Clique aqui para ler esse artigo em PDF.![]()

Clique aqui para ler todos os artigos desta ediçăo
A tecnologia XML e sua integraçăo com Banco de Dados
Embora a Internet possa ser considerada um gigantesco banco de dados, seus dados năo estăo bem organizados. Ou seja, a Internet é uma coleçăo de dados irregular, heterogęnea e distribuída. Para trazer mais ordem ŕ representaçăo dessa imensa quantidade de informaçőes nesse ambiente, foi proposto um novo padrăo, o XML (eXtensible Markup Language).
Outro objetivo do XML consistia em facilitar o intercâmbio e a publicaçăo de dados em aplicaçőes para a Internet. Assim, as aplicaçőes poderiam trocar informaçőes através de um formato de representaçăo de dados comum. No entanto, o XML vem sendo utilizado para propósitos cada vez mais diferentes, como, por exemplo, o desenvolvimento de serviços WEB (web services). Um outro exemplo: a OMG (Object Management Group) está definindo dois novos padrőes baseados em XML, o MOF (Meta- Object Facility) e o XMI (XML Metadata Interchange), que permitem a interoperabilidade entre ferramentas CASE de acordo com modelos de software definidos em UML.
A crescente aceitaçăo do XML e seu uso cada vez maior tendem a gerar uma quantidade enorme de dados nesse formato. Muitos desses dados săo transientes (passageiros) e năo precisam ser armazenados, mas existem também aqueles que precisam ser armazenados. Em funçăo disso, a tecnologia de bancos de dados tem se deparado com dois novos desafios: (1) armazenar documentos XML internamente no SGBD, criando mecanismos para consultá-los e atualizá-los de forma eficiente, e (2) integrar dados já existentes (legados) com os dados no formato XML.
Os desafios descritos acima se traduzem na demanda por interoperabilidade entre os modelos de dados relacional e objeto-relacional de um lado e o modelo de dados XML de outro. O resultado disso é que as principais empresas que desenvolvem gerenciadores de bancos de dados (Oracle, IBM, Microsoft) estăo investindo na construçăo de versőes de seus respectivos produtos para atender a esses desafios. Além disso, vemos hoje o surgimento de SGBDs XML Nativos, como o Tamino XML Server e o Berkeley DB XML.
Este artigo, além de introduzir os principais conceitos referentes ao XML, resume as principais estratégias propostas pela tecnologia de bancos de dados para o armazenamento e processamento de dados XML.
XML: uma Breve Introduçăo
O XML é uma metalinguagem, ou seja, uma linguagem que permite definir novas linguagens através da criaçăo customizada de marcaçőes. Uma linguagem de marcaçăo de texto possui um conjunto de marcadores (também conhecidos como tags) que săo utilizados para atribuir determinadas características a uma informaçăo (um exemplo de linguagem de marcaçăo é a HTML).
O XML é também um formato de representaçăo independente de plataforma, porque o conteúdo de um documento em XML é texto plano em formato Unicode; pode-se visualizá-lo com um simples editor de textos. A especificaçăo do padrăo XML foi feita pelo W3C (World Wide Web Consortium).
Nota: observe que o termo XML normalmente pode ser usado para duas definiçőes distintas: ele pode ser tanto o padrăo que especifica a metalinguagem como o modelo de dados correspondente. Neste artigo, utilizarei esse termo para ambas as situaçőes, mas o contexto em que o utilizo deverá ser suficiente para eliminar qualquer ambigüidade.
Informalmente, o XML pode ser visto como um formato de representaçăo de dados. O modelo de dados XML permite representar dados através de dois componentes: elementos e atributos. Para descrever esses componentes, considere o exemplo fornecido na Listagem 1.
Listagem 1 - Exemplo de documento XML
<?xml version=”1.0”?>
<ordensCompra>
<ordemCompra dataCompra=”13-09-2003”>
<nomeCliente>Daniela Florescu</nomeCliente>
<endereço>
<rua>Rua Florianópolis, 31</rua>
<cidade>Rio de Janeiro</cidade>
<estado>RJ</estado>
<cep>22733-000</cep>
</endereço>
<itensCompra>
<item>
<idProduto>1203-AA</idProduto>
<nomeProduto>Monitor SyncMaster 3Ne</nomeProduto>
<preço>250.00</preço>
</item>
<item>
<idProduto>1364-FS</idProduto>
<nomeProduto>Mouse Ótico Microsoft</nomeProduto>
<quantidade>1</quantidade>
<preço>43.00</preço>
</item>
<item>
<idProduto>1764-GE</idProduto>
<nomeProduto>HP Deskjet 840C</nomeProduto>
<quantidade>1</quantidade>
<preço>172.00</preço>
</item>
</itensCompra>
</ordemCompra>
<ordemCompra dataCompra=”15-09-2003”>
<nomeCliente> Victor Vianu </nomeCliente>
<endereço>
<rua>Rua Araguaia, 128</rua>
<cidade>Săo Paulo</cidade>
<estado>SP</estado>
<cep>12340-001</cep>
</endereço>
<itensCompra>
<item>
<idProduto>1437-TA</idProduto>
<nomeProduto>Gravador CD Philips 52X</nomeProduto>
<preço>400.00</preço>
</item>
</itensCompra>
</ordemCompra>
</ordensCompra>
Um elemento representa a unidade de informaçăo. Os dados de cada elemento săo delimitados por um par de marcadores, que consistem em nomes delimitados pelos símbolos "<" e ">". No XML os marcadores săo definidos pelo usuário, de acordo com o significado do elemento correspondente.
O principal objetivo dos marcadores é delimitar os dados propriamente ditos contidos no elemento. No modelo relacional, esses dados corresponderiam aos valores dos campos de uma linha da tabela. Sendo assim, um elemento é formado por um marcador de início, seguido do conteúdo e finalmente do marcador de término. Por exemplo, os marcadores <nomeProduto> e </nomeProduto> delimitam a cadeia de caracteres "Mouse Ótico Microsoft". Esse é o caso mais simples, onde o conteúdo de um elemento em um documento XML é formado por uma cadeia de caracteres.
No entanto, um documento XML pode conter elementos que sejam, eles próprios, formados por outros elementos, o que resulta na estrutura hierárquica típica de todo documento XML. Na Listagem 1, por exemplo, o elemento raiz do documento corresponde ao marcador ordensCompra. Esse elemento possui diversos subelementos ordemCompra. Este último, por sua vez, possui tręs subelementos: nomeCliente, endereço e itensCompra. Por sua vez, cada elemento itensCompra é composto dos elementos idProduto, nomeProduto, quantidade e preço (a Figura 1 permite perceber mais claramente a estrutura hierárquica do documento apresentado na Listagem 1).
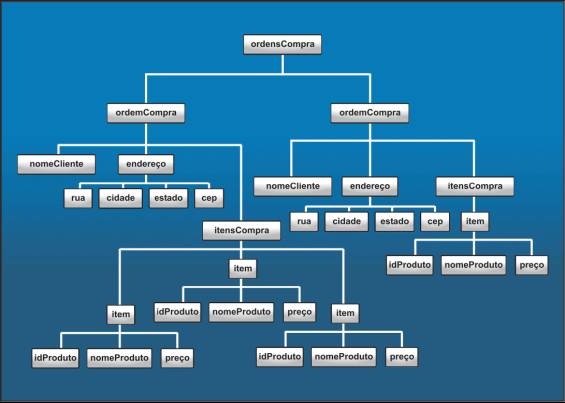
Figura 1 - Estrutura hierárquica de um documento XML
Cada elemento pode possuir também atributos que fornecem informaçőes adicionais. Diferentemente de um elemento, um atributo năo pode conter seus próprios subelementos e atributos. Um atributo sempre possui um nome e um valor atômico. Por exemplo, no documento da Listagem 1, o elemento ordemCompra possui um atributo denominado dataCompra.
O exemplo da Listagem 1 também permite perceber que um arquivo XML possui uma estrutura parecida com a de um documento HTML. No entanto, essas linguagens tęm propósitos distintos. A linguagem HTML é utilizada para definir o formato de apresentaçăo de um documento, ao passo que o XML visa construir documentos que representem dados juntamente com seus respectivos significados, sem considerar o formato de sua apresentaçăo.
Definindo o Esquema de um Documento XML
Um fator decisivo para o sucesso do modelo relacional foi o fato de os dados estarem de acordo com um esquema e seguirem um conjunto de restriçőes de integridade. Certamente, a existęncia dessas características no modelo de dados XML também é interessante. Um exemplo dessa vantagem é: o programa só processaria esses documentos se eles estivessem de acordo com o esquema definido.
Considere o documento da Listagem 1. Se este documento năo tem um esquema associado, nada impede que o valor de um dos elementos preço seja um valor negativo. Agora suponha que o elemento item exibido na Listagem 2 seja inserido no documento da Listagem 1. Note que esse elemento possui dois subelementos preço. Nesse caso, o programa de aplicaçăo năo poderia determinar qual é o preço correto do item.
Exemplo de elemento "item" com dois elementos "preço"
<item>
<idProduto>1364-FS</idProduto>
<nomeProduto>HD Samsung 40G</nomeProduto>
<quantidade>2</quantidade>
<preço>53.00</preço>
<preço>30.00</preço>
</item>
O dois exemplos anteriores ilustram o quăo importante é definir um esquema e restriçőes sobre elementos de um documento em uma aplicaçăo. O W3C define duas formas principais para isso: DTD (sigla para Document Type Definition) e esquema XML (traduçăo para XML Schema).
O conceito de DTD surgiu juntamente com a linguagem SGML, precursora da XML. DTD consiste em um arquivo que define diversas restriçőes a serem seguidas por um documento XML. Por analogia, um DTD poderia ser comparado ao esquema relacional de uma tabela, onde săo definidas a estrutura da tabela e as restriçőes de integridade a serem aplicadas. Assim, o DTD restringe a estrutura de um documento XML. A Listagem 3 apresenta um exemplo de DTD que define a estrutura do documento da Listagem 1.
Listagem 3 - Exemplo de DTD
<?xml version="1.0" ?>
<!DOCTYPE document SYSTEM "exemplo.dtd">
<!ELEMENT ordensCompra(ordemCompra)* >
<!ELEMENT ordemCompra(nomeCliente, endereço, itensCompra) >
<!ELEMENT itensCompra(item)+>
<!ELEMENT item(idProduto, nomeProduto, quantidade, preço)>
<!ELEMENT idProduto (#PCDATA)>
<!ELEMENT nomeProduto (#PCDATA)>
<!ELEMENT quantidade (#PCDATA)>
<!ELEMENT preço (#PCDATA)>
<!ATTLIST ordemCompra dataCompra CDATA #REQUIRED>
Cada linha do DTD que começa pela cláusula ELEMENT define um elemento. Essa definiçăo é feita através da enumeraçăo dos subelementos componentes. Por exemplo, o elemento itensCompra é composto de uma seqüęncia de um ou mais elementos item; já o elemento item é composto dos elementos id-Produto, nomeProduto, quantidade e preço; por fim, os elementos idProduto, nomeProduto, quantidade e preço săo compostos de cadeias de caracteres (PCDATA, Parsed Character Data). A estrutura de um elemento é especificada no DTD por meio do uso de alguns símbolos especiais. Esses símbolos estăo resumidos na Tabela 1.
O DTD também define os atributos de cada elemento. Cada atributo pode ser definido em uma linha do DTD através da cláusula ATTLIST. No exemplo da Listagem 3, o atributo é definido como do tipo CDATA (Character Data), de uso obrigatório (através da cláusula REQUIRED).
A segunda maneira possível de se definir o esquema de um documento XML é através do esquema XML. Ela foi originalmente proposta pela Microsoft e tornou-se uma recomendaçăo oficial do W3C em maio de 2001. Um esquema XML tem o mesmo objetivo de um DTD: descrever a estrutura e as restriçőes de um documento XML. Entretanto, há duas diferenças básicas entre eles.
Em primeiro lugar, um esquema XML consiste, ele próprio, em um documento XML. Uma segunda diferença (mais importante que a anterior) é que um esquema XML fornece mais força expressiva para definir restriçőes sobre os elementos e sobre suas cardinalidades. Para entender essa segunda diferença, considere o exemplo de esquema apresentado na Listagem 4. O esquema XML fornece diversos tipos predefinidos que podem ser utilizados na definiçăo dos elementos de um documento XML. Isso permite restringir o domínio de valores que podem ser atribuídos a um elemento. Por exemplo, compare a definiçăo do elemento quantidade na Listagem 3 e na Listagem 4. No primeiro caso (Listagem 3), é utilizado o tipo CDATA, o que permite atribuir qualquer cadeia de caracteres como valor para esse elemento (inclusive valores que năo correspondam a valores inteiros). Já no segundo caso, é utilizado o tipo xsd:positiveInteger, o que limita os valores desse campo a inteiros positivos.
Listagem 4 - Exemplo de esquema XML.
<?xml version="1.0"?>
<xsd:schema xmlns:xsd=“http://www.w3.org/2001/XMLSchema“>
<xsd:element name=“ordensCompra“ type=“TipoOrdensCompra“/>
<!—Código identificador para produtos -->
<xsd:simpleType name="TipoId">
<xsd:restriction base=”xsd:string”>
<xsd:pattern value=”\d{4}-[A-Z]{2}”/>
</xsd:restriction>
</xsd:simpleType>
<xsd:complexType name=”TipoEndereço”>
<xsd:sequence>
<xsd:element name=”rua” type=”xsd:string”/>
<xsd:element name=”cidade” type=”xsd:string”/>
<xsd:element name=”estado” type=”xsd:string”/>
<xsd:element name=”cep” type=”xsd:decimal”/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name=”TipoOrdensCompra”>
<xsd:sequence>
<xsd:element name=”ordemCompra” minOccurs=”0” maxOccurs=”unbounded”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=”nomeCliente” type=”xsd:string”/>
<xsd:element name=”endereço” type=”TipoEndereço”/>
<xsd:element name=”itensCompra” type=”TipoItemsCompra”/>
</xsd:sequence>
<xsd:attribute name=”dataCompra” type=”xsd:date”/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name=”TipoItensCompra”>
<xsd:sequence>
<xsd:element name=”item” minOccurs=”1” maxOccurs=”unbounded”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=”idProduto” type=”TipoId”/>
<xsd:element name=”nomeProduto” type=”xsd:string”/>
<xsd:element name=”quantidade” type=”xsd:positiveInteger”/>
<xsd:element name=”preço” type=”xsd:decimal”/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>
Além disso, a sintaxe do esquema XML permite a declaraçăo de tipos definidos pelo usuário. Um exemplo săo os tipos TipoOrdemCompra, TipoId, TipoEndereço e TipoItensCompra, definidos no esquema XML da Listagem 4.
É difícil prever se o esquema XML irá substituir completamente o DTD. Ainda existem muitos usuários da SGML (a ancestral da XML) que trabalham exclusivamente com DTD, e muitas ferramentas ainda săo construídas para esse esquema. Certamente as duas alternativas (esquema XML e DTD) ainda coexistirăo durante um bom tempo.
Consultando Documentos XML
A exemplo de uma tabela em um banco de dados, o documento XML armazena informaçőes. Com isso em mente, faz sentido mencionarmos as linguagens que permitam consultá-las. Várias linguagens de consulta para XML foram propostas. De modo geral, essas propostas permitem navegar pelos elementos de um documento XML e especificar predicados para filtrar os elementos desejados. A linguagem que tende a perdurar (por conta de ser uma recomendaçăo do W3C) é a XQuery.
A XQuery é uma linguagem cuja especificaçăo da versăo 1.0 ainda está em desenvolvimento. Assim como a SQL (que consulta uma tabela e retorna uma tabela), a XQuery possui a propriedade de fechamento, ou seja, a execuçăo de uma consulta nessa linguagem sobre um documento XML retorna outro documento XML.
Para dar um exemplo de consulta em XQuery, considere novamente o documento XML da Listagem 1. Para retornar um documento XML que contenha o nome do cliente e a quantidade de itens de cada ordem de compra cuja data de realizaçăo tenha sido 13/09/2003, é utilizada a consulta da Listagem 5(a). O documento resultante pode ser visto na Listagem 5(b).
Listagem 5 - Exemplo de consulta em XQuery
FOR $oc IN //ordemCompra---------------------------->(a)
LET $itens := $oc/item
WHERE $oc//dataCompra = “13-09-2003”
RETURN <ordemCompra>
$oc/nomeCliente
<qtdItens>COUNT($itens)</qtdItens>
</ordemCompra>
<results>------------------------------------------->(b)
<ordemCompra>
<nomeCliente>Daniela Florescu</nomeCliente>
<qtdItens>3</qtdItens>
</ordemCompra>
</results>
Suporte a XML em SGBDs
Descreverei agora algumas das soluçőes atuais para o armazenamento de documentos XML. Certamente, uma forma óbvia de armazenar documentos XML é utilizando um sistema de arquivos.Entretanto, essa alternativa năo será analisada aqui. Apresentarei apenas as alternativas de armazenamento que fazem uso de um SGBD.
SGBDs Puramente Relacionais
A primeira estratégia para o armazenamento de documentos XML consiste em utilizar um SGBD relacional. Uma vantagem dessa alternativa é que a tecnologia relacional está bem sedimentada e, conseqüentemente, uma fraçăo significativa dos dados das empresas e instituiçőes utiliza essa tecnologia. Além disso, o desempenho desses SGBDs no processamento de dados é bem conhecido.
Um SGBD puramente relacional pode armazenar um documento XML de duas formas. A primeira forma consiste em armazenar o documento em um campo de tipo CLOB. Nessa proposta, o SGBD serve somente como um repositório de dados e năo conhece a estrutura dos documentos XML armazenados.
Nota: CLOB é um tipo de dado apropriado para armazenar e processar dados em formato de string. Trata-se de um tipo de dado definido no padrăo SQL:1999, existente nos principais SGBDs comerciais.
Na segunda estratégia de armazenamento, o documento é lido juntamente com seu esquema (que pode ser um DTD ou um esquema XML). Nesse esquema, o documento é analisado (ou seja, tem seus elementos constituintes "quebrados" por um processador de XML). Por fim, o conteúdo do documento XML e a definiçăo de seu esquema (DTD ou Esquema XML) săo armazenados em um banco de dados que possua um esquema relacional adequado para o armazenamento (o artigo Gerenciando Componentes de Software em XML e Bancos de Dados, publicado na ediçăo 5 da SQL Magazine, contém um descriçăo detalhada dessa estratégia de mapeamento).
No entanto, essa segunda estratégia é enganosamente simples. De modo geral, a estrutura hierárquica de um documento XML năo se encaixa muito bem na estrutura relacional. Na prática, um documento XML pode ter uma quantidade arbitrária de elementos aninhados e de atributos, o que faz com que ele seja "achatado" em diversas tabelas do banco de dados. Além disso, o conteúdo do arquivo DTD (ou do esquema XML) também precisa ser mapeado para um conjunto de tabelas, de modo a permitir que o documento XML seja reconstituído sempre que for necessário. Ou seja, embora seja possível o mapeamento de um documento XML para um banco de dados relacional, esse documento precisará ser recursivamente quebrado em seus elementos para ser armazenado em uma ou mais tabelas do banco. Conseqüentemente, a quantidade de junçőes para reconstituir o documento XML através de consultas SQL poderá se tornar proibitiva do ponto de vista do desempenho.
Apesar dos problemas de desempenho decorrentes dessa segunda estratégia, ela é normalmente a preferida quando se trata de armazenar documentos XML em um SGBD puramente relacional. Isso porque essa forma de armazenamento traz vantagens em relaçăo ŕ estratégia de armazenamento que utiliza o tipo CLOB. A vantagem mais marcante é que os elementos do documento XML estăo armazenados em diferentes campos de uma ou mais tabelas, o que possibilita atualizar, remover ou adicionar partes do documento XML através de SQL. Como exemplo, reconsidere o documento XML da Listagem 1. Caso seja preciso inserir ou alterar um novo elemento "item de compra" no documento XML (ou removę-lo de lá), é possível fazer isso facilmente por meio de um comando SQL. Observe que, se fosse utilizada a estratégia de armazenamento baseada no tipo CLOB, seria necessário reescrever todo o documento.
SGBDs Habilitados a XML
Da mesma forma como assimilaram as características do paradigma orientado a objetos (veja SQL Magazine, ediçăo 3, página 32), os principais SGBDs tęm se esforçado nos últimos anos em ajustar o seu modelo de dados para oferecer suporte ao gerenciamento de dados XML. Por conta disso, esses produtos vęm sendo classificados como SGBDs habilitados para XML. O Oracle 9i, o DB2 Universal Server, o SQL Server e o Sybase săo exemplos de produtos que se encaixam nessa categoria. O MySQL também possui alguns recursos (ainda um tanto incipientes).
De modo geral, os SGBDs habilitados para XML armazenam um documento por meio do mapeamento de seus elementos para uma estrutura de dados definida especificamente para XML. Ou seja, esses SGBDs definem novos tipos de dados abstratos específicos a XML que facilitam tanto o armazenamento quanto o processamento desses documentos. Por exemplo, no DB2, há os tipos XML Column e XML Collection; no Oracle, há o tipo XMLType. Assim, um documento XML é armazenado no banco de dados como uma instância de um tipo de dado abstrato para XML. Normalmente, esses tipos de dados abstratos para XML oferecem diversos métodos para manipular o conteúdo de documentos XML.
Já a consulta é feita através de extensőes ŕ linguagem SQL. Por exemplo, considere a criaçăo de uma tabela no Oracle 9i para armazenar o documento da Listagem 1. O comando para essa açăo é apresentado na Listagem 6(a). Note a utilizaçăo do XMLType como tipo da coluna ordens. Para inserir dados nessa tabela, pode-se utilizar um procedimento armazenado que lę um documento XML e armazena o seu conteúdo na coluna ordens. Esse procedimento é apresentado na Listagem 6(b). Por fim, a consulta apresentada na Listagem 6(c) retorna os nomes dos clientes que compraram produtos cujos preços unitários săo maiores que R$ 100,00.
Listagem 6 - Utilizaçăo de tipos de dados abstrato XMLType para manipular XML.
CREATE TABLE T_OrdensCompra (ordens SYS.XMLType);
--------------------------------------------------------->(a)
CREATE OR REPLACE PROCEDURE ArmazenarXML AS
conteudo CLOB := ‘ ‘;
fonte bfile:= bfilename(‘c:\xml’, ‘OrdensCompra.xml’);
BEGIN
DBMS_LOB.fileOpen(fonte, DBMS_LOB.file_readonly);
DBMS_LOB.loadFromFile(conteudo, fonte, DBMS_LOB.getLength(fonte), 1, 1);
DBMS_LOB.fileClose(fonte);
INSERT INTO T_OrdensCompra(ordens) VALUES(SYS.XMLType.createXML(conteudo));
END ArmazenarXML;
--------------------------------------------------------->(b)
SELECT t.ordens.extract(‘ordensCompra//nomeCliente’)
FROM T_OrdensCompra t
WHERE t.ordens.extract(‘ordensCompra//preço/text()’).getNumberVal() > 100.0
--------------------------------------------------------->(c)
No exemplo, foi criada uma tabela com uma coluna para armazenar o documento XML como um todo. No entanto, a maioria dos SGBDs Habilitados para XML fornecem a possibilidade de armazenar um documento utilizando uma granularidade menor, conforme a necessidade. Por exemplo, cada ordem de compra do documento da Listagem 1 poderia ser armazenada em uma linha de uma tabela.
Além de fornecerem extensőes ŕ SQL, alguns SGBDs habilitados para XML também permitem realizar consultas através da XQuery, embora nenhum deles atualmente ofereça suporte completo a essa linguagem de consulta.
SGBDs XML Nativos
A terceira abordagem consiste em utilizar SGBDs XML Nativos, que tęm no documento XML a sua unidade fundamental de armazenamento. Por analogia, o documento XML está para um SGBD XML Nativo assim como o conceito de linha de uma tabela está para um SGBD relacional. Além disso, esse tipo de SGBD utiliza um modelo de dados lógico específico a XML. Nesse modelo, săo definidos os conceitos de elemento, atributo, seqüęncia de elementos e o tipo PCDATA. Os DTDs ou esquemas XML (em vez de esquemas relacionais) definem a estrutura e as propriedades de uma coleçăo de documentos.
A maioria dos SGBDs XML Nativos utiliza em seus modelos de dados o conceito de coleçăo XML. Esse conceito é análogo ao de uma relaçăo (tabela) no modelo de dados relacional. Pode-se definir, por exemplo, uma coleçăo XML para armazenar os pedidos feitos por clientes em uma aplicaçăo de comércio eletrônico.
Em vez de definir o esquema através da DDL da SQL, esses SGDBs permitem definir esquemas para os documentos diretamente em XML. Uma vez definido um esquema, os documentos podem ser armazenados na coleçăo correspondente. As consultas a esses documentos săo feitas (na maior parte dos produtos) por intermédio da XQuery. Como o W3C ainda năo definiu uma sintaxe para atualizaçăo de documentos XML através da XQuery, os mecanismos de atualizaçăo variam de um SGBD XML Nativo para outro. Na verdade, essa é uma questăo controversa em todas as abordagens de armazenamento de documentos XML em SGBDs, e năo só em SGBDs XML Nativos.
Uma vantagem dos SGBDs XML Nativos é o fato de eles serem adequados para manipular documentos XML que năo estejam em conformidade com um esquema predefinido. Ou seja, no caso de documentos XML que năo possuem uma estrutura rígida, os SGBDs XML Nativos parecem ser uma escolha mais apropriada do que os SGBDs habilitados a XML. Porém, é necessário levar em conta o investimento em um novo tipo de SGBD e o fato de que esses SGBDs năo săo adequados para manipular dados relacionais.
Como um pequeno estudo de caso, descreveremos agora algumas características de um SGBD XML Nativo, o Tamino XML Server (para obter uma versăo demo desse produto, consulte o site da empresa).
O Tamino XML Server possui uma ferramenta específica para a criaçăo de esquemas, o Schema Editor, cuja janela principal é exibida na Figura 2. Essa janela possui tręs regiőes principais. Na regiăo ŕ esquerda, é exibida a estrutura em árvore correspondente ao esquema XML que está sendo definido. Na regiăo superior direita, săo exibidas as propriedades do elemento que está selecionado na árvore (essas propriedades podem ser alteradas nessa regiăo). Por fim, a regiăo inferior direita possibilita definir propriedades físicas para o esquema XML que está sendo definido. Duas dessas propriedades definem o tipo de armazenamento a ser utilizado e se existem índices sobre alguns elementos do esquema. Essa ferramenta também permite importar um esquema XML (ou DTD) previamente existente.
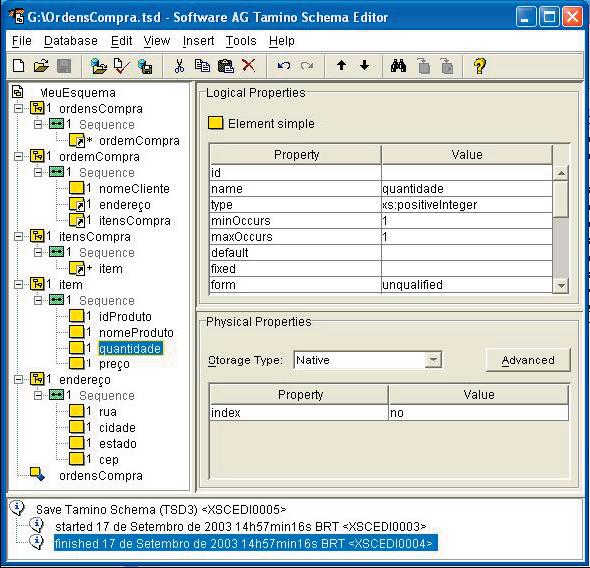
Figura 2 - Janela da ferramenta ‘Schema Editor’ no Tamino XML Server
Uma vez definido um esquema no Tamino XML Server, é possível armazenar de diversas maneiras as instâncias desse esquema (os documentos XML). Uma dessas maneiras é através da ferramenta Tamino Migration Tool. Essa ferramenta permite carregar uma coleçăo de documentos XML armazenados em arquivos para um banco de dados do Tamino XML Server. Outra maneira de armazenar documentos é através da API Java fornecida com esse produto. Essa API possui funçőes para inserir novos documentos XML em uma coleçăo armazenada no banco de dados.
Por fim, os documentos armazenados em uma coleçăo podem ser consultados de duas maneiras. A primeira é através da ferramenta Tamino Interactive Interface, que possibilita o envio de consultas Xquery e a visualizaçăo dos resultados de forma interativa. A segunda é através da API Java, que permite enviar consultas XQuery para o Tamino XML Server.
Além do Tamino XML Server, diversos outros produtos se encaixam na categoria de SGBDs XML Nativos (vide Tabela 2).
|
Produto |
Organizaçăo |
URL |
|
DbXML |
dbXML Group |
www.dbxmlgroup.com/ |
|
Excelon |
eXcelon Corp |
www.exceloncorp.com/ |
|
X-Hive/DB |
The Connection Factory |
www.x-hive.com/ |
|
Tamino XML Server |
Software AG |
www.softwareag.com/tamino |
|
Berkeley DB XML |
Sleepycat Software |
www.sleepycat.com/products/xml.shtml |
|
NATIX |
Data ex machina GmbH |
www.dataexmachina.de/natix.html |
|
Exist |
--- (open source) |
exist.sourceforge.net/ |
Conclusőes
O XML só contribuiu para acelerar as "mutaçőes" pelas quais a tecnologia de bancos de dados vem passando. Um exemplo foi a absorçăo do paradigma orientado a objetos pelos SGBDs relacionais durante a década de 90. Agora, a tecnologia de bancos de dados está se esforçando para se adequar ao padrăo XML.
Um dos desafios é aprimorar as linguagens de consulta para XML. A linguagem XQuery parece despontar como tendęncia, uma vez que foi projetada para atender a esse modelo de dados. No momento, está sendo desenvolvido um padrăo ANSI/ISSO para mapeamento entre SQL e XML, o SQL/XML. Esse padrăo define maneiras de converter os resultados obtidos a partir de uma consulta SQL para o formato XML.
Um fato no mínimo curioso é a possibilidade de, em alguns anos, ocorrer uma competiçăo semelhante ŕ ocorrida entre SGBDs orientados a objetos e SGBDs relacionais. Desta vez, a disputa seria entre os SGBDs Habilitados a XML e os SGBDs XML Nativos. É difícil prever o final dessa história.
O certo é que o antigo modelo de dados hierárquico (utilizado pelos primeiros SGBDs e que se tornou obsoleto após o surgimento do modelo relacional) ressurgiu das cinzas, encarnado em XML, e vem provocando muitas transformaçőes nas tecnologias de bancos de dados atuais.







