Java EE 6: Da configuraçăo aos testes - Parte 1
Java EE 6: Da configuraçăo aos testes - Parte 3
Nesse artigo será descrita uma estratégia para implementaçăo do recurso de recuperaçăo da informaçăo em ambientes web. Será utilizada a integraçăo entre duas soluçőes livres – Apache Nutch e Solr – para construçăo de uma máquina de busca.
Em que situaçăo o tema útil:
A necessidade de acesso eficiente e eficaz ŕs informaçőes disponíveis em ambiente web é cada vez mais crucial para diferentes interesses e estratégias. A integraçăo Apache Nutch-Solr constitui uma alternativa viável para recuperaçăo da informaçăo nesse contexto.
Resumo DevMan:
A necessidade pela busca da informaçăo em ambientes web torna-se cada vez mais crítica e estratégica. E atender essa demanda de forma eficiente e eficaz constitui um desafio cuja complexidade é diretamente impactada pelo crescimento do volume de informaçăo on-line. Frente a essa realidade, construir soluçőes de recuperaçăo da informaçăo sobre uma infraestrutura de busca web já consolidada, constitui uma abordagem segura para o provimento de um serviço dessa natureza. Nesse artigo, será apresentado como duas aplicaçőes open source, o Apache Nutch e Solr, podem funcionar de forma integrada a fim de suportar um mecanismo de busca. Para abstraçăo da arquitetura criada, será apresentada ainda uma pequena aplicaçăo de interface análoga ŕs máquinas de busca tradicionais.
Nos últimos anos, a Internet consolidou-se como a principal fonte para a busca da informaçăo, seja ela acadęmica, comercial, de entretenimento ou de qualquer outra espécie. Para possibilitar e facilitar esse processo, uma vasta gama de portais e sites da web oferecem ferramentas, motores, mecanismos ou interfaces de busca que se propőem a levar o usuário ŕ informaçăo desejada [8].
Nesse contexto, a parte inicial do artigo apresentou duas soluçőes livres que podem ser exploradas para implementaçăo de um mecanismo de recuperaçăo da informaçăo. O foco foi dado na integraçăo de ambas as aplicaçőes, cujo funcionamento em conjunto disponibiliza a infraestrutura necessária para o funcionamento de uma máquina de busca no âmbito da web.
A primeira soluçăo abordada foi o Apache Nutch – uma flexível engine open source projetada para inspecionar páginas na web. Dentre suas principais funcionalidades constam a recuperaçăo, extraçăo de links e parser de páginas, além da indexaçăo de dados. Na parte 1 do artigo, o Nutch foi instalado e configurado para atuar como crawler de uma engine de busca.
Na sequęncia, o Apache Solr foi apresentado como plataforma de consultas. Além da funcionalidade primária de retornar listas de resultados para um dado conjunto de termos consultados, o Solr disponibiliza serviços como o highlighting de termos pesquisados, navegaçăo baseada em facets e auto-complete de queries. Da mesma forma que o Nutch, o Solr foi instalado e configurado para compor uma engine de busca.
Uma vez que ambas as soluçőes ficaram preparadas para funcionar em integraçăo, foram definidas fronteiras dentro de um domínio qualquer (escolheu-se o ascii-code.com) a fim de delimitar a açăo da ferramenta de busca constituída por essa parceria. Nesse ponto, algumas questőes permaneceram em aberto:
· Apesar de estarem configuradas para trabalharem em conjunto, como, efetivamente, Nutch e Solr executam seus processos de forma integrada?
· Como abstrair-se a infraestrutura Nutch-Solr do usuário final através de uma interface amigável?
Assim, na sequęncia do artigo serăo descritos os mecanismos de comunicaçăo entre as duas ferramentas e como outras funcionalidades, nativas das próprias ferramentas, podem ser agregadas ŕ máquina de busca proposta. Além disso, como o objetivo final é possibilitar que as informaçőes e conteúdos de um dado domínio sejam consultados e recuperados de forma rápida, fácil e organizada [9], uma seçăo será dedicada a apresentar uma aplicaçăo web, a qual será chamada de Localiza, cujo objetivo é abstrair a engine de busca e prover uma interface de consulta amigável ao usuário final.
Buscas na web com a integraçăo Nutch-Solr
Assumindo-se que tanto o Nutch como o Solr foram adequadamente instalados e configurados em conformidade com a parte inicial do artigo, o primeiro passo para a disponibilizaçăo do mecanismo de busca envolverá a inicializaçăo do serviço de consultas. Naturalmente, nesta etapa, năo haverá qualquer dado a ser retornado em resposta a uma query, uma vez que nenhuma informaçăo foi previamente carregada na base de dados utilizada por esse serviço.
Assim, será iniciado o servidor Jetty que, por sua vez, tornará a aplicaçăo Solr ativa. Para isso, será efetuada uma chamada ao .jar de inicializaçăo do Jetty. O comando executado é apresentado na Listagem 1, e o arquivo acionado encontra-se em /example, dentro do diretório de descompactaçăo do Solr.
Listagem 1. Comando para start do Apache Solr.
java -jar start.jarApós a execuçăo da Listagem 1, uma maneira de verificar o correto start da aplicaçăo é chamar sua interface de administraçăo pelo browser. Isto pode ser feito pela URL http://localhost:8983/solr/admin/.
A Figura 1 apresenta a interface de administraçăo do Solr que deve ser renderizada.
Figura 1. Interface de administraçăo do Solr.
Uma vez que a aplicaçăo de consultas está ativa, é preciso agora carregá-la com dados. Como já dito anteriormente, neste artigo essa responsabilidade foi atribuída ao Nutch. Assim, de posse das configuraçőes definidas previamente, o próximo passo é executar o algoritmo da Listagem 2 a fim de que os dados possam ser capturados das fronteiras definidas pelos arquivos seed.txt (Listagem 3) e regex-urlfilter.txt (Listagem 4), ambos apresentados na parte 1 deste artigo. Os passos 2.1 a 2.6 da Listagem 2 podem ser executados através de uma única chamada ao script nutch do diretório NUTCH_RUNTIME_HOME/bin. A Listagem 5 apresenta o comando que deve ser acionado a fim de disparar todo o fluxo de execuçăo do crawler Nutch. Dois aspectos deste comando merecem uma consideraçăo antecipada:
1. O comando foi executado a partir do diretório NUTCH_RUNTIME_HOME;
2. Para fins de organizaçăo, criou-se, dentro de NUTCH_RUNTIME_HOME, o diretório crawl, que conterá as bases de dados geradas pelo Nutch.
Listagem 2. Algoritmo do fluxo básico de execuçăo do Nutch.
1. Injetar URLs iniciais.
2. Executar os próximos passos LOOP vezes
2.1. Gerar lista de URLs.
2.2. Buscar conteúdo das páginas.
2.3. Efetuar o parser do conteúdo de cada página.
2.4. Atualizar CrawlDB.
2.5. Atualizar LinkDB.
2.6. Indexar segmentos. Listagem 3. Conteúdo do arquivo seed.txt de URLs inicias.
http://www.ascii-code.com/Listagem 4. Conteúdo do arquivo regex-urlfilter.txt com fronteiras estendidas.
-^(file|ftp|mailto):
-\.(gif|GIF|jpg|JPG|png|PNG|ico|ICO|css|CSS|sit|SIT|eps|EPS|wmf|WMF|zip|ZIP|ppt|PPT|mpg|MPG|xls|XLS|gz|GZ|rpm|RPM|tgz|TGZ|mov|MOV|exe|EXE|jpeg|JPEG|bmp|BMP|js|JS)$
+^http://www.ascii-code.com/
+^http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
+^http://www.w3.org/Protocols/rfc2616/rfc2616.html
+^http://www.ietf.org/rfc/Listagem 5. Comando que dispara o crawler Nutch.
bin/nutch crawl urls/ -solr http://localhost:8983/solr -dir crawl/ -depth 5 -topN 5Foram definidos para o comando crawl da Listagem 5 os seguintes parâmetros:
· -solr: URL da aplicaçăo Solr que receberá os dados do processo de crawler;
· -dir: nome do diretório no qual o crawler alocará os dados capturados e gerados;
· -depth: encarando os links e as páginas web como uma árvore composta de ligaçőes e nós, respectivamente, esse parâmetro define a profundidade máxima de inspeçăo a ser alcançada pelo crawler nessa árvore, tendo como referęncia o nó-raiz, isto é, a página inicial (seed.txt). Outra maneira de entender esse parâmetro é por observar que ele define o número de repetiçőes do fluxo de crawler – a variável de iteraçăo (LOOP) do algoritmo da Listagem 2;
· -topN: estabelece o número máximo de páginas que serăo recuperadas em cada nível (tendo em mente a mesma analogia com a estrutura de árvore do parâmetro -depth) alcançado pelo crawler.
Uma prática comumente adotada é a de definir-se, nas etapas iniciais de implantaçăo de uma ferramenta de RI, uma profundidade reduzida de alcance do processo de crawler (novamente fazendo-se referęncia ŕ analogia da web como uma estrutura de árvore), ou seja, săo atribuídos aos parâmetros -depth e -topN valores significativamente menores quando comparados aos valores necessários para a inspeçăo completa de um domínio. Consequentemente, o número de páginas recuperadas em cada nível de varredura também é limitado. O objetivo dessa contençăo inicial do crawler é o de possibilitar uma verificaçăo de quais páginas estăo sendo inspecionadas e de quais năo estăo sendo submetidas a esse processo. Como neste artigo o volume de páginas envolvidas no processo de crawler é bem resumido, apenas sete páginas, a definiçăo de cinco iteraçőes (-depth) para o processo de varredura do Nutch é suficiente para alcançar as páginas contidas nas fronteiras do processo, assim como o estabelecimento da recuperaçăo de cinco páginas por iteraçăo (-topN).
Conforme exposto pela Figura 2, espera-se que o processo de crawler finalize tendo como resultado a inspeçăo de sete páginas. Para fins de verificaçăo dos dados obtidos por essa varredura, a Listagem 6 apresenta alguns comandos disponíveis no script bin/nutch.
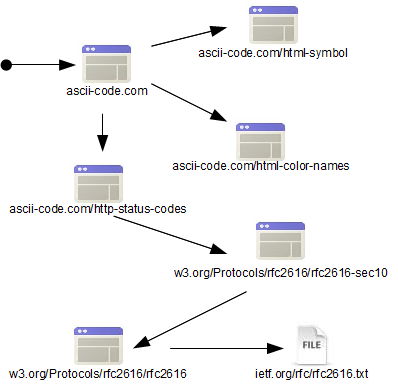
Figura 2. Fluxo de inspeçăo do Nutch.
Listagem 6. Comandos para verificaçăo das páginas inspecionadas pelo crawler.
bin/nutch readdb crawl/crawldb -dump dump
bin/nutch readdb crawl/crawldb -stats ... 


Confira outros conteúdos:



Perguntas frequentes

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programaçăo antes de começar a estudar com vocęs, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda năo tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocęs e logo percebi que săo os melhores do Brasil. É um passo a passo incrível. Só năo aprende quem năo quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocęs estăo fazendo parte da minha jornada nesse mundo da programaçăo, irei assinar meu contrato como programador graças a plataforma.
Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que năo tem como năo aprender, estăo de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tăo presente na vida acadęmica de seus alunos, parabéns!
Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!
Adauto Junior
Já fiz alguns cursos na área e nenhum é tăo bom quanto o de vocęs. Estou aprendendo muito, muito obrigado por existirem. Estăo de parabéns... Espero um dia conseguir um emprego na área.
