
MySQL
Otimizaçăo de consultas em em MySQL
A utilizaçăo eficiente de um SGBD é um fator crucial para que se tenha uma aplicaçăo estável, ágil e capaz de escalar em termos de números de acessos e volume de dados. Considerando o MySQL, existem vários aspectos que devem ser considerados para que ele possa funcionar de forma otimizada, proporcionando ŕ aplicaçăo um tempo de resposta adequado aos seus propósitos. Dentre os vários fatores, podemos citar os ajustes no sistema operacional, escolha de equipamentos e hardwares com bom desempenho, ajustes de parâmetros do MySQL, e por último mais năo menos importante, a otimizaçăo de consultas.
O uso prático de um SGBD se resume em armazenar informaçőes e disponibilizá-las aos seus usuários através de consultas SQL (Structured Query Language). Neste contexto, a maior parte do trabalho realizado por este sistema é exatamente atender a estas requisiçőes tentando processá-las no menor tempo possível, retornando os dados para o usuário que iniciou a consulta. Sendo assim, em sistemas que geram um volume elevado de requisiçőes, se as mesmas năo săo executadas no menor tempo possível, năo é possível manter o desempenho global do sistema em um patamar que satisfaça aos requisitos de tempo do usuário final.
Portanto, para executar uma consulta SQL, o MySQL necessita percorrer várias etapas até gerar o resultado para o usuário que a submeteu. O esforço para a resoluçăo desta consulta dependerá de diversos fatores, tais como o uso de índices, as operaçőes utilizadas, JOINs e sub-selects, por exemplo, além da estrutura dos dados existentes.
Este artigo tem como objetivo apresentar o processo de execuçăo de consultas no MySQL e as principais técnicas para a otimizaçăo destes comandos. Além disto, é preciso compreender o plano de execuçăo de uma consulta e saber como intervir para melhorar a estratégia de execuçăo adotada pelo otimizador. Inicialmente serăo apresentadas as etapas de execuçăo de uma consulta e em seguida como otimizar cada uma destas etapas. Posteriormente será apresentado o comando EXPLAIN, bem como todos os seus aspectos relevantes. E finalmente, serăo discutidos exemplos práticos de comandos e suas respectivas otimizaçőes, salientando a importância do uso de índices e as boas práticas para a sua criaçăo.
Etapas de execuçăo de uma consulta
Todas as vezes que uma consulta SQL é submetida ao MySQL, é iniciada uma série de etapas para a geraçăo de um conjunto resultante de informaçőes que serăo enviadas de volta ao usuário que iniciou a requisiçăo de dados. Portanto, seria conveniente buscar incrementos de desempenho em cada etapa de forma a economizar esforços, possibilitando a geraçăo de um resultado no menor tempo possível. A Figura 1 ilustra cada uma das etapas percorridas pelo MySQL a fim de produzir um resultado a partir de um comando SQL.
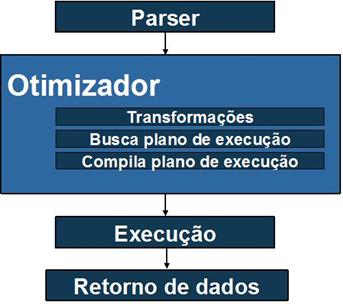
Figura 1. Processo de execuçăo de consultas em MySQL
Conforme ilustra a Figura 1, a execuçăo da consulta exige a repetiçăo de procedimentos, em alguns casos complexos, todas as vezes que uma consulta é submetida. Em especial, se a mesma consulta é executada várias vezes, os mesmos passos devem ser seguidos para cada execuçăo, o que onera ainda mais este custo de execuçăo.
A seguir estăo descritas cada uma das etapas, bem como as estratégias de otimizaçăo que podem ser empregadas a fim de se agilizar a execuçăo das mesmas.
Parser
O Parser é o responsável por interpretar o comando SQL submetido ao MySQL, verificando se o mesmo está sintaticamente correto. O objetivo do parser é converter o comando SQL para um formato binário interno, para que entăo possa ser submetido ao otimizador de consultas.
É notório neste caso que o parser gera uma sobrecarga no processo de execuçăo de uma consulta, uma vez que esta transformaçăo deve ser aplicada a todo e qualquer comando que venha a ser submetido ao MySQL. O pior caso é aquele onde o mesmo comando é executado repetidas vezes, acumulando assim esta sobrecarga a cada requisiçăo. Neste cenário, o ideal seria que a etapa de parser fosse realizada somente a primeira vez em que o comando fosse submetido ao servidor, e que nas execuçőes posteriores esta etapa fosse suprimida, uma vez que já existiria o seu correspondente binário dentro do SGBD.
O MySQL dispőe de duas alternativas úteis para a aceleraçăo do processo de parser, que săo os prepared statement e stored procedures. Estes mecanismos possibilitam a execuçăo de um mesmo comando, ou de uma seqüęncia de comandos, realizando a etapa de parser somente uma vez. Neste caso, o ganho de desempenho é visível, uma vez que a etapa de parser será totalmente desprezada para execuçőes sucessivas de um mesmo comando. A Listagem 1 ilustra a utilizaçăo dos prepared statements em MySQL.
Listagem 1. Utilizaçăo de prepared statements em MySQL.
mysql> PREPARE comando FROM "SELECT nome FROM Pessoas WHERE id = ?";
Query OK, 0 rows affected (0.09 sec)
mysql> SET @codigo = 10;
Query OK, 0 rows affected (0.00 sec)
mysql> EXECUTE comando USING @codigo;
+---------+
| name |
+---------+
| Carla |
+---------+
1 row in set (0.03 sec)
mysql> SET @codigo = 25;
Query OK, 0 rows affected (0.00 sec)
mysql> EXECUTE comando USING @codigo;
+---------+
| name |
+---------+
| Paulo |
+---------+
1 row in set (0.03 sec)
mysql> DEALLOCATE PREPARE comando;
Query OK, 0 rows affected (0.00 sec)
A Listagem 1 fornece um exemplo de um prepared statement utilizado para listar o nome de uma pessoa cujo código será informado a cada execuçăo deste comando. O comando PREPARE realiza a transformaçăo do comando para um formato binário interno e o deixa disponível para ser invocado posteriormente.
Para utilizar o comando preparado anteriormente, utilizou-se de uma variável para informar o código da pessoa a ser exibida. Para isto, utiliza-se o comando EXECUTE informando o nome do prepared statement a ser executado e os argumentos que substituirăo os sinais de interrogaçăo ('?') utilizados no preparo do comando. Vale ressaltar que havendo mais de uma interrogaçăo, deve-se informar na cláusula USING um valor para cada interrogaçăo utilizada na ordem em que as mesmas foram definidas no prepared statements. Vale destacar também que as variáveis devem ser separadas por vírgulas dentro da cláusula USING do comando EXECUTE.
Na Listagem 1, o mesmo comando foi executado para a busca da Pessoa com o id igual a 10 e 25, sendo que nenhum parser foi realizado para estas execuçőes, uma vez que o comando já havia sido previamente preparado. Esta abordagem gera um ganho de desempenho considerável, pois uma etapa do processo é totalmente descartada no momento da execuçăo do comando. Além disto, vale lembrar que o mesmo raciocínio se aplica ŕs stored procedures. Finalmente, o comando DEALLOCATE PREPARE exclui um prepared statement, liberando os recursos alocados para ele.
Entretanto, é preciso salientar que o prepared statement é criado por conexăo (thread), ou seja, dois usuários que utilizam conexőes distintas năo compartilham os seus prepared statements. Assim, este recurso é útil para as aplicaçőes que submetem o mesmo comando repetidas vezes dentro de uma mesma conexăo. No caso de aplicaçőes Web, este comportamento năo é observado, uma vez que năo utilizam conexőes persistentes, submetendo assim os comandos sempre em conexőes distintas, o que minimiza os benefícios da utilizaçăo deste recurso. Neste caso, apesar de os caches serem por conexăo, o que limita parcialmente os ganhos de desempenho, o mais aconselhado seria a utilizaçăo de stored procedures, pois as mesmas săo compartilhadas entre todos os usuários.
Otimizador
O otimizador é o responsável por encontrar o caminho mais curto para a busca das informaçőes desejadas pelo usuário. Este realiza transformaçőes nas consultas de forma a encontrar comandos equivalentes que possam ser executados no menor tempo. Além disto, o otimizador procura detectar qual a melhor ordem de leitura das tabelas em um JOIN a fim de retornar os dados no menor tempo, e ainda opta pela utilizaçăo de um índice, caso exista, para agilizar a execuçăo do comando.
O resultado gerado pelo otimizador é o plano de execuçăo que deve ser seguido pela etapa de execuçăo a fim de se obter os resultados esperados pelo usuário. Todas as decisőes tomadas pelo otimizador para a geraçăo deste plano de execuçăo săo baseadas em estatísticas de dados existentes no sistema, tais como cardinalidade de índices, tamanho de registros e tabelas, dentre outras. Por se basear em metadados, que podem năo estar atualizados ou năo refletirem situaçőes inerentes ao modelo de dados, este plano de execuçăo pode năo espelhar uma situaçăo ótima de busca das informaçőes. Portanto, é preciso compreender a composiçăo deste plano para que se possa intervir de forma a conduzir o MySQL a encontrar o menor caminho para a execuçăo de uma consulta específica.
O comando EXPLAIN permite visualizar este plano de execuçăo e está descrito com detalhes na seçăo a seguir.
Explicando o EXPLAIN
O comando EXPLAIN permite a visualizaçăo do plano de execuçăo de um comando SELECT. Para isto, basta adicionar a palavra EXPLAIN ao comando que se deseja avaliar. A Listagem 2 ilustra a execuçăo do comando EXPLAIN em uma consulta que exibe o nome de todos os países situados na América do Sul e o nome de suas respectivas capitais.
Listagem 2. EXPLAIN da consulta que lista o nome dos países da América do Sul e o nome de suas capitais.
mysql> EXPLAIN SELECT co.name, ci.name
-> FROM City ci, Country co
-> WHERE co.capital = ci.id AND region LIKE 'South am%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: co
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
...







