Este artigo destina-se a analistas e projetistas que estejam utilizando UML (ou pensando em utilizar) para a modelagem de sistemas e que irăo servir-se de um banco de dados relacional para armazenar os dados. Pressupomos que o leitor tenha bons conhecimentos acerca do modelo relacional/entidade-relacionamento e algum conhecimento sobre o modelo de classes e objetos utilizado pela UML.
A modelagem utilizando orientaçăo a objetos apresenta uma série de vantagens. A principal é um casamento maior com o mundo real: enquanto no modelo relacional o analista se preocupa com tabelas, relacionamentos e formas normais, em uma abordagem OO o foco é na fiel representaçăo do mundo real, segundo os aspectos relevantes para o negócio em questăo. Năo há, por exemplo, nenhuma das eternas discussőes para decidir o que deve ou năo ser entidade fraca, relacionamento ternário, chave primária ou candidata.
Para a chamada “transiçăo suave” da análise para o projeto e implementaçăo orientado a objetos é necessário que, além de programar em uma linguagem OO, se armazene as informaçőes em um banco de dados OO. No entanto, a maioria das organizaçőes dispőe apenas de sistemas gerenciadores de bancos de dados relacionais, tais como Oracle, DB2, SQL Server, MySQL e Firebird, entre outros. É necessário entăo mapear o modelo de classes e objetos para um modelo relacional. Esse mapeamento pode ser feito de forma semi-automática por algumas ferramentas, porém, sempre há um custo tanto de desempenho quanto de esforço de programaçăo. Para minimizar estes custos, uma série de heurísticas é aqui apresentada, juntamente com subsídios para que se entenda o cerne do problema.
O termo descasamento de impedância é usado para ressaltar as diferenças entre os paradigmas relacional e orientado a objetos. O paradigma OO é baseado em princípios de programaçăo e engenharia de software bem aceitos ao longo dos anos, tais como acoplamento, coesăo e encapsulamento, enquanto o modelo relacional é baseado em princípios matemáticos da teoria dos conjuntos. Os dois fundamentos teóricos levam a diferentes pontos fortes e fracos. Além disso, o paradigma OO pressupőe administrar a complexidade dividindo o problema em classes que representam dados e comportamentos associados aos dados, ao passo que o modelo relacional propőe formas de se armazenar os dados evitando redundância e as chamadas anomalias de atualizaçăo – as formas normais săo um bom exemplo de tais técnicas. Com objetivos tăo distintos em mente é razoável que se tenha conflitos.
O segredo do bom mapeamento de um modelo de classes para um modelo relacional é entender bem os dois paradigmas e as suas diferenças, e fazer escolhas levando em conta a relaçăo custo/benefício de cada decisăo. Este artigo propőe algumas das técnicas propostas por diversos autores e adotadas em vários projetos, ressaltando vantagens e desvantagens de cada alternativa. Tomaremos por base um sistema gerenciador de banco de dados puramente relacional, porque isto representa a situaçăo da maioria das empresas. No entanto, é bom lembrar que alguns fabricantes estăo estendendo o modelo relacional para o chamado modelo objeto-relacional – por exemplo, o Oracle 9i já apresenta uma série de construçőes OO, tais como classes, herança e métodos, tornando a migraçăo certamente mais fácil.
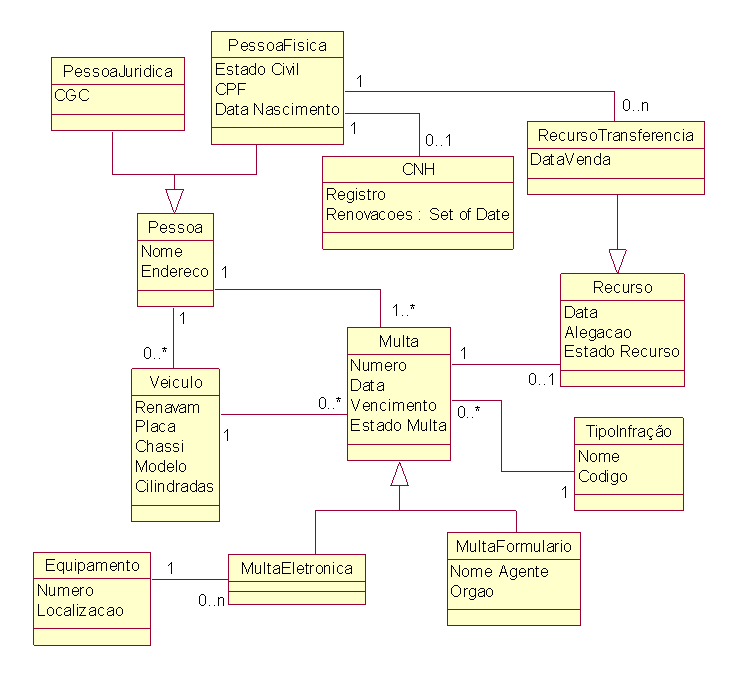
Os principais conceitos de orientaçăo a objetos que aparecem em um modelo de classes e devem ser mapeados para um modelo relacional săo: identidade, classes, atributos, métodos, herança, relaçőes (associaçăo, agregaçăo e composiçăo) e restriçőes. Na figura 1 visualizamos um exemplo de um modelo de classes fictício, que poderia ser utilizado pelo Detran para registrar motoristas, veículos, multas e recursos primários (năo consideramos recursos de segunda instância).
Restriçőes em UML devem ser representadas através de notas em texto corrido ou utilizando-se OCL (Object Constraint Language), uma linguagem recente desenvolvida especialmente para a especificaçăo de restriçőes. Um exemplo de restriçăo representada textualmente seria “năo é permitido criar um recurso para uma multa que já venceu”.
A tabela 1 resume os mapeamentos a serem adotados. Os tópicos a seguir detalham cada um deles.
Muitos autores respeitados na comunidade relacional aconselham o uso de chaves artificiais, sem significado no negócio, denominadas surrogates (ou identificadores) – usualmente, números inteiros seqüenciais que nunca săo reaproveitados. Esta recomendaçăo é praticamente um consenso entre os pesquisadores da comunidade OO, de forma que a tomaremos como uma regra prática: toda tabela que corresponder a uma classe no modelo original possuirá um identificador inteiro como chave primária. Podem haver outras chaves candidatas (alternativas, secundárias), formadas por um ou mais campos, mas a chave primária será sempre este identificador. É costume nomear este campo como ID. Apenas esse atributo será utilizado para a criaçăo de chaves estrangeiras e relacionamentos entre as tabelas. Além disso, um gerador de números seqüenciais para cada chave primária deve ser providenciado.
De forma geral, cada classe simples será mapeada para uma tabela. O que torna uma classe simples é o fato de conter somente atributos que podem ser mapeados diretamente para os tipos básicos do banco de dados, além de năo ser parte de nenhuma hierarquia de classes. Como exemplo temos a classe Veículo, cujo mapeamento seria:
CREATE TABLE VEICULO
(
ID INTEGER NOT NULL PRIMARY KEY,
RENAVAM CHAR(9) NOT NULL UNIQUE,
PLACA CHAR(7) NOT NULL UNIQUE,
CHASSI CHAR(18) NOT NULL UNIQUE,
MODELO CHAR(40) NOT NULL,
CILINDRADAS INTEGER NOT NULL
);
É importante distinguir quatro características de atributos: tipo, cardinalidade, persistęncia e visibilidade.
Tipo: pela sua riqueza, um modelo de classes permite que um objeto tenha atributos de tipos complexos, incluindo tipos abstratos de dados ou até mesmo outros objetos. Mapear estes atributos para um modelo relativamente simples como o relacional deve ser feito de forma criteriosa. Citaremos aqui os casos mais freqüentes:
Tipos simples: possuem correspondęncia direta com os tipos disponíveis no banco de dados, tais como alfanuméricos, inteiros, reais, datas e lógicos. Atributos desse tipo podem ser mapeados diretamente para o seu correspondente no modelo relacional, como no exemplo anterior (Veiculo).
Faixas de Valores: representam valores com limites mínimo e máximo, usualmente de números ou caracteres. Podem ser implementados utilizando-se uma restriçăo na coluna correspondente:
CHECK( cilindradas BETWEEN 50 AND 6000 );
Um bom planejamento deve levar em conta năo somente o desempenho mas também o custo de manutençăo. Caso o limite acima mude, será necessário localizar todos os lugares onde a faixa se aplica e alterar a restriçăo, gerando uma complicaçăo caso a checagem exista em diversas tabelas. Isso pode ser minimizado com o uso de uma ferramenta case mais sofisticada – por exemplo, o Designer2000 da Oracle, que possui suporte para a definiçăo de domínios e representa bem esse tipo de regra.
Tipos Enumerados: usualmente săo tipos que possuem um número finito de valores, tais como estado civil. Há duas abordagens comuns: i) utilizar campos alfanuméricos combinados com faixas de valores; ii) utilizar campos inteiros combinados com tabelas auxiliares. É importante que fique documentado como obter os valores do tipo enumerado, para que seja possível preencher uma combobox em tela, por exemplo.
Utilizar um campo alfanumérico pode ocupar mais espaço, contudo, na maioria dos casos, essa soluçăo possui melhor desempenho e facilita a escrita de consultas. Veja um exemplo:
ESTADO_CIVIL VARCHAR(10), ...
CHECK( ESTADO_CIVIL IN ( ‘SOLTEIRO’, ‘CASADO’,
‘SEPARADO’, ‘DIVORCIADO’, ‘VIÚVO’ ) )
Embora simples de implementar e com boa performance, esta abordagem apresenta os mesmos problemas de manutençăo que a criaçăo de faixas de valores, ou seja, qualquer mudança no tipo enumerado implica em alterar diversas restriçőes espalhadas por várias tabelas. Além disso, a geraçăo de valores para uso em uma combobox torna-se praticamente inviável de ser realizada no banco, devendo ser feita na aplicaçăo. Claramente, esta opçăo é de difícil manutençăo.
O uso de campos inteiros requer codificaçăo para atribuir a cada item um número. Há várias opçőes possíveis: criar uma funçăo (preferencialmente armazenada no banco de dados) que faça a codificaçăo e a decodificaçăo; criar uma tabela exclusiva para o tipo enumerado em questăo; ou criar uma tabela para abrigar todos os tipos enumerados do modelo. Nas tręs alternativas pode-se usar uma restriçăo para validar a entrada, como no caso das faixas de valores. No entanto, em uma consulta, será necessário decodificar o número inteiro para o seu valor correspondente – se usarmos uma tabela auxiliar, isto será feito através de uma junçăo.
Alternativa 1 – criar funçőes que façam a codificaçăo e decodificaçăo, usando a linguagem de programaçăo do banco de dados ou mesmo decodificando ad-hoc:
DECODE( ID, 1, ‘SOLTEIRO’, 2, ‘CASADO’, 3, ‘SEPARADO’, 4, ‘DIVORCIADO’, 5, ‘VIÚVO’ )
Nesse caso seria necessário fazer a validaçăo do campo através do uso de um trigger ou uma restriçăo que verifique se o atributo foi preenchido corretamente. Note que, na sua essęncia, esta abordagem é semelhante ao uso de campos alfanuméricos, apresentando os mesmos problemas de manutençăo. Curiosamente, esta parece ser a maneira predileta de alguns projetistas para implementaçăo de tipos enumerados no modelo relacional – muitas vezes, deixando a cargo do front-end a responsabilidade de verificar se o valor foi codificado ou decodificado corretamente.
Alternativa 2 – criar uma tabela para o tipo enumerado em questăo. Esta abordagem apresenta dois inconvenientes: a proliferaçăo excessiva do número de tabelas e a necessidade de muitas junçőes para se obter o valor do item, podendo degradar o desempenho se as tabelas de tipos forem grandes (o que na maioria das vezes năo é o caso). Por outro lado, é a abordagem mais fácil de ser evoluída.
ESTADO_CIVIL INTEGER REFERENCES TIPO_ESTADO_CIVIL(ID), ...
TABLE TIPO_ESTADO_CIVIL
(
ID INTEGER NOT NULL PRIMARY KEY,
VALOR VARCHAR(10)
);
Alternativa 3 – criar uma tabela para abrigar mais de um tipo enumerado. Essa abordagem possui a vantagem de năo criar diversas tabelas auxiliares, que muitas vezes terăo apenas dois ou tręs valores, sendo tăo flexível ŕ evoluçăo do modelo quanto a alternativa 2. Em contrapartida é mais sujeita a problemas de desempenho, já que a tabela de tipos enumerados será maior.
CREATE TABLE TIPOS_ENUMERADOS
(
ID INTEGER NOT NULL PRIMARY KEY,
TIPO VARCHAR(32),
VALOR VARCHAR(32)
);
...
ESTADO_CIVIL INTEGER REFERENCES TIPOS_ENUMERADOS(ID)
O valor do campo Tipo será o nome da enumeraçăo. Para preencher uma combobox devemos realizar uma consulta ŕ tabela TIPOS_ENUMERADOS restringindo o tipo desejado.
Note que a chave estrangeira năo garante o preenchimento correto, pois a tabela de tipos pode conter outros valores além do conjunto de estados civis (como Sexo). Uma soluçăo seria criar um trigger para consultar a tabela de tipos e verificar se a entrada é válida. Uma forma de resolver esse problema sem sobrecarregar o banco seria fixar faixas para os IDs e definir restriçőes, com as mesmas ressalvas da alternativa 1. Por exemplo:
CREATE TABLE TIPOS_ENUMERADOS
(
ID INTEGER NOT NULL PRIMARY KEY,
TIPO VARCHAR2(32),
VALOR VARCHAR2(32),...
CHECK( (TIPO = ‘ESTADO_CIVIL’ AND ID BETWEEN 10 AND 19)
OR (TIPO = ‘ESTADO_PEDIDO’ AND ID BETWEEN 20 AND 29) ... )
);
...
ESTADO_CIVIL INTEGER REFERENCES TIPOS_ENUMERADOS(ID),
...
CHECK( ESTADO_CIVIL BETWEEN 11 AND 19 )
Observe que tomamos o cuidado de deixar buracos na seqüęncia de IDs, de forma a facilitar a inclusăo de valores no futuro: temos apenas cinco tipos de estado civil mas reservamos a faixa de 10 a 19.
Do ponto de vista da manutençăo, as alternativas 2 e 3 săo superiores ao uso de campos alfanuméricos. Além disso, cabe observar que o argumento de desempenho inferior muitas vezes năo se verifica na prática, pois como as tabelas de tipos săo pequenas e muito utilizadas, é quase certo de permanecerem em memória (no cache do banco) o tempo todo – sem mencionar que essas tabelas certamente terăo índices. Finalmente, a abordagem 2 é na verdade uma normalizaçăo relacional tradicional.
Cardinalidade: a cardinalidade de um atributo pode ser zero, um ou mais de um (quando se tratar de uma coleçăo). No segundo caso devemos colocar uma restriçăo para valores nulos. Quando se tratar de uma coleçăo, podemos criar uma tabela auxiliar contendo uma chave estrangeira para o ID da tabela original. Se a coleçăo năo permitir repetiçăo, deve-se criar uma restriçăo de unicidade contendo o campo e a chave estrangeira. Nesse caso, a criaçăo de um índice é recomendável. Assim, o mapeamento relacional para a classe CNH seria:
CREATE TABLE CNH
(
ID INTEGER NOT NULL PRIMARY KEY,
REGISTRO CHAR(20) UNIQUE NOT NULL
...
);
CREATE TABLE RENOVACOES_CNH
(
CNH_ID INTEGER NOT NULL REFERENCES CNH(ID) ON DELETE CASCADE,
DATA DATE NOT NULL,
UNIQUE( CNH_ID, DATA )
);
Persistęncia: Cabe observar que nem todos os atributos que figuram em uma classe serăo persistentes, ou seja, serăo armazenados. Muitos apenas existirăo em memória. O caso mais comum săo atributos derivados de cálculos realizados sobre outros atributos – idade, por exemplo. Uma soluçăo está no uso de visőes: a classe original é mapeada para um tabela com outro nome, a qual o programador/usuário năo tem acesso, e uma visăo contendo os atributos derivados é criada.
Visibilidade: usualmente os atributos năo săo visíveis fora da classe, ou seja, săo protegidos ou privados. Em um banco relacional isso é bastante difícil de implementar – uma alternativa seria criar visőes para restringir o acesso aos campos e stored procedures para realizar as alteraçőes. Felizmente, na maiorias dos sistemas, os dados a serem armazenados quase sempre săo públicos, ao menos para leitura.
Năo há muito o que fazer em relaçăo aos métodos – a maioria dos bancos relacionais possui o conceito de triggers e de stored procedures, que săo funçőes ou procedimentos executados no ambiente do banco de dados. Em algumas situaçőes esse mecanismo pode ser utilizado para simular métodos. Na maioria das vezes, no entanto, os métodos terăo de ser implementados através da linguagem de programaçăo utilizada para desenvolver a aplicaçăo e năo serăo executados no ambiente do banco de dados. Uma forma de minimizar o impacto na construçăo de aplicaçőes que compartilham o mesmo modelo de dados é o uso de bibliotecas para implementar tais métodos.
Os relacionamentos do modelo de classes săo relativamente simples de se mapear. Basicamente, será usada a mesma abordagem do modelo relacional, com a ressalva de que as tabelas que representam classes terăo como chave primária apenas o campo ID. Como conseqüęncia, todas as chaves estrangeiras também terăo apenas um campo. As cardinalidades devem ser corretamente refletidas no mapeamento.
Relacionamento 1 para 1: coloca-se uma restriçăo de chave estrangeira na chave primária da tabela que representa a parte opcional do relacionamento. Se ambas as pontas forem obrigatórias, talvez seja melhor juntar as duas classes em uma única tabela.
CREATE TABLE MULTA
(
ID INTEGER NOT NULL PRIMARY KEY,
...
);
...
CREATE TABLE RECURSO
(
ID INTEGER NOT NULL PRIMARY KEY REFERENCES MULTA(ID),
...
);
Se ambas as pontas forem opcionais é melhor inserir um novo campo em uma das tabelas, definido-o como chave estrangeira. Este campo poderá ser nulo.
Relacionamentos 1 para n: o mapeamento é semelhante a abordagem relacional, ou seja, colocaremos um campo na tabela que representa o lado N como chave estrangeira para o lado 1. Năo há como mapear a representaçăo de um lado N que seja obrigatório. Por outro lado, se o lado 1 for obrigatório, basta năo permitir valores nulos no campo que é chave estrangeira.
CREATE TABLE TIPO_INFRACAO
(
ID INTEGER NOT NULL PRIMARY KEY,
CODIGO CHAR(3) NOT NUL UNIQUE,
...
);
CREATE TABLE MULTA
(
ID INTEGER NOT NULL PRIMARY KEY,
TIPO_INFRACAO_ID INTEGER NOT NULL REFERENCES TIPO_INFRACAO(ID),
...
);
Relacionamentos m para n: nesse caso utilizaremos uma tabela auxiliar contendo dois campos, cada um sendo chave estrangeira para as tabelas que representam as pontas do relacionamento. Da mesma forma que na cardinalidade 1:N, năo há como representar diretamente a obrigatoriedade, ou seja, relacionamentos 1:M x 1:N.
O mapeamento da herança é o que apresenta a maior dificuldade e também o que traz mais conseqüęncias, tanto no desempenho quanto na facilidade de escrita de determinadas consultas. As escolhas săo: 1) representar todas as classes de uma hierarquia em uma única tabela, acrescentando um atributo Tipo para identificar a classe do objeto; 2) representar cada classe na hierarquia como uma tabela, representando os atributos comuns apenas na tabela que representa a classe pai, o que implica em realizar uma fragmentaçăo vertical; 3) representar cada classe concreta da hierarquia por uma tabela contendo todos os atributos da classe e de suas superclasses, realizando uma fragmentaçăo horizontal.
Todas as classes da hierarquia em uma única tabela: Um atributo Tipo é usado para indicar a classe de cada objeto. Como vantagem, temos que um objeto é armazenado em uma única tabela, tornando fácil a sua recuperaçăo. Além disso, consultas envolvendo superclasses também săo fáceis de serem realizadas.
CREATE TABLE PESSOA
(
ID INTEGER NOT NULL PRIMARY KEY,
TIPO CHAR(1) NOT NULL,
NOME VARCHAR2(50) NOT NULL,
ENDERECO VARCHAR2(60) NOT NULL,
CPF CHAR(8) UNIQUE,
DATA_NASCIMENTO DATE,
CGC CHAR(12) UNIQUE,
CHECK( TIPO IN (‘F’,’J’) ),
CHECK( (TIPO = ‘F’ AND CPF IS NOT NULL AND DATA_NASCIMENTO IS NOT NULL) OR (TIPO <> ‘F’ AND CPF IS NULL AND DATA_NASCIMENTO IS NULL),
CHECK( (TIPO = ‘J’ AND CGC IS NOT NULL) OR (TIPO <> ‘J’ AND CGC IS NULL),
);
CREATE TABLE RECURSO
(
ID INTEGER NOT NULL PRIMARY KEY,
...
PESSOA_ID INTEGER NOT NULL REFERENCES PESSOA(ID),
...
);
Neste caso podemos usar um trigger para garantir que o recurso está relacionado a uma pessoa física, ou alguma separaçăo por faixas de IDs, ou ainda aritmética módulo P (por exemplo, se forem duas classes, os IDs de uma serăo números pares e os IDs da outra números ímpares).
Observe que, se a chave estrangeira estiver na tabela que representa a hierarquia, năo há problema:
CREATE TABLE MULTA
(
ID INTEGER NOT NULL PRIMARY KEY,
TIPO CHAR(1) NOT NULL,
EQUIPAMENTO_ID REFERENCES EQUIPAMENTO(ID),
...
CHECK( TIPO IN (‘E’, ‘F’ ),
CHECK( (TIPO = ‘E’ AND EQUIPAMENTO_ID IS NOT NULL) OR (TIPO <> ‘E’ AND EQUIPAMENTO_ID IS NULL)
);
No mesmo caminho, se a chave estrangeira estiver conectada a classe raiz da hierarquia, também năo teremos problemas:
CREATE TABLE VEICULO
(
ID INTEGER NOT NULL PRIMARY KEY,
PESSOA_ID INTEGER NOT NULL REFERENCES PESSOA(ID),
...
);
Fragmentaçăo vertical: o nome provém do fato de que um objeto é “cortado” em duas ou mais partes, cada uma sendo representada em uma tabela diferente. Ou seja, é como se a tabela da primeira abordagem fosse cortada na vertical. Como a cardinalidade será 1:1, todas as tabelas que representam subclasses terăo o campo ID como chave primária e também como chave estrangeira para a tabela que representa a superclasse. Nesta última, o campo ID será apenas chave primária. Veja o exemplo:
CREATE TABLE PESSOA
(
ID INTEGER NOT NULL PRIMARY KEY,
NOME VARCHAR2(50) NOT NULL,
ENDERECO VARCHAR2(60) NOT NULL
);
CREATE TABLE PESSOA_FISICA
(
ID INTEGER NOT NULL PRIMARY KEY REFERENCES PESSOA(ID) ON DELETE CASCADE,
CPF CHAR(8) NOT NULL UNIQUE,
DATA_NASCIMENTO DATE NOT NULL
);
CREATE TABLE PESSOA_JURIDICA
(
ID INTEGER NOT NULL PRIMARY KEY REFERENCES PESSOA(ID) ON DELETE CASCADE,
CGC CHAR(12) NOT NULL UNIQUE
);
Essa abordagem pode ser utilizada também para representar herança múltipla. A grande vantagem é que eventuais evoluçőes em quaisquer classes da hierarquia săo bastante localizadas, sendo fáceis de implementar. Além disso, os relacionamentos podem fazer uso direto da integridade referencial oferecida pelo próprio banco de dados.
CREATE TABLE MULTA
(
ID INTEGER NOT NULL PRIMARY KEY,
PESSOA_ID INTEGER NOT NULL REFERENCES PESSOA(ID),
...
);
A principal desvantagem é o desempenho: a constante realizaçăo de junçőes para recuperar um único objeto pode tornar as consultas mais simples grandes consumidoras de recursos, afetando o desempenho do banco como um todo.
Fragmentaçăo horizontal: de forma análoga, corresponde a realizar um corte horizontal na tabela da primeira abordagem. Apenas as classes concretas (ou seja, classes que possuem instâncias) serăo representadas no modelo. Os atributos que existirem nas superclasses serăo repetidos nas tabelas que representam as classes concretas, de forma que um objeto estará inteiramente contido em uma única tabela. Com isso, é desnecessário a realizaçăo de junçőes com superclasses para recuperar todos os campos de um único objeto.
CREATE TABLE PESSOA_FISICA
(
ID INTEGER NOT NULL PRIMARY KEY,
NOME VARCHAR2(50) NOT NULL,
ENDERECO VARCHAR2(60) NOT NULL
CPF CHAR(8) NOT NULL UNIQUE,
DATA_NASCIMENTO DATE NOT NULL
);
CREATE TABLE PESSOA_JURIDICA
(
ID INTEGER NOT NULL PRIMARY KEY,
NOME VARCHAR2(50) NOT NULL,
ENDERECO VARCHAR2(60) NOT NULL
CGC CHAR(12) NOT NULL UNIQUE
);
Uma das desvantagens dessa abordagem săo as consultas que envolvem a superclasse: para listar todas as pessoas, físicas e jurídicas, devemos realizar uma uniăo entre as duas tabelas selecionando os atributos da superclasse (no caso, id, nome e endereço). Além disso, é difícil implementar relacionamentos envolvendo uma classe que tenha subclasses. O mecanismo de chaves estrangeiras do banco năo poderá ser aproveitado, devendo ser substituído por um trigger que verifique se o valor está presente em uma das tabelas que representam as subclasses. Por exemplo:
CREATE TABLE MULTA
(
ID INTEGER NOT NULL PRIMARY KEY,
PESSOA_ID INTEGER NOT NULL,
...
);
Dentro de um trigger de insert ou update validamos se o atributo PESSOA_ID é chave de pessoa física ou pessoa jurídica. Alteraçőes nas superclasses terăo de ser refletidas em todas as subclasses, tornando a manutençăo trabalhosa. É necessário também assegurar que os IDs das duas tabelas sejam únicos, ou seja, năo pode haver uma pessoa física com o mesmo ID de uma pessoa jurídica – isto pode ser garantido através de faixas de valores, ou aritmética módulo P. Claramente, esta abordagem apresenta sérios problemas de manutençăo e também problemas para o mapeamento correto de determinadas construçőes, devendo ser evitada principalmente quando existirem relacionamentos envolvendo a superclasse.
As restriçőes explicitadas em um modelo de classes e objetos devem ser implementadas através dos mecanismos já existentes no próprio banco de dados e, quando isto năo for possível, através do uso de triggers. A dificuldade básica desta abordagem consiste em identificar qual evento acionará o trigger. Por exemplo, na regra “năo é permitido criar um recurso para uma multa que já venceu” é fácil reconhecer que devemos criar um trigger no evento de inserçăo da tabela Multa. No entanto, as restriçőes nem sempre serăo tăo simples. Este tema é bastante complexo e năo será discutido nesse artigo.
Deve-se ter em mente que, apesar de se estar usando um modelo OO, todos os mecanismos disponíveis no banco de dados relacional, tais como integridade referencial, unicidade, restriçőes e validaçőes, devem ser utilizados para garantir o estado válido dos dados. Por outro lado, o que deve guiar um bom mapeamento é o grau de fidelidade ao modelo de classes e objetos, sempre contraposto ŕ razăo custo/benefício. Năo se deve realizar o mapeamento com um “pensamento relacional”, aplicando técnicas de identificaçăo de entidades e normalizaçăo de forma cega – o produto final pode ficar tăo distante do modelo original que a programaçăo e manutençăo se tornarăo extremamente difíceis.
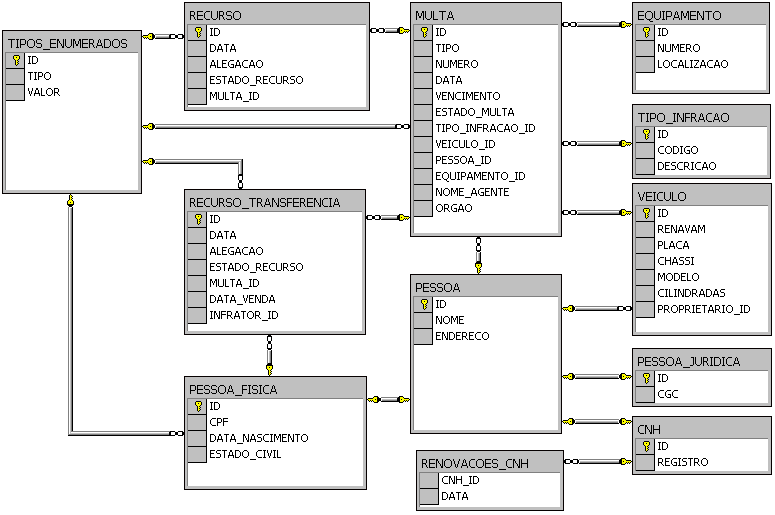
O mapeamento proposto para modelo de classes deste artigo pode ser visualizado na figura 2. O script completo para criaçăo do banco de dados está disponível para download.
| Construçăo | Mapeamento |
|---|---|
| Identidade | Chaves primárias artificiais |
| Classes | Tabelas |
| Atributos | Colunas de tabelas |
| Métodos | Stored procedures ou funçőes fora do banco de dados |
| Relaçőes | Chaves estrangeiras e tabelas de relacionamento |
| Herança | Tabelas, visőes e particionamentos horizontais ou verticais |
| Restriçőes | Constraints e triggers |
Em modelos maiores, a tabela TIPOS_ENUMERADOS pode ser escondida, para melhor legibilidade.

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.