
Algoritmo do Orkut, Oráculo de Bacon, Número de Erdös e outras histórias
Rodrigo Hjort
Leitura obrigatória: “Árvores em PL/pgSQL: Recursividade em busca hierárquica”, Ediçăo 35 da SQL Magazine
Que analista de sistemas nunca se viu imaginando como funcionariam os algoritmos de busca para a classificaçăo de páginas no Google ou como seriam obtidas as ligaçőes entre indivíduos em sites de relacionamento como o Orkut? Ou melhor: como seriam feitas as modelagens de dados para essas aplicaçőes, se é que um SGBD relacional poderia ser usado? Os algoritmos teriam que ficar na camada de aplicativo ou de banco de dados? E quantos acadęmicos já se perguntaram “onde é que eu vou usar Teoria dos Grafos no dia-a-dia”? A análise a seguir tentará responder sucintamente essas questőes, que aparentemente năo săo nada triviais.
Neste artigo será implementado no PostgreSQL um algoritmo de busca em largura em estruturas com relacionamento recursivo. Para isso, serăo utilizados conceitos de Teoria dos Grafos aplicados com a construçăo de funçőes nas linguagens procedurais PL/pgSQL e SQL associadas a triggers e arrays.
A Figura 1 exemplifica o tipo de relacionamento tratado na análise. Numa rede social (ver Nota 1), cada nó representa um indivíduo, que por sua vez relaciona-se a um ou mais outros nós. Neste caso, Jack Nicholson seria o mais “popular”, pois está ligado, ou seja, relaciona-se, a outras seis pessoas. Em oposiçăo, Angelina Jolie, Cameron Diaz e Kim Basinger săo as que menos relaçőes possuem: uma cada.
Nota 1. Definiçăo de rede social.
Rede social é uma das formas de representaçăo dos relacionamentos afetivos ou profissionais dos seres humanos entre si ou entre seus agrupamentos de interesses mútuos.
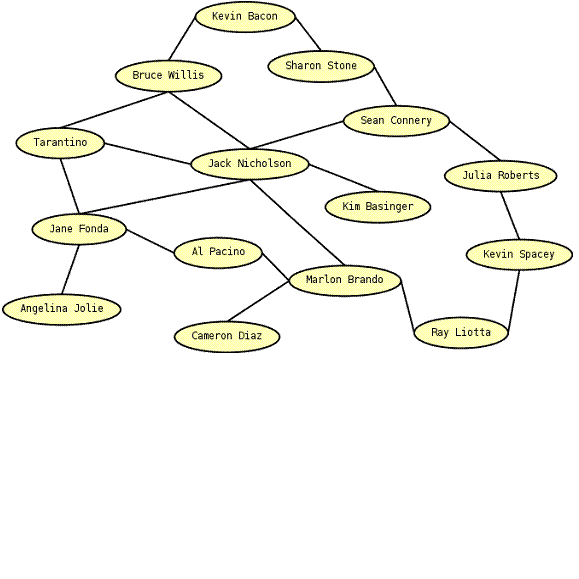
Figura 1. Estrutura de uma rede social: relacionamento entre indivíduos.
As instruçőes SQL contidas neste artigo foram executadas utilizando a ferramenta pgAdmin III (www.pgadmin.org), que já vem instalada com o PostgreSQL 8.1 no Windows e é facilmente instalada no Linux, FreeBSD ou Mac OS X. Além disso, estas instruçőes funcionam em qualquer aplicativo cliente do PostgreSQL, como psql, phpPgAdmin ou PgAccess, e em qualquer plataforma. Portanto, use a ferramenta que achar mais conveniente.
Um overview das aplicaçőes
No início de 2004 o Google, que sempre trouxe inovaçőes tecnológicas ao mundo da Internet, lançou uma nova onda na grande rede: os sites de relacionamento. Na realidade, já existiam diversos produtos semelhantes, como Friendster, Tribe e LinkedIn. Porém, o Orkut, criado por um funcionário do Google, um engenheiro turco chamado Orkut Büyükkokten, foi o que ganhou a maior popularidade, especialmente entre os usuários brasileiros.
Quem já visitou o serviço Orkut deve ter notado que, ao abrir o perfil de uma pessoa ainda năo pertencente ŕ sua rede, o sistema traz alguns possíveis mapeamentos para relacionar o indivíduo selecionado ao usuário atual. Por exemplo, é mostrado o seguinte texto: Fulano > Beltrano > Sicrano > Vocę. Foi baseada nesta idéia, a Teoria dos Seis Graus de Separaçăo, que o Orkut foi desenvolvido. Sucintamente, esta teoria diz que todas as pessoas no mundo podem ser conectadas a qualquer outra por uma rede de no máximo cinco intermediários. Apesar de ser provado que ela estava errada, alguns estudiosos afirmam que essa teoria pode ajudar a esclarecer diversos fenômenos, como epidemias, modas culturais, comportamento dos mercados de açőes e organizaçőes que sobrevivem a mudanças.
Um segundo exemplo de aplicaçăo para redes sociais é abordado no The Oracle of Bacon. O jogo, criado por um cientista da computaçăo nos EUA, mostra como um ator, no caso Kevin Bacon, se relaciona com os demais artistas, sejam de filmes norte-americanos ou năo. Alimentado periodicamente com informaçőes provenientes do portal IMDB (Internet Movie Database), quando o usuário digita o nome de um determinado artista, o sistema faz um mapeamento entre ele e Kevin Bacon, exibindo os filmes em que tiveram participaçăo juntos. Na Nota 2 é apresentado o resultado quando a atriz Audrey Tautou é especificada. Note que o sistema também informa o “Número de Bacon” do indivíduo, o qual se refere ao número de ligaçőes entre os dois artistas.
Nota 2. Exemplo de resultado exibido no The Oracle of Bacon
Audrey Tautou has a Bacon number of 2.
Audrey Tautou was in Da Vinci Code, The (2006) with Tom Hanks
Tom Hanks was in Apollo 13 (1995) with Kevin Bacon
Para finalizar os exemplos, podemos citar o Erdös Number Project, um projeto que tem como objetivo estudar a colaboraçăo nos trabalhos de pesquisa entre os cientistas. Na realidade, os “números de Erdös” sempre fizeram parte da cultura dos matemáticos contemporâneos. Paul Erdös (1913-1996), um dos maiores matemáticos do século passado, nasceu na Hungria e viajou o mundo escrevendo centenas de trabalhos nas mais diversas áreas do conhecimento, e muitos deles em colaboraçăo com outros pesquisadores. Seu número de Erdös é 0. Os seus co-autores tęm número de Erdös 1. Outras pessoas que publicaram algum trabalho em conjunto com pessoas que possuem número de Erdös 1, mas năo com o próprio Erdös, possuem número de Erdös 2, e assim por diante. Se uma pessoa năo possui ligaçăo de co-autoria com Erdös, mesmo que de forma indireta, seu número de Erdös é dito infinito. Na Tabela 1 estăo alguns exemplos de vencedores de pręmios Nobel e seus respectivos números de Erdös.
|
Nome |
Ano |
Área |
# Erdös |
|
Albert Einstein |
1921 |
Física |
2 |
|
Niels Bohr |
1922 |
Física |
5 |
|
Louis de Broglie |
1925 |
Física |
5 |
|
Erwin Schrödinger |
1933 |
Física |
8 |
|
Enrico Fermi |
1938 |
Física |
3 |
|
Theodor Hansch |
2005 |
Física |
5 |
|
John Nash |
1994 |
Economia |
4 |
|
Linus Pauling |
1954 |
Química |
4 |
|
Francis Crick |
1962 |
Medicina |
5 |
Tabela 1. Alguns vencedores de pręmios Nobel e seus respectivos números de Erdös.
Agora que o tema da análise foi proposto, mostraremos um estudo de caso na seçăo a seguir.
Primeiro estudo de caso: redes sociais
Com um olhar de analista de sistemas especialista em modelagem de dados, imaginamos como poderíamos representar as informaçőes no diagrama da Figura 1 em um banco de dados relacional. A entidade que representa uma pessoa seria a tabela PERFIS. Como cada pessoa pode ter uma relaçăo mútua com uma outra ou diversas outras pessoas, precisamos também de uma tabela associativa, a RELACOES. A Figura 2 ilustra o diagrama entidade-relacionamento em questăo. Trata-se de um relacionamento recursivo do tipo rede (ver Nota 3).
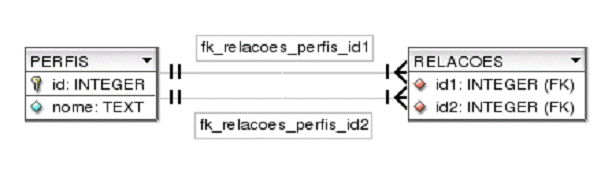
Figura 2. Modelagem: tabela de perfis com relacionamento recursivo do tipo rede.
Nota 3. Resumo sobre relacionamentos recursivos
Um relacionamento recursivo acontece quando uma entidade refere-se a si mesma, e é ilustrado no caso em que uma empresa pode pertencer a outra. Neste tipo de relacionamento, a entidade (ou tabela) pai e a filho săo a mesma. Existem duas variaçőes de relacionamento recursivo:
· Hierárquico (recursăo unitária). Neste tipo de relacionamento, uma entidade (ou tabela) pai pode ter qualquer número de filhos, mas cada filho pode ter um único pai. Exemplo: empregado que possui um supervisor, que por sua vez será outro empregado e que terá diversos subordinados. Esse exemplo de relacionamento foi abordado no artigo “Árvores em PL/pgSQL” publicado na ediçăo 35 da SQL Magazine.
· Em rede (recursăo dupla). Neste tipo de relacionamento, uma entidade (ou tabela) pai pode ter qualquer número de filhos, e um filho pode ter diversos pais. Exemplo: rede de relacionamentos, onde uma pessoa pode conhecer uma ou mais outras pessoas.
Em uma recursăo do tipo rede, a tabela possui um relacionamento muitos-para-muitos consigo própria. Neste caso, o SGBD necessita de uma tabela intermediária, que faz com que este relacionamento desdobre-se em relacionamentos do tipo um-para-muitos. Assim, esta segunda tabela conterá duas chaves estrangeiras que apontam para a tabela original.
A Figura 3 apresenta o código SQL para a criaçăo das tabelas e respectivos relacionamentos (em PostgreSQL) conforme ilustrado na Figura 2. Vide Nota 4 para execuçăo das instruçőes SQL na ferramenta pgAdmin. Perceba algumas peculiaridades neste script: na tabela RELACOES, existe uma constraint do tipo CHECK que impede que uma pessoa seja relacionada a ela mesma (id1 <> id2). Além disso, na criaçăo das chaves estrangeiras (uma para cada apontamento de RELACOES para PERFIS), foi adicionada a cláusula ON DELETE CASCADE. Com essa regra pertencente ao padrăo ANSI, e muitas vezes esquecida, a exclusăo de um perfil faz com que todas as relaçőes em que ele seja participante também sejam excluídas automaticamente, ao invés de levantar qualquer tipo de exceçăo durante a transaçăo. Os índices referentes ŕs chaves primárias de ambas as tabelas săo criados implicitamente pelo PostgreSQL.
Nota 4. Execuçăo de SQL no pgAdmin
No pgAdmin, selecione o banco de dados desejado e acesse o menu Tools, Query Tool. Será aberta a janela para execuçăo das instruçőes. Digite-as na área de texto e acesse o menu Query, Execute ou simplesmente pressione F5 para executá-las. Para mais informaçőes sobre o funcionamento da ferramenta, consulte a documentaçăo on-line (http://www.pgadmin.org/docs/1.4/using.html).
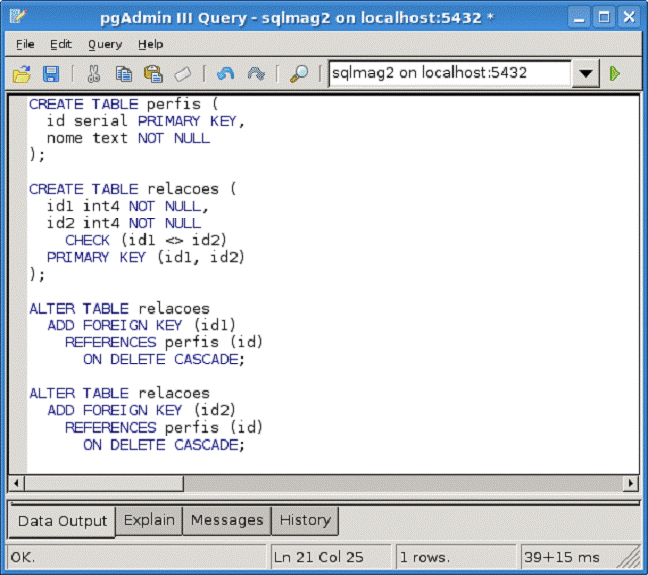
Figura 3. Criaçăo das tabelas e constraints através do pgAdmin III.
O leitor atento já deve ter imaginado um problema com essa modelagem no estudo de caso em questăo: já que a tabela RELACOES liga-se ŕ tabela PERFIS duas vezes, quem será representado pelo id1 e quem será o id2? Exemplificando: Bruce Willis conhece (ou é amigo de) Jack Nicholson ou Jack Nicholson é quem conhece Bruce Willis? Se considerarmos que a relaçăo de amizade é mútua, bilateral, ambas as afirmativas estăo corretas. E como resolver isso no SGBD? Simples: dupliquemos os registros! Cada conjunto (id1: X, id2: Y) terá um correspondente (id1: Y, id2: X). Mas e agora, como controlar mais essa integridade? A resposta é: via trigger.
Com a ajuda de uma trigger, o controle dessa duplicaçăo de registros será transparente no SGBD. Criemos entăo uma trigger que:
· na inclusăo de um registro com o conjunto (id1: X, id2: Y), execute em seguida a inclusăo do conjunto oposto (id1: Y, id2: X);
· na exclusăo de um registro, exclua também o registro referente ao conjunto oposto. ...







