Atençăo: esse artigo tem uma palestra complementar. Clique e assista!
Desenvolvimento de soluçőes para problemas cotidianos enfrentados por DBAs e desenvolvedores de aplicaçőes para banco dados.
Para que serve?
Fornecer conceitos de utilizaçăo de funcionalidades do padrăo SQL ANSI na resoluçăo de problemas enfrentados no dia-a-dia na recuperaçăo de informaçőes do banco de dados.
Em que situaçăo o tema é útil?
Integridade referencial.
Estamos de volta com a coluna Desafio SQL. Para quem nunca a leu, tratamos aqui de problemas enfrentados no dia-a-dia pelos profissionais que trabalham com bancos de dados. E para situarmos estes desafios, a cada artigo contamos um novo capítulo da história da empresa fictícia chamada ItsMyBusiness.
Por curiosidade, lembro aos interessados que esta história começou faz um bom tempo, na Revista #50. Este é o 14o capítulo desta "novela" (no bom sentido, claro).
A ItsMyBusiness é uma empresa de varejo que fez recentemente o seu site de e-commerce. E este site está "bombando"!
Vender mais significa mais dinheiro. Mas do ponto de vista de um banco de dados, representa também um volume maior de transaçőes, maiores cuidados com performance, com armazenamento de dados e disponibilidade do sistema.
Estes săo quesitos que devemos ter em mente desde o início da modelagem de qualquer banco. Mas o fato é que a ItsMyBusiness tratou seu e-commerce como se fosse uma experięncia e năo tomou cuidados básicos com a criaçăo deste sistema.
Se vocę achou que este cenário se parece com o de algum sistema real com o qual vocę trabalhou, isso năo é mera coincidęncia. É triste dizer, mas isso é terrivelmente comum. As empresas economizariam muito dinheiro se seguissem noçőes básicas de projeto.
Bom ou mal, certo ou errado, o fato é que agora a ItsMyBusiness tem que consertar o "motor do seu carro" quando a corrida já está em andamento. Uma série de melhorias e correçőes de bugs no modelo do banco de dados da empresa tem sido feitas nos últimos meses.
No nosso último desafio, apresentamos uma soluçăo de modelagem para melhorar o controle sobre os pedidos que a ItsMyBusiness recebe. A soluçăo previa o detalhamento dos possíveis status que um pedido poderia ter ao longo da sua história, ou seja, desde o momento em que ele é submetido pelo cliente até o momento em que ele é encerrado pela empresa (seja por qual razăo for).
Esta mesma soluçăo incluía a integridade referencial dos dados, ou seja, nosso modelo deveria garantir que os dados registrados no banco fossem 100% consistentes.
O modelo final da base, já incluídas as alteraçőes citadas acima, é apresentado a seguir (Figura 1).
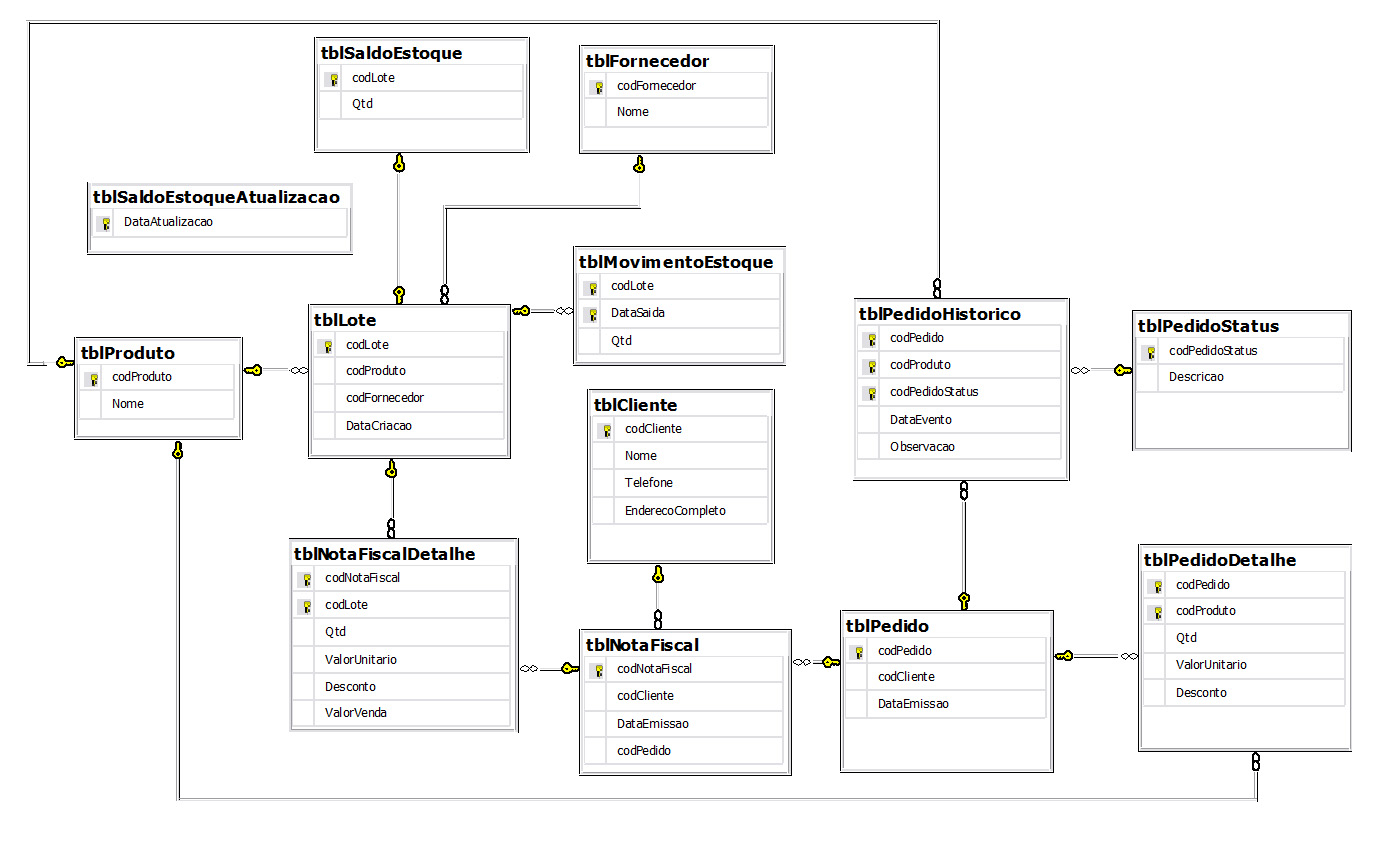
Figura 1. Modelo de dados simplificado da empresa ItsMyBusiness.
O script de criaçăo deste banco de dados está disponível para download no portal da SQL Magazine. O script apresenta versőes para rodar em SQL SERVER, DB2, ORACLE e FIREBIRD.
Voltando ao nosso assunto, para sorte da empresa ItsMyBusiness, o DBA que ela contratou, que no caso é vocę, é um cara muito cuidadoso.
Antes de implementar esta soluçăo, o DBA abriu seu caderno de anotaçőes e viu a seguinte frase escrita 100 vezes em letras garrafais:
“NUNCA FAREI ALTERAÇŐES NO MEU AMBIENTE DE PRODUÇĂO ANTES DE VALIDAR MINHAS SOLUÇŐES EM UM AMBIENTE DE TESTES QUE SIMULE A OPERAÇĂO REAL”.
Entăo ele passou o script de alteraçăo da base para a equipe de testes, que depois de avaliar dezenas de casos de teste, apresentou o seguinte veredito:
“Por razőes desconhecidas, o modelo em análise permite a inserçăo manual de informaçőes inconsistentes na tabela tblPedidoStatus. O problema foi observado quando fizemos inserçăo de dados usando uma declaraçăo SQL do tipo INSERT”.
Xiiii... a casa caiu!
Na verdade, ainda năo caiu, porque a alteraçăo năo foi para produçăo e é para isso mesmo que fazemos testes meticulosos antes de qualquer implementaçăo.
Já sabemos qual é o problema, pois os testadores năo só disseram que o modelo “deu pau”. Eles disseram detalhadamente o que eles estavam fazendo quando o erro foi observado.
O que houve foi o seguinte: foram executadas várias declaraçőes de inserçăo de dados na tabela dbo.tblPedidoHistorico. Algumas delas deveriam ser aceitas e outras deveriam ser rejeitadas. Chamamos isso de casos de testes.
Na Listagem 1 vemos quatro casos de teste que deveriam ser rejeitados.
Listagem 1. Os testes de rejeiçăo .
1 -- Inserçăo de código de pedido inexistente
2 --=====> Insert REJEITADO (CORRETO)
3 INSERT INTO dbo.tblPedidoHistorico
4 (codPedido, codProduto, codPedidoStatus, Observacao)
5 VALUES (1000, 1,1, 'nao existe pedido # 1000')
6
7 -- Inserçăo de código de produto inexistente
8 --=====> Insert REJEITADO (CORRETO)
9 INSERT INTO dbo.tblPedidoHistorico
10 (codPedido, codProduto, codPedidoStatus, Observacao)
11 VALUES (1, 2000 ,1, 'nao existe produto # 2000')
12
13 -- Insercao de código de status inexistente
14 --=====> Insert REJEITADO (CORRETO)
15 INSERT INTO dbo.tblPedidoHistorico
16 (codPedido, codProduto, codPedidoStatus, Observacao)
17 VALUES (1, 1, 3000, 'nao existe status # 3000')
18
19 -- Insercao com produto que năo pertence ao pedido
20 --=====> Insert ACEITO (ERRADO!!!!!!!!!!!!!)
21 INSERT INTO dbo.tblPedidoHistorico
22 (codPedido, codProduto, codPedidoStatus, Observacao)
23 VALUES (1, 8, 1, 'o produto # 8 nao faz parte do pedido # 1')Nos tręs primeiros, tentamos inserir códigos que năo existem (linhas 1 a 22 da Listagem 1) e todos eles foram corretamente rejeitados.
Mas no quarto teste houve um erro. Neste teste, tínhamos códigos válidos para os campos codPedido, codProduto e codPedidoStatus. Mas o produto descrito năo faz parte daquele pedido. O banco deveria rejeitar esta inserçăo, mas ele erradamente a aceitou (linhas 19 a 23).
Agora volta tudo para as suas măos, já que vocę é o DBA/arquiteto/desenvolvedor responsável por este projeto. Sua missăo é:
1. identificar onde está o problema
2. propor uma nova soluçăo
Divirta-se!
Resposta do desafio
Muita gente simplesmente despreza o uso de chaves estrangeiras dentro dos seus bancos de dados. A maioria dos sistemas de gestăo empresarial com os quais eu trabalhei as tratam como se fossem um pecado que deve ser evitado a qualquer custo.
A alegaçăo é que as chaves estrangeiras tem impacto na performance do banco, porque o banco de dados sempre fará a validaçăo dos dados contra cada uma das chaves estrangeiras existentes numa tabela toda vez que for executar qualquer declaraçăo INSERT, DELETE ou UPDATE.
Isso é verdade. Existe mesmo um pequeno custo. E vai acontecer a cada transaçăo que ocorrer no seu banco de dados, exigindo um pouco mais de tempo para execuçăo de qualquer inserçăo, exclusăo ou alteraçăo nos seus dados.
Mas este pensamento estreito esquece um pequeno detalhe: a qualidade dos dados armazenados no seu banco. A integridade referencial (e todos os recursos que ela nos oferece, como é o caso das chaves estrangeiras) existe para garantir a consistęncia das informaçőes.
Para uma empresa que vive na era da informaçăo, é muito mais caro dispor de informaçőes erradas e/ou inconsistentes do que levar um pouco mais de tempo para realizar cada transaçăo.
Pessoalmente, eu uso chaves estrangeiras em todos os modelos de dados que eu crio e năo vejo motivo que justifique a sua ausęncia.
Mas vamos ao que interessa.
Em primeiro lugar, temos que traduzir as palavras dos testadores em termos do modelo do banco de dados.
Quando dissemos "o produto descrito năo faz parte daquele pedido", precisamos entender como o modelo lida com esta informaçăo. Por isso vamos ver esta parte do modelo com maior detalhe (Figura 2).
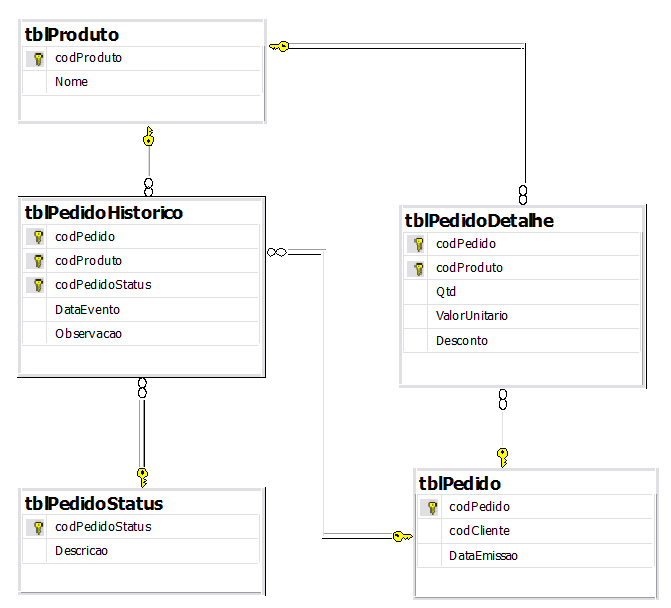
Figura 2. Tratamento do ciclo de vendas.
Veja que o modelo usa a tabela dbo.tblPedidoDetalhe exatamente para armazenar as informaçőes dos produtos que fazem parte de cada pedido. Tanto é assim que a chave primária desta tabela é composta pelos campos código de Pedido e código de Produto.
Entendendo isso, podemos reformular a frase que apresentamos acima. Em termos do modelo de dados, estamos falando que năo existe na tabela dbo.tblPedidoDetalhe nenhuma chave primária composta pelos código de Pedido e código de Produto que estamos inserindo na tabela de histórico do status do pedido.
Para todos os efeitos práticos, nós acabamos de responder a primeira pergunta deste desafio!
Olhe novamente o modelo na Figura 2. Veja que a integridade referencial que criamos no último desafio năo garante que a tabela dbo.tblPedidoHistorico receba combinaçőes de códigos de pedido e de produto que já estejam cadastrados na tabela dbo.tblPedidoDetalhe.
Ao invés disso, a definiçăo existente garante apenas que năo poderemos cadastrar códigos de pedido e de produto que năo existam nas tabelas dbo.tblPedido e dbo.tblProduto, respectivamente. Mas isso năo faz tudo o que precisamos.
Escrevendo explicitamente a resposta ŕ primeira pergunta: o modelo em teste năo usa a integridade referencial adequada para a tabela dbo.tblPedidoHistorico, a qual precisa ser alterada.
Entăo tá, sabemos o que está errado. Mas o que vamos fazer para corrigir?
Bom, nós precisamos criar chaves estrangeiras na tabela dbo.tblPedidoHistorico que façam referęncia ŕ chave primária da tabela dbo.tblPedidoDetalhe. E a chave primária é formada pelo par de campos codPedido + codProduto.
Maravilha. A soluçăo parece simples. E aí vem outra pergunta: o que fazer com as chaves estrangeiras existentes?
Essa é uma boa pergunta. Muita gente acaba deixando “lixo” para trás dentro do banco de dados simplesmente porque ele parece “inofensivo”. Mas se as chaves existentes năo resolvem o problema que deveriam cuidar, é muito importante avaliar se elas podem simplesmente ser eliminadas. Lembre-se que seria uma perda de tempo deixar para trás chaves estrangeiras inúteis, porque isso tem sim um pequeno impacto na performance do sistema, como eu já comentei anteriormente.
No caso em questăo, basta olharmos para Figura 2 para termos uma resposta. A tabela dbo.tblPedidoHistorico possui tręs chaves estrangeiras: uma referenciando dbo.tblPedidoStatus, outra referenciando dbo.tblPedido e a terceira referenciando dbo.tblProduto.
A primeira delas, criada sobre o campo codPedidoStatus, năo é afetada pela soluçăo proposta. Portanto ela fica.
Já sobre as duas outras, veja que elas săo idęnticas ŕs chaves estrangeiras que existem na tabela dbo.tblPedidoDetalhe: uma referenciando a tabela dbo.tblPedido e outra referenciando dbo.tblProduto.
Como nós vamos criar uma nova chave estrangeira em dbo.tblPedidoHistorico referenciando exatamente a tabela dbo.tblPedidoDetalhe, seria redundante manter as referęncias antigas. Entăo devemos excluir ambas.
Para isso, vamos precisar saber os nomes das chaves que serăo excluídas. E esta parte nem sempre é tăo fácil... E cada SGBD tem um meio de lhe mostrar esta informaçăo.
No SQL SERVER, por exemplo, existem visőes de sistema (as Dynamic Management Views ou DMVs) que nos dăo estas e outras informaçőes. Aos interessados, recomendo dar uma olhada na soluçăo apresentada por Pinal Dave (http://blog.sqlauthority.com/2007/09/04/sql-server-2005-find-tables-with-foreign-key-constraint-in-database/).
Respondemos metade da segunda pergunta. Dissemos o que fazer, mas năo como fazer a alteraçăo.
Faltou criarmos uma nova chave estrangeira referenciando dois campos ao mesmo tempo. O padrăo ANSI SQL prevę esta situaçăo de forma muito simples e intuitiva: basta referenciar os dois campos desejados, separando-os por uma vírgula.
A Listagem 2 mostra o script final incluindo a exclusăo das chaves antigas e a criaçăo da nova chave. Este script é válido para SQL SERVER, DB2 e ORACLE.
Listagem 2. Soluçăo do desafio (SQL SERVER, DB2 e ORACLE).
1 --exclui FKs existentes
2 ALTER TABLE dbo.tblPedidoHistorico
3 DROP CONSTRAINT FK_tblPedidoH_tblPedido
4 ;
5
6 ALTER TABLE dbo.tblPedidoHistorico
7 DROP CONSTRAINT FK_tblPedidoH_tblProduto
8 ;
9
10 --cria a FK correta!!!
11 ALTER TABLE dbo.tblPedidoHistorico
12 ADD CONSTRAINT fkPedidoH_DUPLO
13 FOREIGN KEY (codPedido, codProduto)
14 REFERENCES dbo.tblPedidoDetalhe(codPedido, codProduto)
15 ;Para o FIREBIRD, a única alteraçăo necessária é excluir a referęncia ao esquema “dbo”, já que este SGBD năo usa nome de esquema e/ou login ŕ frente do nome dos objetos. O restante da sintaxe é idęntico, conforme Listagem 3.
Listagem 3. Soluçăo do desafio (FIREBIRD).
1 --exclui FKs existentes
2 ALTER TABLE tblPedidoHistorico
3 DROP CONSTRAINT FK_tblPedidoH_tblPedido
4 ;
5
6 ALTER TABLE tblPedidoHistorico
7 DROP CONSTRAINT FK_tblPedidoH_tblProduto
8 ;
9
10 --cria a FK correta!!!
11 ALTER TABLE tblPedidoHistorico
12 ADD CONSTRAINT fkPedidoH_DUPLO
13 FOREIGN KEY (codPedido, codProduto)
14 REFERENCES dbo.tblPedidoDetalhe(codPedido, codProduto)
15 ;
Com isso terminamos o desafio SQL deste męs. Agora podemos passar a correçăo do código para nova série de testes e, se tudo der certo, em breve teremos as novas implementaçőes rodando no ambiente de produçăo da ItsMyBusiness!
Espero que vocę tenha gostado.







