
eterminado lugar pode ser considerado para muitos uma arte, isso porque sempre existem vários caminhos que levam ao mesmo destino. Executar uma tarefa da forma mais eficiente possível requer que o caminho percorrido seja o melhor dentre as centenas de variáveis que podem influenciar na escolha do melhor percurso.
No SQL Server o responsável por calcular a maneira mais eficiente de acesso aos dados é chamado de Query Processor, ele é dividido em duas partes, o Query Optimizer e o Query Execution Engine. Veremos neste artigo como o Query Optimizer funciona e quais os passos necessários para execuçăo de um comando T-SQL.
Entender como funciona e como interpretar o trabalho do Query Optimizer é uma das melhores maneiras de aprimorar seus conhecimentos em SQL Server. Esse conhecimento será de grande valor quando vocę precisar fazer algum trabalho de tunning em banco de dados.
Preparando o ambiente
Para melhor entendimento dos exemplos deste artigo criaremos uma tabela, com alguns dados e uma visăo, que servirăo como base para os testes que serăo apresentados. A Listagem 1 contém o script para criaçăo destes objetos.
O Script cria a tabela Funcionarios com algumas informaçőes (ID, Nome, Salário, Telefone e Cidade) e, em seguida, săo inseridos alguns registros. Logo após, uma view (vw_Funcionarios) é criada. A grosso modo, podemos dizer que Views săo tabelas virtuais definidas por uma consulta T-SQL. A nossa view, criada na Listagem 1, retorna o nome e o salário de todos os funcionários que ganham mais de R$ 900,00.
Listagem 1. Script para criaçăo dos objetos de teste
CREATE TABLE Funcionarios(ID Int IDENTITY(1,1) PRIMARY KEY,
Nome VarChar(30),
Salario Numeric(18,2),
Telefone VarChar(15),
Cidade VarChar(80));
INSERT INTO Funcionarios(Nome, Salario, Telefone, Cidade)
VALUES('José', 850.30, '11-55960015', 'Săo Paulo');
INSERT INTO Funcionarios(Nome, Salario, Telefone, Cidade)
VALUES('Antonio', 950, '11-81115544', 'Săo Paulo');
INSERT INTO Funcionarios(Nome, Salario, Telefone, Cidade)
VALUES('Joăo', 1200, '11-44123321', 'Săo Paulo');
CREATE VIEW vw_Funcionarios
AS
SELECT Nome, Salario FROM Funcionarios
WHERE Salario > 900 Query Optimizer
Quando um comando T-SQL é executado no SQL Server, o Query Processor entra em açăo para gerar um plano de execuçăo. Este plano dirá qual é a melhor maneira de acessar os dados gastando menos recursos e com o desempenho mais eficiente possível.
Podemos observar na Figura 1 a açăo do Query Optimizer (em vermelho) e uma série de passos para compilar e executar um comando T-SQL. Vamos analisar melhor este comportamento.
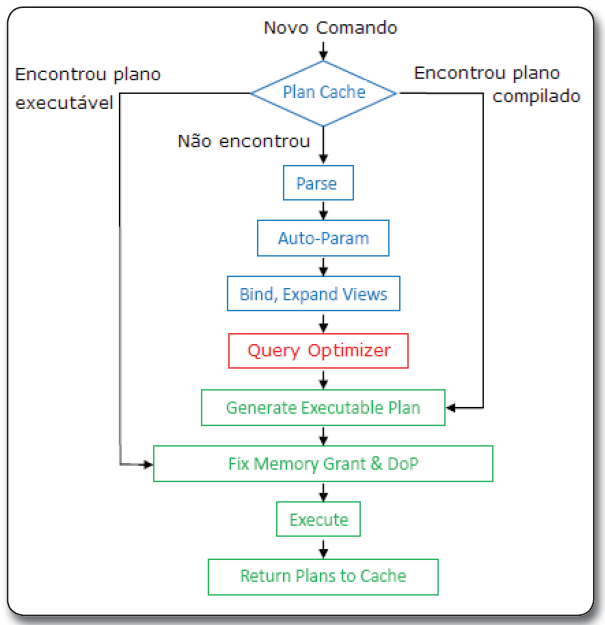
Figura 1. Fluxograma de passos necessários para gerar um plano de execuçăo
Supondo que um SELECT simples, por exemplo, SELECT * FROM Funcionarios, seja enviado ao servidor, a primeira tarefa que o Query Processor fará com o comando é verificar se o mesmo está no Cache Plan (mais informaçőes sobre o Cache Plan no final do artigo). Caso ele năo esteja em cache, o Query Processor enviará o comando para os processos de Parse e Bind.
O Parse/Bind executa um processo conhecido como Algebrizer. Durante este processo o SQL tenta encontrar possíveis erros de escrita na sintaxe e lógica do comando. Por exemplo, o comando “select id from tab1 group by nome” gera uma exceçăo, pois a coluna id năo pertence ao group by e năo está utilizando uma funçăo de agregaçăo (SUM, COUNT, ...). O Algebrizer também expande as definiçőes do comando, isso significa que ele troca “select *” por “select col1, col2, col3...”, ou “select col1 from View” pelo nome das tabelas envolvidas na view.
Sempre que uma view é referenciada em uma consulta, o SQL Server acessa as tabelas que contém os dados. Na Figura 2, por exemplo, podemos visualizar que o SQL acessa a tabela Funcionarios para ler os valores das colunas Nome e Salario.

Figura 2. Ilustraçăo de uma View acessando uma tabela.
Outro passo será resolver os nomes e tipos de objetos envolvidos na consulta. Pode acontecer de haver um sinônimo para uma determinada tabela que está em outro servidor. Quando isso acontece, o SQL precisa identificar que este sinônimo faz referęncia a um objeto que está em outro banco de dados, e este banco pode estar até mesmo ligado a outro servidor utilizando um Linked Server.
Após estas análises o Parse/Bind retorna um binário chamado Query Processor Tree, que é uma representaçăo lógica dos passos necessários para a execuçăo do comando SQL. O Query Processor Tree é enviado para o próximo passo da execuçăo da consulta, que é a análise do Query Optimizer.
É importante destacar que nem sempre um comando é enviado para a análise do Query Optimizer. Por exemplo, alguns comandos DDL, tais como o CREATE Table, que săo de definiçăo das estruturas dos dados, năo tęm necessidade de uma análise do Query Optimizer, pois só há uma forma de o SQL executar esta operaçăo.
...






