No desenvolvimento de aplicaçőes, seja para web, desktop ou dispositivos móveis, além de todos os requisitos funcionais, a equipe de desenvolvimento precisa se preocupar também com requisitos năo funcionais, como segurança, desempenho e escalabilidade, itens esses que constituem o alicerce da aplicaçăo e que, na maioria dos casos, precisam ser levados em consideraçăo desde o início, sob a pena de ser necessário reconstruir toda a aplicaçăo.
Guia do artigo:
- Frameworks
- Arquitetura
- Proposta
- Back-end
- Modelo
- Repositórios
- Serviços
- Controladores
- Configuraçőes
- Segurança
- Front-End
- Autenticaçăo
- Implantaçăo
- Front-end no S3
- Banco de dados
- JVM
No entanto, a modelagem de uma arquitetura robusta, escalável, que permita ŕ equipe alta produtividade, desenvolvimento ágil e que faça uso de recursos de infraestrutura da nuvem em seu favor demanda tempo e tem impacto no orçamento do projeto. Esses itens (tempo e orçamento) nem sempre estăo disponíveis, principalmente para quem está desenvolvendo uma aplicaçăo como hobby e para pequenas startups. Por outro lado, o tempo e o dinheiro investidos nessa etapa reduzem o prazo e simplificam o desenvolvimento e a manutençăo. Além disso, criar uma estrutura a partir do zero ou com pouquíssimo material prévio para cada novo projeto é moroso e improdutivo.
Uma das primeiras e mais difíceis tarefas quando se está iniciando um novo projeto é a escolha das tecnologias que serăo utilizadas. Isso porque, com raras exceçőes, essas decisőes acompanharăo o projeto por toda a sua vida e mudar a tecnologia utilizada normalmente sai caro. E quando o assunto săo as tecnologias que servirăo de base para o projeto, isso inclui linguagens, plataformas utilizadas, servidor de aplicaçőes, o modo de armazenamento dos dados, entre outros itens funcionais e năo funcionais que merecem atençăo.
Felizmente, é possível que uma mesma implementaçăo de arquitetura sirva como referęncia para outras aplicaçőes ou mesmo que seja reutilizada integralmente pela maioria das aplicaçőes web. E é isso que este artigo irá mostrar: uma proposta de arquitetura que pode ser utilizada no modelo mais comum de desenvolvimento web, que se apoia em frameworks e ferramentas consolidadas e que está pronta para ser implantada na nuvem. A intençăo aqui năo é apresentar a “arquitetura definitiva para aplicaçőes web”, mas sim um conjunto de soluçőes de problemas comuns a esse tipo de desenvolvimento, além de fornecer conhecimento para que os desenvolvedores possam adaptar as ideias ŕs suas necessidades e aos requisitos dos seus projetos.
Frameworks
Frameworks săo conjuntos de abstraçőes de códigos e estruturas genéricas que devem servir como suporte para uma complementaçăo que possa criar funcionalidades específicas. Os frameworks săo responsáveis por comandar o fluxo de execuçăo das aplicaçőes ou atividades. Năo os confunda com bibliotecas, que săo códigos completos que năo ditam o fluxo da aplicaçăo e năo precisam de complementaçăo para funcionar. Neste artigo serăo utilizados dois frameworks de grande penetraçăo no mercado, vasta documentaçăo e amplo suporte da comunidade: AngularJS e Spring.
O desenvolvimento para web por muito tempo esbarrou em problemas de compatibilidade entre navegadores, quando utilizar JavaScript muitas vezes trazia mais problemas que soluçőes. No entanto, isso mudou bastante com o surgimento de bibliotecas como o jQuery e frameworks como o Dojo. Foi nessa onda que surgiu o AngularJS, framework JavaScript mantido principalmente pelo Google e usado para o desenvolvimento de aplicaçőes web ricas, seguindo a arquitetura MVW (Model-View-Whatever). Os padrőes arquiteturais normalmente utilizados nas aplicaçőes front-end săo MVC (Model-View-Controller), MVP (Model-View-Presenter) e MVVM (Model-View-ViewModel). Como o AngularJS funciona bem com todos eles, a equipe cunhou o termo MVW, que significa algo como Model-View-e o que funcionar no seu projeto.
Em resumo, o AngularJS estende as funcionalidades do HTML para simplificar e agilizar o desenvolvimento no lado cliente, permitindo a rápida criaçăo de aplicaçőes com excelente usabilidade, além de abstrair e facilitar o uso de recursos importantes, como chamadas a APIs REST e controle do fluxo de páginas.
Do lado servidor, a grande preocupaçăo da maioria dos frameworks sempre foi fornecer ao desenvolvedor toda a infraestrutura possível para que ele pudesse manter o foco na codificaçăo de funcionalidades importantes para o negócio e simplesmente utilizar recursos como segurança e controle transacional. Esse foi, desde o início, o grande apelo dos EJBs, mas a infraestrutura de servidor de aplicaçőes e o ambiente pesado os mantiveram no mundo das grandes aplicaçőes corporativas. O Spring Framework traz todos esses recursos em um ambiente muito mais leve, simples e acessível, permitindo que possa ser utilizado em praticamente qualquer aplicaçăo.
Arquitetura
A arquitetura de um sistema computacional ou de uma aplicaçăo diz respeito aos elementos que servem de base para a sua construçăo e como esses interagem entre si para satisfazer as necessidades de funcionamento, desempenho, segurança e usabilidade. É o tópico que trata das decisőes de design que guiarăo o desenvolvimento e o andamento do projeto.
Entre os requisitos năo funcionais que devem ser observados pela arquitetura estăo a reusabilidade e a escalabilidade. A primeira existe somente em tempo de desenvolvimento e trata da capacidade dos componentes de serem reutilizados (sejam métodos, classes ou serviços). Esse item impacta diretamente o desenvolvimento e a manutençăo uma vez que, quanto maior a reusabilidade, menor a quantidade de código a ser escrito e mantido e mais simples será a aplicaçăo. Já a escalabilidade só faz sentido em tempo de execuçăo e refere-se ŕ capacidade do sistema ou aplicaçăo de suportar o crescimento de trabalho de maneira uniforme, preferencialmente com o menor esforço possível.
O que será mostrado aqui é uma forma de utilizar esses conceitos na prática, com técnicas e padrőes de projeto dos quais a equipe poderá se beneficiar, de acordo com os requisitos e necessidades do projeto.
Proposta
A proposta de arquitetura apresentada neste artigo está dividida em duas partes, bastante conhecidas pelos desenvolvedores: front-end e back-end. O front-end é a camada que interage com o usuário e, assim sendo, é nela onde săo aplicados os conceitos de usabilidade e estética para que a aplicaçăo seja bonita e simples. O back-end, por sua vez, é a camada responsável por executar as funcionalidades associadas ao negócio da aplicaçăo e, dessa forma, é nela que săo implementadas as regras de validaçăo e execuçăo, a persistęncia dos dados e as integraçőes com outros sistemas.
A ideia é que as duas camadas sejam desacopladas fisicamente, como se fossem duas aplicaçőes implantadas em estruturas diferentes e utilizando recursos diferentes. A aplicaçăo AngularJS é o cliente, e comporta as páginas HTML, os arquivos JavaScript, as imagens e outros recursos, que serăo providos por um servidor de arquivos comum, como o Apache, NGiNX ou outro que esteja disponível. Esses normalmente săo mais rápidos e estáveis que os servidores de aplicaçőes para a execuçăo desse tipo de tarefa, onde os arquivos năo sofrem modificaçőes no seu conteúdo.
Já a aplicaçăo back-end será implementada em Spring, tendo como base o projeto Spring Boot, que simplifica bastante o desenvolvimento, encapsula o uso de um servidor de aplicaçőes e fornece uma API REST para que a aplicaçăo cliente possa executar suas tarefas. Ao contrário das aplicaçőes que utilizam páginas dinâmicas, como JSP e JSF, os serviços REST năo precisam fazer a geraçăo de páginas, o que os tornam significativamente mais leves, exigindo menos recursos do servidor e possibilitando um desenvolvimento mais simples e produtivo.
Os serviços back-end serăo fornecidos somente como stateless (veja o BOX1), o que significa que năo precisarăo ser criados e destruídos para cada cliente ou sessăo, reduzindo o processamento e a quantidade de memória necessária no back-end. Além disso, por năo terem necessidade de afinidade com o usuário da requisiçăo, isto é, de uma instância do serviço năo ser dedicada a um único cliente, a tarefa de balanceamento da carga de trabalho se torna muito mais simples.
Para garantir a segurança da aplicaçăo, a autenticaçăo será feita por meio de um token de segurança. Basicamente, na primeira requisiçăo, a aplicaçăo cliente solicita um token, informando um nome de usuário e uma senha. Se os dados estiverem corretos, o back-end fornece um token, que estará associado ao usuário e deverá ser informado em cada requisiçăo. Enquanto o token for válido, a aplicaçăo cliente terá autorizaçăo para executar.
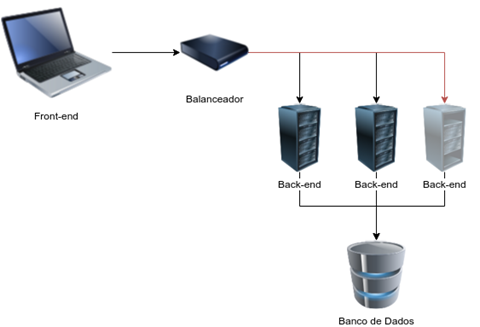
A Figura 1 mostra como poderá ser implantada a aplicaçăo, incluindo, além do front-end e do back-end, elementos de infraestrutura, como balanceadores de carga e banco de dados.
Um balanceador de carga de trabalho (workloader) é o componente responsável por distribuir, de acordo com critérios estabelecidos, a execuçăo do trabalho requisitado entre os recursos disponíveis. Assim, um balanceador pode, por exemplo, entregar uma requisiçăo para cada servidor existente, em um sistema de rodízio.
BOX 1. Serviço stateless
Um serviço stateless é aquele que, como o nome sugere, năo tem estado, isto é, tudo que é necessário para sua execuçăo está nos dados da requisiçăo e năo é preciso que um outro serviço seja executado antes ou depois dele para que a sua tarefa se complete.
Back-end
Normalmente, ao desenvolver uma aplicaçăo web, assim como para a implantaçăo de aplicaçőes em ambientes de produçăo, é preciso configurar um servidor de aplicaçőes (Tomcat ou Jetty, por exemplo) e implantar o pacote WAR nesse servidor. Na proposta de arquitetura deste artigo, será mostrado o uso do Spring Boot, soluçăo que facilita a criaçăo de aplicaçőes web standalone de forma realmente muito simples, sem a necessidade de utilizaçăo explícita de um servidor de aplicaçőes (o framework cuida disso), sem arquivos de configuraçăo, sem geraçăo de código e sem a necessidade de deploy.
A criaçăo de um novo projeto é sempre uma tarefa chata e repetitiva, quando o desenvolvedor precisa criar estruturas de pastas e pacotes, arquivos de build e outros recursos, normalmente muito parecidos. Uma excelente ferramenta para começar um novo projeto é o Spring Initializr (veja a seçăo Links), uma aplicaçăo web do projeto Spring que realiza esse trabalho repetitivo rapidamente e com um número mínimo de parâmetros. Ao acessar o Initializr é possível selecionar as preferęncias do projeto, como o gerenciador de dependęncias, a versăo do framework Spring, os demais módulos que se deseja incluir, como segurança e persistęncia, e, por fim, ao clicar no botăo Generate Project, gerar um esqueleto do projeto com um pom.xml (vide Listagem 1) e uma classe de inicializaçăo da aplicaçăo (vide Listagem 2) com um método main().
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>demo</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
Além do que é criado por padrăo, serăo necessárias mais algumas dependęncias para as funcionalidades desejadas, como a capacidade de conversar no protocolo REST, utilizaçăo do formato JSON e acesso a bancos de dados. Isso pode ser feito de duas formas: selecionando as dependęncias desejadas no próprio Initializr, ou adicionando essas dependęncias manualmente no pom.xml, como na Listagem 3. A vantagem da primeira opçăo é que năo é necessário conhecer o groupId ou o artifactId do Maven específicos para o módulo desejado, sendo possível fazę-lo somente com o seu nome. A escolha de qual opçăo utilizar fica a cargo do desenvolvedor.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.9.10</version>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
</dependency>
Uma das preocupaçőes da arquitetura aqui proposta, como visto anteriormente, é a simplicidade e reusabilidade do código, com o objetivo de aumentar a produtividade e melhorar a manutenibilidade. Sendo assim, a aplicaçăo back-end será dividida nas camadas mostradas na Figura 2. A separaçăo de responsabilidades é um conceito de grande importância e, por isso, deve servir de guia para manter a arquitetura da aplicaçăo nos trilhos.
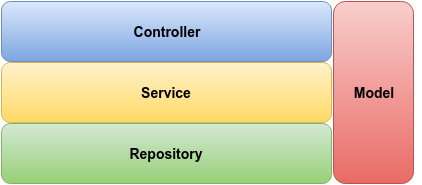
Uma excelente ideia para o projeto é o padrăo chamado Layer SuperType, que orienta a criaçăo de um supertipo para cada camada da aplicaçăo. Segundo Martin Fowler, năo é incomum que todas as classes de uma mesma camada tenham métodos e atributos que se repetem com pouca ou nenhuma variaçăo. Logo, o melhor a fazer é colocar todo esse comportamento comum no supertipo da camada, reduzindo o código escrito e replicado.
Modelo
Na camada de modelo estăo as entidades mapeadas do banco de dados, que servirăo de parâmetro na definiçăo dos supertipos das demais camadas da aplicaçăo. Além dos mapeamentos, é uma boa ideia utilizar os recursos do Hibernate Validator para fazer as validaçőes básicas da entidade — obrigatoriedade, valores mínimos e máximos, tamanho das strings, etc. — colocando anotaçőes na própria classe, pois o seu uso é prático e essas restriçőes estăo intimamente relacionadas ŕ integridade da entidade. A Listagem 4 mostra o supertipo dessa camada.
package com.exemplo.demo.modelo;
@MappedSuperclass
public abstract class BaseModelo implements Serializable {
private static final long serialVersionUID = 1L;
}
Inicialmente, essa classe năo tem nenhum código que será herdado pelas outras classes, mas atributos comuns e seus mapeamentos podem ser adicionados. Algumas aplicaçőes podem ter um ID incremental, a data e hora de inserçăo e da última atualizaçăo em todas as entidades, por exemplo. Por ser uma classe abstrata, ela precisa ser anotada com @MappedSuperclass para indicar que năo deve ser interpretada como uma entidade concreta e, desse modo, que deverá ser estendida por todas as demais entidades, garantindo o mesmo tipo e comportamento, quando necessário, a todas elas.
Repositórios
Agora que a superclasse que servirá como parâmetro ŕs demais camadas está pronta, pode-se definir a próxima camada na pilha da aplicaçăo: a camada de acesso aos dados, que como o nome indica, é responsável por recuperar, incluir e alterar os dados.
Certamente, muito do código escrito nessa camada para executar as tarefas mais comuns é repetitivo e pode ser parametrizado. No entanto, o Spring é capaz de fazer melhor e reduzir drasticamente a quantidade de código escrito, sendo necessário somente definir a interface do repositório. A partir disso, fica a cargo framework, em tempo de execuçăo, gerar a implementaçăo.
package com.example.demo.repositorios;
@NoRepositoryBean
public interface BaseRepositorio<T extends BaseModelo> extends PagingAndSortingRepository<T, Long> {
}
Para que essa “mágica” aconteça, é claro que algumas regras devem ser seguidas para informar ao Spring qual código deve ser gerado, começando pela hierarquia da interface. Embora năo seja obrigatório, é uma boa ideia estender interfaces do framework para herdar suas definiçőes, reduzindo o código e mantendo um padrăo de contrato, mesmo em projetos diferentes. Por isso, o supertipo dessa camada, mostrado na Listagem 5, estende PagingAndSortingRepository, que define métodos de listagem com suporte ŕ paginaçăo e ordenaçăo, e também os métodos para salvar, obter e excluir, que podem ser vistos em mais detalhes na Listagem 6. Além disso, o supertipo também é parametrizado com uma entidade que estende de BaseModelo, permitindo que somente as classes que pertencem a essa hierarquia possam ter seus próprios repositórios.
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
<S extends T> S save(S entity);
<S extends T> Iterable<S> save(Iterable<S> entities);
T findOne(ID id);
boolean exists(ID id);
Iterable<T> findAll();
Iterable<T> findAll(Iterable<ID> ids);
long count();
void delete(ID id);
void delete(T entity);
void delete(Iterable<? extends T> entities);
void deleteAll();
Serviços
A próxima camada apresentada é a de serviços. Responsável pela lógica de negócio da aplicaçăo, é nela que estarăo as regras de validaçăo mais complexas, como quais as condiçőes pré-existentes para que os dados sejam persistidos e a interaçăo entre entidades, além de orquestrar diferentes serviços para a execuçăo de uma tarefa. Em uma aplicaçăo de venda de passagens, por exemplo, o serviço responsável pela reserva deverá orquestrar os serviços necessários para verificaçăo da disponibilidade de voo, reserva de acentos e pagamentos. Por ser a detentora das regras de negócio e coordenar a interaçăo entre outros serviços, essa classe também é a responsável por interagir com o repositório para acessar ou persistir os dados.
Na superclasse da camada de serviços (veja a Listagem 7) estarăo os métodos comuns, públicos e protegidos a todos os serviços da aplicaçăo. Esses devem ser implementados de forma genérica, deixando para as classes concretas fornecer o código específico de cada caso. Por exemplo, o método save pode invocar um método protected que faz a validaçăo dos dados antes de persisti-los. Nesse caso, a implementaçăo padrăo pode năo fazer validaçăo alguma, deixando essa tarefa a critério das subclasses. As classes concretas, por sua vez, além de complementar o código do supertipo, precisam ser anotadas com @Service e @Transactional. A primeira anotaçăo serve para identificá-la como um service para o framework e a segunda, para indicar que existe controle transacional nesse componente. Isso é necessário porque essas classes realizarăo tarefas de alteraçăo no banco de dados.
package com.example.demo.services;
public abstract class BaseServicos<T extends BaseModelo> {
public void delete(Long id) { ... }
@Transactional(propagation=Propagation.NOT_SUPPORTED)
public T get(Long id) { ... }
@Transactional(propagation=Propagation.NOT_SUPPORTED)
public Page<T> list(Integer page) { ... }
public T save(T object) { ... }
}
Nos métodos que realizam consulta ao banco de dados sem realizar qualquer alteraçăo é uma boa ideia utilizar a anotaçăo @Transactional(propagation=Propagation.NOT_SUPPORTED). Isso indica ao framework que năo precisa haver controle transacional para essa operaçăo, economizando recursos tanto no servidor de aplicaçőes quanto no banco de dados.
Controladores
A camada de controle deve ser responsável por receber as requisiçőes da aplicaçăo cliente, realizar transformaçőes e repassar as requisiçőes ŕ camada de serviços. Assim como ocorre com outros componentes, criar controllers no Spring é fácil e pode ser feito anotando a classe com @RestController, o que sinaliza que esse controle conversa com as aplicaçőes clientes por meio do protocolo REST. Nesse caso, năo é necessária nenhuma anotaçăo ou configuraçăo adicional para informar ao Spring que tanto o response quanto o request devem utilizar o formato JSON. Assim como nas outras camadas, deve haver uma superclasse para essa também (vide Listagem 8).
package com.example.demo.controladores;
public abstract class BaseControlador<T extends BaseModelo> {
@RequestMapping(value = "/{id}", method = RequestMethod.DELETE)
public void delete(@PathVariable Long id, HttpServletRequest request, HttpServletResponse response) { ... }
@RequestMapping(value = "/{id}", method = RequestMethod.GET)
public T get(@PathVariable("id") Long id, HttpServletRequest request, HttpServletResponse response) { ... }
@RequestMapping(value = "", method = RequestMethod.GET)
public Page<T> list(@RequestParam(value = "p", required = false, defaultValue = "0") Integer page, HttpServletRequest request, HttpServletResponse response) { ... }
@RequestMapping(value = "", method = RequestMethod.POST)
public T save(@Validated @RequestBody T object, HttpServletRequest request, HttpServletResponse response) { ... }
}
Como nos demais casos de superclasses de camada, essa é uma classe abstrata e por isso năo possui a anotaçăo de implementaçăo (@RestController neste caso) que deve ser colocada nas classes concretas. A anotaçăo @RequestMapping, por sua vez, define a URI de acesso ao controller e deve ser declarada tanto na classe concreta, para especificar o recurso manipulado por ela, quanto nos métodos, para especificar em quais condiçőes cada método será acionado.
Seguindo as convençőes de nomenclatura de recursos para APIs REST, a URI de cada controller deve ser o nome do recurso por ele manipulado, no plural. Logo, tomando o exemplo de uma aplicaçăo de venda de passagens, a URI do controller que manipula a entidade Reserva seria /reservas. Ainda de acordo com a convençăo REST, os verbos HTTP devem ser utilizados para definir as operaçőes realizadas em um determinado recurso, sendo o método GET para recuperar e os métodos POST e/ou PUT para gravar. Assim, se a URI /reservas for usada com o método GET, o controller deve retornar a lista de reservas, mas se o método utilizado for POST, o controller irá salvar o objeto JSON recebido. Da mesma forma, se a URI /reservas/1234 for utilizada com o método GET, o controller retornará essa reserva no formato JSON, se for utilizado o POST, os dados da reserva serăo atualizados, e ser for DELETE, a reserva será excluída.
Configuraçőes
Agora que todas as camadas do back-end estăo criadas, é necessário configurar a aplicaçăo para que os componentes sejam carregados pelo Spring. Nas versőes anteriores do framework, essa tarefa era feita em arquivos XML nos lugares mais diversos e com uma sintaxe complicada. Por outro lado, as versőes mais atuais dăo suporte ŕ configuraçăo por meio de anotaçőes, como acontece nos componentes. Essa abordagem facilita o desenvolvimento e a manutençăo da aplicaçăo, já que tudo está no mesmo lugar. Porém, alterar essa configuraçăo em tempo de execuçăo năo é possível, pois o código precisa ser recompilado e reimplantado.
Para informar ao Spring onde estăo os componentes, deve ser utilizada a anotaçăo @ComponentScan na classe de entrada da aplicaçăo. Essa anotaçăo tem o parâmetro basePackages, que deve ser preenchido com a lista de pacotes, separados por vírgula, que serăo varridos ŕ procura dos componentes devidamente anotados com @Service, @RestController e @Component. Nesse caso, o trecho que será adicionado ŕ classe deve ser o seguinte:
@ComponentScan(basePackages = "com.example.demo.controladores,com.example.demo.servicos")Embora permita o uso de anotaçőes, algumas das configuraçőes do comportamento do framework só podem ser feitas por meio de properties, e para isso o Spring conta com um engenhoso recurso. Se houver um arquivo chamado application.properties no classpath da aplicaçăo, esse arquivo será lido e suas propriedades serăo carregadas. Acontece que é bastante comum que se utilize um valor no ambiente de desenvolvimento e outro no ambiente de produçăo, e isso pode causar problemas. O desenvolvedor acaba esquecendo de alterar as configuraçőes e o arquivo de desenvolvimento passa a ser utilizado em produçăo ou o inverso. Por isso, o mecanismo de configuraçőes tem o conceito de perfil, parecido com o do Maven.
Assim como no arquivo pom.xml, no arquivo de properties é possível definir qual o perfil padrăo utilizado em tempo de execuçăo. Isso é feito por meio da propriedade spring.profiles.active. Caso ela tenha um valor, o framework irá carregar as propriedades do arquivo application-<perfil>.properties, se ele existir, e sobrepor os seus valores no arquivo original. Assim, se a propriedade spring.profiles.active tiver o valor dev, por exemplo, e existir um arquivo chamado application-dev.properties, esse será carregado e seus valores irăo sobrepor os valores do arquivo application.properties.
O Spring possui um grande número de propriedades para configurar os mais diversos comportamentos da aplicaçăo, como a porta usada para acesso HTTP. Uma propriedade que merece ser mencionada aqui é a security.sessions=NEVER. Com ela, nenhuma sessăo será criada no lado servidor, o que economiza recursos e simplifica a escalabilidade da aplicaçăo.
Deve-se evitar o armazenamento de dados relativos ao cliente na sessăo do servidor de aplicaçőes. Essa prática, além de onerar o servidor, complica o escalonamento da aplicaçăo, uma vez que exige o compartilhamento de sessőes. Uma boa alternativa é utilizar um banco de dados NoSQL, do tipo document base ou key-value, de preferęncia em memória.
Como uma das premissas da arquitetura proposta é que a aplicaçăo front-end e a back-end fiquem fisicamente em servidores diferentes, é possível que, dependendo do local de hospedadagem, o acesso a esses servidores, ou conjunto de servidores, se dę por meio de domínios diferentes. Isso leva a um problema comum, conhecido por CORS (Cross-Origin Resource Sharing). Para habilitar esse recurso na aplicaçăo, deve-se definir, no arquivo application.properties, as propriedades com prefixo endpoints.cors de acordo com as necessidades.
O mecanismo de CORS permite restringir o acesso a APIs entre sites de domínios diferentes. Isso se dá porque os navegadores modernos impedem que uma chamada via AJAX seja feita para um servidor em um domínio que năo seja o do site acessado, a menos que o servidor explicite a autorizaçăo por meio de um cabeçalho HTTP.
Segurança
Com a aplicaçăo do lado servidor estruturada, é preciso pensar na segurança. Nesse caso, a aplicaçăo utilizará um mecanismo de autenticaçăo OAuth2 baseado em token para as chamadas ŕ API REST.
Nesse modelo, o fluxo de autenticaçăo funciona da seguinte forma: a aplicaçăo cliente envia as credenciais do usuário, normalmente login e senha, para o servidor. O servidor valida essas credenciais e, em caso positivo, retorna ŕ aplicaçăo cliente um token. A partir daí, a cada requisiçăo enviada pelo cliente, o token deve ser enviado junto, no cabeçalho HTTP, para ser validado no servidor.
Para que isso tudo funcione corretamente, deve-se configurar o módulo de segurança no Spring. Isso pode ser feito adicionando a dependęncia do módulo ŕs configuraçőes do Maven ao criar o esqueleto do projeto no Initializr, selecionando Security na lista de dependęncias, ou adicionando manualmente o trecho de código da Listagem 9 ao arquivo pom.xml.
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-core</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.security.oauth</groupId>
<artifactId>spring-security-oauth2</artifactId>
</dependency>
Agora é hora de utilizar os recursos de configuraçăo programática para definir como a segurança irá funcionar. Em uma nova classe, que aqui será chamada de OAuth2ServerConfiguration, especificaremos as configuraçőes necessárias. A classe deve ficar no pacote com.example.demo.security e ser anotada com @Configuration. No entanto, para que ela seja corretamente lida pelo Spring, é preciso adicionar esse pacote ŕ lista de pacotes na anotaçăo @ComponentScan da classe de entrada.
Uma boa maneira de organizar as configuraçőes é adicionar duas classes estáticas ŕ OAuth2ServerConfiguration: uma para a configuraçăo da autorizaçăo, onde săo definidos os recursos protegidos da aplicaçăo; e outra para configurar o gerenciamento dos tokens de autenticaçăo.
Na Listagem 10 está um exemplo de como a configuraçăo pode ser feita. Na documentaçăo do framework pode-se verificar os detalhes e configuraçőes que satisfazem ŕs necessidades de cada projeto. É possível, por exemplo, definir um serviço responsável por recuperar as informaçőes do usuário a partir das credenciais, caso o projeto precise de um modelo mais elaborado para representar o usuário autenticado.
package com.example.demo.security;
@Configuration
public class OAuth2ServerConfiguration {
@Configuration
@EnableResourceServer
protected static class ResourceServerConfiguration extends ResourceServerConfigurerAdapter { ... }
@Configuration
@EnableAuthorizationServer
protected static class AuthorizationServerConfiguration extends AuthorizationServerConfigurerAdapter {
@Override
public void configure(AuthorizationServerEndpointsConfigurer endpoints) throws Exception { ... }
}
}
Quando um usuário é autenticado com sucesso e um token é gerado, esse token deve ser armazenado em algum lugar para poder ser validado depois. É no método configure() da classe AuthorizationServerConfigurerAdapter que esse lugar é informado. Para isso, configure() recebe como argumento um objeto do tipo AuthorizationServerEndpointsConfigurer, que pode ser utilizado para alterar diversas configuraçőes de autenticaçăo, entre elas o tokenStore, que é o mecanismo de armazenamento de tokens.
O framework oferece, por padrăo, dois tipos de armazenamento de tokens: em memória ou em um banco de dados por meio de acesso JDBC. Obviamente o primeiro é mais rápido e deve ser utilizado em ambiente de desenvolvimento. O segundo, por sua vez, pode ser adotado em ambiente de produçăo, pois permite que vários servidores compartilhem os mesmos tokens de forma bastante simples. Uma boa opçăo para esse armazenamento é utilizar um banco de dados em memória, como o H2.
Front-End
Há vários anos, no início do desenvolvimento das aplicaçőes web, o JavaScript era usado somente para realizar algumas validaçőes no lado cliente ou executar alguma animaçăo. Na maioria das vezes, coisas puramente estéticas, sem impacto real no funcionamento da aplicaçăo. Isso porque, além de ter um desempenho ruim, as diferenças entre navegadores tornavam as coisas bastante complexas para fazer algo importante, uma vez que era de responsabilidade do desenvolvedor resolver essas diferenças.
Com o aumento do poder de processamento nos computadores pessoais e a guerra dos navegadores, os fabricantes passaram a investir mais nos mecanismos de execuçăo de JavaScript, melhorando o seu desempenho e seguindo um caminho para a reduçăo das diferenças entre eles. A linguagem passou entăo a ganhar mais importância e relevância e começaram a surgir bibliotecas e frameworks que aproveitam melhor suas capacidades.
Entre eles, surgiu o AngularJS, que é um framework que segue um novo paradigma de aplicaçőes web, chamado SPA (Single Page Application), oferecendo suporte a interfaces de usuário ricas, sem recarregar a página inteira e preocupadas com a beleza e a usabilidade. As funcionalidades e a modularizaçăo do framework o tornam uma excelente opçăo para esse tipo de aplicaçăo, entregando ao desenvolvedor facilidade de uso e alta produtividade.
Embora năo costume ter uma interface web como o Spring Initializr, o AngularJS possui várias ferramentas para criar o esqueleto de um novo projeto, como o Angular Seed, que năo é mantido pela equipe do AngularJS, e o Yeoman, que também pode ser usado para outros tipos de projetos, como Node.js. Essas opçőes săo simples de usar e năo deve haver dificuldades para o desenvolvedor. Por isso, nenhuma delas será abordada neste artigo.
Como explicado anteriormente, o AngularJS é um framework MVW, o que significa que ele funciona bem com qualquer padrăo de projeto MVC, MVP ou MVVM. Assim sendo, aqui será adotado o padrăo MVC.
Ao iniciar uma aplicaçăo construída sobre o AngularJS, a página HTML inicial é carregada, assim como o seu script. Esse script contém, entre outras coisas, a definiçăo de states (ou rotas, dependendo de qual recurso for utilizado), que sinaliza qual view deve ser carregada de acordo com a situaçăo (state) da aplicaçăo. Desse modo, pode haver, por exemplo, um state chamado home e outro chamado about, de forma que a navegaçăo entre as páginas se dá por meio das mudanças de state.
Do mesmo modo que ocorre no back-end, a lógica de execuçăo deve ser implementada nos controllers, uma vez que esses componentes săo os responsáveis por alterar estados e controlar o uso da interface do usuário. Assim como há, normalmente, uma classe RestController para cada recurso no back-end, um bom nível de granularidade para essa camada, pelo menos inicialmente, é que haja um controller para cada view. Ŕ medida que os componentes săo reutilizados, é possível perceber que alguns dos controladores podem ser divididos para melhorar a coesăo e aumentar o reuso.
Ainda que seja comum executar chamadas ŕs APIs REST nos controladores, vę-se como uma boa prática encapsular essas chamadas em services. Para facilitar isso, o framework oferece uma boa abstraçăo para a execuçăo de chamadas remotas via AJAX, semelhante ao jQuery, o que facilita bastante a vida do desenvolvedor. Ao colocar as chamadas ŕs APIs em serviços, obviamente um para cada resource, torna-se possível que um determinado controller reutilize diferentes serviços na mesma tela, por exemplo.
Além disso, o framework ainda coloca ŕ disposiçăo uma série de funcionalidades que ajudam significativamente no desenvolvimento, livrando o programador da preocupaçăo com as minúcias de baixo nível da linguagem JavaScript.
Autenticaçăo
Da mesma forma que foi necessário incluir um mecanismo para garantir a segurança no back-end, é importante que algo parecido seja feito no front-end também. Contudo, desta vez, isso năo implica exatamente em uma questăo de segurança, mas sim de usabilidade, dependendo do funcionamento da aplicaçăo. Isso porque, como o back-end irá verificar a autenticaçăo da aplicaçăo cliente, as requisiçőes serăo negadas caso o front-end năo verifique. Sendo assim, para evitar que erros de autenticaçăo apareçam para o usuário que ainda năo efetuou login ou que teve a sessăo expirada, é importante que o mecanismo esteja sincronizado.
Para isso, será criado um serviço de autenticaçăo na aplicaçăo cliente. A ideia é que ele seja responsável por tudo relacionado ŕ aplicaçăo, como verificar se a autenticaçăo foi realizada e se está válida, realizar a atualizaçăo do token se necessário, recuperar os dados do usuário logado e, é claro, realizar login e logout.
Uma vez que o serviço de autenticaçăo esteja criado, deve ser adicionado um event listener ao mecanismo de manutençăo do estado da aplicaçăo, o $stateProvider. Ao receber a notificaçăo de stateChangeStart, ou seja, de que a aplicaçăo está iniciando a mudança para um novo estado, o listener solicita ao serviço de autenticaçăo que verifique se há um usuário autenticado. Em caso negativo, o usuário é redirecionado para a página de login.
Lembre-se que o serviço de autenticaçăo deve utilizar algum recurso de persistęncia para armazenar o token de autenticaçăo, certificando-se que esse seja removido quando o usuário efetuar logout. Isso pode ser feito por meio de cookies. A vantagem de usar cookies ao invés do armazenamento de dados do navegador é que é possível definir um tempo para que esse expire, fazendo com que tenhamos logout automático. As Listagens 11 e 12 mostram como se dá esse fluxo.
$rootScope.$on('$stateChangeStart',
function (event, toState) {
if (!auth.isAuthorized() && toState.isLogin != true) {
$state.go('access.signin');
event.preventDefault();
}
});
Listagem 12. Serviço de autenticaçăo.
function isAuthorized() {
try {
if (header == null) {
setAuthorization(getAuthorization());
}
return header != null;
} catch (error) {
}
}
function setAuthorization(authorization) {
header = "Bearer " + authorization.access_token;
$cookies.put(CONFIG.AUTH, JSON.stringify(authorization), {expires: moment().add(30, 'minutes').toDate()});
}
function getAuthorization() {
var authorization = null;
try {
authorization = JSON.parse($cookies.get(CONFIG.AUTH));
} catch (Exception) {
}
return authorization;
}
Há um bug relacionado a esse fluxo aberto no GitHub do componente ui-router. Para contorná-lo, deve ser utilizado o seguinte código, logo após a configuraçăo dos estados (assumindo que app.home é o estado padrăo da aplicaçăo):
$urlRouterProvider.otherwise(function ($injector, $location) {
var $state = $injector.get("$state");
$state.go("app.home");
});Ao realizar o login, o controller responsável por essa tela deverá utilizar o serviço de autenticaçăo para executar a tarefa. Esse último, por sua vez, autentica o usuário na aplicaçăo back-end, o qual só entăo deverá ser direcionado para a página inicial da aplicaçăo.
Quando o serviço de autenticaçăo é invocado para executar, deverá verificar se já existe um token armazenado em um cookie válido e, caso positivo, somente realizar a validaçăo do token no servidor, ao invés de uma nova autenticaçăo. Isso é feito definindo o parâmetro grant_type da requisiçăo para refresh_token e o parâmetro refresh_token com o token de atualizaçăo, sendo que esse é retornado pelo servidor no momento da autenticaçăo com login e senha.
No caso de năo haver nenhum token disponível, uma nova autenticaçăo deve ser feita, com o nome do usuário e a senha. O serviço de autenticaçăo deve entăo definir os parâmetros grant_type, scope, username e password com os respectivos valores: "password", "read write", nome do usuário e senha do usuário.
Em ambos os casos, além dos parâmetros passados, o serviço deve informar ainda o client_id e o client_secret. Esses valores săo especificados na aplicaçăo back-end, na classe de configuraçăo da segurança. Há ainda o cabeçalho Authorization, que deve ter a string 'Basic ' concatenada com o resultado da funçăo btoa(cliente_id + ':' + client_secret). Essa funçăo transforma a sequęncia com o id do cliente, o caractere “:” e o código secreto do cliente em um hash base64.
Em seguida, os dados de autenticaçăo devem ser enviados, via HTTP POST, para a URI /oauth/token, e o seu resultado, como dito anteriormente, será armazenado em formato JSON em um cookie no navegador. Em casos mais críticos ou se o desenvolvedor é mais preocupado com a segurança, é possível encriptar os dados da autenticaçăo antes de armazená-los no cookie. É claro que isso fará necessária a decriptaçăo dos mesmos quando forem recuperados.
Uma vez autenticado, é importante lembrar que a cada nova requisiçăo para o back-end, o cabeçalho Authorization: Bearer + access_token deve ser enviado para que a autenticaçăo seja validada, do contrário o servidor negará a requisiçăo. Isso pode ser feito configurando o cabeçalho padrăo no $httpProvider para evitar que eventuais esquecimentos se tornem uma dor de cabeça.
Utilize o recurso de definiçăo de constantes do AngularJS para guardar configuraçőes, como o client_id, o client_secret, endereços de servidores remotos ou outros valores que normalmente se repetem no código. Para isso, há o método constant no módulo da aplicaçăo que define uma chave e um valor, que pode ser numérico, string, um array ou um objeto. Assim, quando necessário, basta injetar a constante definida pelo nome. Como exemplo, suponha que foi definida uma constante com o nome CLIENTE. Desse modo, basta que se use a injeçăo de dependęncias do framework com o nome CLIENTE e ela estará disponível.
Implantaçăo
Há vários anos esse era um problema muito chato para quem desenvolve aplicaçőes web baseadas em Java, pois năo havia hospedagem barata e de qualidade. Os provedores de hospedagem de baixo custo, que forneciam estruturas muito pequenas, embora suficientes para muitos tipos de projetos, năo davam suporte a ambientes com servidores de aplicaçőes, porque isso requeria um suporte mais qualificado e mais caro. Esse cenário acabava por inviabilizar e desestimular o desenvolvimento de pequenos projetos e relegava a plataforma Java a ambientes corporativos, que possuíam orçamento para aluguel de servidores dedicados e poderiam configurá-los conforme as necessidades da aplicaçăo.
Com o surgimento e, principalmente, com o crescimento e popularizaçăo da computaçăo em nuvem, a demanda aumentou e o preço ficou cada vez mais acessível, tornando a realizaçăo de pequenos projetos muito menos impeditiva e com custos de uma pequena fraçăo de outrora. Agora, é possível ter uma máquina de pequeno porte, com um processador, 512 megabytes de memória RAM e alguns gigabytes de disco por US$ 5 por męs. Certamente um hardware capaz de executar, sem dificuldades, uma aplicaçăo implementada sobre a arquitetura vista neste artigo.
Um dos maiores e mais conhecidos players de computaçăo na nuvem do mercado é o Amazon Web Services. A empresa fornece uma enorme gama de serviços e infraestrutura no modelo Pay As You Go, ou seja, pague conforme o uso, além de sistemas operacionais, tamanhos de hardware e orçamentos variados. Particularmente, os serviços oferecidos pela Amazon Web Services necessários para a implantaçăo de uma aplicaçăo seguindo a arquitetura proposta săo: S3, EC2 e RDS.
O Amazon S3, ou Amazon Simple Storage Service, provę armazenamento com confiabilidade, segurança, escalabilidade e alto desempenho. É bastante simples de usar, embora tenha recursos mais avançados, como políticas de aposentadoria de dados, e também é muito barato, já que a cobrança é feita pelo volume de dados armazenado. O mais interessante nesse caso é que o S3 permite que os arquivos nele armazenados sejam servidos via HTTP diretamente, sem a necessidade de um outro servidor. Por esse motivo, todo front-end da aplicaçăo deve ser implantado nele.
O EC2, que significa Elastic Compute Cloud, é o tipo de serviço mais comum: um servidor dedicado. Ele permite que o cliente escolha qual sistema operacional e qual versăo irá executar e em minutos é possível ter disponível um novo servidor exclusivo, com uma capacidade que pode variar de um processador e meio gigabyte de memória a até 36 processadores com 244 gigabytes de memória.
O último, Relational Database Service (RDS), é o serviço que provę bancos de dados na nuvem, com um custo acessível, recursos confiáveis, seguro e redimensionável. A Amazon dispőe de seis implementaçőes diferentes de bancos de dados: Amazon Aurora, Oracle, MS SQL Server, PostgreSQL, MySQL e MariaDB.
A melhor notícia é que toda essa estrutura está disponível em um modo de degustaçăo por um período de tempo limitado para novos usuários. Ou seja, é possível implantar a aplicaçăo para testes ou piloto gratuitamente e ela năo será removida ao final do prazo, mas será preciso começar a pagar pelo uso.
Front-end
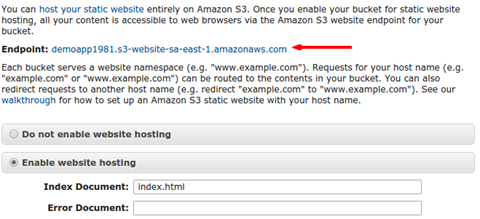
Para implantar o front-end no S3 é preciso criar um novo bucket (que é simplesmente uma forma de organizar os arquivos) informando um nome que o identifique unicamente — demoapp, por exemplo — e uma regiăo (geográfica) na qual os arquivos serăo hospedados. Em seguida, deve-se habilitar o suporte ao Static Web Hosting, que está disponível nas propriedades do bucket e permite que os arquivos sejam acessados diretamente por qualquer pessoa, funcionando como um servidor web comum — veja na Figura 3 a seta indicando o endereço de acesso. Além disso, é necessário informar o arquivo index do bucket a fim de evitar que a lista de arquivos do site seja exibida ao invés da aplicaçăo (veja a Figura 3). Ainda podemos informar uma página de erro 404, que será exibida quando o arquivo solicitado năo existir.
Depois de criado e habilitado o serviço de hospedagem do bucket, basta fazer o upload dos arquivos diretamente para ele. Visto que ele funcionará como o servidor web da aplicaçăo, é importante que as raízes do bucket e da aplicaçăo coincidam ou os arquivos năo serăo localizados corretamente.
Banco de dados
Como o endereço do servidor de banco de dados normalmente é utilizado no back-end, é uma boa ideia configurar o banco de dados antes do back-end. Portanto, ao acessar o painel do RDS, clique em Launch DB Instance e escolha qual sistema gerenciador de bancos de dados será utilizado (é importante prestar atençăo ŕs indicaçőes de quais săo elegíveis para o período de gratuidade).
Feito isso, as configuraçőes, como o tipo de hardware, espaço em disco, nome da instância, usuário e senha, devem ser selecionadas. Logo após, informamos o nome do banco de dados e escolhemos a localizaçăo do servidor, que deverá ser a mesma do servidor back-end. Além disso, é permitido realizar configuraçőes de rede (que só devem ser alteradas se o desenvolvedor souber o que está fazendo) e políticas de backup.
Depois de clicar para que a instância do servidor de banco de dados seja criada, leva alguns minutos até que ela fique disponível. Uma vez pronta, pode-se conectar usando o cliente apropriado para o fornecedor escolhido e executar os scripts de criaçăo e povoamento dos dados iniciais do banco.
Back-end
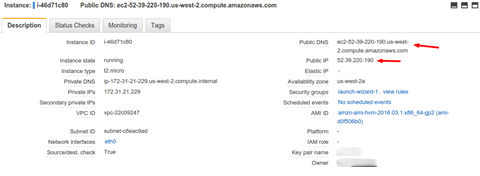
Para executar o back-end da aplicaçăo será necessário um servidor que disponha de uma máquina virtual Java. Sendo assim, no painel de controle do EC2, basta clicar em Launch Instance, escolher a opçăo Amazon Linux e depois o porte do servidor (há uma indicaçăo das máquinas que săo elegíveis para o período de gratuidade). Revisadas as configuraçőes, ao clicar no botăo Launch o servidor será iniciado logo após selecionarmos o par de chaves SSH que será utilizado para acessá-lo. A Figura 4 mostra onde localizar o nome e IP para acesso ao servidor.
A aplicaçăo back-end, construída sobre o framework Spring Boot, agora precisa ser empacotada usando o comando mvn package, o que irá gerar um arquivo JAR no diretório target do projeto. Concluída essa etapa, o JAR deve ser enviado para o servidor, o que pode ser feito via SCP:
scp -i caminho_do_arquivo_chave target/arquivo.jar ec2-user@nome-do-host:/home/ec2-user
ssh -i caminho_do_arquivo_chave ec2-user@nome-do-host
java -jar arquivo.jar &
Pronto! Agora a aplicaçăo está na nuvem.
Há inúmeras outras formas de implementar uma arquitetura que siga os mesmos conceitos, com as mesmas preocupaçőes, ainda que utilizando diferentes tecnologias (ou as mesmas). Esse mesmo conceito pode, por exemplo, ser empregado em aplicativos móveis, com uma abordagem năo nativa com o framework Ionic.
O que é importante é a atençăo aos requisitos, funcionais e năo funcionais, o respeito ŕs diretrizes a serem seguidas no projeto e no desenvolvimento, assim como a aplicaçăo de conceitos simples que facilitam e aceleram o trabalho. Ademais, é preciso ter cuidado para năo cair na armadilha da otimizaçăo precoce, criando soluçőes caras e complexas que talvez nunca sejam necessárias de fato. Ŕs vezes é melhor ter um desempenho 15% pior do que um atraso de 10% no prazo. Lembre-se que a diferença entre o remédio e o veneno é a dose.










