Acessando outros SGBDs via DBI-Link no PostgreSQL
Nesta série de artigos, que será apresentada em duas partes, implementaremos uma replicaçăo assíncrona de um banco de dados em PostgreSQL no Windows para qualquer outro SGBD que disponibilize um driver ODBC (ver Nota 1).
soluçăo a ser descrita utiliza trechos de códigos do DBI-Link 1.0 (ver Nota 2), um conjunto de funçőes escritas em PL/Perl por David Fetter, membro do grupo de desenvolvimento do PostgreSQL. Como destino na replicaçăo, serăo usadas as versőes Express Edition (XE) de cada um dos tręs maiores SGBDs disponíveis no mercado: Microsoft SQL Server 2005, Oracle 10g, e IBM DB2 9, todos instalados na plataforma Windows x86 (32 bits). Será utilizada a versăo 8.1.5 do PostgreSQL no Windows como banco de dados de origem.
Nesta primeira etapa, trataremos exclusivamente da conexăo com outros SGBDs de dentro do PostgreSQL, utilizando para isso o DBI-Link. Antes disso, veremos como criar e executar scripts em Perl no Windows, como configurar fontes de dados ODBC e como utilizá-las através da biblioteca DBD do Perl.
Motivaçăo
Imagine a seguinte situaçăo: numa empresa existem diversas bases de dados corporativas, e em sistemas gerenciadores de bancos de dados distintos. Nela foi implementada uma soluçăo de data warehousing baseada num grande SGBD (Oracle, SQL Server ou DB2). Paralelamente, no mesmo cenário, atua um banco de dados transacional PostgreSQL. Algumas informaçőes contidas nesse banco de dados OLTP (ver Nota 3) precisam ser replicadas para o ambiente OLAP (ver Nota 4).
Achou um pouco utópico o cenário descrito acima? Entăo vejamos outro mais simples. Na empresa foram adquiridos separadamente diversos sistemas "fechados", que servem a áreas distintas. As informaçőes destes sistemas estăo hospedadas em SGBDs diferentes e independentes. Após algum tempo, surge a necessidade de um novo sistema, que será desenvolvido em PostgreSQL. Esse sistema poderá servir para alimentar tabelas antes estáticas nos bancos de dados dos outros aplicativos comprados.
Em grandes corporaçőes, esta heterogeneidade nos ambientes de bancos de dados é muito mais comum do que imaginamos. E este será o nosso desafio: integrar informaçőes de um banco de dados em PostgreSQL a outro SGBD qualquer.
Preparando o terreno para o camelo: Perl no Windows
Para criar funçőes na linguagem procedural PL/Perl no PostgreSQL, é preciso instalar as bibliotecas do Perl no sistema operacional em questăo. Para isso, baixe e rode o instalador do ActivePerl (http://www.activestate.com/store/activeperl/ ) para Windows. Ao término da instalaçăo, abra o gerenciador de pacotes do Perl, clicando no menu Iniciar → Programas → ActiveState ActivePerl → Perl Package Manager. Será preciso instalar os seguintes pacotes:
- DBI (http://dbi.perl.org/): interface independente de banco de dados para o Perl;
- DBD-ODBC (http://www.annocpan.org/dist/DBD-ODBC/): driver ODBC para a DBI.
Veja que existem diversas possibilidades de fontes de dados para a DBI no Perl. Além disso, estăo disponíveis drivers de módulos DBI específicos para alguns SGBDs, como:
- DBD-ADO: driver DBI para Microsoft ADO (Active Data Objects);
- DBD-mysql: driver MySQL para a DBI;
- DBD-Oracle: driver Oracle para a DBI;
- DBD-SQLite: pequeno e rápido motor de banco de dados SQL embutido;
- DBD-Sybase: driver Sybase para a DBI;
- DBD-XBase: leitura e escrita em arquivos XBase (dbf), incluindo suporte ŕ DBI.
E como se năo bastasse, também temos ŕ disposiçăo os seguintes pacotes:
- DBD-AnyData: acesso via DBI para XML, CSV e outros formatos de arquivos;
- DBD-Excel: classe para drivers DBI que atuam em arquivos do Excel;
- DBD-Google: torna o Google uma fonte de dados para a DBI;
- DBD-Proxy: módulo para conectar-se a um banco de dados num driver DBI remoto (via proxy).
Assim, com toda essa parafernália de interfaces disponíveis para o Perl, podemos acessar praticamente qualquer fonte de dados a partir do PostgreSQL. Além de consultar e gravar em qualquer outro SGBD, podemos facilmente gerar planilhas do Excel ou fazer pesquisas no Google de dentro do PostgreSQL, e via instruçăo SQL!
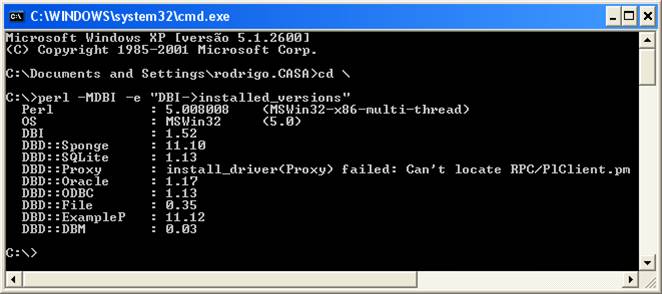
Em seguida, testaremos as interfaces DBI disponíveis para o Perl. Abra o "Prompt de comando" do Windows (menu Iniciar ŕ Executar ŕ digite o comando "cmd") e execute o comando da Listagem 1. Veja na Figura 1 o resultado. Se aparecer a entrada "DBD::ODBC", significa que já podemos fazer em Perl uma conexăo a um banco de dados via driver ODBC.
perl -MDBI -e "DBI->installed_versions"
Configurando e testando as conexőes ODBC
Nos bancos de dados de destino, crie um usuário com permissőes de conexăo, criaçăo de objetos como tabelas e índices (instruçőes DDL) e de consulta e manutençăo dos dados (instruçőes DML). Para acompanhar o artigo, é sugerida a criaçăo de um usuário chamado "postgres" com a senha "postgres".
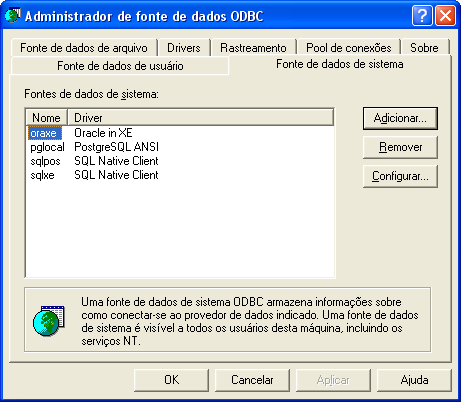
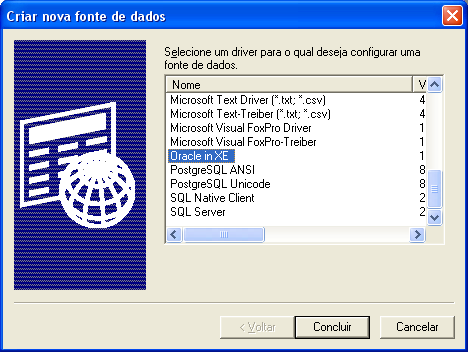
O próximo passo é configurar as fontes de dados ODBC no Windows para os SGBDs proprietários. Caso o servidor de banco de dados esteja alocado em outra máquina, será preciso ao menos instalar o software cliente. Abra o "Administrador de fonte de dados ODBC" do Windows (Painel de Controle → Ferramentas administrativas → Fontes de dados (ODBC)) e clique na guia "Fonte de dados de sistema" (ver Figura 2). A partir dessa tela, configure as conexőes desejadas aos bancos de dados de destino (ver Figura 3).
Para cada SGBD existem opçőes específicas para a conexăo via ODBC. Apesar disso, será preciso preencher as seguintes informaçőes: DSN (ou nome da fonte de dados), servidor (endereço IP ou nome do servidor, podendo ser "localhost" caso esteja na mesma máquina), porta (caso năo seja a default, que é diferente para cada SGBD) e, eventualmente, nome do banco de dados inicial.
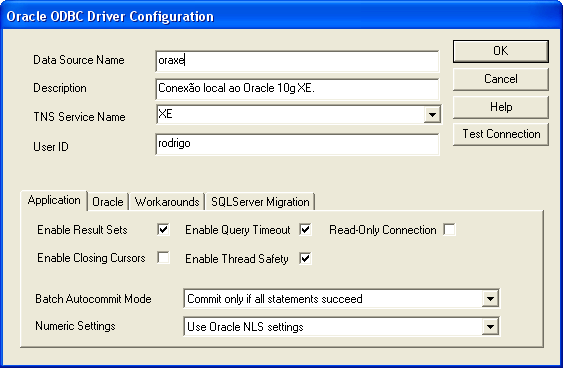
Na Figura 4 configuramos uma conexăo ao Oracle 10g Express Edition rodando localmente. Podemos testar a conexăo recém-criada clicando no botăo "Test Connection".
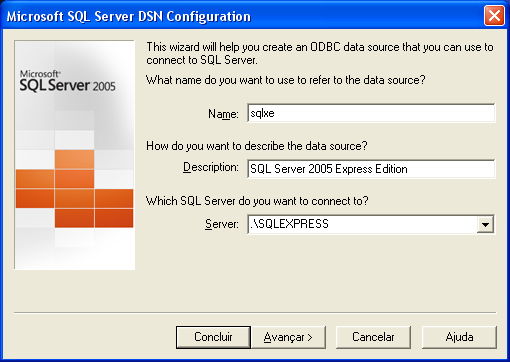
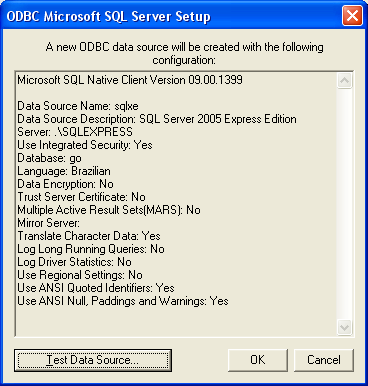
Nas Figuras 5 e 6 vemos como configurar uma conexăo ao Microsoft SQL Server 2005 Express Edition no servidor local. Clicando no botăo "Test Data Source...", podemos verificar se a conexăo é válida.
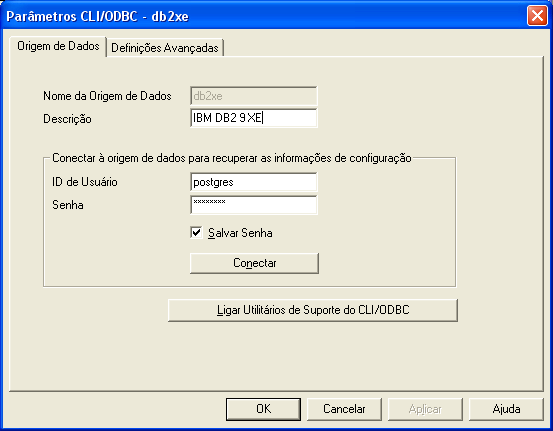
Para finalizar, a Figura 7 exibe a configuraçăo do driver ODBC para o IBM DB2 9 Express Edition. Clicando no botăo "Conectar" podemos testar a validade da conexăo.
Tudo pronto? Ainda năo. Antes de embrenhar no ambiente do PostgreSQL, faremos alguns testes em Perl de conexăo via ODBC ŕs fontes de dados que acabamos de criar.
Primeiros testes com Perl e ODBC
Nos SGBDs de destino, rode o script com instruçőes SQL contidas na Listagem 2. Ele criará uma tabela chamada NOVA contendo dois campos, e em seguida incluirá tręs registros nela. A instruçăo DDL funcionará sem problemas para todos os SGBDs em questăo e em qualquer ferramenta.
CREATE TABLE nova ( id int NOT NULL PRIMARY KEY, nome varchar(50) NOT NULL ); INSERT INTO nova VALUES (1, 'primeiro'); INSERT INTO nova VALUES (2, 'segundo'); INSERT INTO nova VALUES (3, 'terceiro'); SELECT * FROM nova;
A tabela tem uma estrutura bem simples, e serve apenas para efeitos de teste. Agora abra aquela poderosa ferramenta do Windows, o Bloco de Notas, digite o texto contido na Listagem 3 e salve o arquivo como "conectar.pl". Ele é um script em linguagem Perl que efetua a conexăo ao banco de dados via ODBC, exibe o nome e a versăo do SGBD e executa uma consulta SQL ŕ tabela NOVA.
CREATE TABLE nova ( id int NOT NULL PRIMARY KEY, nome varchar(50) NOT NULL ); INSERT INTO nova VALUES (1, 'primeiro'); INSERT INTO nova VALUES (2, 'segundo'); INSERT INTO nova VALUES (3, 'terceiro'); SELECT * FROM nova;...







