Classificaçăo e Análise de Dados usando Árvore de Decisăo
Olá, leitores! Estamos de volta e vamos falar sobre árvore de decisăo, provavelmente um dos métodos mais antigos de classificaçăo e análise de dados.
As árvores de decisăo săo uma representaçăo simples do conhecimento e uma forma eficiente de construir classificadores que podem predizer valores de determinados atributos de um conjunto de dados.
A modelagem gráfica de uma árvore consiste de folhas, também chamadas de nós, e ramos. Onde cada nó representa o conjunto de dados de uma classificaçăo, esta por sua vez representada pelos ramos.
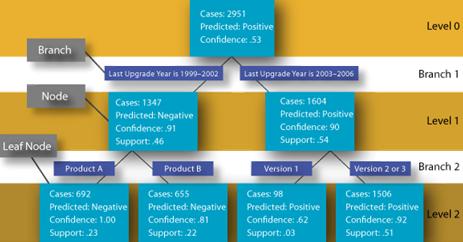
Figura 1 – Árvore de Decisăo em Níveis
Os níveis mostrados acima representam a classificaçăo dos dados. Cada nível exibe a que classe foi encontrada para aquele dataset. O primeiro nó é a raiz, o grupo no qual todos os dados se enquadram.
Vejam: a árvore vai se ramificando sobre os dados na tentativa de identificar quais os melhores ramos para cada informaçăo. Estas tentativas geram uma regra, ou melhor, um conjunto de regras que quando aplicado ao nó gera a classificaçăo. Para os programadores procedurais é como implementar diversos IF-ELSE-THEN para que a classificaçăo seja feita.
Existem diversos algoritmos conhecidos, que fazem a implementaçăo de uma árvore de decisăo. Năo existe uma forma precisa para determinarmos qual o melhor algoritmo. O desempenho deles pode variar de acordo com o volume de dados e com a situaçăo em que estăo sendo usados.
Um dos primeiros algoritmos desenvolvidos foi o ID3. Seu conceito de criaçăo usou a idéia dos sistemas de inferęncia e dos conceitos de aprendizado de máquina. Em pouco tempo outros algoritmos também surgiram: C4.5, CART (Classification and Regression Trees), CHAID (Chi Square Automatic Interaction Detection) e outros mais.
Até aqui tudo bem, mas vamos dar uma olhada na prática como fazer uma árvore de decisăo. Pra isso vou usar o ambiente de Data Mining da Oracle (Banco e GUI).
Os dados que vamos usar foram utilizados como exemplo em um artigo da Oracle Magazine algum tempo atrás e eu guardei comigo, năo me recordo de qual ediçăo.
SQL> desc customer_satisfaction
Nome Nulo? Tipo
--------------------------------- --------------- --------------
CUSTOMER_SATISFACTION_ID NOT NULL NUMBER(10)
PRODUCT VARCHAR2(100)
VERSION NUMBER(2)
LAST_UPGRADE_YEAR VARCHAR2(4)
FEEDBACK VARCHAR2(10)
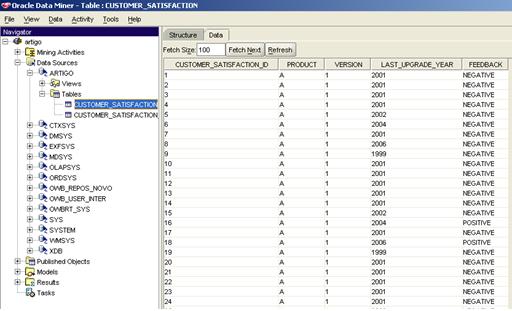
Figura 2 – Tela de Dados da Tabela Customer Satisfaction
Para criarmos a nossa árvore de decisăo vamos até o menu Activity e selecionamos a opçăo Build. A tela de wizard para selecionarmos o que iremos fazer será mostrada:
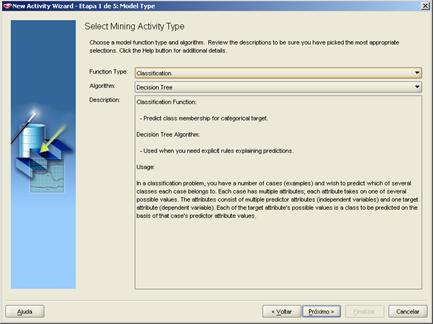
Figura 3 – Tela de Wizard
Na próxima tela nós selecionamos quais os dados que iremos classificar.
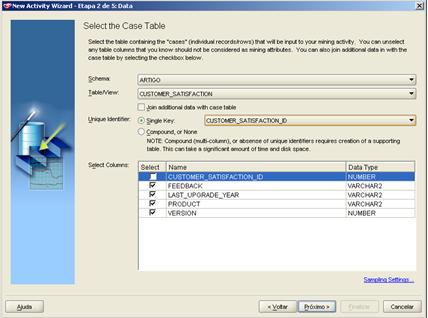
Figura 4 – Seleçăo de Dados
Nós vamos entăo selecionar todos os campos, menos o customer_satisfaction_id; ele será a nossa chave primária seqüencial, entăo o seu conteúdo é irrelevante para a análise.
Agora precisamos selecionar qual atributo servirá como a variável resposta e quais as variáveis independentes. Neste caso, vamos classificar os dados de acordo com a variável feedback, ela será nossa variável de resposta, enquanto todas as outras servirăo como variáveis independentes.
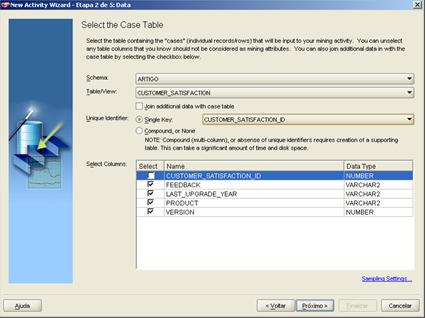
Figura 5 – Seleçăo de Variáveis
Pronto. Mais um click e criamos um processo que irá gerar a nossa árvore. Vejam abaixo:
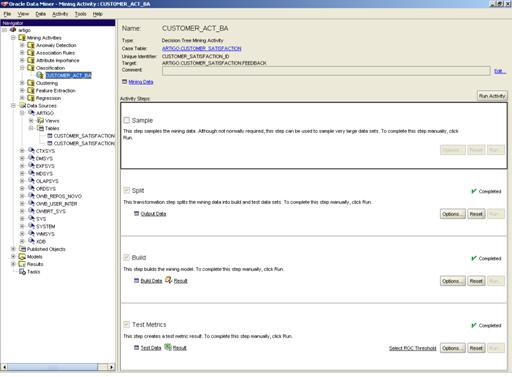
Figura 6 – Processo de criaçăo da árvore.
No item Build da tala de processos existe um ícone chamado Result. Clicando nele podemos ver o resultado da árvore.
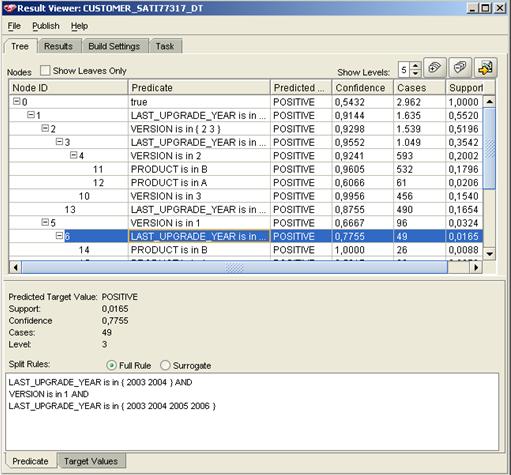
Figura 7 – Resultado da Árvore
Na figura acima podemos ver os nós criados pela árvore e ao clicar sobre cada nó, vemos quais regras criadas, fazendo com que os registros da tabela que atenderem a esta regra sejam ali agrupados.
Construir esta árvore foi extremamente simples, o que acaba mostrando que năo é necessário ser nenhum super matemático para entender ou criar uma árvore para analisar sua massa de dados. É claro que dadas ŕs proporçőes da análise que se pretende fazer a complexidade para a construçăo irá aumentar um pouco, mas mesmo assim é de fácil compreensăo.
Bom, pessoal, é isso! Espero que vocęs tenham aproveitado esta coluna e até a próxima.
Um forte abraço a todos.
Vander Emiro Muniz
www.triscal.com.br







