Atençăo: esse artigo tem uma palestra complementar. Clique e assista!
Entender como as statistics e histograms auxiliam o CBO (Cost Based Optimizer – Otimizador Baseado em Custo).
Para que serve?
Para entendermos o impacto que estatísticas obsoletas ou ausentes causam nos planos de execuçăo.
Em que situaçăo o tema é útil?
Na análise de comandos SQL com problemas de desempenho.
O otimizador é o programa que realiza a transformaçăo de comandos SQL em planos de execuçăo. A partir do Oracle na versăo 7, introduziu-se o Cost Based Optimizer (CBO) que, como o nome sugere, baseia-se no custo das operaçőes. A partir do Oracle na versăo 10g, esse otimizador se tornou default, sendo que seu antecessor, baseado em regras é bem mais simples de ser compreendido já que funciona a partir de 15 regras pré-definidas năo levando em consideraçăo a distribuiçăo dos dados (ele é influenciado pela sintaxe do comando e ainda existe apenas por questőes de compatibilidade). De acordo com [1], [2] e [3] (ver Referęncias Bibliográficas), o CBO gera suas estimativas para acesso aos dados baseado nas métricas de custo, cardinalidade e seletividade, sendo influenciado por parâmetros, statistics e hints (diretivas de compilaçăo). Daí a importância de entendermos como as estatísticas funcionam e auxiliam o CBO na geraçăo do plano de execuçăo.
Antes de entrarmos no tópico de estatísticas vamos entender um pouco mais sobre o otimizador e como săo gerados os planos de execuçăo. O CBO é dividido em 3 componentes principais, conforme mostrado na Figura 1.
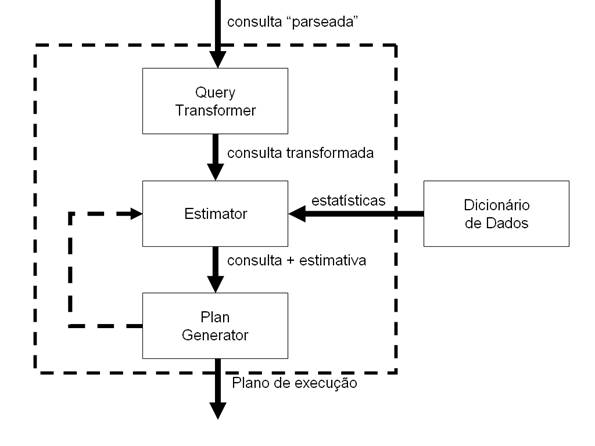
Figura 1. Componentes do CBO
O Query Transformer recebe um comando proveniente do analisador gramatical e o divide em diferentes blocos relacionados entre si. Seu objetivo é verificar se existe alguma forma mais otimizada para o comando em que se obtenha o mesmo resultado, gerando assim o melhor plano de execuçăo. Para isto ele utiliza técnicas como:
• view merging: quando o analisador gramatical se depara com uma visăo em um comando, ele a coloca em um bloco separado. O otimizador verifica qual é a melhor maneira de resolver essa visăo com a criaçăo de “sub-planos”. Após ter otimizado o bloco contendo a visăo, o query transformer tenta agrupá-lo a outros blocos da consulta;
• subquery unnesting: assim como as visőes, as sub-consultas săo colocadas em blocos separados pelo analisador gramatical. O query transformer busca a melhor forma de resolver este comando, encontrando a maneira mais otimizada de resolver a sub-consulta e agrupando em um bloco da consulta principal, transformando esta consulta em uma junçăo da consulta principal;
• query rewrite with materialized views: uma visăo materializada é similar a uma consulta armazenada em uma tabela. Quando o query transformer encontra uma consulta compatível com uma materialized view, a consulta é reescrita para utilizar a estrutura. Isto traz ganhos de desempenho, uma vez que parte do resultado já está previamente pronto, dispensando a necessidade de executá-lo novamente;
• predicate pushing: agrega um predicado que fica fora da visăo para dentro da visăo se isso melhorar na geraçăo dos planos de execuçăo.
O Estimator é responsável por indicar o esforço estimado para cada plano apresentado pelo QueryTransformer. Para gerar o custo, o estimator baseia-se em duas métricas: seletividade e cardinalidade, que serăo explicados no decorrer deste artigo.
O Plan Generator testa diferentes planos de execuçăo para uma consulta e escolhe aquele que apresenta o menor custo. Estes planos săo gerados com variaçőes de formas de acesso, formas de junçăo e ordens de junçăo. Para gerar o plano de execuçăo de uma consulta, săo gerados os sub-planos para cada bloco de visőes năo agrupadas e sub-consultas. Estes blocos săo otimizados separadamente de baixo para cima, ou seja, a sub-consulta mais interna é otimizada em primeiro lugar, e um sub-plano é gerado para ela. Já a consulta mais externa é a última a ser otimizada. O número de planos possíveis é proporcional ŕ quantidade de junçőes na clausula FROM. Para iniciar uma pesquisa pelo melhor plano, o gerador de planos organiza os itens da junçăo de acordo com sua cardinalidade, o item de menor cardinalidade é colocado em primeiro lugar e assim sucessivamente até o item de maior cardinalidade.
Agora vamos definir rapidamente os conceitos que influenciam o comportamento do otimizador:
• Custo: número gerado pelo otimizador para determinar o melhor método de acesso (estimativa);
• Seletividade: porcentagem de linhas retornadas conforme a aplicaçăo de uma condiçăo (filtro). A fórmula utilizada para cálculo depende da distribuiçăo dos dados e da quantidade de buckets. Para as situaçőes que analisaremos neste artigo utilizaremos as tręs Equaçőes 1, 2 e 3.
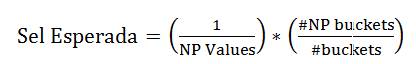
Equaçăo 1. Seletividade para valores năo-populares
...






