As pr¾ximas colunas abordarÒo o conceito de Business Intelligence dentro do banco de dados Oracle.
Todos sabemos como Ú importante extrair informaþ§es gerenciais do banco de dados. Ter acesso aos dados transacionais (ou relacionais, como prefira no banco de dados Ú uma realidade para praticamente todas as empresas.
Sistemas de gerenciamento empresarial (ERP) sÒo responsßveis por armazenar e manter dados sob a rÝgida fiscalizaþÒo e controle de processos. Isso faz com que as empresas consigam manter as operaþ§es bßsicas do dia-a-dia, como Folha de Pagamento, RecebÝveis, Pagamentos e Controle Contßbil. PorÚm, ter as operaþ§es controladas jß nÒo Ú suficiente em um ambiente de alta competitividade.
Para se tomar decis§es, Ú necessßrio ter acesso ao maior volume de informaþ§es possÝvel, dentro de um prazo razoßvel e de uma maneira permita analisar os dados com facilidade. Dentro desta perspectiva surgiu a necessidade de se adaptar os dados transacionais para que fosse possÝvel extrair informaþ§es gerenciais.
Conceitualmente os primeiros sÒo chamados de OLTP (Online Transaction Processing) e os segundos de DSS (Decision Support System). Conceitos
Em uma rßpida pesquisa na Internet, pode-se encontrar facilmente diversos conceitos relacionados ao Business Intelligence. Na Wikipedia encontra-se:
- Data Warehouse (DW): sistema de comliutaþÒo utilizado liara armazenar informaþÒo relativa Ós atividades de uma emliresa em bancos de dados, de forma consolidada.
- Data Mart: sub-conjunto de dados de um Data Warehouse. Geralmente sÒo dados referentes a um assunto em esliecial ou diferentes nÝveis de sumarizaþÒo.
- Business Intelligence (BI): Ú um conjunto de metodologias de gestÒo imlilementadas atravÚs de ferramentas de software, cuja funþÒo Ú liroliorcionar ganhos nos lirocessos decis¾rios gerenciais e da alta administraþÒo nas organizaþ§es.
Estas, dentre uma infinidade de outras definiþ§es, deixam claro o que se quer alcanþar com estes trÛs componentes bßsicos: a inteligÛncia por trßs dos dados. Em maior ou menor grau, com maior ou menor abrangÛncia, ter acesso Ós informaþ§es armazenadas e extrair destes dados subsÝdios para tomada de decisÒo Ú fundamental para sobrevivÛncia das empresas. Necessidades
O mercado de BI Ú um dos que mais tem crescido ao longo dos ·ltimos anos. Por este motivo os fornecedores de banco de dados tÛm procurado atender a esta demanda oferecendo produtos cada vez mais competitivos.
Por outro lado, o mercado de trabalho exige um profissional cada vez mais competente para lidar com esta demanda. Sem nos aprofundarmos neste aspecto, estß claro que o profissional de BI deve aliar competÛncias tÚcnicas no banco de dados ao conhecimento do neg¾cio da empresa.
Cada vez mais os produtos de BI deixam de ser uma ôcaixa pretaö e passam a compor o neg¾cio da empresa. Isso faz com que todos os profissionais envolvidos no processo assumam riscos e responsabilidades. No BI tradicional havia a preocupaþÒo em levar informaþ§es aos usußrios. No atual, deve-se criar inteligÛncia nos processos do neg¾cio. Processo
O processo bßsico que estß por trßs de um BI Ú identificar padr§es nos dados armazenados. Com base nestes padr§es Ú possÝvel propor anßlises que possam prever o comportamento de um determinado perfil, seja cliente, produto, perÝodo, etc. Com isso Ú possÝvel extrair informaþ§es importantes para a ßrea financeira, marketing, seguranþa, etc. Oracle 10g R 2
Nesta versÒo do Oracle foi disponibilizado o pacote DBMS_PREDICTIVE_ANALYTICS. AtravÚs deste pacote Ú possÝvel medir o grau de aderÛncia dos dados Ós previs§es que se pode realizar.
A estrutura do pacote Ú:
PROCEDURE EXPLAIN
| Argument Name | Type | In/Out | Default? |
| DATA_TABLE_NAME | VARCHAR2 | IN | |
| EXPLAIN_COLUMN_NAME | VARCHAR2 | IN | |
| RESULT_TABLE_NAME | VARCHAR2 | IN | |
| DATA_SCHEMA_NAME | VARCHAR2 | IN | DEFAULT |
PROCEDURE PREDICT
| Argument Name | Type | In/Out | Default? |
| ACCURACY | NUMBER | OUT | |
| DATA_TABLE_NAME | VARCHAR2 | IN | |
| CASE_ID_COLUMN_NAME | VARCHAR2 | IN | |
| TARGET_COLUMN_NAME | VARCHAR2 | IN | |
| RESULT_TABLE_NAME | VARCHAR2 | IN | |
| DATA_SCHEMA_NAME | VARCHAR2 | IN | DEFAULT |
O objetivo dos procedimentos sÒo:
û Procedimento EXPLAIN: analisa o conjunto de dados para explicar o valor de cada atributo. Quanto maior o valor, mais forte o relacionamento entre os dados.
û Procedimento PREDICT: retorna um conjunto de valores que permite analisar o grau de confianþa na previsÒo do conjunto de dados.
Imagine que uma empresa tenha um problema para analisar. Este problema estß relacionado ao pagamento que os clientes realizam todos os meses. A proposta Ú realizar um estudo sobre as prestaþ§es do cadastro. Sabe-se que o estßgio de pagamento das prestaþ§es segue a tabela a seguir:
| Estßgio de Recebimento das Parcelas |
| R û Renegociado |
| P ûParcialmente recebido |
| A û Aberto / NÒo recebido |
| B û Baixado / Quitado |
| X û Renegociado |
Inicia-se o processo de anßlise com a ExplicaþÒo dos dados da tabela PARCELA e com base na coluna de estßgio de recebimento. O comando a seguir cria a tabela REC_RESULTADOS e atribui o conte·do da anßlise realizada. Note que, como a tabela serß criada, caso vocÛ queira fazer diversas anßlises precisarß apagar a tabela REC_RESULTADOS ou criar tabelas com outros nomes para novas anßlises.
begin
DBMS_PREDICTIVE_ANALYTICS.EXPLAIN(
DATA_TABLE_NAME => 'PARCELA',
EXPLAIN_COLUMN_NAME => 'STPARCELA',
RESULT_TABLE_NAME => 'REC_RESULTADOS' );
end;
/
SELECT * FROM REC_RESULTADOS;
| ATTRIBUTE_NAME | EXPLANATORY_VALUE | RANK |
| CDCONTR | ,572647579 | 1 |
| DTVENC_YYYY | ,281829136 | 2 |
| NRPARCELA | ,261050041 | 3 |
| DTVENC_DD | ,248689654 | 4 |
| NRSEQUENCIA | ,246277295 | 5 |
| CDSERIE | ,071490398 | 6 |
| DTVENC_DDD | ,008667611 | 7 |
| CDRENEG | ,001523855 | 8 |
| DTVENC_WW | ,00018959 | 9 |
| DTVENC_HH24 | 0 | 10 |
| DTVENC_MI | 0 | 10 |
| DTVENC_MM | 0 | 10 |
| DTVENC_D,071490398 | 0 | 10 |
Pode-se notar que o procedimento realizou uma anßlise que retornou o grau de confianþa para se prever algo em cada campo da tabela PARCELA.
O comando a seguir irß analisar o processo de previsÒo com base no resultado do comando anterior.
SET SERVEROUTPUT ON
DECLARE
v_predict_accuracy NUMBER(30,10);
BEGIN
DBMS_PREDICTIVE_ANALYTICS.PREDICT (
ACCURACY => v_predict_accuracy,
DATA_TABLE_NAME => 'PARCELA',
CASE_ID_COLUMN_NAME => 'CDCONTR',
TARGET_COLUMN_NAME => 'STPARCELA',
RESULT_TABLE_NAME => 'REC_PREVISAO');
DBMS_OUTPUT.PUT_LINE('*** Accuracy ***');
DBMS_OUTPUT.PUT_LINE(v_predict_accuracy);
END;
/
*** Accuracy ***
,5727376841
O resultado anterior indica que, com base nas colunas que foram rankeadas de 1 a 9 na listagem anterior, pode-se considerar um grau de acerto de mais de 57% sobre os dados analisados.
Quando se pesquisa a tabela criada (REC_PREVISAO), obtÚm-se a probabilidade de cada contrato por tipo de parcela. Isso porque foram estes os campos atribuÝdos ao procedimento PREDICT para anßlise. Em CASE_ID foi colocada a chave para anßlise e em TARGET_COLUMN_NAME a coluna alvo da anßlise. Nota-se que o banco de dados retornou, para cada contrato, a coluna mais provßvel e a probabilidade de ocorrÛncia.
| CDCONTR | PREDICTION | PROBABILITY |
| 1 | X | ,332324415 |
| 2 | X | ,333333343 |
| 3 | B | ,19823128 |
| 5 | A | ,249942511 |
| 6 | R | ,229957595 |
| 7 | A | ,245485559 |
| 8 | B | ,19823128 |
| 10 | B | ,191841915 |
| 11 | P | ,172297433 |
| 12 | A | ,249915019 |
| 13 | B | ,199963599 |
| 14 | B | ,199917749 |
| 15 | B | ,19616136 |
| 16 | B | ,189381897 |
| 17 | B | ,199595645 |
| 18 | R | ,229957595 |
| 19 | B | ,192676052 |
| 20 | A | ,248632267 |
| 21 | A | ,248632267 |
| 22 | R | ,217115507 |
| 23 | R | ,217115507 |
| 24 | R | ,217115507 |
| 25 | B | ,188040942 |
| 26 | A | ,239121288 |
Agora vocÛ jß pode praticar um pouco e extrair suas pr¾prias conclus§es atravÚs da anßlise dos dados coletados. Na pr¾xima ediþÒo, vamos ver uma ferramenta grßfica (e grßtis) da Oracle que nos permite realizar este trabalho de uma maneira mais simpßtica. Esta ferramenta Ú o Oracle Data Miner.
Veremos agora como utilizar o Oracle Data Miner, uma ferramenta visual e gratuita da Oracle para extrair os mesmos dados, mas de uma maneira bem mais simpßtica.
O Oracle Data Miner pode ser obtido gratuitamente no Portal de desenvolvimento da Oracle: http://www.oracle.com/technology/products/bi/odm/odminer.html.A instalaþÒo Ú bastante simples, como tem sido com a maior parte das ferramentas da Oracle desenvolvidas em Java. Depois de criar um diret¾rio (exemplo: c:\oracle\odm) e extrair os dados do arquivo ZIP, vocÛ deve clicar duas vezes em ODMINERW.EXE que se encontra no subdiret¾rio BIN.
A primeira coisa a fazer Ú definir uma configuraþÒo de acesso ao banco de dados. VocÛ encontrarß a tela da Figura 1:
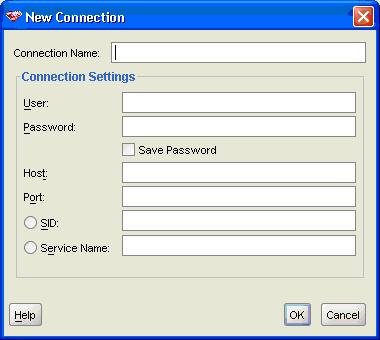
Figura 1. ConfiguraþÒo da conexÒo com o banco de dados
DÛ um nome Ó sua conexÒo, informe o usußrio, senha, servidor, porta de comunicaþÒo e SID ou nome do serviþo. Logo ap¾s clicar em OK, vocÛ terß a validaþÒo do seu ambiente. Em caso de falha, verifique os dados informados. Caso vocÛ tenha problemas, verifique com o administrador do seu ambiente se tudo estß correto. Estes dados sÒo os mesmos que vocÛ utiliza normalmente para se conectar ao banco de dados, portanto vocÛ nÒo deverß encontrar dificuldades.
A Figura 2 mostra a tela inicial do ODM.
Figura 2. Tela inicial do Oracle Data Miner
De todas as opþ§es que aparecem, a primeira que nos interessa Ú ôData Sourcesö, pois aqui estarÒo os schemas que possuem as tabelas que serÒo analisadas.
Conforme vocÛ pode notar na Figura 3, no schema SGI jß estÒo criadas as duas tabelas do artigo anterior: AA_EXPLAIN_RESULTS (REC_RESULTADOS) e AA_PREDICT_RESULTS (REC_PREVISAO). Troquei os nomes das tabelas apenas para facilitar a localizaþÒo na ferramenta.
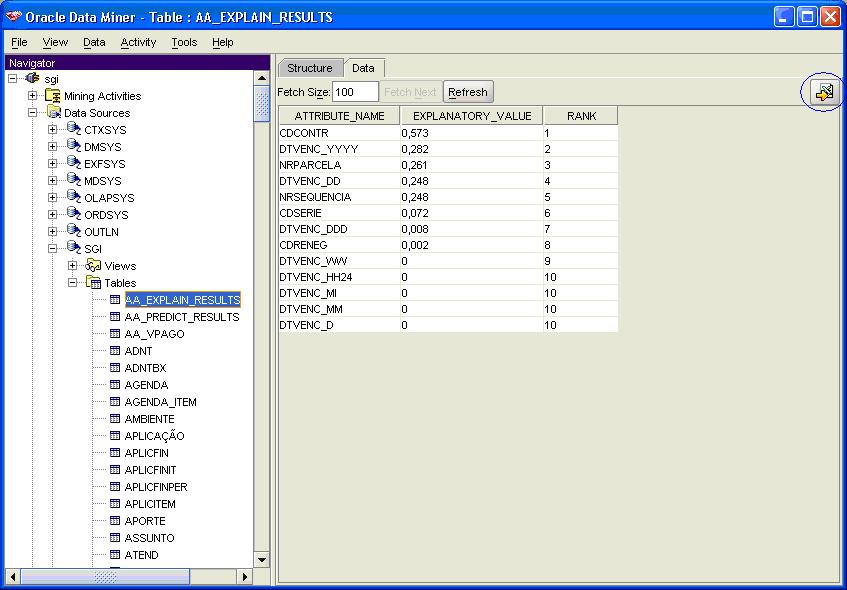
Figura 3. Dados extraÝdos do EXPLAIN
Veja que os mesmos dados que foram mostrados na busca que realizamos no SQL*Plus estÒo disponÝveis na ferramenta. As vantagens comeþam no volume de informaþ§es que temos disponÝvel: podemos ver a estrutura da tabela criada (Figura 4). Uma outra vantagem Ú a possibilidade de exportar os dados para uma planilha Excel, simplesmente clicando no botÒo destacado.
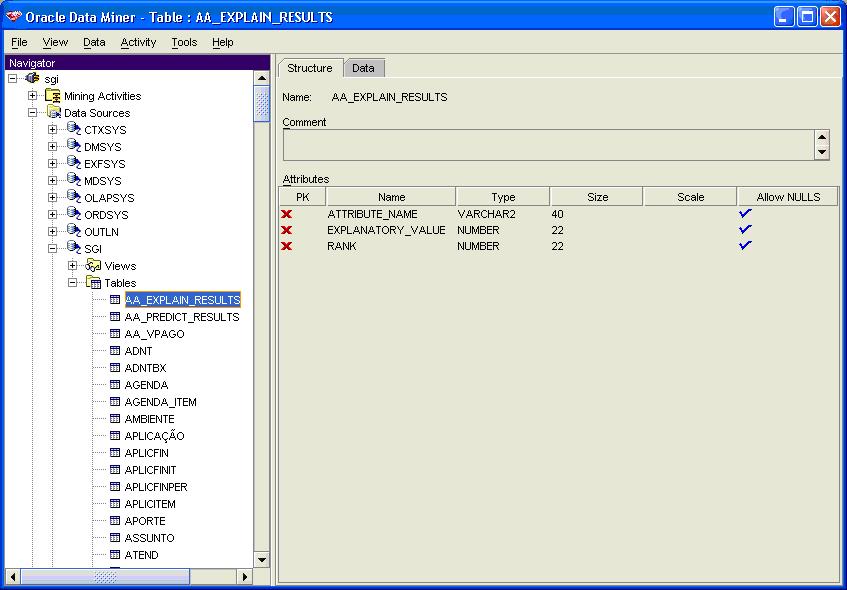
Figura 4. Estrutura da tabela criada no EXPLAIN
Uma outra vantagem Ú que podemos realizar o mesmo trabalho que fizemos anteriormente selecionando a tabela (ou visÒo) e, com o botÒo direito, selecionar se queremos fazer uma previsÒo (PREDICT) ou explicaþÒo (EXPLAIN), conforme Figura 5.
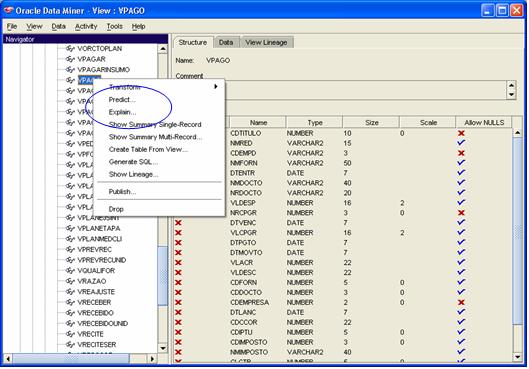
Figura 5. Opþ§es para gerar automaticamente o PREDICT e o EXPLAIN
Ao clicar em qualquer uma das duas opþ§es, o ODM abre um wizard para conduzir a criaþÒo das tabelas (Figura 6).
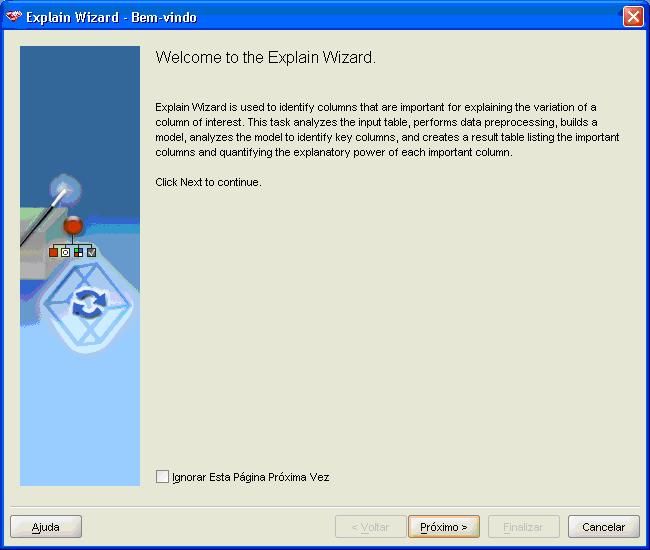
Figura 6. Wizard para o EXPLAIN
VocÛ seleciona o atributo que quer explicar (Figura 7):
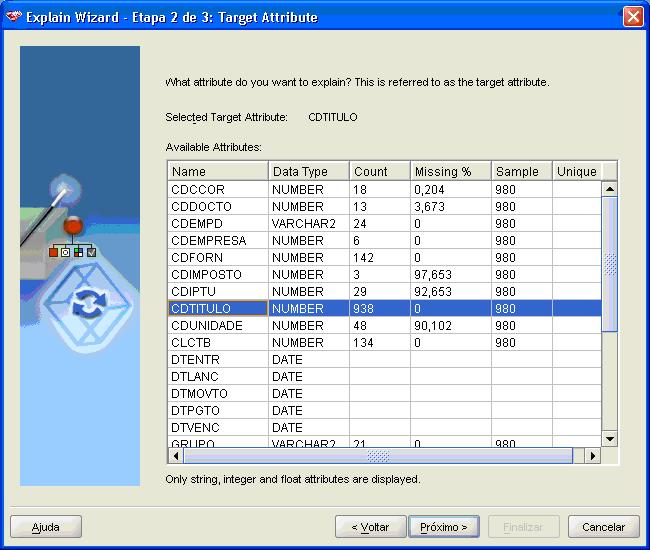
Figura 7. SeleþÒo do atributo
E atribui um nome Ó tabela que serß criada (Figura 8):
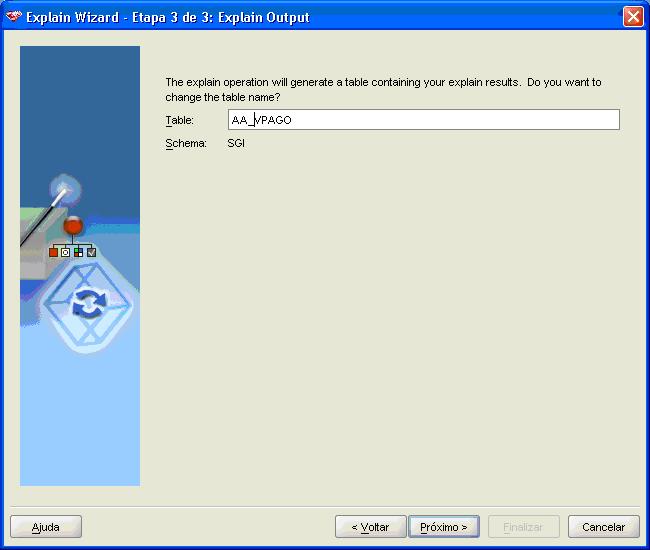
Figura 8. DefiniþÒo do nome da tabela
Pronto! O trabalho estß realizado. O mesmo processo pode ser feito com o PREDICT.
Outros trabalhos relacionados Ó extraþÒo de dados gerenciais podem ser realizados no ODM, conforme vocÛ pode ver na Figura 9.
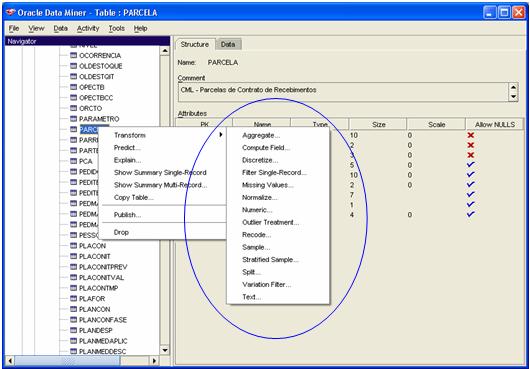
Figura 9. Opþ§es de TransformaþÒo para anßlise de dados gerenciais
AtÚ a pr¾xima!







