


O objetivo deste artigo é demonstrar como definir os níveis de serviços requeridos pelos usuários e como dimensionar a capacidade do HW para atender aos níveis acordados. Sendo assim, este artigo serve para conhecer quais volumes de negócio se relacionam aos elementos de infraestrutura, entender quais as principais funcionalidades do negócio impactam os servidores e antever problemas de desempenho.
Em que situaçăo o tema é útil?
Determinar a capacidade de produçăo atual e futura com níveis de desempenho satisfatórios
Resumo DevMan:
É cada vez mais comum nas organizaçőes de TI gerenciar, analisar e corrigir problemas de desempenho que os usuários relatam. Neste contexto, este artigo visa a detalhar teoricamente um projeto de capacity planning, bem como mostrar quais săo e como coletar as métricas importantes para a realizaçăo desse tipo de projeto.
É cada vez mais comum nas organizaçőes de TI gerenciar, analisar e corrigir problemas de desempenho que os usuários relatam. No mundo perfeito, os administradores se preparam com antecedęncia a fim de evitar gargalos, utilizando-se do que chamamos de capacity planning. Esse tipo de projeto tem por objetivo determinar a capacidade de produçăo para responder a novas demandas, fornecendo níveis satisfatórios de serviços aos usuários e mantendo, assim, uma boa relaçăo custo-benefício. Neste contexto, este artigo visa a detalhar teoricamente um projeto de capacity planning, bem como mostrar quais săo e como coletar as métricas importantes para a realizaçăo desse tipo de projeto.
A Figura 1 mostra os tręs pilares fundamentais para a realizaçăo de um capacity planning.
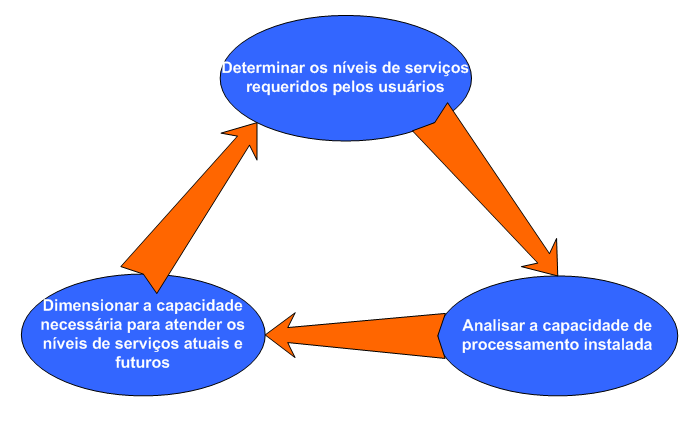
Figura 1. Pilares do Capacity Planning
Vamos, entăo, detalhar cada um desses pilares.
Determinar os níveis de serviços requeridos pelos usuários
O primeiro passo em projeto de capacity planning é categorizar o trabalho realizado pelo sistema e alinhar as expectativas dos usuários do modo como o trabalho é realizado.
Nessa fase, o capacity planning deve focar seus esforços em:
· Who: quem realiza o trabalho (usuário ou departamento);
· What: qual tipo de trabalho é realizado (relatório de finanças);
· How: como o trabalho é realizado (rotina batch); e
· Establish Service Levels: acordar um nível satisfatório entre service provider (provedor do serviço) e o service consumer (cliente). O service levels é frequentemente definido pela perspectiva do usuário, tipicamente em tempo de resposta e throughput.
O processo global de estabelecimento de requisitos em nível de serviço exige primeiro uma compreensăo dos workloads (cargas de trabalho) e service que é a classificaçăo lógica do trabalho realizado em um computador do sistema, como mostrado na Figura 2.
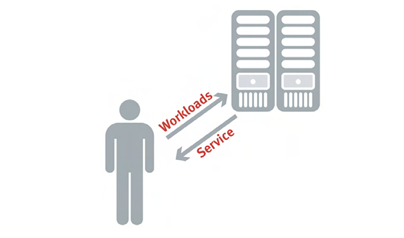
Figura 2. Workloads e Service
A partir deste entendimento inicial, como estabelecer os níveis de serviço?
Os níveis de serviço devem ser estabelecidos conforme as metas plausíveis para o negócio e, para tanto, será necessário conhecer, no mínimo:
· Os processos de negócio envolvidos com determinado serviço;
· A prioridade para o negócio do serviço;
· O crescimento esperado da procura pelo serviço durante os próximos anos;
· O pior tempo de resposta aceitável para o serviço; e
· Sazonalidade do serviço.
Năo săo necessários acordos formais e assinados pela TI e a área de negócios, mas é recomendável garantir que ambas as partes recebam as informaçőes supracitadas. Estabelecidos tais acordos, o Capacity poderá garantir um desempenho adequado a um custo mínimo.
Analisar a capacidade de processamento instalada
Devemos analisar a capacidade atual para que ela seja alinhada ŕs expectativas de tempo de resposta dos usuários.
Nessa fase é necessário:
· Comparar as medidas de todos os itens referenciados nos acordos de nível de serviço com seus objetivos, o que fornece a resposta sobre a capacidade atual estar ou năo adequada ao que esperam os usuários;
· Analisar o uso de todos os dispositivos envolvidos no sistema CPU, memória, dispositivo de I/O, banco de dados, servidor de aplicaçăo, entre outros; e
· Mensurar o tempo de resposta e a utilizaçăo de recursos para cada workload e determinar quais recursos do sistema estăo sendo mais consumidos para cada workload.
Como mensurar o uso global de recursos?
É importante realizar o monitoramento de cada um dos recursos envolvidos no sistema computacional, verificando se algum deles está saturado (utilizaçăo próxima ou igual a 100%). Caso haja saturaçăo, os workloads que utilizam tal recurso estarăo susceptíveis a apresentar tempos piores de resposta. O tempo de resposta pode ser definido segundo a fórmula abaixo:
Tempo de Resposta = Tempo de Serviço + Tempo de Espera (Wait Events)Por isso, mostra-se importante também o detalhamento de cada workload com relaçăo aos recursos utilizados, refletido em algo semelhante ŕ Figura 3. Por exemplo, imagine um comando ou processo que obtenha o relatório das apólices de seguro fechadas no último męs e um detalhamento de onde é gasto o tempo para completar este workload.
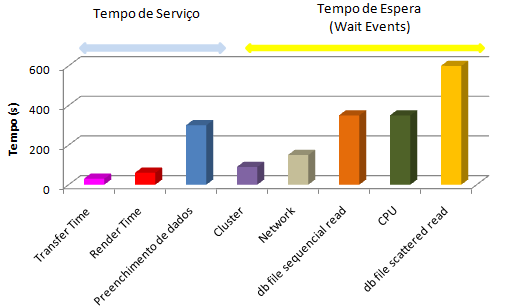
Figura 3. Detalhamento de recursos utilizados por workload
Dimensionar a capacidade necessária para atender os níveis de serviços atuais e futuros
Utilizando as previsőes de crescimento do negócio e os requisitos do sistema, deve-se implementar as alteraçőes necessárias para manter os mesmos níveis de serviço alinhados com as perspectivas de crescimento do negócio.
Nessa fase será necessário conhecer:
· Crescimento esperado do negócio;
· Requisitos para novas funcionalidades/aplicaçőes; e
· Consolidaçăo dos itens acima com as métricas coletadas pelos dispositivos atuais.
Conhecendo algumas métricas
Agora que conhecemos a teoria para a realizaçăo de um projeto de capacity planning, vamos analisar quais métricas podem ser coletadas para cada camada que constitui o sistema computacional.
Primeiramente, temos que definir thresholds (limites) que indicam níveis de conforto satisfatórios, por exemplo 50 GB de redo diário. Ultrapassando esse nível, os tamanhos dos arquivos tęm de ser reajustados para manter o tempo de leitura recomendado pelo Oracle (15 a 30 min).
Depois disso, será necessário verificar as métricas do Oracle com as métricas coletadas pelos outros componentes do sistema computacional. As métricas que podem ser coletadas săo:
· CPU: utilizaçăo, run-queue, context switches (voluntárias e involuntárias), interrupçőes, system calls;
· Storage: Número de IOPS/second, Queue Depth, Tamanho de IOPS, Tempo de resposta, throughput;
· Filesystem: crescimento e tempo de resposta;
· Memória: memória física consumida, swap in/out e Page faults;
· Rede: Throughput e detalhes do netstat –s e kstat; e
· Servidor de aplicaçăo (supondo IIS): time-taken, bytes-sent, bytes-received, status, cs-uri-stem, cs-uri-query, cs(cookie), cs(referrer).
Do monitoramento do servidor de aplicaçăo, podemos retirar as informaçőes plotadas como exemplo na Figura 4.
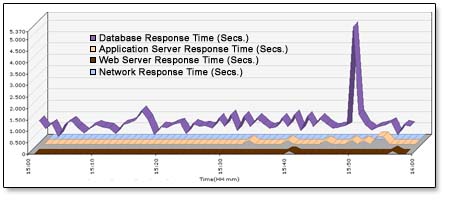
Figura 4. Workloads e Service
Já as métricas que devem ser coletadas para uma análise detalhada do banco de dados săo:
· Users (transactions, logons, parses);
· Redo activity;
· Temp activity;
· Tablespace e espaço usado pelos objetos;
· Pga usage;
· Sga usage;
· Parallel Operations;
· I/O Operations; e
· File Stats e Temp Stats.
Para Wait events devemos analisar os top waits events, events idle e parallel (PX*) waits (se houver), conforme pode ser visto no exemplo da Figura 5.
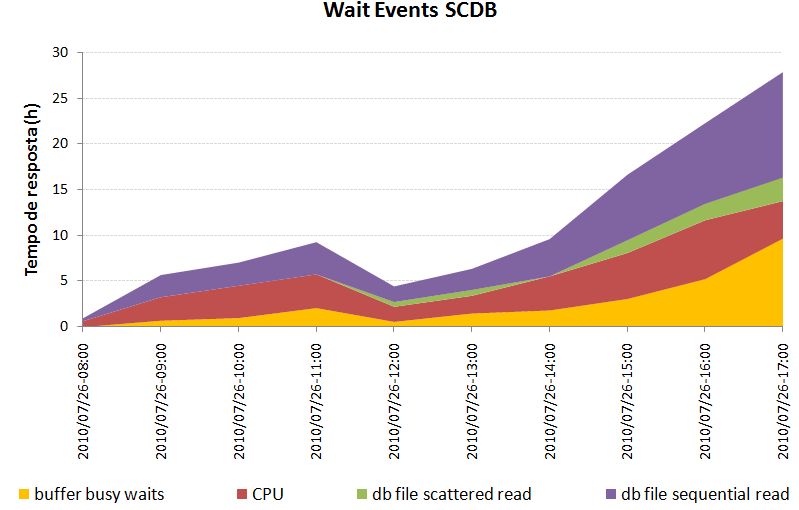
Figura 5. Top Wait Events
A decomposiçăo do tempo de resposta mostra que events idle e parallel năo săo significativos no dia analisado desta base. Entăo vamos detalhar rapidamente os principais wait events plotados na Figura 5:
· CPU: tempo gasto de CPU para processamento das operaçőes;
· Db file scattered read: tempo gasto com leituras multiblocks;
· Db file sequencial read: tempo gasto com leituras single-blocks;
...
Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.