Neste artigo apresentaremos uma visăo conceitual sobre o que é big data, onde se originou, seus motivadores e principais usuários. Demonstraremos também modelos de programaçăo como o MapReduce, assim como ferramentas Java para lidar com big data. E abordaremos, principalmente, ferramentas como o Hadoop, que trazem consigo um modelo robusto de programaçăo distribuída paralelizada para grandes conjuntos de dados.
Em que situaçăo o tema é útil:
O surgimento de ferramentas e cenários para processar big data, principalmente relacionados ŕ tecnologia Java, faz com que oportunidades de transformar grandes volumes de dados de empresas em informaçőes ricas para decisőes sejam cada vez mais frequentes e possíveis de realizar. Para estas empresas, a diferença para tirar vantagem nesta área em relaçăo ŕ concorręncia, pode estar na capacidade e criatividade de conseguir explorar eficientemente o big data, pois a ferramenta existe, é real e open-source.
Resumo DevMan:
Entender o conceito de big data ajudará a compreender melhor qual é o papel desempenhado por ferramentas como o Hadoop. Ao longo do tempo, será mais comum o surgimento deste tipo de desafio em empresas que desejam explorar seu big data. Assim, neste artigo, desvendaremos de maneira prática, com o objetivo de buscar o entendimento, de que forma podemos processar e explorar um grande conjunto de dados através do uso do MapReduce e ferramentas Java (Hadoop). Isto nos possibilita construir aplicaçőes big data em Java.
Com o constante crescimento e facilidade de acesso ŕ tecnologia, cada vez mais e mais volumes de dados săo produzidos. Diariamente, săo gerados petabytes de informaçőes envolvendo operaçőes comerciais e financeiras, e mesmo no ambiente doméstico é comum encontrar usuários que possuem discos de backup com capacidade de 1 terabyte ou mais.
E com este crescente acesso ŕ tecnologia, empresas como Facebook, Yahoo! e Google culminaram coletando dados em uma escala sem precedentes, números além do comum. Eles foram os primeiros a coletar toneladas de dados oriundos de milhőes de usuários. Arduamente, perceberam que os sistemas convencionais de armazenamento e processamento de dados năo atenderiam a suas demandas. Deste modo, nos anos 2000, colocando seus melhores pensadores para criar, foram capazes de desenvolver novas técnicas como MapReduce, BigTable e o Google File System, para lidar com tais volumes e processamento. Assim, após um período utilizando estas tecnologias de forma privada, por volta do ano 2005, Facebook, Yahoo! e Google tomaram a iniciativa de compartilhá-las através da publicaçăo de “white papers”, descrevendo suas tecnologias para soluçőes que requerem o manuseio de big data.
O termo big data é utilizado para referenciar conjuntos de dados de grande volume, o qual é praticamente inviável o manuseio com ferramentas e técnicas convencionais. Lidar com um grande volume de dados acarreta dificuldades no processamento, tais como: indexaçăo, análise de padrőes e até mesmo consultas.
Estes desafios de operaçőes com big data estăo presentes em grandes sites como a Amazon, que gera um enorme volume de dados. A rede social Facebook lida com cerca de 40 bilhőes de fotos geradas por seus usuários. Atualmente, mais de 350 milhőes de usuários ativos acessam a rede social via dispositivos móveis, e săo realizados em média 250 milhőes de uploads de fotos por dia. Em março de 2008, a rede social Facebook coletava diariamente 200 GB de dados; atualmente, coleta 15 terabytes. Imagine apenas o simples fato de gerar um registro de log para cada uma destas operaçőes, qual seria a quantidade de registros que atingiríamos no período de 365 dias? O projeto Grande Colisor de Hádrons (LHC – Large Hadron Collider), o maior acelerador de partículas do mundo, mantido pela CERN, por exemplo, irá produzir 15 petabytes de dados anualmente.
Outro exemplo de desafio com dados: o recurso de pesquisas Search Assist da Yahoo!, fornece sugestőes em tempo real conforme o usuário digita o que deseja pesquisar. Estas sugestőes săo criadas analisando anos de registros de dados das pesquisas e termos utilizados. Para uma empresa do porte da Yahoo!, este registro de dados resulta em terabytes de arquivos de log em apenas um dia, e centenas de terabytes dentro do período de um ano. Para a Yahoo!, antes de o Hadoop ser utilizado, criar a base de dados para o Search Assist levava 26 dias. Agora, com o Hadoop, leva 20 minutos.
É para lidar com essa constante e crescente necessidade de trabalhar com volumes intensivos de dados que surgiu a definiçăo de big data.
Companhias das mais variadas indústrias, por consequęncia da crescente capacidade de coletar e processar mais e mais informaçőes, se encontram com problemas para lidar com big data, e anseiam por soluçőes.
Na busca de oportunidades para prover soluçőes para este mercado, o big data gera um impacto que faz com que grandes players da indústria, tais como Oracle, IBM, Microsoft e SAP, invistam cada vez mais, na ordem de bilhőes de dólares, para se especializarem no gerenciamento e análise de dados nestas proporçőes.
Esta tendęncia traz benefícios para vários campos e atividades que necessitam analisar informaçőes de grandes volumes de dados, como: astronomia, biologia, pesquisas científicas, pesquisas militares, meteorologia, imagens de satélite, redes sociais, pesquisa em internet, logs web, transaçőes bancárias, mercado financeiro, e-commerce, etc. Estar apto a processar analiticamente esse enorme conjunto de dados produzido pode gerar benefícios valiosos para instituiçőes financeiras e năo-financeiras.
Junto com este termo de categorizaçăo (big data), vęm surgindo técnicas e ferramentas poderosas que se tornaram alternativas úteis para tratar esses volumes de dados. O que possibilita prover informaçőes que antes năo eram aproveitadas em visőes analíticas, por serem tăo complicadas e custosas de serem obtidas. Visőes que podem apresentar informaçőes estratégicas, que săo parte importante nas tomadas de decisőes. Dentro destes grandes volumes de dados podem estar escondidos padrőes de informaçőes valiosos, antes inacessíveis devido ao grande esforço para extraí-los.
Hoje, com o custo mais baixo do hardware e processamento em arquitetura cloud disponível no mercado, a opçăo de análise de big data é acessível também para as médias e pequenas corporaçőes. Para estabelecer um data warehouse, é necessário adquirir ferramentas com o preço de alguns milhares de dólares, adquirir o serviço para construçăo da soluçăo por mais alguns milhares de dólares, depois aguardar algumas dezenas de meses. E durante esses meses, esperar que o investimento (tempo e dinheiro) gasto se justifique, que promova visőes que atenderăo suas necessidades e lhe fornecerăo vantagens sobre os competidores. Por isso, empresas que precisavam processar grandes volumes de dados puderam assim realizar, com o advento de ecossistemas como Hadoop e HBase, soluçőes para garimpar bilhőes de dados de forma mais ágil, e ainda com custo mais acessível. Obviamente, as soluçőes corporativas de alto-custo de data warehouse năo irăo desaparecer, o que está acontecendo é que, agora, um data warehouse pode năo ser mais a única opçăo.
Além disso, eles podem ser opçőes complementares e năo excludentes, pois dentro do ciclo de vida dos dados, as duas soluçőes podem participar dividindo as responsabilidades. Mas ainda assim, há uma intersecçăo quanto ao armazenamento e análise, onde ambas as soluçőes podem atuar. Podemos observar uma ilustraçăo sobre isso na Figura 1.
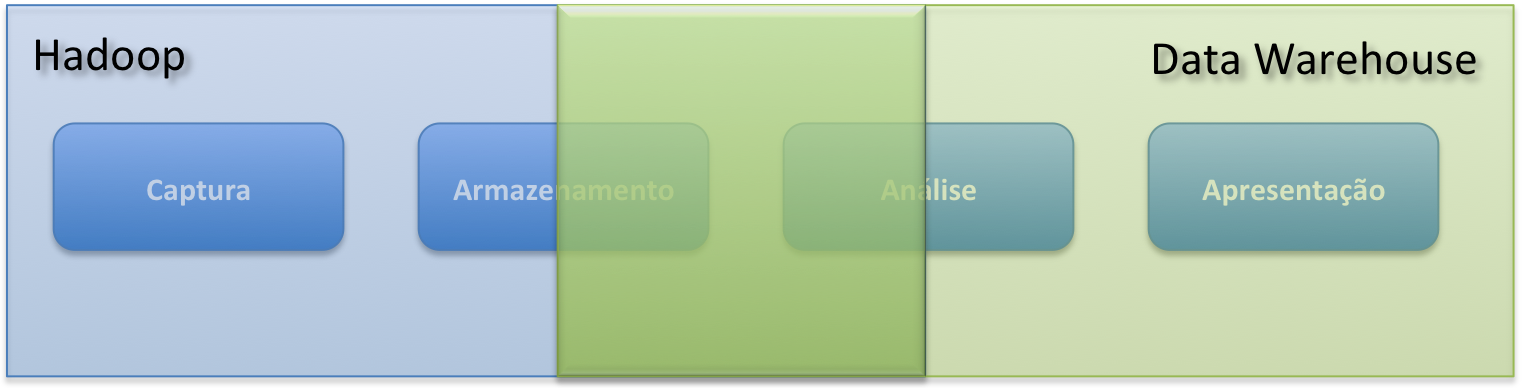
Figura 1. Áreas de atuaçăo do Hadoop e do data warehouse dentro do ciclo de vida dos dados.
Lembrando que săo cenários distintos armazenar big data e realizar alguma coisa com big data, como a execuçăo de processamentos analíticos. Portanto, uma coisa é possuir big data, outra coisa é fazer algo útil com ele.
Na decisăo de transformar a sua grande massa de dados em informaçőes úteis para os objetivos da instituiçăo, é executada uma abordagem que analisa a natureza dos dados e das plataformas de software disponíveis para explorá-los. Nesta abordagem, o big data é comumente caracterizado sob tręs diferentes aspectos: volume, velocidade e variedade. Provavelmente, na perspectiva do dono dos dados, será necessário lidar com cada um destes aspectos em um grau ou outro para orientar a soluçăo a ser criada.
Volume
É sempre muito mais vantajoso poder processar o maior volume de dados possível para a obtençăo de respostas mais precisas. Por exemplo, se for viável analisar a relaçăo da influęncia de compra, entre pares de compradores de hábitos diferentes, de um site e-commerce na ordem de trilhőes de registros, será muito mais eficiente do que analisar alguns milhares de registros. E para processar este grande volume de registros selecionados, possuir um bom modelo de análise das informaçőes é uma parte importante, mas estar apto a processar um volume grande de dados trará mais confiança e precisăo ao resultado final da equaçăo devido ŕ maior abrangęncia diante das informaçőes armazenadas.
Quando lidamos com grandes volumes de dados, maiores do que os convencionais softwares e bancos de dados relacionais podem manusear, temos algumas opçőes de ferramentas, como: data warehouse, arquiteturas MPP (Massively Parallel Processing), banco de dados como o Greenplum ou soluçőes como o Apache Hadoop. Porém, adotar soluçőes de data warehouse envolve o tratamento de estruturas (schemas) pré-definidas, enquanto que com o Apache Hadoop năo temos que impor nenhuma condiçăo na estrutura dos dados que serăo processados.
Velocidade
Possuir uma informaçăo precisa no momento errado năo é uma grande vantagem, porém possuir uma informaçăo precisa no momento certo é, de fato, a vantagem que o dono dos dados procura. Por exemplo, năo existe muita vantagem em possuir informaçőes do hábito de compra de casais com média de idade de 30 anos durante o Natal, e que possuam filho com idade menor de 12 meses, somente na véspera do evento. E há casos, que para serem úteis, prover as informaçőes em tempo real é uma grande vantagem, quando năo uma necessidade.
Em busca desta vantagem, ou mesmo necessidade, companhias especializadas em operaçőes financeiras anseiam por rápida movimentaçăo de informaçőes para seu próprio benefício. Hoje em dia, o tráfego de dados que flui entre clientes e servidores cresceu exponencialmente, pois estamos munidos de dispositivos que permitem acesso mais conveniente e constante a redes, como tablets e smartphones. Além disso, informaçőes como geolocalizaçăo e imagens săo também providas pelos usuários. Aqueles que possuem a capacidade de utilizar rapidamente essa grande quantidade de informaçőes, podem, por exemplo, recomendar produtos e serviços que tenham alguma relaçăo com o contexto do usuário no momento de uma pesquisa em um site na internet, e assim ganhar em competitividade.
A importância da velocidade está no grau de rapidez em que fluxo de informaçőes é realizado: desde a entrada dos dados, até o ponto onde estes se tornam úteis e săo utilizados na tomada de decisőes.
Um comercial de uma grande empresa de tecnologia diz: “vocę
năo atravessaria a rua se tudo que vocę tivesse fosse um snapshot do tráfego de
5 segundos atrás, atravessaria?”. Neste contexto, năo haveria tempo para
esperar relatórios serem gerados ou mesmo jobs do Hadoop se completarem. Para
casos como este é que a indústria está estabelecendo técnicas como ...







