Atençăo: por essa ediçăo ser muito antiga năo há arquivo PDF para download.
Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.

Estatísticas de Distribuiçăo de Dados no SQL Server
As estatísticas de distribuiçăo de dados representam o coraçăo do otimizador de consultas SQL de todo banco de dados. Estatísticas desatualizadas ou mesmo a falta de estatísticas adequadas no momento da execuçăo de uma query podem resultar na escolha de planos de execuçăo ineficientes, causando perdas de desempenho.
Neste artigo, apresentaremos algumas estatísticas utilizadas pelo SQL Server 2000. Aprenderemos a ler as estatísticas de um índice e faremos alguns exemplos práticos para demonstrar sua importância. Será explicado também como o otimizador de comandos faz uso de estatísticas para escolher o melhor plano de execuçăo de uma consulta.
Decifrando estatísticas
As estatísticas existem para que o otimizador de queries possa “prever” o número de linhas afetadas pelo comando sem que ele precise ser executado. Através de simulaçőes envolvendo os diversos índices da tabela, o otimizador pode escolher aquele que apresenta melhor custo-benefício e com isso, movimentar um número menor de registros para processar a query. As estatísticas servem também para determinar o melhor algoritmo de join (nested loop, merge ou hash) para resolver a query.
Esses cálculos estatísticos envolvem duas unidades básicas de medidas: seletividade e densidade. Seletividade consiste em uma propriedade relativa ao número de linhas identificadas por um valor chave. Por exemplo, as primary-keys săo altamente seletivas, pois, a partir da(s) coluna(s) que compőem sua chave, é possível identificar um (e somente um) registro. A densidade é o inverso de seletividade. Ela mede o índice de duplicidades existentes num índice. Índices năo exclusivos, com muitas chaves duplicadas, possuem densidade alta e seletividade baixa. A Listagem 1 nos mostra um exemplo prático do cálculo desses índices para a tabela Orders, considerando a coluna CustomerId.
select Nro_Linhas_Orders = count(*),
CustomerId_Distintos = count(distinct CustomerId),
Seletividade_CustomerId = count(distinct CustomerId) / cast(count(*) as dec(5,2)),
Densidade_CustomerId = 1 / cast(count(distinct CustomerId) as dec(5,2))
from Orders
-------------------------------------------------------------------------------------------------
Nro_Linhas_Orders Clientes_Distintos Seletividade_CustomerId Densidade_CustomerId
-------------------------------------------------------------------------------------------------
816 89 .109068 .011235
Listagem 1: Cálculo da densidade e seletividade para a tabela Orders, coluna CustomerId.
Aplicando os conceitos de seletividade e densidade no resultado da Listagem 1, percebemos o seguinte:
· A seletividade da coluna CustomerId é baixa ( ela identifica apenas 11% de códigos distintos na tabela Orders) (0.109068).
· A densidade (ou índice de duplicidades) da coluna CustomerId é alta, e existem em média 91 repetiçőes (816 * 0.11235) para cada código de cliente.
As estatísticas de distribuiçăo de dados num índice podem ser visualizadas com o comando DBCC SHOW_STATISTICS. A Listagem 2 mostra o resultado desse comando sobre o índice composto ix_CustomerId_Orders (CustomerId,OrderDate), criado na tabela NorthWind.Orders.
Nota
As estatísticas de distribuiçăo de um índice săo armazenadas na coluna de data-type image em SysIndexes.StatBlob (tabela de sistema responsável por armazenar metadados dos índices e estatísticas).
create index ix_CustomerId_OrderDate on Orders (CustomerId,OrderDate)
DBCC SHOW_STATISTICS (orders,IX_CustomerId_OrderDate)
----------------------------------------------------------------------------------------------------
Statistics for INDEX 'customerid'.
----------------------------------------------------------------------------------------------------
Updated Rows Rows Sampled Steps Density Average key length
----------------------------------------------------------------------------------------------------
Aug 27 2003 7:49PM 830 830 89 0.0 14.0
----------------------------------------------------------------------------------------------------
All density Average Length Columns
----------------------------------------------------------------------------------------------------
1.1235955E-2 10.0 CustomerID
1.2150669E-3 18.0 CustomerID, OrderDate
1.2048193E-3 22.0 CustomerID, OrderDate, OrderID
----------------------------------------------------------------------------------------------------
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
----------------------------------------------------------------------------------------------------
ALFKI 0.0 6.0 0 0.0
ANATR 0.0 4.0 0 0.0
ANTON 0.0 7.0 0 0.0
AROUT 0.0 13.0 0 0.0
BERGS 0.0 18.0 0 0.0
BLAUS 0.0 7.0 0 0.0
BLONP 0.0 11.0 0 0.0
BOLID 0.0 3.0 0 0.0
BONAP 0.0 17.0 0 0.0
..
…..
………
Listagem 2: Execuçăo do comando DBCC SHOW_STATISTICS sobre o índice ix_CustomerId_Orders
Analisemos agora o resultado desse comando:
1. A última data de atualizaçăo das estatísticas desse índice foi 27 de agosto de 2003, ŕs 7:49 da noite (coluna Updated). Tabelas com alto índice de modificaçőes precisam apresentar pouca defasagem de tempo nessa informaçăo.
2. As colunas RANGE_HI_KEY e AVG_RANGE_ROWS informam detalhes sobre a distribuiçăo da PRIMEIRA COLUNA que compőe o índice. Em nosso caso, para o índice ix_CustomerId_OrderDate (CustomerId,OrderDate) será criado um histograma para a coluna CustomerId. Esse histograma nada mais é do que a contagem de ocorręncias dos códigos de cliente (CustomerId) na tabela Orders. As duas linhas abaixo foram extraídas da Listagem 2 e alteradas para facilitar a compreensăo:
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
----------------------------------------------------------------------------------------------------
1 0.0 15.0 0 0.0
75 50.0 8.0 10 5.0
...
2.1 - Existem 15 pedidos (EQ_ROWS) para CustomerId=1 e 8 pedidos para CustomerId=75;
2.2 - Existem 50 pedidos cujos códigos de cliente CustomerId situam-se entre 1 e 75 (considerando-se códigos repetidos);
2.3 - Dos 50 códigos existentes no intervalo aberto ]1,75[, existem 10 códigos distintos
(=DISTINCT_RANGE_ ROWS);
2.4 - Existe uma média de 5 repetiçőes para cada código diferente situado no intervalo ]1,75[
(=AVG_RANGE_ ROWS).
3. O cálculo de densidade é efetuado para a composiçăo de todas as colunas que formam o índice. Em nosso caso, ele será reproduzido para as coluna CustomerId e CustomerId+OrderDate.
4. O cálculo de densidade é representado pela fórmula (1 / (somatória de valores distintos para a chave)). Considerando a coluna CustomerId, teríamos o seguinte :
select Densidade_CustomerId = 1 / cast(count(distinct CustomerId) as dec(5,2)) from Orders
Multiplicando a coluna ROWS da Listagem 1 pelos valores presentes em ALL DENSITY, temos uma idéia clara da distribuiçăo das chaves do índice (ver Tabela 1).
|
Colunas do índice |
Rows * All Density |
Avaliaçăo |
|
CustomerId |
830 * 1.1235955E-2 = 9.32584 |
Para cada código diferente de CustomerId, existe em média 9 duplicidades |
|
CustomerId +OrderDate |
830 * 1.2150669E-3 = 1.00851 |
Existe em média somente uma ocorręncia na tabela Orders para a composiçăo da chave CustomerId +OrderDate |
|
CustomerId +OrderDate +OrderId |
830 * 1.2048193E-3 = 1 |
Existe somente uma ocorręncia na tabela Orders para a composiçăo da chave CustomerId +OrderDate + OrderId |
Tabela 1 – Calculo da Densidade.
No entanto, considerar separadamente as informaçőes de densidade e o histograma já năo seriam suficientes para uma análise? Bem, o histograma é calculado somente para a primeira coluna do índice. Se vocę possuir um índice composto, o SQL Server 2000 năo conseguiria uma medida precisa com base apenas no histograma. Se vocę fornecer a chave completa de um índice composto, o otimizador trabalhará com as informaçőes do histograma e de densidade e utilizará aquela que apresentar o menor valor. Para predizer o número de linhas afetadas pelo comando select * from Orders where CustomerId='BOTTM' and OrderDate='1996-12-20' e de posse das estatísticas relacionadas na Listagem 2, temos duas opçőes:
a. Para utilizar a informaçăo de densidade, devemos multiplicar o número de linhas da tabela pelo índice correspondente da coluna All Density para as colunas CustomerId,OrderDate (830*1.2150669E-3). O produto, neste caso igual a 1, representa o número de linhas afetadas.
b. Utilizando o histograma, que registra a distribuiçăo da primeira coluna do índice (=CustomerId), obtemos a informaçăo de que existem 14 linhas para RANGE_HI_KEY='BOTTM'.
Comparando as duas alternativas, (Densidade=1 ou Seletividade=14), optamos pela densidade, pelo fato de ela apresentar o menor valor (ver Figura 1). Esse processo se repetirá para os índices presentes na tabela Orders para, entăo, ser escolhido aquele que apresente melhor custo-benefício.
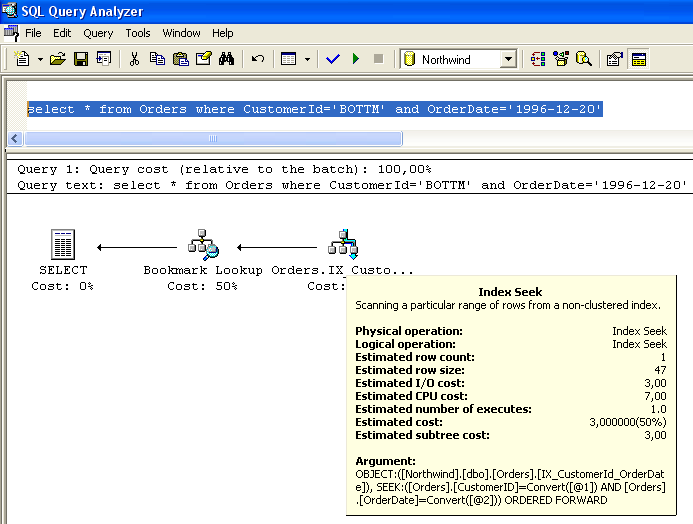
Figura 1 - Estimativa de execuçăo com base em informaçőes da densidade do índice ix_CustomerId_OrderDate.
Como manter atualizadas as estatísticas de um índice
Existem diversas maneiras de atualizaçăo de estatísticas (ver exemplos na Tabela 2):
1. auto-update statistics: opçăo default para bancos de dados criados no SQL Server 2000. Pode ser acessada via comando sp_dbOption ou, no Enterprise Manager, na guia Properties...Options clicando-se com o botăo direito no banco de dados em questăo. Auto update statistics năo impőe atualizaçăo on-line de estatísticas, mas controla limites internos de alteraçőes que, quando atingidos, disparam as atualizaçőes. É um método bastante eficiente e sugiro que mantenham essa opçăo ativa.
2. update statistics: atualiza estatísticas relacionadas a uma tabela em particular. É interessante forçar a atualizaçăo de estatísticas após operaçőes que envolvam a modificaçăo de grande número de registros.
3. sp_updatestats: essa stored procedure é um cursor que executa o comando update statistics para todas as tabelas de um banco.
|
Comando |
Exemplo de utilizaçăo |
|
UPDATE STATISTICS table | view [ index | ( statistics_name [ ,...n ] ) ] [ WITH [ [ FULLSCAN ] | SAMPLE number { PERCENT | ROWS } ] | RESAMPLE ] [ [ , ] [ ALL | COLUMNS | INDEX ] [ [ , ] NORECOMPUTE ] ] |
[*] Para atualizar todas as estatísticas vinculadas ŕ tabela Orders: update statistics Orders
[*] Para atualizar as estatísticas do índice ix_CustomeId_ OrderDate : update statistics Orders (ix_CustomerId_OrderDate)
[*] Para atualizar as estatísticas do índice ix_CustomeId_ OrderDate, com base em uma amostra (=sample) de 50% da tabela Orders: update statistics Orders (ix_CustomerId,OrderDate) with sample 50%
|
|
SP_UPDATESTATS [[@resample =] 'resample'] |
[*] Para atualizar todas as estatísticas das tabelas pertencentes ao banco de dados NorthWind: use NorthWind exec sp_updatestats
[*] Para atualizar todas as estatísticas das tabelas pertencentes ao banco de dados NorthWind, adotando a mesma amostra utilizada na criaçăo das estatísticas: use NorthWind exec sp_updatestats resample
|
|
SP_DBOPTION [ [ @dbname = ] 'database' ] |
[*] Para habilitar a atualizaçăo automática de estatísticas no banco de dados NorthWind: exec sp_dbOption ‘NorthWind’, ‘auto update statistics’, ’true’ |
Tabela 2 - Exemplos de procedimentos para atualizaçăo de estatísticas
Criaçăo automática de estatísticas
As estatísticas săo criadas para o primeiro elemento da chave de um índice. Considere um índice năo-cluster de nome ix_pedido_sqlmag, formado pelas colunas (empresa,filial,nro_pedido) na tabela fictícia pedido_sqlmag. Além da estrutura física, o metadata do índice irá gerar e manter informaçőes estatísticas sobre a distribuiçăo das linhas de acordo com a chave do índice. Essas informaçőes servirăo para o otimizador fazer projeçőes e decidir a respeito da utilizaçăo desse índice para resolver queries. Apenas para ilustrar, as informaçőes estatísticas arquivadas para o índice ix_pedido_sqlmag, mostrariam o seguinte:
|
Total de linhas da tabela : 10.000 Densidade média das colunas que compőe o índice:
|
Façamos agora o papel do otimizador para resolver a query abaixo:
select * from pedido_sqlmag where empresa=1 and filial=10
Sabemos que o otimizador trabalha com projeçőes. Para estimar o tempo de execuçăo, ele se baseia em informaçőes estatísticas previamente armazenadas. Observando as estatísticas do índice ix_pedido_sqlmag, ele percebe que o índice năo é seletivo, pois todas as linhas da tabela pedido_sqlmag possuem empresa igual a 1. Dessa maneira, ele parte para o segundo elemento do índice (=filial). Nesse momento, existem duas opçőes (ver tabela 3).
|
Auto-Create Statistics está habilitado? |
Como o otimizador irá proceder na escolha do plano de execuçăo da query |
|
NĂO |
O otimizador irá analisar a densidade do conjunto empresa+filial. Como a densidade é alta – praticamente todas as colunas da tabela possuem a mesma empresa e filial – é certo que o otimizador năo utilizará o índice |
|
.SIM |
Como a informaçăo de densidade do conjunto empresa+ filial năo é seletiva, o otimizador irá optar por gerar nesse momento as estatísticas de distribuiçăo na forma de um histograma para a coluna filial. De posse das estatísticas, o otimizador consegue identificar se filial igual a 10 possui alta seletividade no índice ix_pedido_sqlmag e opta pela utilizaçăo do índice para resolver a query. |
Tabela 3
Com esse exemplo, concluímos que Auto-Create Statistics influencia a resoluçăo de queries ao criar automaticamente estatísticas necessárias para o otimizador. Concluímos também que a situaçăo ideal é manter a coluna MAIS SELETIVA no PRIMEIRO SEGMENTO DE ÍNDICES COMPOSTOS.
Ao deixar a criaçăo automática de estatísticas a cargo do SQL Server 2000, serăo criadas estatísticas sempre que o otimizador se deparar com selects ineficientes, que forcem processos de “scan” (leituras sequenciais). Um ponto interessante: a estatística pura e simples nem sempre ajuda – saber que existem tręs linhas sob uma determinada condiçăo em um universo de 10.000 linhas existentes numa tabela năo significa muita coisa SE NĂO HOUVER UMA MANEIRA RÁPIDA O BASTANTE PARA ACESSAR SOMENTE ESSAS TRĘS LINHAS. Portanto, a situaçăo ideal é que estatísticas estejam amparadas por índices para que o acesso ao dado pesquisado seja realmente eficiente.
Para compreendermos como funciona a criaçăo automática de estatísticas e sua importância, faremos agora um exemplo prático, executado no SQL Query Analyser.
1 – Inicialmente, desabilite a opçăo auto create statistics do banco de dados NorthWind. É isso mesmo: para que possamos entender como funciona a criaçăo automática de estatísticas, partiremos do caso oposto, ou seja, observaremos o que NĂO acontece quando essa opçăo está desligada. O comando abaixo desligará a criaçăo automática de estatísticas:
exec sp_dbOption 'NorthWind','auto create statistics','FALSE'
2 - Crie e popule a tabela exemplo pedido_sqlmag (ver Listagem 3).
use NorthWind
set nocount on
create table pedido_sqlmag (
empresa smallint,
filial smallint,
nro_pedido int,
vlr_pedido decimal(10,2) )
declare @i smallint
set @i=0
while @i < 10000
begin
insert into pedido_sqlmag (empresa,filial,nro_pedido, vlr_pedido)
values ( 1 , 5 , @i , (@i*1.5) )
set @i=@i+1
end
Listagem 3
3 - Crie o índice abaixo na tabela pedido_sqlmag:
create unique index ix pedido_sqlmag on pedido_sqlmag (empresa,filial,nro_pedido)
4 - Confirme a existęncia de duas linhas na tabela de sistema SysIndexes. Uma para IndId=0 (indicando que pedido_sqlmag é uma heap) e outra entrada para IndId=2 (para o índice criado anteriormente) (ver Listagem 4).
select id_indice=indid, nome_indice= left(name,50), nro_linhas = rows from sysindexes
where id=object_id('pedido_sqlmag')
----------------------------------------------------------------------------------------------------
id_indice nome_indice nro_linhas
------------ -------------------------- --------------
0 pedido_sqlmag 10000
2 ix_pedido_sqlmag 10000
Listagem 4
Nota
Em algumas situaçőes a coluna rows na tabela SysIndexes pode apresentar distorçőes. Se isto ocorrer, o comando DBCC UpdateUsage ('NorthWind','pedido_sqlmag') irá efetuar a correçăo.
5 - Confirme as estatísticas criadas para o índice ix_pedido_sqlmag observando que o histograma é criado APENAS para a primeira coluna (nesse caso, empresa) que integra o índice (ver Listagem 5).
DBCC Show_Statistics ('pedido_sqlmag','ix_pedido_sqlmag')
----------------------------------------------------------------------------------------------------
Statistics for INDEX 'ix_pedido_sqlmag'.
Updated Rows Rows Sampled Steps Density Average key length
----------------------------------------------------------------------------------------------------
Sep 3 2003 7:33PM 10000 10000 1 0.0 8.0
All density Average Length Columns
----------------------------------------------------------------------------------------------------
1.0 2.0 empresa
1.0 4.0 empresa, filial
9.9999997E-5 8.0 empresa, filial, nro_pedido
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
----------------------------------------------------------------------------------------------------
1 0.0 10000.0 0 0.0
Listagem 5
6 – Agora, execute o select da Listagem 6, confirmando a seleçăo do índice ix_pedido_sqlmag. O comando showplan_text faz com que o parser năo execute a query, mas apenas mostre o plano de execuçăo no formato texto.
set showplan_text on
select * from pedido_sqlmag where empresa=1 and filial=5 and nro_pedido=100
StmtText
----------------------------------------------------------------------------------------------------
|--Bookmark Lookup(BOOKMARK:([Bmk1000]), OBJECT:([Northwind].[dbo].[pedido_sqlmag]))
|--Index Seek(OBJECT:([Northwind].[dbo].[pedido_sqlmag].[ix_pedido_sqlmag]),
SEEK:([pedido_sqlmag].[empresa]=Convert([@1])
AND [pedido_sqlmag].[filial]=Convert([@2])
AND [pedido_sqlmag].[nro_pedido]=Convert([@3]))
ORDERED FORWARD)
Listagem 6
7 - Vamos inserir agora 3 linhas para especificar uma filial diferente (por exemplo filial=10) daquela utilizada na inserçăo dos registros no passo 2.
insert into pedido_sqlmag (empresa,filial,nro_pedido,vlr_pedido) values (1,10,25,50)
insert into pedido_sqlmag (empresa,filial,nro_pedido,vlr_pedido) values (1,10,26,51)
insert into pedido_sqlmag (empresa,filial,nro_pedido,vlr_pedido) values (1,10,27,52)
Nota
Se executarmos outro dbcc show_statistics após as inserçőes, obteremos o mesmo resultado do item 5 pelo fato de os tręs registros inseridos năo possuírem representatividade suficiente para alterar as informaçőes de densidade das colunas empresa e filial em All Density.
8 - Observe agora na figura 2 o plano de execuçăo gerado para que o comando select criado pudesse resgatar as 3 linhas inseridas no item anterior.
Observe que, apesar de existirem somente 3 registros na condiçăo apresentada pela query, o índice ix_pedido_sqlmag NĂO foi utilizado pela ausęncia de estatísticas relacionadas ŕ distribuiçăo de dados na coluna filial. A informaçăo de densidade fornecida em All Density năo é representativa para as 3 linhas inseridas no passo 7. O histograma também năo traz nenhum benefício, apenas informa que a maioria de linhas na tabela pedido_sqlmag pertence ŕ empresa de código 1, o que năo apresenta nenhuma vantagem para a consulta no que se refere ao desempenho.

Figura 2 - Plano de execuçăo gerado para comando select, filtrando empresa e filial.
9 – Agora, habilite novamente a opçăo auto create statistics no banco de dados NorthWind
exec sp_dbOption 'NorthWind','auto create statistics','TRUE'
Observe que no select executado no item-8, o índice năo foi utilizado pois a distribuiçăo de dados para a coluna Empresa informava que o índice ix_pedido_sqlmag possuía seletividade muito baixa, já que todas as 10.000 linhas da tabela possuíam Empresa=1. Como năo existem estatísticas que indiquem que esse mesmo índice é bastante seletivo para Filial=10, sua utilizaçăo foi descartada no plano de execuçăo.
10 - Gere o plano de execuçăo gráfico para o mesmo select do passo 8. Note que, na Figura 3, o Table Scan foi substituído por um Index Scan.
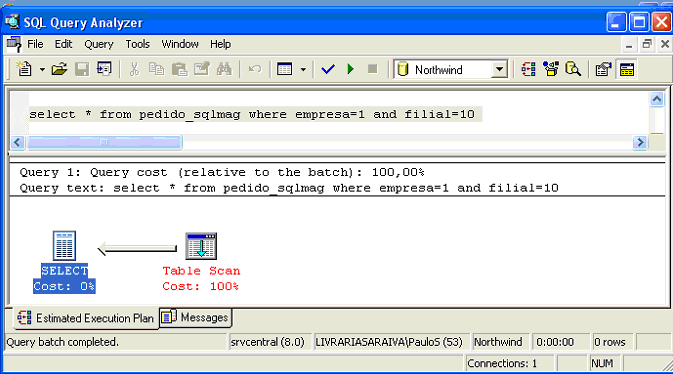
Figura 3 - Plano de execuçăo alterado pela existęncia de estatísticas para a coluna filial.
11 - Para concluir o teste, execute novamente o select na tabela SysIndexes (ver Listagem 7).
select id_indice=indid, nome_indice= left(name,50), nro_linhas = rows from sysindexes
where id=object_id('pedido_sqlmag')
----------------------------------------------------------------------------------------------------
id_indice nome_indice nro_linhas
------------ -------------------------- --------------
0 pedido_sqlmag 10000
2 ix_pedido_sqlmag 10000
3 WA_Sys_filial_17F790F9 0
Listagem 7
Ao executar o mesmo select do item 4 na tabela SysIndexes, constate a criaçăo de um suposto índice de nome _WA_Sys_filial_17F790F9. A inserçăo da linha para indid=3 năo representa um índice, mas sim estatísticas de distribuiçăo geradas automaticamente pelo banco. Como a informaçăo de densidade para o conjunto empresa e filial era pouco significativa, o SQL Server 2000 optou por gerar estatísticas na forma de um histograma para a coluna filial, de modo a auxiliá-lo na escolha do plano de execuçăo.
Nota
O nome da coluna sobre o qual a estatística foi criada está explicitado depois do prefixo “wa_sys”
Executando agora um dbcc show_statistics sobre _WA_Sys_filial_17F790F9, verificaremos no histograma da Listagem 8 que a estatística _WA_Sys_filial_17F790F9 é ALTAMENTE SELETIVA PARA FILIAL=10, justificando a escolha da estatística no plano de execuçăo da consulta.
Statistics for collection '_WA_Sys_filial_17F790F9'.
Updated Rows Rows Sampled Steps Density Average key length
----------------------------------------------------------------------------------------------------
Sep 10 2003 6:04PM 10003 10003 2 0.0 2.0
All density Average Length Columns
----------------------------------------------------------------------------------------------------
0.5 2.0 filial
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
----------------------------------------------------------------------------------------------------
5 0.0 10000.0 0 0.0
10 0.0 3.0 0 0.0
Listagem 8 – Histograma de acesso ŕ coluna filial.
Apesar de a estatística năo fazer nenhuma referęncia direta ao índice ix_pedido_sqlmag, este foi utilizado, uma vez que o otimizador busca estatísticas de distribuiçăo sobre as colunas que compőem o índice (lembrando que as estatísticas sobre a primeira coluna do índice encontram-se no próprio índice).
Caso tivéssemos mais de um índice utilizando o campo Filial, o processo de seleçăo do índice pelo otimizador levaria em conta as colunas presentes no comando select e procuraria identificar um índice que deixasse a query “coberta” (*).
(*) Queries cobertas ou “covered queries” săo aquelas onde todas as colunas presentes no comando select fazem parte de um índice.
Nota
A query abaixo serve para identificar se um objeto é uma estatística ou um índice, na tabela SysIndexes
select id_indice=indid,
nome_indice=left(name,30),nro_linhas=rows ,
tipo = case when IndexProperty(object_id('pedido_sqlmag'),name,'IsStatistics') = 1
then 'Estatistica'
else 'Indice'
end
from sysindexes
where id=object_id('pedido_sqlmag')
---------------------------------------------------------------------------------------------------------------------------------------
id_indice nome_indice nro_linhas tipo
--------- ------------------------------ ------------- -----------
0 pedido_sqlmag 10000 Indice
2 ix_pedido_sqlmag 10000 Indice
3 _WA_Sys_filial_17F790F9 0 Estatistica
Dicas sobre manipulaçăo de estatísticas
· Mantenha auto create statistics habilitado;
· Mantenha auto update statistics habilitado;
· Tenha em mente que índices com seletividade baixa săo ineficientes. A simples existęncia de um índice năo implica em sua utilizaçăo pelo otimizador. Em geral, se a seletividade de uma chave for inferior a 0.85, o índice năo será utilizado;
· Năo se esqueça de atualizar as estatísticas após comandos de manipulaçăo em massa de registros;
· Considere a execuçăo do Index Tunning Wizard. No Enterprise Manager, selecione Tools\Wizards\Manangement\Index Tunning Wizard para reavaliaçăo de seus índices e estatísticas;
· Procure reservar a coluna mais seletiva para o primeiro segmento. A criaçăo de um índice gera também um histograma de distibuiçăo para o primeiro segmento da chave. Se essa coluna for bastante seletiva, năo serăo necessárias estatísticas adicionais para as outras colunas, o que deixará o processo de otimizaçăo mais rápido e eficiente e aumentará muito as chances de utilizaçăo do índice no processo de otimizaçăo da query;
· Revise periodicamente as estatísticas criadas em suas tabelas. Lembre-se que, se vocę executar um select sobre uma coluna que năo possua índices, serăo geradas automaticamente estatísticas sobre a distribuiçăo de dados nessa coluna. Se esse select năo for executado regularmente (foi uma query ad-hoc), é aconselhável dropar essas estatísticas (*) com o comando DROP STATISTICS <nome-da-tabela>,<nome-da-estatistica>. Por outro lado, se essa coluna for utilizada constantemente, crie um índice para essa coluna. Para listar as estatísticas geradas para as colunas de uma tabela, utilize o comando sp_HelpStats <nome-da-tabela>.
(*) Vocę também pode deixar a cargo do SQL Server 2000 a remoçăo de estatísticas criadas automaticamente e que năo sejam mais utilizadas pelo otimizador. O SQL Server 2000 possui um relógio interno que dropa automaticamente as estatísticas após um longo tempo de inatividade.
Conclusăo
Entender como funcionam as estatísticas nos ajudam a: (1) criar índices que serăo efetivamente utilizados pelo otimizador e; (2) evitar a criaçăo de índices ineficientes. Nas próximas ediçőes, daremos continuidade a esse assunto e nos aprofundaremos na arquitetura de índices utilizada pelo SQL Server 2000. Até breve!







