Clique aqui para ler esse artigo em PDF.![]()

Clique aqui para ler todos os artigos desta ediçăo
Desnormalizaçăo: uma faca de dois gumes
por Eduardo Bezerra
Leitura Obrigatória: Artigos do Prof Bráulio - SQL Magazine 6 e 7.
Normalizar as tabelas de um banco de dados relacional tem como objetivo prevenir o aparecimento de certas dependęncias (dependęncias funcionais năo-triviais, parciais, transitivas, multivaloradas ou de junçăo) nesse banco de dados. O procedimento para se chegar a um banco de dados normalizado consiste em aplicar sucessivamente diversas transformaçőes sobre o esquema desse banco de dados de forma a obter um novo esquema onde as tabelas componentes estejam em conformidade com determinadas restriçőes pré-estabelecidas. Essas restriçőes estăo associadas ŕs denominadas formas normais.
Uma forma normal consiste em um conjunto de restriçőes que um esquema de banco de dados deve satisfazer para que se possa afirmar que tal esquema satisfaz ŕquela forma normal. Conforme detalhado nos artigos do Prof. Bráulio Ferreira (veja a SQL Magazine 6 e 7), existem diversas formas normais. Cada forma normal (ŕ exceçăo da primeira) engloba as restriçőes das formas normais anteriores e define restriçőes adicionais a serem satisfeitas pelo esquema do banco de dados.
Na prática, a normalizaçăo é realizada através da fragmentaçăo vertical de uma ou mais tabelas, ou seja, através da criaçăo de duas ou mais novas tabelas para conter colunas que anteriormente pertenciam a uma única tabela. Portanto, de uma forma geral, um esquema normalizado possui mais tabelas do que o seu esquema correspondente năo normalizado. A aplicaçăo da normalizaçăo a um esquema dá a certeza de que os dados armazenados segundo este esquema estarăo livres de diversas anomalias as quais está suscetível um esquema que năo esteja normalizado, como a repetiçăo (redundância) descontrolada de dados.
Podemos pensar na normalizaçăo como um estado (ou situaçăo) do banco de dados: se todas as tabelas desse banco estăo normalizadas, entăo o banco está normalizado. Nesse sentido, o estado inverso ŕ normalizaçăo é chamado de desnormalizaçăo, no qual uma ou mais tabelas do modelo lógico do banco de dados săo aglutinadas em uma única tabela do esquema relacional. A princípio, a única razăo para a aplicaçăo da desnormalizaçăo é a de eliminar o custo das junçőes em operaçőes de seleçăo sobre as tabelas envolvidas.
Uma análise superficial do parágrafo anterior pode levar o leitor a concluir que a desnormalizaçăo sempre aumenta o desempenho no processamento de consultas de seleçăo. O raciocínio (errôneo, como veremos a seguir) para essa conclusăo seria o seguinte: “se a quantidade de tabelas é maior em um esquema relacional normalizado, entăo haverá um maior número de operaçőes de junçăo para a obtençăo do resultado das consultas nesse esquema do que em um esquema desnormalizado correspondente (operaçőes de junçăo săo sabidamente bastante custosas do ponto de vista computacional). Conseqüentemente, o custo da execuçăo de seleçőes em um esquema normalizado é sempre maior do que o custo sobre o esquema desnormalizado correspondente”.
Para argumentar a razăo de o raciocínio anterior constituir uma falácia, me permitam considerar algumas situaçőes fora do contexto de bancos de dados:
· Ontem houve greve de ônibus no Rio de Janeiro. Fui para o trabalho de carro. A princípio, o que era de se esperar era que eu chegasse mais cedo ao trabalho (afinal de contas, a quantidade de ônibus nas ruas era menor). Acabei por chegar mais tarde. O fato é que, justamente por conta da falta de ônibus, a quantidade de carros de passeio nas ruas aumentou tanto que o trânsito ficou ainda mais caótico do que o usual.
· A princípio, pode-se pensar que o aumento dos downloads de músicas pela Internet é o principal fator para a queda de venda de CDs. No entanto, um estudo realizado por economistas norte-americanos revela que baixar músicas de um CD năo afeta significativamente suas vendas. Segundo o estudo, outros fatores parecem ser a verdadeira causa da queda de vendas: competiçăo com outras mídias (DVDs e vídeo games); reduçăo do número de discos lançados; boicote dos consumidores contra a indústria fonográfica; crescimento exagerado das vendas de CDs nos anos noventa, quando o uso de CDs em vez de LPs, estava começando a deslanchar; etc.
O leitor pode vir a se perguntar o que as situaçőes acima tęm a ver com o conceito de desnormalizaçăo. O fato é que o mesmo tipo de raciocínio menos cuidadoso que pode levar a conclusőes errôneas (assim como nas situaçőes acima) é utilizado na desnormalizaçăo. Na verdade, as variáveis com as quais o desenvolvedor encarregado de escolher entre a normalizaçăo e a desnormalizaçăo tem que lidar săo numerosas. Analisada mais detalhadamente, a situaçăo é mais complicada do que parece, e năo necessariamente o processamento sobre uma tabela desnormalizada será sempre mais eficiente do que sobre um esquema equivalente normalizado.
O objetivo desse artigo é mostrar que, embora existam casos em que a desnormalizaçăo se justifica, há algumas situaçőes em que a desnormalizaçăo traz um aumento no tempo de processamento, além de outras desvantagens. Nas demais seçőes deste artigo, tento lançar luz sobre diversas questőes relacionadas ŕ desnormalizaçăo.
Exemplo de tabela desnormalizada
Para exemplificar os argumentos das seçőes seguintes, vamos considerar a tabela denominada Locaçőes, apresentada na Listagem 1. Essa tabela apresenta informaçőes sobre carros de uma locadora de veículos, além de informaçőes sobre os locatários desses carros e das locaçőes realizadas.
Locaçőes( placa_carro,
licença_locatário,
nome_locatário,
endereço_locatário,
modelo_carro,
cnpj_fabricante_carro,
razăo_social_fabricante_carro,
qtd_km_rodados_total,
qtd_km_rodados_por_locatário,
data_início_locaçăo,
data_término_locaçăo )
Listagem 1.
Essa tabela está claramente desnormalizada. Para entender o porquę disso, considere a existęncia das seguintes dependęncias funcionais (entre outras):
· cnpj_fabricante_carro ŕ razăo_social_fabricante_carro (dependęncia transitiva da chave primária; violaçăo da 3FN)
· licença_locatário ŕ nome_locatário (dependęncia parcial da chave primária; violaçăo da 2FN)
Em uma tabela desse tipo (desnormalizada) algumas de suas colunas (năo componentes da chave) năo dependerăo única e exclusivamente da chave primária. De acordo com Fabian Pascal (veja Nota), essa característica leva a possíveis dependęncias:
1. Uma ou mais colunas dependem somente de uma parte da chave (composta), o que corresponde ŕ violaçăo da 2FN.
2. Dependęncia indireta da chave. Isto é, uma ou mais colunas dependem de outra coluna (năo chave) que por sua vez depende da chave. Isso corresponde ŕ violaçăo da 2FN.
3. Dependęncias multivaloradas dentro da chave da tabela. Isso corresponde ŕ violaçăo da 4FN.
4. Dependęncias de junçăo dentro da chave primária, o que corresponde ŕ violaçăo da 5FN.
Nota
Fabian Pascal é um especialista em bancos de dados relacionais de opiniőes um tanto polęmicas e declaraçőes (um outro tanto) ríspidas, mas que merecem a atençăo de qualquer profissional que trabalhe com SGBDs. Visite www.dbdebunkings.com.
Projeto lógico versus projeto físico
Um aspecto polęmico envolvendo a normalizaçăo e a desnormalizaçăo é a confusăo entre os projetos lógico e físico de um banco de dados. A confusăo típica é que “normalizaçăo degrada o desempenho do banco de dados”. Até especialistas da área de bancos de dados mundialmente conhecidos, como Joe Celko, tęm opiniőes controversas sobre o assunto (veja Nota).
Nota
"The reason for denormalization is performance." (Traduçăo: “A razăo para desnormalizaçăo é o desempenho”). Essa frase aparece na página 44 do livro intitulado SQL for Smarties (Autor: Joe Celko; Editora: Morgan Kaufmann).
A normalizaçăo é uma atividade típica do projeto lógico de um banco de dados. Nessa etapa do projeto de um banco de dados, um modelo conceitual (e.g., o modelo de entidades e relacionamentos) é mapeado para um modelo lógico (e.g., o modelo relacional).
Já os aspectos relativos ao desempenho devem ser tratados na etapa posterior ao projeto lógico, denominada projeto físico do banco de dados. É no projeto físico que questőes que influenciam no desempenho devem ser consideradas (como métodos de armazenamento e acesso, definiçőes de índices sobre as tabelas envolvidas, características do hardware utilizado, a freqüęncia de execuçăo das operaçőes de consulta e de manipulaçăo envolvidas, detalhes de implementaçăo do SGBD sendo utilizado, grau de acesso concorrente a disco, etc.).
Mesmo sem considerar a confusăo entre os projetos lógico e físico, a desnormalizaçăo ainda năo garante um melhor desempenho sobre operaçőes em um banco de dados, conforme veremos nas duas seçőes seguintes.
Consulta versus manipulaçăo
Voltando ŕ questăo das junçőes levantada anteriormente e analisando o problema mais detalhadamente, podemos constatar que a sobrecarga de processamento necessária para manter a integridade dos dados (através da definiçăo de gatilhos, por exemplo) pode năo compensar o ganho de desempenho obtido com a desnormalizaçăo. De fato, a manutençăo da integridade pode necessitar das mesmas operaçőes de junçăo que a desnormalizaçăo se propunha a eliminar!
Para exemplificar, vamos considerar a tabela Locaçőes. Para obter informaçőes sobre locaçőes, locatários e carros utilizados, a utilizaçăo dessa tabela desnormalizada realmente produz uma execuçăo mais eficiente. Afinal de contas todos os dados necessários estăo armazenados em uma única tabela, o que normalmente leva o SGBD a posicionar essas informaçőes em blocos de disco contíguos.
No entanto, o que acontece quando um novo registro deve ser adicionado ŕ tabela Locaçőes? Uma das operaçőes que devem ser realizadas para garantir que os dados permaneçam consistentes é atualizar a quantidade total de quilômetros rodados pelo carro (coluna qtd_km_rodados_total). Para isso, todos os valores dos campos de qtd_km_rodados_total deverăo ser atualizados para os registros que possuírem valores de placa do carro e de licença do locatário semelhantes ao registro recém incluído. Deixo como exercício para o leitor verificar que há também problemas quando da exclusăo e da atualizaçăo de registros nessa tabela. Todos esses problemas provenientes da sua desnormalizaçăo!
A conclusăo é que, se por um lado a desnormalizaçăo tornou a obtençăo de informaçőes na tabela em questăo mais eficiente, por outro lado o desempenho das operaçőes de manipulaçăo (inserçăo, remoçăo e atualizaçăo) fica comprometido. De uma forma geral, um dos aspectos que pesam contra a desnormalizaçăo é a questăo da consistęncia (ou integridade) dos dados. Um benefício eventual obtido pela desnormalizaçăo (aumento do desempenho em uma determinada consulta de seleçăo) tem seu preço: uma tabela desnormalizada fica vulnerável ao surgimento de anomalias quando manipulaçőes săo realizadas sobre ela, e a integridade dos dados fica ameaçada.
Consulta versus consulta
A seçăo anterior descreve a polęmica mais óbvia em relaçăo ŕ escolha entre normalizaçăo e desnormalizaçăo (eficięncia em consultas versus manutençăo de integridade dos dados). No entanto, a sobrecarga necessária para manutençăo da integridade dos dados năo é o único fator a considerar quando o desenvolvedor estiver pensando em desnormalizar um esquema. Há um outro aspecto menos óbvio.
Considere novamente os dados da tabela Locaçőes. Essa tabela armazena dados sobre tręs conceitos distintos: carros, locatários e as próprias locaçőes. O que acontece quando aplicaçőes de bancos de dados precisam obter acesso a esses dados separadamente?
Por exemplo, digamos que o departamento de marketing da locadora precisa enviar uma mala direta para as pessoas que já alugaram carros. Provavelmente, essa tarefa envolveria uma consulta sobre a tabela Locaçőes, para resgatar somente os dados relativos a clientes (nome_locatário e endereço_locatário). Como esses dados estăo em uma tabela que possui diversas outras colunas năo relacionadas a clientes, a quantidade de informaçőes sobre clientes por bloco de disco será menor do que se houvesse uma tabela armazenando somente dados sobre clientes. Conseqüentemente, o SGBD levará mais tempo para resgatar os dados necessários para montar a mala direta ao utilizar a tabela desnormalizada Locaçőes. Perceba que esse ponto acaba indo de encontro ao citado anteriormente neste artigo. Ou seja, um dos benefícios da desnormalizaçăo (a reduçăo na quantidade de junçőes) acaba sendo prejudicado em situaçőes específicas.
De uma forma geral, se for tomada a decisăo de aglutinar dados de duas ou mais tabelas em uma única tabela (ou seja, desnormalizar), as aplicaçőes que necessitam ter acesso aos dados que do contrário estariam em uma tabela separada terăo agora que ler desnecessariamente outras informaçőes. E a leitura dessas outras informaçőes desnecessárias aumenta o tempo de processamento das consultas de seleçăo.
Note que essa situaçăo de diferentes aplicaçőes acessarem diferentes informaçőes é típica em um banco de dados corporativos. O fato é que a desnormalizaçăo que resultou na tabela Locaçőes fez com que o seu esquema relacional ficasse apropriado para uma determinada aplicaçăo (consultas envolvendo dados sobre locatários, carros e locaçőes simultaneamente). Mas e as outras aplicaçőes que acessam o mesmo banco de dados e tęm necessidades de informaçőes diferentes? A resposta é que o desempenho dessas aplicaçőes fica prejudicado pelo fato delas terem que acessar dados que simplesmente năo as interessam. Isso para năo mencionar as necessidades de aplicaçőes que sejam construídas no futuro.
Uma açăo aconselhável é que o desenvolvedor estude as funcionalidades específicas do SGBD que irá utilizar (mais particularmente, as características relativas ao projeto físico de bancos de dados). Provavelmente, haverá alguma funcionalidade que aumente o desempenho de uma determinada consulta sem que seja necessário o uso da desnormalizaçăo.
A normalizaçăo também năo é uma panacéia
Apesar de tudo que foi descrito nas seçőes anteriores, algumas vezes a violaçăo das regras da normalizaçăo se faz útil. A idéia geral da normalizaçăo é que o desenvolvedor de um banco de dados aplique as regras das formas normais até “as últimas conseqüęncias”, ou seja, até a quinta forma normal. Entretanto, de acordo com Chris Date, está idéia năo deve ser tomada como lei. Um banco de dados completamente normalizado muitas vezes contém tantos grupos de dados (domínios de valores) fragmentados que dificultam por demais a tarefa de obtençăo de informaçőes.
Qualquer um envolvido no desenvolvimento de um banco de dados deve ter conhecimento da técnica de normalizaçăo. No entanto, o desenvolvimento do banco năo deve necessariamente se basear somente nessa técnica. Violar as regras da normalizaçăo de forma consciente e cuidadosa é aceitável, mas isso somente deve ser feito quando os benefícios da mudança justificam a violaçăo da(s) regra(s). Abaixo cito dois casos, um em que a desnormalizaçăo pode ser evitada e outro em que ela pode ser aplicada.
· Um primeiro exemplo é o caso das desnormalizaçőes criadas por motivos históricos, e das desnormalizaçőes criadas para geraçăo de relatórios específicos. Nesse caso, a desnormalizaçăo pode ser evitada através do uso da desnormalizaçăo virtual. Uma desnormalizaçăo virtual é aquela criada através de visőes (views). Ou seja, poder-se-iam construir diversas visőes sobre a(s) tabela(s) desnormalizada(s), onde cada visăo seria utilizada por uma determinada aplicaçăo. No entanto, há que se considerar o outro lado da moeda (ou gume da faca!): o que um SGBD normalmente faz quando uma visăo é solicitada é executar uma consulta – ou seja, de qualquer modo, a consulta sobre a tabela desnormalizada teria de ser executada. Por outro lado, há SGBDs que trabalham com a materializaçăo de visőes. Ou seja, os dados da visăo ficam armazenados (o Oracle e o SQL Server 2000, por exemplo, possuem esse recurso). A vantagem é ter o resultado pré-computado quando for necessário; contudo, a visăo será atualizada toda vez que ocorrerem alteraçőes nos dados da(s) tabela(s) envolvidas.
· Como um segundo exemplo, considere duas tabelas, Produtos e GrupoProdutos, uma que armazena produtos e outra que armazena grupos de produtos. Considere também que há um relacionamento um-para-muitos entre Produtos e GrupoProdutos. Considere mais ainda que o campo nome em GrupoProdutos é chave candidata. O diagrama da Figura 1 ilustra duas alternativas de projeto para essas duas tabelas. Na primeira alternativa, segue-se o projeto clássico. Já na segunda alternativa, o nome do grupo de produtos é adicionado ŕ tabela Produtos, originando uma desnormalizaçăo nessa tabela. Além disso, esse campo agora é o utilizado como chave estrangeira. Note que o tamanho de cada um dos registros da tabela Produto aumenta em relaçăo ŕ primeira alternativa (pois o nome do produto é do tipo CHAR(20), que ocupa mais espaço que INTEGER), o que faz com que menos registros por bloco sejam trazidos do disco para a memória principal. Por outro lado, essa desnormalizaçăo faz com que a informaçăo de nome do grupo de cada produto esteja presente em cada linha da tabela Produtos. Esse exemplo ilustra o fato de que algumas vezes a repetiçăo de um campo em uma tabela (ou seja, desnormalizaçăo) pode economizar uma junçăo e causar efeitos colaterais negativos irrelevantes (nesse exemplo, o pouco esforço de atualizaçăo), sobretudo se o campo em questăo for de pouca mutabilidade. Em particular, se a informaçăo de nome do grupo de produtos for sempre necessária quando um produto for requisitado, talvez a segunda alternativa seja a melhor, pois isso elimina o custo de junçăo entre as duas tabelas.
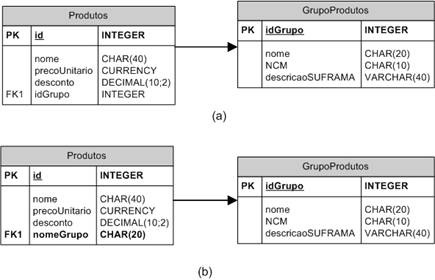
Figura 1.
Conclusőes
Talvez a razăo de haver uma guerra religiosa acerca da normalizaçăo e da desnormalizaçăo seja o fato de năo haver uma resposta óbvia para a pergunta: quais săo as conseqüęncias de utilizar uma tabela desnormalizada? A normalizaçăo e a desnormalizaçăo săo estados antagônicos de um banco de dados que năo podem ser conciliados facilmente.
Nesse artigo, descrevi situaçőes em que o uso de uma tabela desnormalizada traz prejuízos em vez de ganhos para o desempenho geral de um esquema relacional. O fato é que há dois gumes da faca, tanto para a desnormalizaçăo, quanto para a normalizaçăo. Aconselho um estudo detalhado e pontual de todos os fatores envolvidos no projeto do banco de dados. Somente se todos esses fatores forem cuidadosamente estudados, e se todas as alternativas relativas ao projeto físico forem consideradas, é que o desenvolvedor terá em măos as informaçőes suficientes para optar por violar ou năo as regras da normalizaçăo.
Por fim, o que posso dizer para resumir esse artigo é que a desnormalizaçăo năo é um monstro que deve ser expulso para os confins do mundo dos bancos de dados. Mas, a cada vez que vocę desnormaliza seu banco de dados, vocę paga um preço, que pode ser em perda de flexibilidade e manutenibilidade, em perda de integridade dos dados, ou mesmo em perda de desempenho.
Para Saber Mais
Existe um vasto material sobre o assunto “normalizaçăo versus desnormalizaçăo” disponível na Web. Abaixo, cito alguns endereços que podem servir como fonte adicional de estudo sobre o assunto.
· DENORMALIZATION AND THE RULES OF RECONSTRUCTION: http://www.tdan.com/i014ht04.htm
· Responsible Denormalization
http://www.winnetmag.com/SQLServer/Article/ArticleID/9785/9785.html
· DENORMALIZATION FOR PERFORMANCE - ET TU ACADEMIA? http://www.dbdebunk.citymax.com/page/page/622733.htm
· Denormalization, Database normalization and Performance - Hidden dangers: http://www.databasedesign-resource.com/denormalization.html
· Pattern: Denormalization (http://www.objectarchitects.de/ObjectArchitects/orpatterns/Performance/Denormalization/)
· Responsible Denormalization, Michelle A. Poolet, http://www.winnetmag.com/Articles/Index.cfm?ArticleID=9785







