja o exemplo da figura 17.
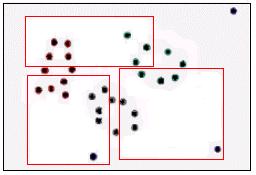
Figura 16
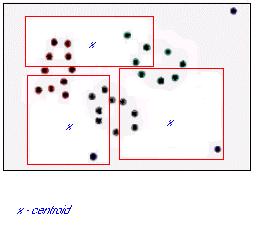
Figura 17
4) Em seguida, os centroids săo reposicionados de acordo com sua distância em relaçăo aos grupos de pontos mais próximos (figura 18a). Com o centroid reposicionado, os clusters săo novamente calculados (figura 18b). Em seguida, os centroids săo novamente recalculados (figura 18c) e esse processo é repetido até que os clusters estejam bem definidos (figura 18d). Observe que, nessa técnica, a qualidade de definiçăo dos clusters será melhor ŕ medida que as ‘nuvens’ de pontos estiverem bem agrupadas.
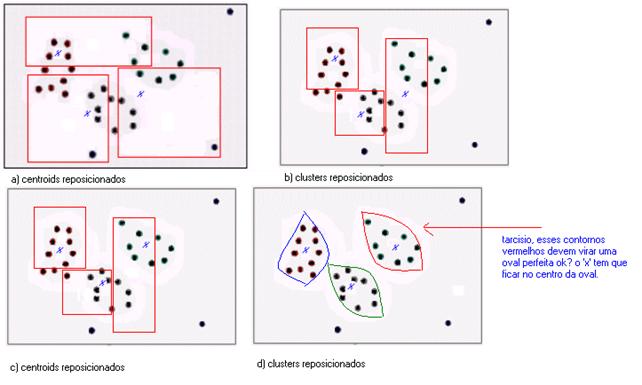
Figura 18
·Hierarquia: O algoritmo mais conhecido é o HAC. Essa técnica trabalha de duas formas: i) divisivo: começa com um cluster único e vai particionando-o em clusters menores, num processo iterativo; ii) aglomerativo: faz justamente o contrário: começa de partes indivisíveis e vai se agrupando em clusters maiores. O resultado é uma árvore de grupos (chamada dendograma), como mostrado na figura 19. A figura 20 exibe a diferença entre os algoritmos aglomerativos e divisivos.
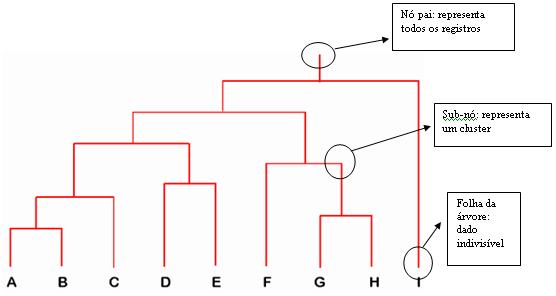
Figura 19
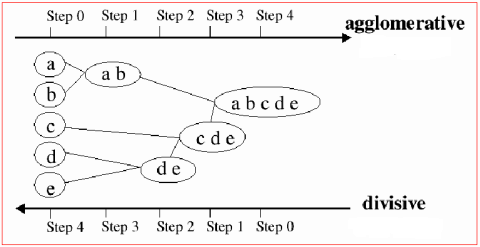
Figura 20
Na ferramenta Weka, os algoritmos de clusterizaçăo podem ser acessados através da aba Cluster. O algoritmo que implementa a técnica k-means é chamado SimpleKMeans, e o algoritmo que implementa a técnica de hiearquia é chamado CobWeb. Năo entraremos em detalhes, pois um exemplo prático de clusterizaçăo pode ser visto na matéria Explorando visualmente informaçőes em grandes bases de dados utilizando a ferramenta FMDB, publicada nesta ediçăo. Maiores informaçőes sobre o uso da ferramenta Weka para clusterizaçăo podem ser obtidos em sua documentaçăo.
Um exemplo envolvendo estimativa
A estimativa (também conhecida como regressăo) é considerada uma tarefa preditiva - seu objetivo é prever um valor numérico desconhecido a partir de alguns atributos conhecidos, utilizando uma massa de dados histórica como modelo. Por exemplo, tendo um banco de dados de imóveis, podemos prever o valor do aluguel de um novo imóvel baseado em fatores como localidade, dimensăo, segurança, entre outros.
As técnicas mais comuns de estimativa săo baseadas nos mesmos métodos da classificaçăo, ou seja, utilizam árvores de decisăo. Em outras palavras, a idéia básica é a geraçăo de modelos que possam estimar o valor (numérico) de determinado atributo. Exemplos de algoritmos de estimativa săo: M5 e CART.
Vamos ao exemplo prático na ferramenta Weka. Utilizaremos o arquivo baskball.arrf, disponível no website da revista. Esse arquivo foi obtido do endereço http://prdownloads.sourceforge.net/weka/datasets-numeric.jar, que disponibiliza um jarfile contendo 37 problemas de regressăo. No website da ferramenta podem ser obtidos outros datasets de exemplo.
A tabela baskball contém dados de atletas de basquete. Os campos săo: assistęncia por minuto, altura, tempo em quadra, idade e pontos por minuto. A Listagem 2 mostra parte deste arquivo. O objetivo do exemplo é gerar um modelo para prever a altura de um determinado jogador tendo em măos as demais informaçőes.
@relation baskball
@attribute assists_per_minute real
@attribute height integer
@attribute time_played real
@attribute age integer
@attribute points_per_minute real
@data
0.0888,201,36.02,28,0.5885
0.1399,198,39.32,30,0.8291
0.1107,196,35.22,25,0.4799
0.2521,183,31.73,29,0.5735
0.1007,193,28.81,34,0.6318
0.1067,196,35.6,23,0.4326
...
Listagem 1.
Clique na aba Classify. O algoritmo utilizado será o M5P (figura 21), que é baseado na geraçăo de árvores de classificaçăo.
O próximo passo é escolher o atributo objetivo (altura do jogador); lembre-se que o objetivo da estimativa é prever o valor de atributos numéricos – portanto, o atributo objetivo deve ser numérico. Para isso, selecione o atributo de acordo com o destaque 1 da figura 21. Em seguida, clique em Start. O resultado pode ser visualizado no destaque 2 da figura 21.
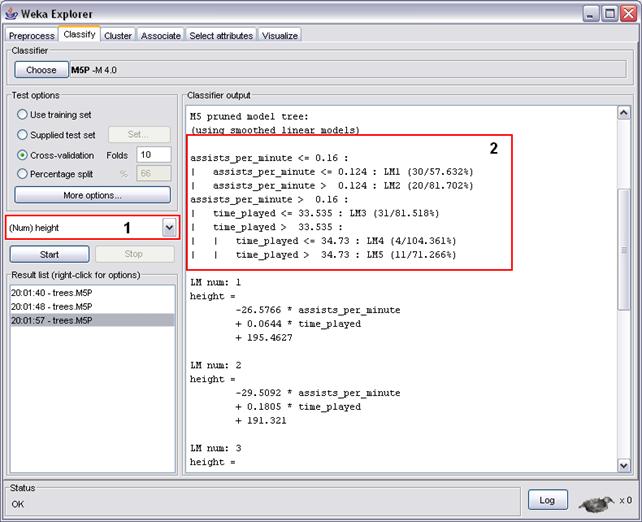
Figura 21
Para visualizar a árvore de decisăo clique com o botăo inverso do mouse sobre o item trees.M5P, gerado dentro do Result List, e selecione a opçăo Visualize Tree.
Para exemplificar, um jogador com as características assists-per-minute = 0,19 e time-played = 34 tem uma altura prevista de 1.88 (regra 4). A funçăo para a regra 4 é:
height = (-104.3935 * assists_per_minute) + (0.0352 * time_played) + 206.8226
Conclusăo
Neste artigo vimos que o crescente acúmulo de dados nas corporaçőes muitas vezes esconde informaçőes relevantes. Neste cenário, foram apresentados a importância da mineraçăo de dados e o processo (KDD) do qual ela faz parte. Por fim, foram vistas algumas técnicas de mineraçăo juntamente com exemplos didáticos e reais, facilitando assim o entendimento.
As técnicas apresentadas neste artigo săo as mais básicas no processo de data mining. Existem diversas ténicas mais complexas, tais como redes neurais, algoritmos genéticos, induçăo, deduçăo, entre outras. Contudo, os métodos apresentados neste texto săo os mais populares, e servem para resolver a maioria dos problemas primários de descoberta de conhecimento.
Espero que tenham gostado do assunto. Ele é bastante amplo e diversas áreas podem obter benefícios com seu uso. Até a próxima!
Referęncias
· A survey of data mining and knowledge discovery software tools - Michael Goebel and Le Gruenwald
· The Data Mining Industry Coming of Age – Gregory Piatetsky Shapiro – IEEE Intelligent Systems vol 14 – nov/dec 1999 – pg. 32-34
· Livro: Sistemas de Banco de Dados: Fundamentos e Aplicaçőes. Elmasri & Navathe.
· Livro: Sistemas Inteligentes: Fundamentos e Aplicaçőes. Solange de Oliveira Rezende.
· Livro: Data mining: técnicas e aplicaçőes para o marketing direto. Fernanda Cristina Naliato do Amaral.
· Livro: Data mining: Practical Machine Learning Tools and Techniques with java implementations. Ian H. Witten, Eibe Frank.
· Books on-line do SQL Server.
· Apostila de Data mining – Universidade Estadual Paulista.
· Investigaçăo de regressăo no processo de mineraçăo de dados. Daniel Gomes Dosualdo. Dissertaçăo de mestrado. USP – Săo Carlos.
· Visualizaçăo de Operaçőes de Junçăo em Sistemas de Bases de Dados para Mineraçăo de Dados. Maria Camila Nardini Barioni. Dissertaçăo de mestrado. USP – Săo Carlos.
· Computer Aided Mining – Marcelo A. Bittencourt. Dissertaçăo de mestrado. UFF – Universidade Federal Fluminense.
· Processo de extraçăo de conhecimento de bases de dados. Autores: Solange de Oliveira Rezende e Cláudio Alex Jorge da Rocha.
· http://www.cs.sfu.ca/~han/DM_Book.html
· http://www.cs.waikato.ac.nz/~ml/weka/index.html
· http://www.microsoft.com/technet/prodtechnol/sql/2000/maintain/dmperf.mspx
· http://www.ics.uci.edu/~mlearn
· http://www.the-data-mine.com
DOWNLOAD: www.sqlmagazine.com.br/sql10/download.asp







