Atençăo: esse artigo tem um vídeo complementar. Clique e assista!
O artigo trata dez cenários problemáticos que podem ocorrer no cotidiano da administraçăo do banco PostgreSQL e possíveis soluçőes para estes problemas.
Para que serve:
Através destes cenários, que săo bastante próximos de possíveis problemas que ocorrem no dia a dia, o leitor será esclarecido sobre qual é a melhor metodologia de resoluçăo de problemas diante dos fatos.
Em que situaçăo o tema é útil:
O artigo esta recheado de dicas e soluçőes úteis năo somente para solucionar problemas mas para também realizar a manutençăo preventiva diária.
Especialistas em software indicam uma crescente na adoçăo de soluçőes free (gratuitas ou de código aberto) como um mecanismo para driblar os incautos da crise mundial. Diante deste fato, usar o PostgreSQL năo é apenas uma opçăo para reduçăo de custo operacional em um projeto, mas também é usar um SGDB com poder suficiente para atender grandes demandas. Apenas para informaçăo, projetos como a ferramenta de comunicaçăo SKYPE foi desenvolvida utilizando o SGBD PostgreSQL. Um caso de sucesso como este já demonstra a aplicabilidade deste banco.
Ruma ŕ versăo 8.4, o PostgreSQL é um atrativo para gerentes de T.I e DBAs. Porém, mesmo com uma vasta documentaçăo, administrar banco de dados exige muitas vezes mais do que um bom conhecimento técnico. Problemas podem surgir e nem sempre a soluçăo é encontrada em um manual. O propósito deste artigo é justamente este: auxiliar os que estăo iniciando projetos em PostgreSQL e terăo pela frente uma longa peleja. Sendo assim, convido os leitores a escreverem enviando problemas para que em uma segunda fase possamos transformar o problema em uma soluçăo compartilhada através de artigos.
Os cenários que iremos abordar săo:
1. O sistema está com falta de espaço em disco;
2. Sistema amanhece travado quando o Vacuum entra em execuçăo;
3. O pg_dump năo está realizando backup. Foi descoberta uma tabela corrompida;
4. Há valores duplicados na tabela e năo conseguimos criar uma Chave Primária;
5. De repente aparecem muitos processos em “IDLE IN TRANSACTION” e os outros processos entram em waiting travando a aplicaçăo;
6. Meu sistema está lento demais;
7. Quando executo o relatório o sistema trava;
8. Nunca tenho certeza se o Slony está replicando;
9. Nunca tenho certeza se as novas tabelas estăo sendo replicadas;
10. Estou em dúvida em saber qual é a melhor estratégia de Backup.
O ambiente adotado
Neste artigo iremos reforçar as soluçőes em ambiente Linux/Unix, embora algumas soluçőes possam ser empregadas em Windows. O fato é que ao se falar de PostgreSQL, o Linux é o sistema operacional que melhor se encaixa como S.O. para montar um ambiente de produçăo. Em hardwares de mercado como HP, DELL e IBM, a distribuiçăo deve tender para o Red Hat Enterprise ou o SuSE devido ŕ política de homologaçăo destes marcas. Em nosso caso, por se tratar de um laboratório, estaremos utilizando o Ubuntu 9.04 juntamente com o PostgreSQL 8.3 e Slony I por ser a soluçăo de replicaçăo mais comum. O ambiente foi montado através do gerenciador de pacotes do Debian (APT).
Resumo do ambiente:
· S.O = Ubuntu Server 9.04 i386
· SGBD = PostgreSQL 8.3
· Replicaçăo = Slony I
· HD = Partiçăo de 1 G para o PostgreSQL e 300Mb para o pg_xlog
Para montar os 10 cenários que iremos seguir neste artigo, foi também necessário realizar a criaçăo de uma base de dados de exemplo. Para isso, criamos a base com o nome revista contendo por enquanto duas tabelas: a tabela usuario (Tabela 1) e a tabela produto (Tabela 2).
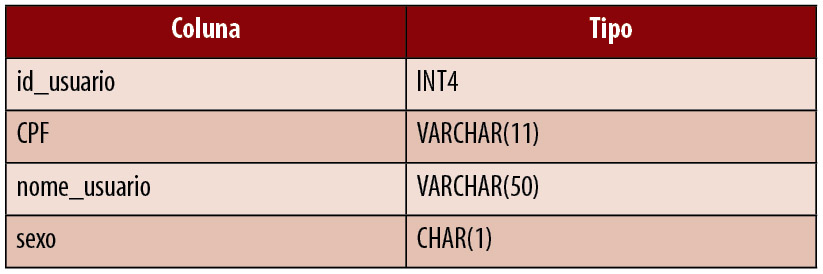
Tabela 1. Campos da tabela usuario
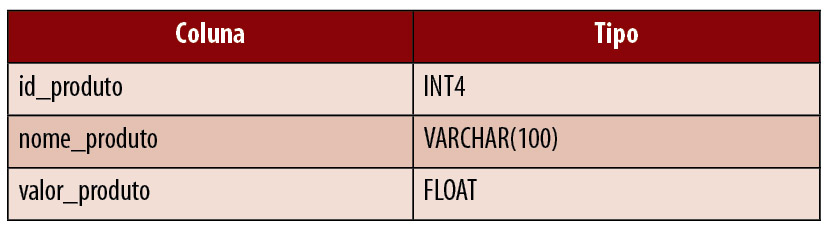
Tabela 2. Campos da tabela produto
Para povoar estas tabelas, foi utilizada uma rotina escrita em Perl, apresentada na Listagem 1. Esta rotina gera um arquivo texto com a sintaxe SQL para importaçăo através do comando psql do PostgreSQL. Caso o leitor se familiarize com outra linguagem, poderá transcrever para PHP, JAVA, Shell Script.
Listagem 1. Código shell – popula.pl para polular o banco revista
1. #!/usr/bin/perl
2. $count = 1;
3. $arquivosaida = "popula_usuario.sql";
4. @chars = ("A" .. "Z", "a" .. "z");
5. @numbers = (1 .. 9);
6. @single_chars = ("a" .. "e");
7. $totalrecords = 6000000; # 6 milhoes
8. print "Gerando dados em ", $arquivosaida, " \n";
9. open(OUTPUT, "> $arquivosaida");
# TABELA USUARIO
10. print OUTPUT "DROP TABLE usuario;\n";
11. print OUTPUT "CREATE TABLE usuario(";
12. print OUTPUT "id_usuario INT4, cpf varchar(11), nome_usuario VARCHAR(50), sexo CHAR(1)";
13. print OUTPUT ");\n";
14. print OUTPUT "COPY usuario (id_usuario, cpf, nome_usuario, sexo) FROM stdin;\n";
15. while ($count <= $totalrecords)
16. {
17. $randstring = join("", @chars [map{rand @chars} ( 1 .. 50 ) ]);
18. $randnum = join("", @numbers [map{rand @numbers} ( 1 .. 11 ) ]);
19. $randchar = join("", @single_chars [map{rand @single_chars} (1)]);
20. print OUTPUT;
21. print OUTPUT $count."\t".$randnum."\t".$randstring."\t".$ranchar."\n";
22. $count++;
23. };
24. print OUTPUT "\\.";
25. print OUTPUT "\n";
# TABELA PRODUTO
26. print OUTPUT "DROP TABLE produto;\n";
27. print OUTPUT "CREATE TABLE produto(";
28. print OUTPUT "id_produto INT4, nome_produto VARCHAR(50), valor_produto REAL";
29. print OUTPUT ");\n";
30. print OUTPUT "COPY produto (id_produto, nome_produto, valor_produto) FROM stdin;\n";
31. # redefinindo variaveis
32. $count = 1;
33. $totalrecords = 1000000; # 1 milhao
34. while ($count <= $totalrecords)
35. {
36. $randstring = join("", @chars [map{rand @chars} ( 1 .. 8 ) ]);
37. print OUTPUT;
38. print OUTPUT $count."\t".$randstring.”\t”.”12.5”. "\n";
39. $count++;
40. };
41. print OUTPUT "\\.";
42. print OUTPUT "\n";
# CRIACAO PK E INDEX
43. print OUTPUT “ALTER TABLE usuario ADD CONSTRAINT pk_usuario PRIMARY KEY (id_usuario);\n”
44. print OUTPUT “ALTER TABLE produto ADD CONSTRAINT pk_produto PRIMARY KEY (id_produto);\n”
45. print OUTPUT "CREATE INDEX idx_produto ON produto(nome_produto);\n";
46. print OUTPUT "CREATE INDEX idx_usuario ON usuario(nome_usuario);\n"
# VACUUM
47. print OUTPUT "VACUUM ANALYZE usuario;\n";
48. print OUTPUT "VACUUM ANALYZE produto;\n";
# FECHANDO ARQUIVO
49. close OUTPUT;
50. print "OK... GERADO! \n";Na Listagem 1, entre as linhas 1 e 9 săo declarados os parâmetros (ex: nome do arquivo de saída e quantidade de registros a serem criados, que foi definido para 5 milhőes) a serem usados no processo de criaçăo do script para povoar o banco revista. Entre as linhas 10 e 25 săo montados os códigos SQL para criaçăo e inserçăo de dados na tabela usuario. Entre as linhas 26 e 42 săo montados os códigos SQL para criaçăo e inserçăo de dados na tabela produto. Nas linhas de 43 a 45 săo configurados chaves primárias e índices para as duas tabelas, e por fim é utilizado o comando VACUUM para visualizar o conteúdo das duas tabelas. Atente para esta explicaçăo, pois precisaremos ajustá-la para os diferentes cenários que iremos descrever ao longo deste artigo.
A partir de agora iremos seguir em cada um dos 10 cenários descrevendo problemas e soluçőes que podem ser encontrados por DBAs durante a administraçăo de um banco de dados em PostgreSQL.
Cenário 1 – O sistema esta com falta de espaço em disco
Ao planejar um sistema, devemos ter em mente, mesmo que no “chute”, o quanto este sistema poderá gerar de dados no HD. Năo podemos ser exagerados em comprar mais do que realmente precisamos. Em todo projeto que está nascendo, o CUSTO OPERACIONAL é uma variável importante para analisarmos a lucratividade do projeto.
É claro que o DBA năo deve ser uma espécie de NEO do filme MATRIX que vę apenas BITS, mas deve contemplar o projeto no âmbito financeiro. Porém, mesmo um bom planejamento pode ocasionar problemas que geram aquelas dores de cabeça como a FALTA DE ESPAÇO EM DISCO!
O que pode ocasionar este problema?
1. Índices e chaves primarias
2. Falta de vacuum full
3. Ferramentas de replicaçăo.
Problemas devido a Índices e Chaves Primárias
Os índices năo săo uma estrutura mágica no qual vocę os cria e ele como mágica aumenta a velocidade da consulta. Na verdade, índice é uma estrutura do banco de dados que consome espaço em disco proporcional ŕ quantidade de registros existentes na tabela. Năo estamos sendo contrários ŕ criaçăo de índices, mas algo que sempre foge do planejamento de uma equipe de sistema e do DBA é que quando criamos índices durante o processo natural de um projeto em produçăo, este índice irá precisar alocar espaço em disco.
Para demonstrar isso na prática, vamos criar os 6 milhőes de registro existentes nas duas tabelas que estamos utilizando (usuario e produto), mas sem a criaçăo das chaves primárias e índices. Para isso, basta remover as linhas 43 a 46 da ...







