Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.

Clique aqui para ler todos os artigos desta ediçăo
Dicas de modelagem de dados
A grande maioria dos desenvolvedores, mesmo năo desempenhando formalmente o papel de DBA ou Analista de Dados, normalmente encontra-se envolvido com situaçőes de modelagem de dados. Neste sentido, com o intuito de auxiliar o trabalho destes desenvolvedores, este artigo apresenta um conjunto bastante abrangente de dicas de modelagem.
Muitos dos problemas encontrados após a implementaçăo de um banco de dados tęm sua origem em uma modelagem de dados feita sem uma análise mais profunda do escopo do projeto. Outro fator que colabora para uma má modelagem é o desconhecimento de técnicas como a normalizaçăo e desnormalizaçăo de tabelas, bem como a năo adoçăo de integridade referencial, que auxiliam na definiçăo mais ajustada do modelo ŕ realidade que irá atender.
Agora vamos ŕs dicas!
Modelagem de dados: projeto conceitual
1. Sempre faça modelagem de dados, isso ajuda no entendimento do problema e no planejamento de uma soluçăo mais aderente aos seus objetivos. O objetivo do modelo conceitual é a definiçăo do problema, năo da soluçăo.
2. Existem diferentes terminologias para modelagem conceitual. Os exemplos da Figura 1 representam diferentes notaçőes para um relacionamento 1:N, sendo as mais comuns de serem implementadas pelas atuais ferramentas CASE. A primeira notaçăo, de Peter Chen, é a mais utilizada para a construçăo do modelo conceitual enquanto a segunda, do Pé de Galinha, é a mais utilizada para a construçăo do modelo lógico.
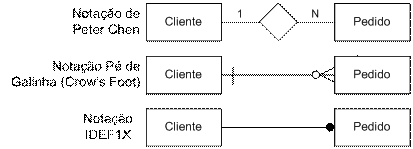
Figura 1. Notaçőes para modelagem de dados.
3. Elimine qualquer redundância de dados. Redundâncias permitidas săo aquelas relativas a chaves estrangeiras, que fazem referęncia ŕ chave primária de outra tabela. Por exemplo, năo se deve repetir o nome do cliente em seus pedidos, pois ele pode ser facilmente obtido através do relacionamento.
4. Utilize um padrăo para dar nomes a entidades. Normalmente, nomes de entidades săo no singular.
5. Dę nomes significativos a entidades, atributos e relacionamentos. Nomes que năo representam seu real objetivo dificultam a compreensăo do modelo.
6. Deve-se determinar os relacionamentos e, decidir como é a relaçăo de dependęncia entre cada entidade é sempre importante. Os tipos de relacionamento podem ser:
· 0:1 (mínimo: nenhum – máximo: um);
· 0:N (mínimo: nenhum – máximo: muitos);
· 1:1 (mínimo: um – máximo: um);
· 1:N (mínimo: um – máximo; muitos);
· N:N (mínimo: muitos – máximo: muitos).
7. Relacionamentos năo obrigatoriamente precisam ter nomes, mas é uma boa prática de modelagem nomeá-los, pois facilita o entendimento. Assim, utilize nomes significativos para os relacionamentos, como apresentado na Figura 2 para o relacionamento Lotaçăo.

Figura 2. Nomeando relacionamentos.
8. Relacionamentos N:N ou que possuem atributos normalmente geram novas tabelas no modelo lógico. O nome do relacionamento pode ser utilizado como nome da tabela e deve ser cuidadosamente escolhido, como exemplificado na Figura 3.

Figura 3. Gerando tabelas a partir de relacionamentos.
9. Ao dar nomes a atributos determinantes, coloque sempre algo que identifique a entidade que está sendo relacionada. Por exemplo, um atributo chave cod_cliente é melhor do que simplesmente código. Lembre-se que, no modelo lógico, este atributo será repetido como chave estrangeira nas entidades relacionadas. Percebe-se na Figura 4 que, se o nome da chave primária da entidade Cliente for apenas codigo, quando repetida na entidade Pedido para representar o relacionamento, seu nome năo será representativo, ou seja, năo se pode observar facilmente a qual entidade está associado. Se o atributo tivesse sido chamado de cod_cliente, esta associaçăo seria muito mais fácil. Este problema seria mais grave se a entidade Pedido estivesse associada ŕ outra cujo nome de sua chave primária também fosse codigo. Teríamos mais de um atributo com o mesmo nome, que as ferramentas CASE costumam modificar atribuindo uma seqüęncia numérica, o que dificulta enormemente a compreensăo do modelo.

Figura 4. Nomeando atributos chave.
10. Procure padronizar os nomes dos atributos de seu diagrama entidade relacionamento. Por exemplo, ao ver o atributo num_pedido percebe-se facilmente que seu tipo é numérico. A padronizaçăo garante um bom entendimento dos atributos perante a equipe de desenvolvimento, garantindo eficięncia na fase de desenvolvimento da aplicaçăo.
11. Atençăo para entidades desconectadas no diagrama. Podem năo ser um problema, mas precisam ser verificadas. Por exemplo, é comum que entidades que representem parâmetros estejam soltas no diagrama.
12. Cuidado com relacionamentos com participaçăo total em ambos os lados de um relacionamento (obrigatoriedade dos dois lados). Isso pode provocar uma situaçăo onde uma entidade dependa da outra recursivamente. Além disso, deve-se estar atentos a situaçőes onde o banco de dados ainda está vazio e precisa-se cadastrar registros em apenas uma das entidades. Observe o exemplo abaixo da Figura 5. Um Cliente possui um ou mais Pedidos e um Pedido é obrigatoriamente de um Cliente. Devido ŕ obrigatoriedade em ambos os lados do relacionamento, esta situaçăo impede que Clientes sejam cadastrados sem Pedidos e que Pedidos sejam feitos sem Clientes.

Figura 5. Relacionamento com participaçăo total em ambos os lados.
Modelagem de dados: projeto lógico
13. Muitas vezes costuma-se “pular” a etapa de modelo conceitual de dados e passa-se diretamente para o modelo lógico. Em grande parte pode-se creditar isso a muitas ferramentas CASE, que partem diretamente do modelo lógico. Considera-se isso perigoso. A modelagem conceitual foi criada para atender ŕs necessidades do usuário, sem limitaçőes tecnológicas. Desta forma, no primeiro modelo, năo se deve preocupar com chaves primárias e estrangeiras. As chaves săo necessárias uma vez que é assim que os SGBDs trabalham, mas isso năo faz parte das necessidades do usuário. O mesmo pode ser dito com relaçăo ao tipo e tamanho de dados, e ainda mais do mapeamento de relacionamentos 1:1 e n:n. O objetivo do projeto lógico é a definiçăo da soluçăo.
14. Vale lembrar que nem todo modelo lógico de dados é a cópia fiel do modelo conceitual de dados.
15. Toda entidade do modelo conceitual vira uma tabela no modelo lógico.
16. Deve-se relacionar diretamente cada coluna ao escopo da tabela: se um campo descreve o assunto de uma tabela diferente, este campo deve pertencer ŕ outra tabela.
17. Elimine colunas repetidas no modelo: se uma informaçăo se repete em diversas tabelas, é um indício de que existem colunas desnecessárias. Deve-se buscar a tabela que faça mais sentido para conter a coluna em questăo.
18. Dimensione corretamente os tipos de dados em funçăo de seus conteúdos para diminuir o espaço de armazenamento.
19. Campos de texto com tamanho variável tendem a consumir menos espaço de armazenamento.
20. Defina corretamente a obrigatoriedade para atributos das entidades de forma a retratar o objetivo da entidade. Por exemplo, o nome do cliente deve ser obrigatório, pois năo faz sentido cadastrar um cliente sem seu nome. Muitas vezes, preocupa-se apenas com a obrigatoriedade para os atributos chave, mas esta questăo é importante para todos os atributos, tomando-se o devido cuidado de năo impor restriçőes demais que impeçam que novos registros possam ser inseridos.
21. Elimine atributos derivados ou calculados: năo é recomendado armazenar o resultado de cálculos nas tabelas. O correto é que o cálculo seja gerado sob demanda, normalmente em uma consulta.
22. Toda tabela deve ter uma chave primária, que pode ser simples ou composta. A chave primária é o identificador do registro e deve ser única dentro de uma tabela.
23. Ao determinar a chave primária, deve-se escolher, em cada tabela, quais colunas formarăo a chave primária. Para uma coluna ser candidata ŕ chave primária, deverá atender aos principais requisitos:
· Deverá ser a menor possível;
· O seu valor deverá ser diferente de vazio ou zero (not null);
· Deverá ser de preferęncia numérica;
· O seu valor deverá ser único para toda a tabela.
24. Chaves estrangeiras devem corresponder a chaves primárias da relaçăo associada ou ser nulas, quando năo for um campo obrigatório.
25. Crie chaves cegas (Blind Key) toda vez que năo for possível identificar a chave primária, ou quando esta for muito complexa, composta por muitos atributos. Esses tipos de atributos geralmente săo conhecidos por atributos falsos, ou seja, năo fazem parte de forma explícita da regra de negócio, porém foram criados para garantir flexibilidade ou integridade ao modelo de dados desenvolvido. Por exemplo, um funcionário pode ter diversos dependentes, que possuem nome e data de nascimento. Nenhum destes atributos, nem mesmo a concatenaçăo deles, garante uma chave primária única. Uma soluçăo é a criaçăo de um novo atributo determinante, como cod_dependente.
26. Refine os relacionamentos uma vez que alguns destes poderăo gerar novos elementos que complementarăo o modelo, sendo estes:
· Relaçăo de Herança (mutuamente exclusivo ou năo): por exemplo, numa hierarquia de Funcionario contendo especializaçőes Gerente e Engenheiro, um determinado funcionário pode ser Gerente e Engenheiro ao mesmo tempo?;
· Entidade Associativa: gerada quando informaçőes que necessitam ser armazenadas năo podem ser colocadas numa das entidades do relacionamento. Acontece em situaçőes de relacionamentos com atributos ou relacionamentos N:N.
...







