


Quando se leva em conta a necessidade de compartilhamento de informaçőes entre diferentes sistemas, arquivos ainda săo um meio ainda bastante comum de integraçăo. Esse tipo de prática está normalmente associado ao processamento de um grande volume de dados, podendo tanto acontecer entre softwares de uma mesma companhia, quanto entre aplicaçőes de organizaçőes distintas.
Listas de preços geradas por um determinado fornecedor, lançamentos contábeis e/ou financeiros, movimentaçőes bancárias e registros de folha de pagamento săo apenas alguns exemplos comuns de agrupamento de dados comumente carregados em bases relacionais por meio de arquivos.
Existem inúmeras soluçőes que podem ser empregadas em cenários como os citados aqui. A própria Microsoft conta com o Integration Services, sendo este último um dos componentes do SQL Server. A grande vantagem deste serviço (Integration Services) está em permitir que se obtenham aplicaçőes robustas e extremamente flexíveis no que se refere processamento de informaçőes.
Ainda sobre o Integration Services, merece destaque o fato de que o mesmo dispőe de mecanismos capazes de processar grandes massas de dados organizadas sob a forma dos mais variados tipos de arquivos, sem que isto implique em grandes esforços de implementaçăo. Săo suportados, neste caso, formatos como texto (em que cada posiçăo pode corresponder a um campo/informaçăo), CSV (sigla do inglęs "Comma-separated values", com os diferentes valores de cada linha estando separados neste caso por ponto-e-vírgula), XML ou ainda, planilhas do Excel e bancos de dados Access.
No entanto, nem sempre será possível se contar com ferramentas que simplificam a importaçăo de dados presentes em arquivos. Se o gerenciador de banco de dados utilizado for o SQL Server, a classe SqlBulkCopy do .NET Framework (namespace System.Data.SqlClient) pode se revelar como um instrumento de grande valia em tais situaçőes.
Partindo de objetos dos tipos DataReader, DataTable ou DataRow, a classe SqlBulkCopy fornece meios para a carga eficiente de grandes volumes de dados em tabelas do SQL Server. Além disso, a performance conseguida através de instâncias da classe SqlBulkCopy costuma se mostrar bem superior, sobretudo se comparada ŕ execuçăo de centenas de instruçőes SQL através de referęncias to tipo Command ou ainda, com mecanismos como LINQ to SQL ou o Entity Framework.
A finalidade deste artigo é demonstrar como o tipo SqlBulkCopy pode ser utilizado na importaçăo do conteúdo de arquivos para bases de dados do SQL Server. Visando cumprir este objetivo, será apresentado um exemplo prático de como se proceder com a carga de um arquivo com a extensăo .csv.
A soluçăo apresentada neste artigo foi criada no .NET framework 4.5, através da utilizaçăo do Microsoft Visual Studio 2012 Professional.
Basicamente, será construída uma Console Application de nome “TesteSqlBulkCopy (Figura 1), a qual será responsável por importar informaçőes de um arquivo .csv contendo preços de produtos comercializados por um estabelecimento comercial.
Figura 1: Criando o projeto TesteSqlBulkCopy
Num cenário real, este catálogo de produtos poderia estar sendo gerado por um fornecedor da empresa considerada, englobando neste caso um número extenso de itens que seriam reprocessados a cada novo arquivo recebido (ao menos para os testes aqui descritos, será efetuada a carga de um arquivo com poucos itens, somente para efeitos de simulaçăo).
Uma vez que a soluçăo e o projeto correspondente tenham sido gerados, faz-se necessária a inclusăo de uma referęncia para a biblioteca System.Configuration (Figura 2). Este ajuste foi efetuado de maneira que se possam acessar funcionalidades disponibilizadas pelo tipo ConfigurationManager (conforme será demonstrado durante a implementaçăo das classes que compőem a aplicaçăo).
Figura 2: Adicionando ao projeto uma referęncia ŕ biblioteca System.Configuration
Quanto ŕ estrutura das informaçőes presentes no catálogo de produtos, o arquivo .csv em que constarăo tais registros possuirá as seguintes colunas (já mencionadas aqui na ordem esperada pela aplicaçăo de exemplo):
Na Figura 3 está um exemplo de como seria este arquivo.
OBSERVAÇĂO: Para efeito de testes, a aplicaçăo de exemplo irá sempre procurar por um arquivo de nome “AtualizacaoCatalogo.csv” no diretório “C:\Temp\Catalogo\”.
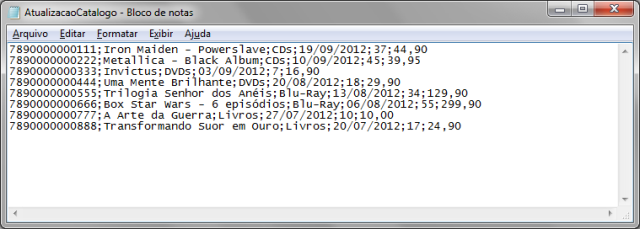
Figura 3: Arquivo .csv contendo o catálogo de produtos
A estrutura da tabela que receberá as informaçőes do arquivo AtualizacaoCatalogo.csv é apresentada na Listagem 1. Conforme será demonstrado mais adiante, está se partindo do pressuposto que essa estrutura (TB_CARGA_CATALOGO) faz parte de um banco de dados também chamado “TesteSqlBulkCopy”.
Listagem 1: Estrutura da tabela TB_CARGA_CATALOGO
CREATE TABLE [dbo].[TB_CARGA_CATALOGO](
[CodigoBarras] [varchar](13) NOT NULL,
[NomeProduto] [varchar](50) NOT NULL,
[Categoria] [varchar](30) NOT NULL,
[DtIniComercializacao] [datetime] NOT NULL,
[QtdDisponivel] [int] NOT NULL,
[VlSugerido] [decimal](10,2) NOT NULL,
CONSTRAINT [PK_TB_CARGA_CATALOGO] PRIMARY KEY ([CodigoBarras])
)
Já na Listagem 2 está o arquivo app.config do projeto TesteSqlBulkCopy. Encontram-se declarados no mesmo os seguintes itens:
Listagem 2: Arquivo app.config da aplicaçăo TesteSqlBulkCopy
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<connectionStrings>
<add name="TesteSqlBulkCopy"
providerName="System.Data.SqlClient"
connectionString="Data Source=.;Initial Catalog=TesteSqlBulkCopy;Integrated Security=True"/>
</connectionStrings>
<appSettings>
<add key="CaminhoArquivoCatalogo"
value="C:\Temp\Catalogo\AtualizacaoCatalogo.csv"/>
</appSettings>
<startup>
<supportedRuntime version="v4.0"
sku=".NETFramework,Version=v4.5" />
</startup>
</configuration>
Com as diferentes configuraçőes do projeto de testes já definidas, chega o momento de se proceder com a implementaçăo das classes que serăo utilizadas por esta aplicaçăo.
A primeira dessas construçőes será o tipo estático ArquivoCatalogo (Listagem 3), o qual será responsável pela conversăo do conteúdo do arquivo .csv contendo o catálogo de produtos num objeto equivalente da classe DataTable (namespace System.Data).
Constam na classe ArquivoCatalogo as seguintes operaçőes:
A operaçăo GetInformacoesCatalogo faz ainda uso das seguintes classes:
Listagem 3: Classe ArquivoCatalogo
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Data;
using System.IO;
using System.Configuration;
namespace TesteSqlBulkCopy
{
public static class ArquivoCatalogo
{
private static DataTable CreateDataTableCatalogo()
{
DataTable dt = new DataTable();
dt.Columns.Add(
"Codigo", typeof(string));
dt.Columns.Add(
"Nome", typeof(string));
dt.Columns.Add(
"Categoria", typeof(string));
dt.Columns.Add(
"DtIniComerc", typeof(DateTime));
dt.Columns.Add(
"QtDisponivel", typeof(int));
dt.Columns.Add(
"PrecoSugerido", typeof(decimal));
return dt;
}
public static DataTable GetInformacoesCatalogo()
{
DataTable dtProdutos = CreateDataTableCatalogo();
using (StreamReader arquivo = new StreamReader(
ConfigurationManager
.AppSettings["CaminhoArquivoCatalogo"]))
{
string linhaArquivo;
string[] campos;
DataRow registro;
while (!arquivo.EndOfStream)
{
linhaArquivo = arquivo.ReadLine();
campos = linhaArquivo.Split(
new string[] { ";" },
StringSplitOptions.None);
registro = dtProdutos.NewRow();
registro["Codigo"] = campos[0].Trim();
registro["Nome"] = campos[1].Trim();
registro["Categoria"] = campos[2].Trim();
registro["DtIniComerc"] =
Convert.ToDateTime(campos[3]);
registro["QtDisponivel"] =
Convert.ToInt32(campos[4]);
registro["PrecoSugerido"] =
Convert.ToDecimal(campos[5]);
dtProdutos.Rows.Add(registro);
}
}
return dtProdutos;
}
}
}
Na Listagem 4 está a definiçăo da classe estática CatalogoBulkCopyHelper. Esta última disponibiliza o método CreateSqlBulkCopy, o qual recebe como parâmetro uma conexăo do tipo SqlConnection (namespace System.Data.SqlClient). Como resultado de sua execuçăo, a operaçăo CreateSqlBulkCopy retornará uma instância da classe SqlBulkCopy, objeto este devidamente configurado para a carga das informaçőes do catálogo.
Sobre a criaçăo de uma referęncia da classe SqlBulkCopy a partir da operaçăo CreateSqlBulkCopy, é possível observar:
Listagem 4: Classe CatalogoBulkCopyHelper
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Data.SqlClient;
namespace TesteSqlBulkCopy
{
public static class CatalogoBulkCopyHelper
{
public static SqlBulkCopy CreateSqlBulkCopy(
SqlConnection conexao)
{
SqlBulkCopy bc = new SqlBulkCopy(conexao);
bc.DestinationTableName = "dbo.TB_CARGA_CATALOGO";
bc.ColumnMappings.Add("Codigo", "CodigoBarras");
bc.ColumnMappings.Add("Nome", "NomeProduto");
bc.ColumnMappings.Add("Categoria", "Categoria");
bc.ColumnMappings.Add("DtIniComerc",
"DtIniComercializacao");
bc.ColumnMappings.Add("QtDisponivel", "QtdDisponivel");
bc.ColumnMappings.Add("PrecoSugerido", "VlSugerido");
return bc;
}
}
}
Será por meio do método ProcessarImportacao da classe CatalogoFacade (Listagem 5) que ocorrerá a leitura do arquivo AtualizacaoCatalogo.csv e, consequentemente, a carga dos dados deste último para a tabela TB_CARGA_CATALOGO.
O tipo CatalogoFacade pode ser considerado um exemplo de uso de um padrăo de projeto conhecido como Façade. Através deste pattern um conjunto de açőes envolvendo diversos objetos pode ser encapsulado, de forma que estruturas que dependam de uma ou mais funcionalidades năo precisem realizar uma série de açőes complexas para produzir o efeito esperado.
Quanto ŕ implementaçăo da operaçăo ProcessarImportacao, deve ser destacado:
Listagem 5: Classe CatalogoFacade
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Data;
using System.Data.SqlClient;
using System.Configuration;
namespace TesteSqlBulkCopy
{
public class CatalogoFacade
{
public void ProcessarImportacao()
{
using (SqlConnection conexao =
new SqlConnection(ConfigurationManager
.ConnectionStrings["TesteSqlBulkCopy"]
.ConnectionString))
{
conexao.Open();
SqlCommand cmd = conexao.CreateCommand();
cmd.CommandText =
"TRUNCATE TABLE dbo.TB_CARGA_CATALOGO";
cmd.ExecuteNonQuery();
using (SqlBulkCopy bc =
CatalogoBulkCopyHelper.CreateSqlBulkCopy(conexao))
{
bc.WriteToServer(
ArquivoCatalogo.GetInformacoesCatalogo());
}
}
}
}
}
Por fim, a Listagem 6 apresenta o código referente ŕ classe Program, com o método Main sendo acionado ao se executar este projeto de testes.
Conforme pode ser observado, uma instância de CatalogoFacade é criada dentro do método Main, invocando a partir disto o método ProcessarImportacao. Com esta açăo será carregado o conteúdo do arquivo .csv com informaçőes do catálogo de produtos e, na sequęncia, tais dados serăo inseridos na base de dados de testes.
Listagem 6: Classe Program
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace TesteSqlBulkCopy
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(
"Iniciando carga do catálogo de produtos...");
CatalogoFacade facade = new CatalogoFacade();
facade.ProcessarImportacao();
Console.WriteLine(
"Processamento concluído com sucesso!");
Console.ReadKey();
}
}
}
Executando a TesteSqlBulkCopy por meio do Visual Studio, será exibida uma tela como a que consta na Figura 4.
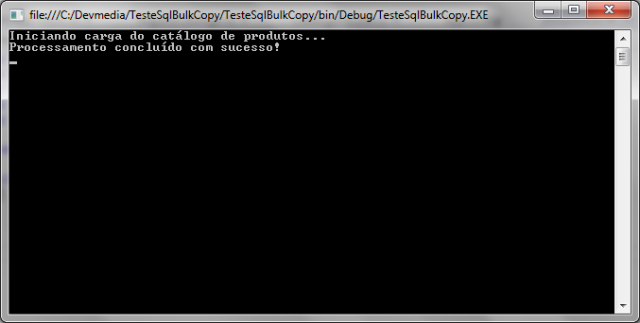
Figura 4: Carga dos dados já efetuada através da aplicaçăo TesteSqlBulkCopy
Consultando a tabela TB_CARGA_CATALOGO dentro do SQL Server Management Studio, contata-se que os dados foram carregados corretamente nessa estrutura (Figura 5).
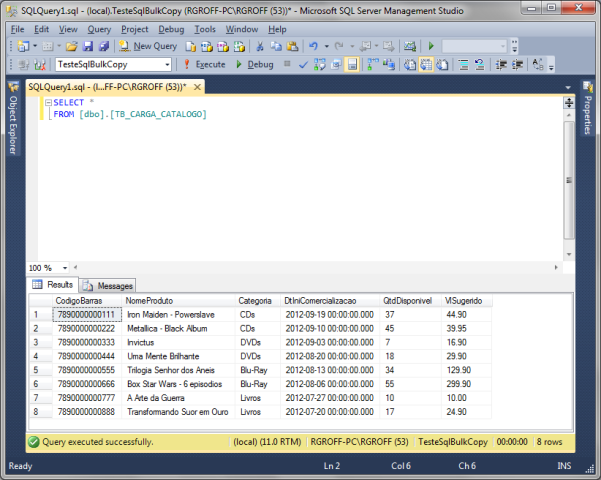
Figura 5: Consultando a tabela TB_CARGA_CATALOGO após a execuçăo da aplicaçăo TesteSqlBulkCopy
OBSERVAÇĂO: a exclusăo de informaçőes para a consequente carga de novos dados costuma ser um tipo de prática bastante comum na manipulaçăo de arquivos. Isto se justifica pois, em muitas situaçőes, os registros da tabela de destino năo representam a versăo definitiva: tais informaçőes serăo validadas e, posteriormente, transferidas para uma outra estrutura similar (através da execuçăo de comandos de INSERT, UPDATE ou ainda, DELETE). Importante destacar que todo este processo năo foi detalhado aqui por questőes de simplificaçăo.
Procurei com este artigo demonstrar uma maneira simples, porém bastante eficiente para a carga de centenas (ou até milhares) de registros em aplicaçőes .NET que dependam de bancos de dados no SQL Server. O uso da classe SqlBulkCopy năo substitui outros recursos para execuçăo de instruçőes SQL como objetos Command do ADO.NET, LINQ to SQL e até o Entity Framework. Na verdade, a utilizaçăo de tais mecanismos é mais adequada em situaçőes que envolvam o processamento de transaçőes a partir de telas de cadastro de informaçőes (e que, portanto, envolvem a execuçăo de poucos comandos SQL).
Espero que o conteúdo aqui abordado possa ser útil no seu dia-a-dia. Até uma próxima oportunidade!

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.