Clique aqui para ler este artigo em pdf ![]()

Clique aqui para ler todos os artigos desta ediçăo
Explorando o DataRow do ADO.NET
por John Papa
O ADO.NET oferece uma rica interface de programaçăo que permite aos desenvolvedores interagir com linhas por meio dos objetos DataTable, DataRowCollection e DataRow. Analisarei uma forma de vocę manipular dados usando o DataRow e de se concentrar na importaçăo, percurso, localizaçăo e exame de dados no ADO.NET e C#.
Criando e Importando Linhas
O DataTable expőe vários métodos que podem ser usados na manipulaçăo de objetos DataRow, como ImportRow, NewRow, Select e LoadDataRow. Usarei esses métodos em um aplicativo Windows® Forms de exemplo para mostrar a vocę como capturar uma ou mais linhas de um DataSet e adicioná-las a um segundo DataSet. Mostrarei também como criar e carregar manualmente um DataSet.
Para começar, carrego um DataSet diretamente da tabela Employee do banco de dados SQL Server™ Northwind (consulte a Figura 1) e o vinculo a um DataGrid (consulte a Listagem 1). Depois disso, crio uma chave primária de restriçăo para o DataTable na coluna EmployeeID. Como esta coluna é uma coluna IDENTITY do banco de dados Northwind, defino também a propriedade AutoIncrement como true, e ambas as propriedades AutoIncrementSeed e AutoIncrementStep como -1. Isso dirá ao DataTable que, sempre que uma linha for inserida ali, ele deverá gerar o valor da coluna de dados EmployeeID, começando com um valor de -1 e decrescendo 1 para cada linha. Com isso, os valores de EmployeeID em qualquer linha inserida seriam -1, -2, -3 e assim por diante. Isso é importante porque năo tenho como saber qual valor o banco de dados atribuirá ao EmployeeID quando eu enviar novas linhas para serem inseridas. Desse modo, atribuo um valor que sei que năo pode ser atribuído pelo banco de dados (números negativos). Em seguida, ao enviar os dados para serem inseridos no banco de dados, ignorarei o valor de EmployeeID e recuperarei o valor recém-criado e atribuído a partir do banco de dados.
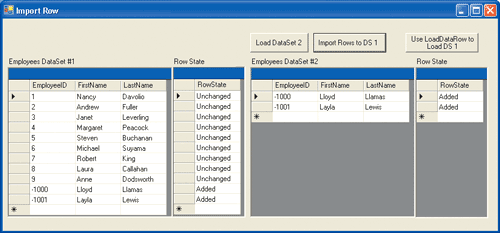
Figura 1 – Carregando o DataSet
Listagem 1 – Carrega a tabela Employee e preenche o DataGrid
m_oCn = new SqlConnection(m_sCn);
//-- Define o SELECT Command
string sSQL = "SELECT EmployeeID, FirstName, LastName FROM
Employees";
SqlCommand oSelCmd = new SqlCommand(sSQL, m_oCn);
//-- Pega os registros de Employees
oSelCmd.CommandType = CommandType.Text;
m_oDa.SelectCommand = oSelCmd;
m_oDa.Fill(m_oDs1, "Employees");
//-- Define a primary key
m_oDs1.Tables["Employees"].Constraints.Add("PK_Employees",
m_oDs1.Tables["Employees"].Columns["EmployeeID"], true);
m_oDs1.Tables["Employees"].Columns["EmployeeID"].
AutoIncrement = true;
m_oDs1.Tables["Employees"].Columns["EmployeeID"].
AutoIncrementSeed = -1;
m_oDs1.Tables["Employees"].Columns["EmployeeID"].
AutoIncrementStep = -1;
//-- Vincula
grdEmployees1.DataSource = m_oDs1.Tables["Employees"];
Em seguida, crio manualmente um segundo DataSet usando código e, depois, adiciono duas linhas de funcionários a ele (consulte a Listagem 2). Neste código de exemplo, eu crio um DataTable e adiciono a ele objetos DataColumn que correspondam aos objetos DataColumn do primeiro DataSet: m_oDs1. Também adiciono uma restriçăo de chave primária a essa tabela para manter os dois DataTables e DataSets sincronizados. No entanto, repare que eu defini AutoIncrementSeed como -1000 (consulte a Listagem 2). Dessa forma, quando pego as linhas deste DataTable criado manualmente e as copio no DataTable extraído do banco de dados, tenho certeza de que nenhuma das linhas terăo EmployeeIDs iguais (duplicadas). Essa é uma soluçăo simples, porém eficaz, de evitar valores de chave năo exclusivos (non-unique key values[r1] ).
Em seguida, criarei uma nova linha para o DataSet criado manualmente, usando o método NewRow (novamente, consulte a Listagem 2). Isso pode parecer deselegante porque, para adicionar uma nova linha ao DataTable, preciso solicitar a nova linha ao DataTable, atribuir seus valores e, em seguida, adicionar a nova linha ao DataTable. Assim, quando chamo o método NewRow, a linha recém-criada é na verdade separada do DataTable. Para anexá-la, é necessário que ela seja passada ao método Add da coleçăo Rows do DataTable.
Listagem 2 – Cria o DataSet manualmente
DataTable oDt = new DataTable("Employees");
DataRow oRow;
//-- Crio a tabela
oDt.Columns.Add("EmployeeID",
System.Type.GetType("System.Int32"));
oDt.Columns.Add("FirstName",
System.Type.GetType("System.String"));
oDt.Columns.Add("LastName",
System.Type.GetType("System.String"));
oDt.Constraints.Add("PK_Employees", oDt.Columns["EmployeeID"],
true);
oDt.Columns["EmployeeID"].AutoIncrement = true;
oDt.Columns["EmployeeID"].AutoIncrementSeed = -1000;
oDt.Columns["EmployeeID"].AutoIncrementStep = -1;
m_oDs2.Tables.Add(oDt);
//-- Adiciono as linhas
oRow = m_oDs2.Tables["Employees"].NewRow();
oRow["FirstName"] = "Lloyd";
oRow["LastName"] = "Llamas";
m_oDs2.Tables["Employees"].Rows.Add(oRow);
oRow = m_oDs2.Tables["Employees"].NewRow();
oRow["FirstName"] = "Layla";
oRow["LastName"] = "Lewis";
m_oDs2.Tables["Employees"].Rows.Add(oRow);
grdEmployees2.DataSource = m_oDs2.Tables["Employees"];
O código a seguir pode ser executado para importar as linhas do segundo DataSet (o que foi criado manualmente) para o primeiro DataSet (proveniente do banco de dados Northwind).
//-- Importa as linhas
foreach (DataRow oRow in m_oDs2.Tables["Employees"].Rows)
{
m_oDs1.Tables["Employees"].ImportRow(oRow);
}
Este código executa um loop nas duas linhas que inseri no DataTable criado manualmente e as importa através do método ImportRow, uma de cada vez, para o DataSet extraído da tabela Employee do Northwind.
E isso é tudo que vocę precisa para importar dados. No entanto, é necessário observar alguns aspectos importantes sobre a importaçăo de dados. Quando os dados săo importados de um DataTable para outro, o RowState também é importado. Para demonstrar isso, adicionei mais dois objetos DataGrid ao Windows Form (consulte a Figura 1). Adicionei um segundo DataTable para armazenar o RowState de cada linha no primeiro DataSet, que já contém um DataTable de funcionários provenientes do Northwind. Com isso, existem agora dois objetos DataTable no primeiro m_oDs DataSet: um que se refere aos funcionários e o outro que possui o mesmo número de linhas que o primeiro. O segundo DataTable, que chamei de State, é utilizado apenas para armazenar o RowState de cada linha proveniente do DataTable Employee.
O segundo DataSet já contém um DataTable para armazenar os funcionários que criei manualmente através de código. Adicionei um segundo DataTable a ele para armazenar o RowState de cada uma de suas linhas. O objetivo aqui é demonstrar como o RowState da linha é persistido pelo método ImportRow. Os RowStates das linhas recuperadas da tabela Employees do banco de dados e armazenadas no primeiro m_oDs1 DataSet săo todos definidos como “unchanged”, já que năo se fará nada com eles. Os valores de RowState das linhas adicionadas manualmente ao segundo m_oDs2 DataSet săo ambos “added”, já que eu mesmo os adicionei. Desse modo, quando eu importo essas duas linhas para o DataSet m_oDs1, o RowState das duas linhas novas ainda é “added”.
Só como lembrete: se eu tivesse invocado o método AcceptChanges no primeiro DataSet após ter adicionado as duas linhas, seus valores RowState seriam definidos como “unchanged”. Desse modo, quando posteriormente eu as importasse para o DataSet m_oDs2, seus RowStates também estariam “unchanged”. Quando o método AcceptChanges é invocado em um DataTable, ele informa ao DataTable que os valores originais de cada DataRow devem ser definidos como valor atual (seja ele qual for), produzindo um RowState “unchanged” para cada linha. O código completo deste exemplo inclui também o código que rastreia o RowState DataGrid.
E, já que estamos falando no assunto, LoadDataRow é outro método que vale a pena abordar. Basicamente, o método ImportRow copia um DataRow de um DataTable para um segundo DataTable, partindo do princípio de que ambos os objetos DataTable possuam as mesmas colunas. O método LoadDataRow também pode ser usado para copiar linhas. O código a seguir mostra como ImportRow foi usado no exemplo do código anterior para copiar um DataRow de um DataTable para outro:
//-- Importa a linha
m_oDs1.Tables["Employees"].ImportRow(oRow);
Esse resultado também pode ser obtido com o método LoadDataRow, conforme se vę a seguir:
//-- Carrega os dados da linha
object[] aRowValues = {oRow["EmployeeID"], oRow["FirstName"],
oRow["LastName"]};
m_oDs1.Tables["Employees"].LoadDataRow(aRowValues, false);
Como as linhas estăo apenas sendo copiadas, o ImportRow será mais prático quando os dois objetos DataTable existirem com as mesmas colunas. No entanto, LoadDataRow propicia um pouco mais de flexibilidade. Por exemplo, se os objetos DataTable năo tiverem as mesmas colunas, vocę poderá usar o LoadDataRow mas năo o ImportRow. Isto acontece porque o método LoadDataRow aceita arrays de valores para inserir (neste caso, em um DataTable). Assim, se os dois objetos DataTable tivessem colunas diferentes, LoadDataRow poderia simplesmente capturar os valores apropriados na devida ordem do segundo DataTable para inseri-los no primeiro DataTable.
No entanto, o método LoadDataRow tem outra finalidade, além de inserir linhas em um DataTable. Na verdade, LoadDataRow é mais útil quando é necessário atualizar uma linha existente (se houver) ou adicionar uma nova linha se ela năo existir. Caso seja encontrado o valor de chave da linha, LoadDataRow atualizará esses valores em vez de inserir uma nova linha. Essa é apenas outra maneira de demonstrar que LoadDataRow é mais flexível que ImportRow, já que neste cenário ImportRow geraria uma exceçăo se já houvesse uma linha com um valor de chave duplicado.
Localizando Linhas
O próximo código de exemplo destina-se a responder ŕs diversas perguntas que recebi com relaçăo ŕ localizaçăo de linhas. Como existem diversas formas de localizar linhas usando o ADO.NET, descreverei exemplos das tręs técnicas mais importantes: os métodos Find, Contains e Select. Todos esses tręs métodos podem ser usados para localizar linhas específicas; no entanto, eles realizam essa tarefa de diferentes formas.
O método Find procura uma linha pelo valor de sua chave primária. Se encontrar a linha, ele a retornará; caso contrário, ele retornará um valor nulo. O método Find é bastante útil quando vocę precisa localizar uma linha e executar uma açăo nela. Utilizei esse método no primeiro exemplo deste artigo, quando sincronizei o DataGrid Employee ao DataGrid RowState correspondente. Naquele exemplo, eu tinha um valor comum em ambos os objetos DataGrid – o EmployeeID. Criei uma restriçăo de chave primária em ambos os objetos [r2] DataTable subjacentes aos objetos DataGrid, usando seus DataColumns EmployeeID. Com isso, eu pude executar um loop nas linhas do DataTable Employee e definir o estado correspondente da linha do DataTable para o valor apropriado. Observe como o código de exemplo a seguir executa um loop em cada funcionário do DataTable Employees e utiliza o método Find para recuperar a linha correspondente no DataTable State.
DataRow oStateRow;
foreach (DataRow oRow in m_oDs1.Tables["Employees"].Rows)
{
oStateRow = m_oDs1.Tables["State"].Rows.Find(oRow["EmployeeID"]);
oStateRow["RowState"] = oRow.RowState;
}
Neste exemplo, para que o método Find funcione de maneira adequada, é necessário haver uma chave primária. É preciso também existir a restriçăo de chave primária no DataColumn EmployeeID; caso contrário, o método Find irá gerar uma Exception. O método Find depende da restriçăo para localizar a linha desejada. Como o método Find requer sempre uma restriçăo de chave primária, năo é necessário se preocupar em localizar mais de uma linha. Se o DataTable possuísse múltiplos objetos DataColumn em sua chave primária (que resultassem em uma chave composta), eu poderia simplesmente ter passado um array de valores que representassem os valores da chave para o método Find.
Se năo precisasse localizar uma linha nem realizar açőes nela (mas apenas saber se ela existe no DataTable e se corresponde ao valor de chave primária), eu poderia usar o método Contains. Este método é bastante útil quando se precisa apenas verificar a existęncia de uma linha (sem recuperá-la). Ele funciona do mesmo modo que o método Find, no qual pode ser passado um valor único ou um array de valores, dependendo da quantidade de colunas que formam sua chave primária. Como o método Contains depende da existęncia de uma chave primária (assim como o método Find), antes de prosseguir, é importante certificar-se de que ela exista. Contains oferece uma maneira simples de verificar a existęncia de uma linha, enquanto Find verifica a linha e a retorna.
A terceira técnica consiste em usar o método Select do objeto DataTable. Ele retorna um array de objetos DataRow que atendem aos critérios especificados. O método Select possui várias formas sobrecarregadas, por isso, ele pode ser filtrado por meio de uma expressăo de string, retornado em determinada ordem de classificaçăo, ou filtrado para mostrar somente certos estados de linha.
A principal diferença entre os métodos Select e Find é que este último busca uma linha que corresponda aos valores de chave primária passados. Ele pode retornar zero linhas ou uma linha, ao passo que o método Select pode retornar zero ou mais linhas. Neste aspecto, o método Select é mais flexível, já que ele năo depende da existęncia de uma restriçăo de chave primária. Ele procura todas as linhas que atendem aos critérios e as retorna em um array de objetos DataRow. Para compararmos os métodos Find e Select, o fragmento de código a seguir mostra a utilizaçăo do método Find (proveniente do exemplo anterior) bem como a provável aparęncia do código de substituiçăo (se o método Select fosse utilizado):
//-- Usando o método Find
oStateRow = m_oDs1.Tables["State"].Rows.Find(oRow["EmployeeID"]);
oStateRow["RowState"] = oRow.RowState;
//-- Usando o método Select
DataRow[] aRow = m_oDs1.Tables["State"].Select("EmployeeID = " +
oRow["EmployeeID"]);
aRow[0]["RowState"] = oRow.RowState;
No caso deste exemplo, o método Find é mais eficiente, já que estou sempre procurando uma única linha. É possível usar o método Select, embora ele năo ofereça a vantagem de se usar apenas o valor de chave primária. Além disso, observe como codifiquei o índice de linha como primeira linha (índice de 0) no código de exemplo onde usei o método Select. Eu poderia ter executado um loop pelas linhas retornadas, mas como sei que existe apenas uma única linha, assumi o risco de inseri-la no código. Obviamente, esta năo é a melhor técnica quando se está procurando por uma única linha.
No entanto, o método Select pode ser bastante eficaz quando se está buscando um número desconhecido de linhas. Por exemplo, para localizar todos os funcionários de Seattle (supondo que a coluna City estivesse em meu DataTable), eu poderia facilmente fazę-lo com este código:
DataRow[] aRow = oDs.Tables["Employees"].Select("City = 'Seattle'");
Eu também poderia classificar os objetos DataRow recuperados no array, especificando da seguinte maneira o parâmetro de ordem de classificaçăo do método Select:
DataRow[] aRow = m_oDs2.Tables["Employees"].Select("City = 'Seattle'",
"LastName");
Esse método retornaria os funcionários que vivem em Seattle, classificados por seus sobrenomes. O método Select também pode filtrar linhas usando o DataViewRowState. O código a seguir retornaria os funcionários de Seattle recém-adicionados, classificados por sobrenome:
DataRow[] aRow = m_oDs2.Tables["Employees"].Select("City = 'Seattle'",
"LastName", DataViewRowState.Added);
Conclusőes
Este artigo demonstrou como recuperar linhas, verificar se elas existem, localizar uma linha específica com base no valor de chave, criar tabelas manualmente, criar uma nova linha e copiar linhas entre objetos DataTable. Abordou também DataRowState e como ele é persistido ao se usar o método ImportRow para importar uma linha. Tanto DataRowState quanto DataViewRowState săo extremamente úteis no ADO.NET, especialmente quando se trata de concorręncias.







