


Na linguagem Java, um mapa (map) é um objeto que associa (ou “mapeia”) chaves com valores. Cada chave é sempre associada a, no máximo, um valor e năo podem existir chaves duplicadas. A Figura 1 mostra um exemplo em que as chaves săo nomes de pessoas e os valores săo os números de telefone das mesmas.
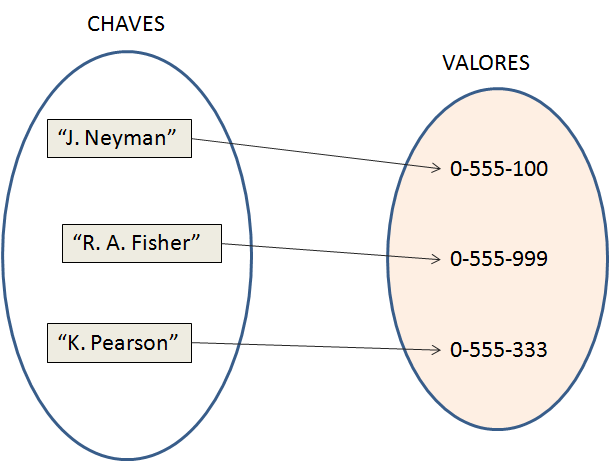
Figura 1: Mapa associando nomes (chave) e telefones (valor)
Existem inúmeras aplicaçőes práticas para os mapas. Este artigo apresenta uma das mais interessantes: usar este tipo de objeto com o objetivo de descobrir as palavras presentes em um determinado arquivo texto e computar as suas frequęncias (número de ocorręncia de cada uma delas).
A Listagem 1 apresenta o programa Java que utiliza um objeto do tipo java.util.HashMap para realizar a contagem de frequęncia de palavras. A explicaçăo sobre o funcionamento do programa é apresentada através de comentários colocados dentro do código e em explicaçőes adicionais apresentadas na parte final deste artigo.
Listagem 1: Classe “ContaPalavras”
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* classe ContaPalavras - recebe como entrada um arquivo texto, identifica as
* diferentes palavras e contabiliza as frequęncias.
*
* uso: java ContaPalavras arquivo_texto
*
* @author Eduardo Correa
*
*/
public class ContaPalavras {
public static void main(String[] args) throws Exception {
//-------------------------------------------------------
// (0) declaraçăo/inicializaçăo de variáveis
//-------------------------------------------------------
String curLine; //recebe cada linha lida do arquivo texto
Map<String,Integer> mapPalavras; //mapa: Palavra -> Frequencia
//usado para contabilizar as
//frequencias das palavras
mapPalavras = new HashMap<String,Integer>();
//-------------------------------------------------------
// (1) abre o arquivo texto
//-------------------------------------------------------
//(1.1) testa se nome do arq. texto foi passado na chamada do programa
if (args.length != 1) {
System.err.println("ERRO: eh preciso especificar o nome do arquivo");
System.err.println("Uso: java ContaPalavras arquivo_texto");
System.exit(1);
}
//(1.2) abre o arquivo
FileReader txtFile = new FileReader(args[0]);
BufferedReader txtBuffer = new BufferedReader(txtFile);
//-------------------------------------------------------
// (2) loop que processa cada linha do arquivo texto
//-------------------------------------------------------
//(2.1) pega a primeira linha do arquivo
curLine = txtBuffer.readLine();
while (curLine != null) {
//-------------------------------------------------------
//(2.2) quebra a linha em tokens (palavras) utilizando
// expressăo regular.
//
// O programa usa uma forma simplificada p/ obter os tokens.
// Săo considerados tokens:
// - uma sequęncia de 1 a n números
// - uma sequęncia de 1 a n letras
//-------------------------------------------------------
//primeiro converte tudo para minúsculo
String minusculo = curLine.toLowerCase();
//depois aplica a expressăo regular
Pattern p = Pattern.compile("(\\d+)|([a-záéíóúçăőôę]+)");
Matcher m = p.matcher(minusculo);
//-------------------------------------------------------
//(2.3) IMPORTANTE: neste loop pegamos cada palavra
// e atualizamos o mapa de frequęncias
//-------------------------------------------------------
while(m.find())
{
String token = m.group(); //pega um token
Integer freq = mapPalavras.get(token); //verifica se esse
//token já está no mapa
if (freq != null) { //se palavra existe, atualiza a frequencia
mapPalavras.put(token, freq+1);
}
else { // se palavra năo existe, insiro com um novo id e freq=1.
mapPalavras.put(token,1);
}
}
//pega a próxima linha do arquivo
curLine = txtBuffer.readLine();
}
txtBuffer.close();
//-------------------------------------------------------
// (3) imprime o mapa de frequencias
//-------------------------------------------------------
for (Map.Entry<String, Integer> entry : mapPalavras.entrySet()) {
System.out.println(entry.getKey() + "\tfreq=" + entry.getValue());
}
}
}
Para testar a execuçăo do programa, utilizaremos o arquivo “teste.txt” que contém o texto de uma notícia publicada em um jornal. O conteúdo do arquivo é apresentado na Figura 2.

Figura 2: Arquivo teste.txt
A execuçăo do programa sobre esse arquivo texto produzirá o resultado mostrado na Figura 3:
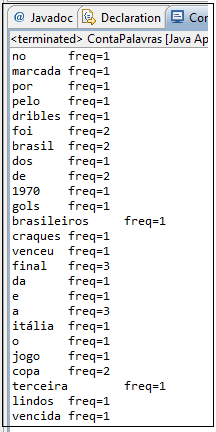
Figura 3: Resultado do Processamento
No programa apresentado, as seçőes 2.2 e 2.3 contęm os trechos de código mais importantes. Por isso vamos agora comentar um pouco essas seçőes. Na seçăo 2.2, o primeiro passo é converter a linha lida do arquivo para minúsculo. Após isso ser feito, utilizamos a classe “Pattern” para definir a expressăo regular que será utilizada para “quebrar” uma linha lida do arquivo em um conjunto de palavras (ou “tokens” - termo comumente utilizado na mineraçăo de texto). A classe “Matcher” é responsável por aplicar (ou executar) essa expressăo regular.
O programa da Listagem 1 utiliza a seguinte expressăo regular:
(\\d+)|([a-záéíóúçăőôę]+)")
Esta expressăo indica que consideraremos uma palavra qualquer sequęncia de números (ex: 1970, 2013, 33, 0, etc.) ou qualquer sequęncia de letras (ex: “jogo”, “a”, “dribles”, etc.). Năo é um método perfeito, pois realiza separaçőes erradas em alguns casos. Por exemplo: no caso da frase “plataforma P20”, a expressăo regular faz a separaçăo em tręs tokens, “plataforma”, “p” e “20” ao invés do correto, que seria apenas dois (“plataforma” e “p20”). Outro problema ocorre em palavras que possuem hífen, como “couve-flor”, que seria quebrada em 2 tokens (“couve” e “flor”). De qualquer forma, no geral, a expressăo regular apresenta bom desempenho e a vantagem de ser simples.
Seguindo com a explicaçăo do programa, na seçăo 2.3 temos um loop que percorre cada token (palavra) identificado em uma linha do arquivo como o objetivo de criar o mapa de palavras. Nosso mapa terá a estrutura similar a mostrada no esquema da Figura 4. As chaves săo as palavras e os valores a frequęncia de cada uma delas (é um mapa String -> Integer).
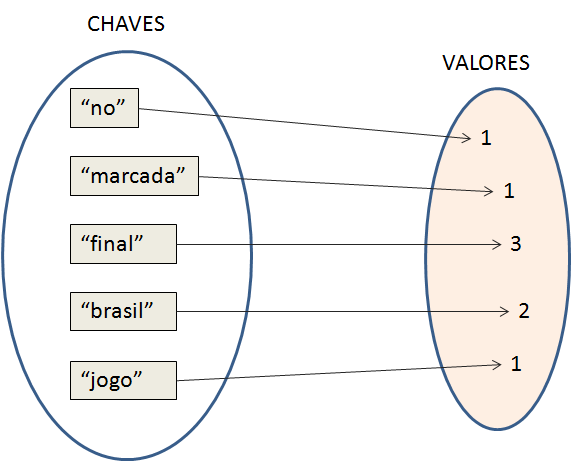
Figura 4: Estrutura do objeto mapPalavras
No loop implementado na seçăo 2.3, realizamos o seguinte processamento para cada token. Primeiro verificamos se o mesmo já foi inserido no HashMap (objeto “mapPalavras”) com o uso do método “get”. Depois basta usar o método “put” para atualizar o mapa. O método “put” tem a vantagem de ser bastante versátil, pois podemos utilizá-lo tanto para inserir um novo elemento no mapa como para atualizar um elemento já existente. Observe que, em nosso programa, quando uma palavra ainda năo está no mapa, utilizamos o método “put” para inseri-la com frequęncia = 1. Quando a palavra já está armazenada no mapa, utilizamos igualmente o método “put”, mas desta vez para incrementar a frequęncia da mesma.
Finalizando o programa, na seçăo 3 percorremos todos os elementos do nosso mapa, imprimindo as chaves (palavra) e os valores (frequęncia).
Até a próxima!

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.