Introduçăo
As redes bayesianas (RB) săo esquemas de representaçăo simbólica de conhecimento - a representaçăo é modelada pela lógica proporcionada pelos processos de formalizaçăo matemática adotados - que incorporam em sua base de conhecimento uma distribuiçăo conjunta de probabilidades envolvendo variáveis aleatórias. Entre as variáveis haverá relaçőes de dependęncia estocásticas, explicitadas por fatos ou regras, que podem ser adquiridas por meio de um especialista no domínio enfocado ou por uma base de dados. As aplicaçőes práticas de RB vęm sendo bastante desenvolvidas no âmbito dos sistemas especialistas probabilísticos (principalmente no diagnóstico e prognóstico médico), da recuperaçăo de informaçăo probabilística, da descoberta de conhecimento em bases de dados (descriçăo), e da classificaçăo bayesiana.
Segundo Simőes, Nassar e Pires (2001), as RB săo compostas basicamente por duas partes, uma qualitativa e outra quantitativa. A parte qualitativa, que pode ser visualizada esquematicamente na Figura 1, é um modelo gráfico, na verdade um grafo acíclico direcionado (GAD), no qual as variáveis săo representadas por nós, e os arcos que os ligam significam dependęncias diretas entre essas variáveis. Ele é acíclico no sentido de que năo há, no grafo, arcos ligando a saída de um nó ŕ sua própria entrada. 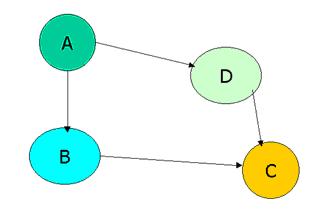
Já a parte quantitativa é formada pelo conjunto de probabilidades totais e condicionais, a priori, associadas aos nós e arcos existentes na parte qualitativa.
Um dos grandes incentivos ŕ utilizaçăo desse método de representaçăo, um verdadeiro diferencial, é o flexível ambiente conjunto gráfico-quantitativo proporcionado pelas RB, o qual permite prontamente, e de forma on-line, a realizaçăo de simulaçőes e análises de sensibilidade, como o leitor poderá verificar na próxima coluna.
As referidas distribuiçőes de probabilidade condicionais, que representam o conhecimento adquirido do especialista ou dos dados, devem ser registradas por meio de algum teorema ou corolário matemático. Isso tem sido obtido satisfatoriamente pelo Teorema de Bayes. Esse teorema, herança devida ao estudo das probabilidades por parte do teólogo e matemático Thomas Bayes (1702 - 1761), é a base para a parte quantitativa das redes bayesianas. É importante ao usuário conhecer, ao menos em certo grau, os fundamentos desse teorema, já que isso é importante na fase de validaçăo da RB em um processo de classificaçăo.
Entăo sejam H 1 , H 2 ,..., H k partiçőes de um espaço amostral S , e sendo e um evento associado a S , o teorema é formalizado por: 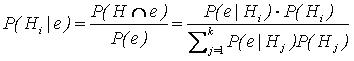 (1)
(1)
Sendo i = 1,2..., k . Essa equaçăo, também conhecida como fórmula das probabilidades das causas (ou dos antecedentes), nos informa, em última análise, a probabilidade de uma particular hipótese H i (causa) ocorrer, dada a ocorręncia do evento e . Este teorema, segundo a literatura específica, é matematicamente perfeito, e somente a má avaliaçăo dos P( H i ) é que pode tornar sua aplicaçăo discutível (MEYER, 1975).
No que concerne a aquisiçăo do conhecimento, os H's săo as hipóteses possíveis e mutuamente excludentes do estado de uma variável. Os eventos e's săo entendidos como as evidęncias provocadas pelo estado H da variável. Um resultado muito interessante para o uso em RB é obtido a partir da suposiçăo prévia, ou a verificaçăo, de que dois ou mais eventos e 1 , e 2 ,...,e n săo independentes, dada a ocorręncia da hipótese H , ou seja, o conhecimento sobre a ocorręncia do evento e 1 năo traz informaçăo adicional sobre a ocorręncia de e 2 , e vice versa. Assim, o Teorema de Bayes, sob a hipótese de evidęncias múltiplas e independentes assume a forma seguinte:
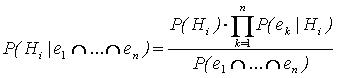 (2)
(2)
Atualizaçăo Bayesiana para Novas Evidęncias
As RB, no contexto da aplicaçăo em sistemas inteligentes e extraçăo de conhecimento, devem ser capazes de se atualizar frente a novas evidęncias e realidades percebidas a partir do mundo real. Essa capacidade de atualizaçăo é proporcionada pelo teorema em tela e, para tal, considerando-se a referida hipótese de independęncia condicional, que simplifica sobremaneira a atualizaçăo bayesiana da rede, basta que seja adaptada a equaçăo (2). De fato, considerando-se uma hipótese H i e denotando-se uma seqüęncia de eventos, supostamente independentes em relaçăo ŕ H i , por e 1 , e 2 ,...,e n = e n , a ocorręncia de uma nova evidęncia e n+1 pode ser contabilizada da seguinte forma:
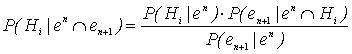 (3)
(3)
Esse resultado mostra que ao ser calculada a probabilidade condicional da hipótese H i , dado um conjunto de evidęncias e n , isto é, ![]() a probabilidade conjunta das evidęncias passadas
a probabilidade conjunta das evidęncias passadas ![]() pode ser desprezada na equaçăo, pois
pode ser desprezada na equaçăo, pois ![]() passa a representar completamente a experięncia passada, e sua atualizaçăo para um novo evento e n+1 requer apenas sua multiplicaçăo pela razăo
passa a representar completamente a experięncia passada, e sua atualizaçăo para um novo evento e n+1 requer apenas sua multiplicaçăo pela razăo 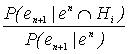 , a qual contabiliza o impacto da nova evidęncia.
, a qual contabiliza o impacto da nova evidęncia.
Classificaçăo e Descriçăo Bayesiana
Para a aplicaçăo de RB em data-mining, tanto na descriçăo quanto em classificaçăo, é necessário que a rede apreenda determinadas características e parâmetros a partir dos dados, de forma a estar apta a produzir conhecimento ou classificar probabilisticamente casos ou indivíduos em classes ou categorias. Nesse contexto de aprendizagem, o objetivo básico é levantar todas as informaçőes sobre a estruturaçăo e magnitude das probabilidades totais e condicionais a priori associadas aos estados das variáveis aleatórias envolvidas no domínio.
Vimos que uma RB possui uma estrutura qualitativa e uma parte quantitativa. Ambas podem ser aprendidas indutivamente a partir de dados. Primeiro aprende-se a estrutura gráfica e, posteriormente, a parte quantitativa (numérica) que envolve as probabilidades. O aprendizado numérico atualmente é considerado relativamente simples, enquanto que o aprendizado da estrutura gráfica, que envolve a definiçăo e orientaçăo das relaçőes de dependęncia condicional, é bastante complexo, pois se houver hipoteticamente dez variáveis em uma base de dados, o número total de redes (estruturas gráficas) possíveis se eleva a incríveis f(10) = 4,2 x 1018 (Silva e Ladeira, 2002).
Por isso, muitas vezes a pesquisa bayesiana utiliza-se da chamada abordagem ingęnua para o aprendizado da estrutura. O enfoque ingęnuo assume a mencionada hipótese simplificadora de independęncia condicional entre as variáveis. De forma a aclarar esse conceito, sejam X, Y e Z tręs variáveis aleatórias discretas. Dizemos que X é condicionalmente independente de Y, dado Z, se a distribuiçăo de probabilidades de X é independente do valor de Y, dado o valor de Z.
Essa suposiçăo implica, na prática, que os atributos para as variáveis em questăo săo condicionalmente independentes, dada uma determinada classe Ci, resultando que a probabilidade de se observar o conjunto de atributos (e1,..., en) é dada pela equaçăo 5: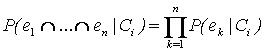 (4)
(4)
Com isso, as probabilidades ![]() podem ser aprendidas facilmente a partir de uma amostra de estimaçăo e, utilizando-se das equaçőes (2) e (4), vai-se atribuir ao caso ou indivíduo a classe de maior probabilidade posterior, o que, na prática, implica atribuir-lhe a classe de maior valor de
podem ser aprendidas facilmente a partir de uma amostra de estimaçăo e, utilizando-se das equaçőes (2) e (4), vai-se atribuir ao caso ou indivíduo a classe de maior probabilidade posterior, o que, na prática, implica atribuir-lhe a classe de maior valor de 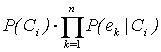
Estudos comparativos informados na literatura dăo conta de que o classificador ingęnuo, para certos domínios, é comparável em termos de resultados com as redes neurais e as árvores de decisăo. Contudo, há ocasiőes em que a rigidez da hipótese de independęncia condicional năo funciona a contento, e ela tem de ser relaxada, requisitando um aprendizado generalizado, de forma a produzir bons resultados, e isso eleva bastante o grau de complexidade do aprendizado de estruturas, pois todas as relaçőes de dependęncia/independęncia passíveis de ocorrerem a partir de uma distribuiçăo de probabilidade conjunta P, săo, a princípio, passíveis de aposiçăo no grafo, e, portanto devem ser investigadas. A aprendizagem generalizada é um campo em aberto atualmente, e tem sido tema de extensos estudos e pesquisas envolvendo elevado nível de complexidade e processamento computacional.
Os leitores que quiserem aprofundar-se nos aspectos formais apresentados acima, bem como estudar algoritmos de aprendizado bayesiano generalizado, podem consultar a bibliografia relacionada ao final deste artigo.
A partir das noçőes aqui apresentadas, năo percam na próxima coluna a utilizaçăo prática de uma Shell (em versăo Demo) especificamente voltada para aplicaçőes de RB, objetivando efetuar um aprendizado automático de estrutura e quantitativo, pelo processo ingęnuo, a partir de uma amostra de dados teste.
Abraços, Alexandre.
Bibliografia Referenciada e Consultada:
BARRETO, Alexandre; VIEIRA, Renato C.; NASSAR, Silvia M. Redes Bayesianas e Produçăo de Conhecimento: uma abordagem de data-mining em dados de um concurso vestibular. In: 35ş Reuniăo Regional da ABE/SOBRAPO, Florianópolis-SC, 2003 e V Escola Regional da Sociedade Brasileira de Computaçăo (SBC) - Centro-Oeste, 2002.
B ITTENCOURT, Guilherme. Inteligęncia Artificial: ferramentas e teorias. Florianópolis: Editora da UFSC, 2001.
MEYER, Paul L. Probabilidade: Aplicaçőes ŕ Estatística. Rio de Janeiro: LTC, 1975.
NEAPOLITAN, Richard. Probabilistic Reasoning in Expert Systems. John Wiley & Sons, Inc. New York, 1990.
RABUSKE, Renato A. Inteligęncia Artificial. Florianópolis: Editora da UFSC, 1995.
RUSSEL, Stuart; NORVIG, Peter. Artificial Intelligence - A Modern Approach. Prentice-Hall, 1995.
SCHEINES, Richard. (R.Scheines@andrew.cmu.edu)/Carnegie Mellon University "http://www.andrew.cmu.edu/user/scheines/tutor/d-sep.html", acesso em 25/08/2003, 10:50 hs.
SIMŐES, Priscyla Waleska Targino de Azevedo; NASSAR, Silvia Modesto; PIRES, Maria Marlene de Souza. Sistema de Apoio na Avaliaçăo da Falęncia do Crescimento Infantil. In: CONGRESSO BRASILEIRO DE COMPUTAÇĂO, Workshop de Informática Aplicada ŕ Saúde, 2001.
SILVA, W. T., e LADEIRA, M. Mineraçăo de Dados com Redes Bayesianas. XXI JAI – Jornada de Atualizaçăo em Informática. Anais do XXII Congresso da Sociedade Brasileira de Computaçăo, vol. 2, pg. 235-286, 2002.
STEIN, Carlos Efrain. Sistema Especialista Probabilístico: Base de Conhecimento Dinâmica. 2000. Dissertaçăo (Mestrado em Cięncias da Computaçăo) - Programa de Pós-Graduaçăo em Cięncias da Computaçăo, UFSC, Florianópolis.
Um abraço.
Alexandre.







