Atençăo: por essa ediçăo ser muito antiga năo há arquivo PDF para download.
Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.

Clique aqui para ler todos os artigos desta ediçăo
Conceitos e Otimizaçăo de bloqueios no SQL Server
A arquitetura de ambientes transacionais é fundamentada no conceito segundo o qual, para que haja consistęncia de informaçőes, é necessário que se estabeleçam regras rígidas no acesso a dados. Essas regras năo permitem, por exemplo, que dois usuários compartilhem a mesma alteraçăo ou excluam o mesmo registro em uma tabela. Para executar essas restriçőes, o banco utiliza um recurso denominado bloqueio (lock) em transaçőes.
O ato de abrir uma transaçăo sinaliza para o banco que as tabelas manipuladas deverăo ser tratatas com algum tipo de bloqueio para que sejam consistentes.
O SQL Server efetua bloqueios sempre no menor recurso disponível, para viabilizar maior concorręncia. Isso evita cenários năo coerentes, como bloquear uma tabela para alterar apenas uma linha. A situaçăo ideal é que seja bloqueado somente o set de registros manipulados na transaçăo, liberando, assim, acessos concorrentes a outros registros na mesma tabela.
No entanto, bloqueios consomem recursos - cada um gasta 64 bytes e cada processo aguardando a liberaçăo do recurso bloqueado consome 32 bytes de memória. Por economia, sempre que a quantidade de bloqueios na sessăo excede um limite interno, eles săo promovidos ŕ níveis mais abrangentes. Dessa forma, bloqueios de linha e/ou página podem ser transformados em bloqueios de tabela. Sempre que acontece o escalonamento, os bloqueios de nível mais baixo săo liberados.
Os recursos que podem ser bloqueados, em ordem crescente de granulidade, estăo listados na tabela 1.
NOTA: Bloqueios de linha nunca săo promovidos para bloqueios de página.
NOTA: Granulidade diz respeito ŕ abrangęncia do bloqueio, ou seja, se afeta uma linha, página ou tabela.
Tipos de Bloqueio
Os bloqueios podem diferir quanto ao recurso bloqueado (linha, página, extent, tabela ou database), duraçăo (se permanecem ou năo ativos durante toda a transaçăo) ou tipo (Shared, Update, Exclusive, Intent, Schema ou Bulk Update). Os tipos săo detalhados a seguir:
Shared (S): utilizados para processos de leitura. Ao se aplicar um comando SELECT, um bloqueio do tipo shared é efetuado. Sua finalidade é restringir alteraçőes de dados e/ou de estrutura nos objetos que estăo sendo lidos. Shared locks săo compatíveis entre si; ou seja, é possível executar vários SELECTs para uma mesma tabela sem que uma sessăo trave a outra. Quando executados sob o nível de isolamento read committed permanecem ativos somente durante a execuçăo do comando. Em isolamentos repeatable read ou serializable, permanecem ativos até o término da transaçăo.
Update (U): săo utilizados em processos de alteraçăo/exclusăo de dados. Para entender seu uso, devemos notar que um UPDATE, de forma geral, é antecedido de uma leitura do conjunto de registros que será alterado. Por exemplo:
UPDATE FROM funcionarios
SET salario = salario * 1.10
WHERE depto = 5
Antes de iniciar a alteraçăo o SQL Server recupera todos os funcionários do departamento 5, promovendo um update lock durante a leitura (e năo durante a alteraçăo em si). Update locks năo săo compatíveis entre si, ou seja, năo é permitido mais de um bloqueio para um mesmo recurso em paralelo – o que evita a ocorręncia de deadlocks de conversăo. Após a leitura dos dados, o bloqueio é promovido para exclusive e a alteraçăo é efetuada. Com esse mecanismo, O SQL Server garante maior concorręncia durante a atualizaçăo.
Nota: Maiores detalhes sobre deadlocks de conversăo estăo disponíveis na SQL Magazine 2.
Exclusive (X): acionado no momento em que a alteraçăo/exclusăo efetivamente acontece. Um bloqueio exclusivo assegura que um e somente um processo estará manipulando o conjunto de registros definido na transaçăo. Como o nome sugere, eles năo săo compatíveis com qualquer outro tipo de bloqueio, sendo liberados somente no término da transaçăo.
Intent (I): um intent lock nada mais é do que uma “marca” sinalizando que existem bloqueios de menor nível hierárquico sendo executados. Por exemplo, um processo que detém um lock exclusive de linha gera também dois intent exclusive locks: um para a página onde se encontra o registro e outro para a tabela. A finalidade do intent lock é evitar o conflito de recursos. Imagine que um processo necessite de um bloqueio exclusivo de tabela. Se existem intent locks ativos neste objeto, o bloqueio năo poderá ser honrado.
Além de IS (Intent Share), IX (Intent Exclusive) e IU (Intent Update), existem outras opçőes de intent locks, que acontecem quando eles săo combinados com shared locks (por exemplo, vocę atualiza um registro e, na mesma transaçăo, efetua uma leitura na página que o contém): SIX (Shared with Intent Exclusive), UIX (Update with Intent Exclusive) e SIU (Shared Intent Update).
Schema: controla atualizaçőes de estrutura (também conhecida como schema) das tabelas. Evitam, por exemplo, que uma tabela que está sendo utilizada em produçăo seja alterada (Schema Modification Locks ou Sch-M), ou que algum processo acesse uma tabela cuja estrutura está em modificaçăo (Schema Stability Locks ou Sch-S).
Bulk Update: utilizado para agilizar processos envolvendo a transferęncia de arquivos texto com o utilitário BCP. Esse bloqueio é acionado quando a opçăo TabLock estiver ativa ou quando com a opçăo Table lock on bulk load estiver setada para a tabela através do comando sp_TableOption.
NOTA: BCP ou Bulk Copy Program é um utilitário de linha de comando disponível no SQL Server para importaçăo/exportaçăo de arquivos texto.
Dependendo da operaçăo realizada no banco, o SQL Server opta automaticamente por um tipo de bloqueio. Observe que diversos tipos podem ser combinados em uma mesma transaçăo. Para verificar a compatibilidade entre tipos de bloqueio, acesse
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/acdata/ac_8_con_7a_8um1.asp
Hints
O comportamento de bloqueios está diretamente ligado ao nível de isolamento adotado na transaçăo. Conforme visto no artigo anterior (ediçăo 4), o SQL Server reconhece os seguintes níveis de isolamento:
Read Uncommitted - Permite a leitura de dados năo comitados, desrespeitando os bloqueios exclusivos mantidos nas transaçőes.
Read Committed - Nível de isolamento padrăo. Significa que processos de leitura só podem ser efetuados sobre dados comitados. Bloqueios realizados em comandos SELECT săo liberados no término do comando.
Repeatable Read - Incorpora as características de Read Committed. Assegura que registros lidos năo serăo alterados por outros processos, garantindo releituras idęnticas. Bloqueios realizados em comandos SELECT săo liberados somente no término da transaçăo.
Serializable - Incorpora as características de Repeatable Read, năo permitindo, adicionalmente, que outras sessőes efetuem inserçőes no conjunto de registros lidos.
Ŕs vezes pode ser interessante especificar, em um determinado comando, um nível de isolamento diferente do adotado para a sessăo. Para isso, usa-se diretivas conhecidas como hints, que săo declaradas junto aos comandos de manipulaçăo de dados. Observe a listagem a seguir:
BEGIN TRAN
INSERT x …
UPDATE y …
…
SELECT * FROM z (holdlock)
..
SELECT * FROM w
COMMIT
O hint holdlock altera o nível de isolamento adotado na sessăo (read committed), para Repeatable Read. Se o hint năo fosse utilizado, o bloqueio seria liberado logo após a operaçăo de leitura (antes da execuçăo de SELECT * FROM w).
Em geral, hints podem ser utilizados para modificar as seguintes propriedades:
· Alterar o nível de isolamento do comando:
Ex: SELECT OrderId FROM Orders (HoldLock)
· Alterar a granulidade do comando:
Ex: SELECT OrderId FROM Orders (PagLock)
· Alterar o tipo padrăo de bloqueio:
Ex: SELECT OrderId FROM Orders (UpdLock)
· Selecionar um índice específico para resolver uma query:
Ex: SELECT OrderId FROM Orders (index=OrderDate)
· Forçar um tipo de join para o plano de execuçăo (Loop, Merge ou Hash):
Ex: SELECT o.OrderId FROM Orders o
inner LOOP JOIN [Order Details] d on o.OrderId = d.OrderId
Veja uma descriçăo detalhada dos tipo de hint no box “Tipos de Hint”. A seguir, algumas regras na utilizaçăo de hints:
· Operaçőes que modificam dados exigem bloqueios exclusivos e năo podem ter seu nível de isolamento alterado para NoLock, ReadUncommitted ou ReadPast.
· Só é possível combinar hints de origens diferentes (por exemplo, combina-se holdlock com updlock, mas nunca holdlock com nolock). A mensagem de erro 1047: Conflicting locking hints specified traduz essa regra.
· Avaliar bem se a utilizaçăo de hints é necessária. Alguns hints tęm o poder de “mascarar” problemas latentes - por exemplo, o hint NoLock otimiza os processos ao extremo. Alguns administradores ficam tentados a usar esse recurso, ao invés de investigar as queries com baixa performance. O problema é que NoLock pode gerar “registros fantasmas”, resultantes da leitura năo comitada. Como normalmente a performance năo é mais importante do que a consistęncia das informaçőes, o uso desse hint deve ser avaliado com cuidado.
Um caso prático
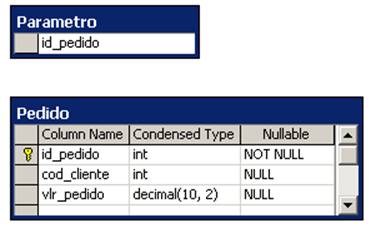
Vejamos um exemplo prático envolvendo hints e transaçőes. Criaremos uma procedure para inserir linhas na tabela Pedido (figura 1) e retornar o número do pedido para a aplicaçăo. Os parâmetros da procedure săo o código do cliente (cod_cliente) e o valor do pedido (vlr_pedido). O número do pedido será obtido da tabela Parametro, que contém somente um registro informando o número do próximo pedido. Após ler o valor corrente, o número do pedido nesta tabela será incrementado em uma unidade. A operaçăo acontece em um ambiente multi-usuário, com geraçăo de pedidos simultânea. Deve-se, portanto, identificar o nível de isolamento adequado para que năo existam problemas de violaçăo de chave primária na tabela Pedido. Na listagem 1 vemos alguns cenários para resoluçăo do problema.
Figura 1: Tabelas utilizadas no estudo de caso sobre hints
Listagem 1: Cenários envolvendo criaçăo de procedure para atualizaçăo do Pedido
|
Cenário 1: Permite violaçăo de chave primária
create procedure stp_GerarPedido ( @p_cod_cliente int, @p_vlr_pedido dec (10,2), @o_id_pedido int output) as set nocount on
begin tran select @o_id_pedido=id_pedido from Parametro
insert into Pedido values (@o_id_pedido, @p_cod_cliente, @p_vlr_pedido)
update Parametro set id_pedido = id_pedido +1 commit |
Cenário 2: Sujeito a deadlocks
Create procedure stp_GerarPedido ( @p_cod_cliente int, @p_vlr_pedido dec (10,2), @o_id_pedido int output) as set nocount on set transaction isolation level repeatable read begin tran select @o_id_pedido=id_pedido from Parametro
insert into Pedido values ( @o_id_pedido, @p_cod_cliente, @p_vlr_pedido )
update Parametro set id_pedido = id_pedido +1 commit |
|
Cenário 3: Sujeito a deadlocks Create procedure stp_GerarPedido ( @p_cod_cliente int, @p_vlr_pedido dec (10,2), @o_id_pedido int output) as set nocount on begin tran select @o_id_pedido=id_pedido from Parametro (holdlock)
insert into Pedido values ( @o_id_pedido, @p_cod_cliente, @p_vlr_pedido ) update Parametro set id_pedido = id_pedido +1 commit
|
Cenário 4: Correto Create procedure stp_GerarPedido_4 ( @p_cod_cliente int, @p_vlr_pedido dec (10,2), @o_id_pedido int output ) as set nocount on begin tran select @o_id_pedido=id_pedido from Parametro (updlock)
insert into Pedido values ( @o_id_pedido, @p_cod_cliente, @p_vlr_pedido )
update Parametro set id_pedido = id_pedido +1 commit |
|
Cenário 5: Correto Create procedure stp_GerarPedido ( @p_cod_cliente int, @p_vlr_pedido dec (10,2), @o_id_pedido int output ) as set nocount on begin tran update Parametro set id_pedido = id_pedido + 1
select @o_id_pedido = (id_pedido - 1) from Parametro insert into Pedido values ( @o_id_pedido, @p_cod_cliente, @p_vlr_pedido ) commit |
Cenário 6: Correto Create procedure stp_GerarPedido ( @p_cod_cliente int, @p_vlr_pedido dec (10,2), @o_id_pedido int output ) asset nocount on begin tran update Parametro set id_pedido = id_pedido +1, @o_id_pedido = id_pedido
insert into Pedido values ( @o_id_pedido, @p_cod_cliente, @p_vlr_pedido ) commit |
A procedure do cenário 1 está sujeita a violaçăo de chave primária na tabela Pedido. Nesse exemplo, dois processos concorrentes podem resgatar o mesmo número de pedido da tabela Parametro, pois năo existe bloqueio para SELECTs rodando sobre transaçőes com nível de isolamento read committed (o nível default).
Os cenários 2 e 3 apresentam um caso propício para deadlocks de conversăo. Para relembrar, um deadlock é uma espera cíclica, que acontece quando um processo X fica aguardando a liberaçăo do bloqueio de um processo Y, e vice-versa.
Observe que o bloqueio holdlock (ou Repeatable Read) realizado na tabela Parâmetro impede que outras sessőes modifiquem o registro, mas năo proíbe que seu conteúdo seja acessado. Além disso, bloqueios holdlock săo compatíveis entre si, ou seja, permitem que outras sessőes também repitam o bloqueio (bloqueios holdlock săo do tipo Shared).
Dessa forma, se duas sessőes executarem a procedure no mesmo instante, o UPDATE năo conseguirá promover um bloqueio exclusive. Como exclusive năo permite a existęncia de nenhum outro bloqueio para o mesmo recurso, a primeira sessăo ficará aguardando a liberaçăo do bloqueio holdlock estabelecido na sessăo 2. No momento em que a segunda sessăo tentar realizar o bloqueio exclusivo, ela ficará aguardando a conclusăo de holdlock da sessăo 1, fechando o ciclo que ocasiona o deadlock.
Os cenários 4, 5 e 6 estăo corretos. Bloqueios Update (updlock) năo săo compatíveis entre si, ou seja, apenas uma sessăo pode obter este bloqueio para o mesmo recurso – sessőes concorrentes permanecerăo aguardando a execuçăo completa da primeira. O cenário 6 apresenta uma maneira interessante de se realizar “dois comandos em um”; observe que a variável @o_id_pedido é inicializada no próprio comando UPDATE. Num teste intenso de inserçăo de registros (quatro sessőes inserindo um montante de 50.000 registros cada), o cenário 4 mostrou-se o mais bem sucedido.
Cenários ŕ parte, a verdade é que situaçőes como essa podem e devem ser evitadas. Por exemplo, definir a coluna id_pedido na tabela Pedido como auto-incremento resolveria o problema de forma mais simples (elimina-se a tabela Parametro) e limpa (menos código).
Uma alternativa otimista
Uma opçăo ao uso de hints para contornar o efeito de bloqueios em comandos SELECT, pode ser obtida com colunas TimeStamp. Esse tipo de dado possui a característica especial de versionar registros: sempre que uma linha é modificada, a coluna TimeStamp recebe automaticamente um novo valor. A Microsoft garante que valores TimeStamp năo se repetem num mesmo database. Portanto, um meio eficiente de verificar se um registro sofreu algum tipo de alteraçăo por sessőes concorrentes é armazenar, no ínicio da transaçăo, o valor de TimeStamp em uma variável. No momento do UPDATE, podemos comparar o valor lido com o atual, verificando se o registro foi modificado por outro processo. Nesse caso, invalidamos a transaçăo com um rollback e a reiniciamos. Essa abordagem (também conhecida por bloqueio otimista) subentende que processos conflitantes săo exceçăo e considera que submeter novamente a transaçăo é mais interessante do ponto de vista de concorręncia e economia de recursos do que forçar um bloqueio mais rigoroso.
A listagem 2 demonstra um exemplo desse cenário. Observe que utilizamos a funçăo năo documentada TSEqual, que retorna o erro #532 se os valores de TimeStamp passados como parâmetro forem diferentes. Note que a transaçăo na sessăo 1 é submetida duas vezes, em funçăo da alteraçăo concorrente realizada na sessăo 2.
Listagem 2: Simulaçăo de transaçăo com bloqueios otimistas
Sessăo 1: Executar o batch abaixo
use NorthWind
go
alter table Orders add TS timestamp not null
go
declare @ts timestamp
declare @contador_trans int
set @contador_trans=1
SUBMETER_TRANS:
begin tran
select @ts=TS from Orders where OrderId=10248
waitfor delay '00:00:30' -- tempo de espera, para que a sessăo 2 termine primeiro
update Orders
set OrderDate=getdate()
where OrderId = 10248 and TSEqual(ts,@ts)
if @@error = 532
begin
rollback tran
set @contador_trans=@contador_trans+1
if @contador_trans <=3
begin
print 'Submetendo novamente a transaçăo ...'
goto SUBMETER_TRANS
end
else goto FIM_ROLLBACK
end
FIM_COMMIT:
if @@trancount > 0 COMMIT
RETURN
FIM_ROLLBACK:
raiserror ('Processo de atualizaçăo da tabela Orders abortado!',11,1)
RETURN
Sessăo 2: Executar em paralelo o batch
update Orders
set OrderDate=getdate()
where OrderId = 10248
Em termos práticos, podemos substituir hints que degradam performance (holdlock, updlock, xlock) pela checagem adicional da versăo de colunas TimeStamp em comandos UPDATE.
Exceçăo deve ser feita ŕ utilizaçăo de hints em operaçőes modificativas que afetam grande número de registros. Nesse caso, o uso de hints apropriados pode trazer ganhos significativos de performance. Por exemplo, veja o comando abaixo:
UPDATE Orders SET OrderDate = getdate()
Se paralelamente executarmos o comando sp_lock, veremos uma infinidade de bloqueios produzidos pela sentença (tabela 2). Nesse caso, seria mais econômico utilizar o hint TabLock, conforme a linha a seguir:
UPDATE orders with (tablock) SET orderdate=getdate()
Com este hint, apenas um bloqueio de tabela é gerado, conforme mostra a tabela 3.
Tabela 2: UPDATE executado para todos os registros da tabela Orders
|
Spid |
Dbid |
ObjId |
IndId |
Type |
Resource |
Mode |
Status |
|
66 |
6 |
21575115 |
6 |
KEY |
(9e00a4a08460) |
X |
GRANT |
|
66 |
6 |
21575115 |
6 |
KEY |
(1900ff5cf54b) |
X |
GRANT |
|
66 |
6 |
21575115 |
6 |
KEY |
(9c003fc58759) |
X |
GRANT |
|
…. |
…. |
…. |
…. |
… |
… |
… |
… |
|
66 |
6 |
21575115 |
0 |
RID |
1:189:7 |
X |
GRANT |
|
66 |
6 |
21575115 |
6 |
KEY |
(7801c8c69339) |
X |
GRANT |
|
…. |
…. |
…. |
…. |
… |
… |
… |
… |
|
66 |
6 |
21575115 |
0 |
TAB |
|
X |
GRANT |
|
…. |
…. |
…. |
…. |
… |
… |
… |
… |
Tabela 3: UPDATE realizado com hint
|
Spid |
Dbid |
ObjId |
IndId |
Type |
Resource |
Mode |
Status |
|
66 |
6 |
21575115 |
0 |
TAB |
|
X |
GRANT |
Monitorando Bloqueios
Monitorar bloqueios significa estar atento a processos que impedem a execuçăo normal de outros processos. Algumas características que tornam os processos lentos săo:
· Uso inadequado de predicados nas queries, impossibilitando a utilizaçăo de índices eficientes;
· Níveis de isolamento inadequados, que prolongam a duraçăo de bloqueios;
· Transaçőes excessivamente longas;
· Incidęncia de deadlocks.
O SQL Server disponibiliza duas procedures e dois utilitários para ajudar na identificaçăo de processos causadores de gargalo, conforme descrito a seguir.
Procedure SP_LOCK
Fornece um retrato detalhado dos locks ativos no servidor. Veja a tabela 4.
Tabela 4
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ------- ---------------- -------- -----------
55 6 0 0 DB S GRANT
55 6 21575115 0 RID 1:205:0 S WAIT
55 6 21575115 0 PAG 1:205 IS GRANT
55 6 21575115 0 TAB IS GRANT
56 22 0 0 DB S GRANT
57 6 0 0 DB S GRANT
57 6 21575115 0 TAB IX GRANT
57 6 21575115 6 KEY (430259d8c611) X GRANT
57 6 21575115 0 PAG 1:205 IX GRANT
57 6 21575115 6 PAG 1:312 IX GRANT
57 6 21575115 0 PAG 1:313 IX GRANT
57 1 85575343 0 TAB IS GRANT
57 6 21575115 6 KEY (7e01d7d31932) X GRANT
57 6 21575115 0 RID 1:205:0 X GRANT
Significado das colunas retornadas pela execuçăo do comando:
· spid: id da sessăo relacionada ao bloqueio, pode estar ativo ou passivo. O spid ativo é o responsável pelo bloqueio, sinalizado com Status=GRANT. Ele será passivo quando estiver aguardando pela liberaçăo do recurso bloqueado (Status=WAIT);
· dbid: id do database onde o bloqueio está sendo mantido. O id de um database pode ser obtido pela funçăo db_id(‘<NOME-DO-DATABASE>’);</NOME-DO-DATABASE>
· ObjId: id do objeto que detém o bloqueio. Para saber o nome do objeto bloqueado utilize a funçăo object_name(<ID>)</ID> no database responsável pelo bloqueio;
· IndId: id do índice onde o bloqueio está sendo executado;
· Type: sigla do recurso onde o bloqueio está sendo executado (tabela 1);
· Resource: nome interno do recurso;
· Modo: tipo de bloqueio que está sendo aplicado (S: Shared, IS: intent shared, X: exclusive, IX: intent exclusive, SIX: intent with shared exclusive);
· Status: posiçăo do spid em relaçăo ao bloqueio; se estiver aguardando a liberaçăo de um recurso o status será WAIT; se for o responsável pelo bloqueio o status será GRANT
Acionar a procedure sp_lock para rastrear processos bloqueados pode se tornar uma tarefa
complexa, principalmente quando vocę recebe ligaçőes de vários setores da empresa
informando que “o sistema está travado”.
De forma geral, é necessário identificar as sessőes cujo status seja wait, procurar por
sessőes com status grant para o mesmo objeto e finalizá-las, para liberaçăo do bloqueio.
Procedure SP_WHO
A procedure sp_who (existe também uma versăo năo documentada com pequenas variaçőes – sp_who2) fornece uma maneira mais amigável para se identificar sessőes responsáveis por travamentos, apresentando uma relaçăo de todos os processos ativos no servidor. Valores diferentes de zero na coluna blk sinalizam o spid responsável pelo bloqueio. Na tabela 5, vemos o spid 55 travado pela sessăo 57. Repare que, na linha da sessăo 57, o status do processo é Runnable e a coluna Blk apresenta-se zerada, informando que ela possui bloqueios ativos.
Tabela 5: Resultado da execuçăo do comando sp_who
|
Spid |
Ecid |
Status |
LoginName |
HostName |
Blk |
DbName |
Cmd |
|
.. |
… |
….. |
…. |
…. |
… |
…. |
… |
|
55 |
0 |
Sleeping |
xxx\PauloS |
DesktopP |
57 |
NorthWind |
SELECT |
|
57 |
0 |
Runnable |
xxx\SilvioR |
DesktopS |
0 |
NorthWind |
Update … |
|
.. |
… |
….. |
…. |
…. |
… |
…. |
… |
No contexto representado nesta tabela, o problema pode ser facilmente resolvido: basta identificar na coluna Cmd o processo que está em andamento e, se necessário, finalizá-lo com o comando kill (kill 57). Imagine agora um ambiente mais robusto, com 100 usuários ativos no sistema e o travamento da sessăo 55 causado pela sessăo 57, a sessăo 57 bloqueada pela 198, que está bloqueada pela 177, que está bloqueada pela 45 ...; enfim, existe um sem número de sessőes travadas.
Em situaçőes desse tipo, uma alternativa eficaz para identificar sessőes responsáveis por bloqueios em cadeia é executar uma consulta ŕ tabela SysProcesses, localizada no database master (responsável pelo registro de todos processos ativos no servidor). Com base nessa tabela, basta formular uma query que liste os processos em execuçăo (blocked=0) responsáveis por bloqueios em outras sessőes (blocked <> 0) (listagem 3).
Listagem 3
select spid, blocked, left (hostname,20) as HostName_SPID,
waitTime_Seg = convert(int,(waittime/1000)), open_tran, status,
left(program_name,30) as program_name
from master.dbo.sysprocesses
where spid in (select blocked from master.dbo.sysprocesses where blocked > 0 )
and blocked = 0
order by spid
Monitorando bloqueios com Windows 2000 System Monitor
O Windows 2000 System Monitor (ou Performance Monitor nas versőes anteriores ao Windows 2000) fornece alguns contadores para análise geral de bloqueios. Pode-se saber, por exemplo, que o tempo médio para espera de bloqueios aumentou em 1 segundo desde a última verificaçăo. Para uma análise nesse nível torna-se fundamental a manutençăo de um baseline, sem o qual é impossível estabelecer parâmetros razoáveis de boa performance. Os contadores mais interessantes săo Average Wait Time (tempo médio de espera, em milissegundos, para uma requisiçăo de bloqueio) e Number of DeadLocks /seg (número de deadlocks por segundo). Esse utilitário está disponível no menu Start\Programs\Administrative Tools\Performance (figura 2).
NOTA: Manter um baseline implica definir uma série de índices para controle de performance, identificando variaçőes em análises periódicas.
Monitorando bloqueios com o Profiler do SQL Server
O SQL Server Profiler mantém a classe Locks para monitoramento de bloqueios. É adequada a utilizaçăo dos eventos Lock: DeadLock e Lock:DeadLock Chain para rastrear sessőes envolvidas em deadlocks e Lock:TimeOut para investigar quais processos estăo relacionados ao erro #1222: “Lock request time out period exceeded.”. Esse utilitário está disponível em Start\Programs\Microsoft SQL Server\Profiler (figura 3).
Conclusăo
O uso racional de bloqueios é equivalente a performance. Entender como agem os bloqueios no servidor é um passo muito importante para que as aplicaçőes se tornem mais leves e aptas a tratar processos concorrentes de maneira eficaz.
Figura 2: Windows 2000 System Monitor
Figura 3: Profiler do SQL Server 2000
Recurso |
Descriçăo |
|
RID |
Row identifier. Utilizado para bloqueios de linha em tabelas sem índice cluster (heaps). |
|
Key |
Utilizado para bloqueios de linha em tabelas com índice cluster. |
|
Page |
Página. |
|
Extent |
Grupo contíguo de 8 páginas de dados ou índice. Bloqueios de extent săo utilizados no momento da alocaçăo de espaço para crescimento de tabelas. |
|
Table |
Toda a tabela (incluindo também índices). |
|
DB |
Banco de dados. |
Tabela 1
BOX: Problemas decorrentes do uso incorreto de isolamento
|
Sintoma |
Descriçăo do Problema |
Nome técnico |
|
Eu modifiquei um registro mas, por algum motivo, a alteraçăo foi perdida. |
Dois processos foram executados simultaneamente, năo estando protegidos por bloqueios de nenhuma espécie. A última alteraçăo irá prevalecer. |
Lost Update
|
|
Quando o resumo de vendas foi processado, esse item tinha sido vendido, por isso está constando no relatório. |
O item que consta no relatório nunca foi vendido. O processo que gerou o relatório năo respeitou os bloqueios mantidos por uma transaçăo ativa no momento da impressăo, que năo foi concluída em funçăo de um rollback. |
Dirty Read
|
|
Algo está acontecendo de errado, pois duas leituras simultâneas em um mesmo conjunto de registros trouxeram resultados diferentes. |
Ocorreram alteraçőes nos registros entre a primeira e segunda leitura |
NonRepeatable Read |
|
Algo está acontecendo de errado, pois a segunda leitura efetuada no mesmo conjunto de registros trouxe um número maior de linhas. |
Ocorreram alteraçőes e/ou inclusőes de registros entre as duas leituras. |
Serializable |
BOX: Tipos de Hint
Hints que alteram o nível de isolamento de uma transaçăo
|
* HoldLock |
Prolonga a duraçăo do bloqueio até o término da transaçăo. Válido para comandos SELECT. |
|
* NoLock |
Efetua leituras em dados năo comitados (dirty read). |
|
* ReadUncommitted |
O mesmo que NoLock. |
|
* ReadCommitted |
Trabalha com isolamento ReadCommitted, respeitando bloqueios estabelecidos em outras sessőes. |
|
* ReadPast |
Instrui a query a “pular” a leitura de recursos bloqueados. Só pode ser utilizado em comandos SELECT. |
|
* RepeatableRead |
Mesmas características do isolamento repeatable read. |
|
* Serializable |
Mesmas características do isolamento serializable. |
Hints que alteram a granulidade das transaçőes
|
* RowLock |
Efetua bloqueios de linha na execuçăo do comando. A utilizaçăo desse hint inibe o escalonamento (ex: passar de bloqueio de linha para tabela). |
|
* PagLock |
Efetua bloqueios de página na execuçăo do comando. |
|
* TabLock |
Efetua bloqueio de tabela na execuçăo do comando. |
|
* TabLockX |
Efetua bloqueio de tabela (exclusivo) na execuçăo do comando. |
Hints que alteram o tipo de bloqueio nas transaçőes
|
* UpdLock |
Utilizado em comandos SELECT para restringir pesquisas concorrentes. Apenas uma transaçăo pode obter este bloqueio para um mesmo recurso (equivalente ao tipo Update). |
|
* Xlock |
Enquanto updlock permite que os dados selecionados sejam lidos por comandos SELECT “puros” (escritos sem utilizaçăo de hints), xlock impőe exclusive locks no set de linhas lidas, tornando-as indisponíveis para qualquer tipo de operaçăo. |







