n=left>
Clique aqui para ler todos os artigos desta ediçăo
Replicaçăo e alta disponibilidade no PostgreSQL
Carlos Eduardo Smanioto
Neste artigo introdutório iremos falar sobre algo que é de grande utilidade para os desenvolvedores e DBAs: múltiplas instâncias do nosso banco de dados para alta disponibilidade, backup ou migraçăo de versăo no-downtime (sem queda do oferecimento da informaçăo). Estas săo algumas vantagens da replicaçăo com alta disponibilidade.
Neste primeiro artigo vamos explorar o Slony, um software de replicaçăo que em conjunto com outras ferramentas do Linux se torna um forte aliado na alta disponibilidade de servidores PostgreSQL.
Como nas outras vezes, este artigo exige um pouco de conhecimento de instalaçăo do PostgreSQL a partir do código fonte. Foi explicado algo sobre isso nos artigos de tuning do PostgreSQL no Linux (ediçőes 12, 14 e 19 da SQL Magazine).
Entendendo o que é replicaçăo
É a cópia (transmissăo) de informaçőes de uma ou mais bases de dados para outra estrutura semelhante. No caso dos SGBDs, é a duplicaçăo de uma determinada “açăo” em base de dados separadas logicamente e/ou geograficamente. Em outras palavras, replicaçăo é a sincronizaçăo de açőes de um SGBD em duas ou mais bases de dados com a mesma estrutura, podendo ser na mesma máquina replicando com ela mesma (separadas logicamente) ou em máquinas distintas (separadas por pontos geográficos).
Toda sincronizaçăo é realizada no instante em que a informaçăo se torna consistente no SGBD. Quando isso acontece, podemos ter dois tipos de sincronizaçăo: síncrona e assíncrona.
Replicaçăo síncrona (sincronizada)
Neste tipo de sincronizaçăo, a replicaçăo da açăo é feita instantaneamente. Se alguma cópia do banco é alterada, essa alteraçăo será imediatamente aplicada a todos os outros bancos dentro da transaçăo. A replicaçăo síncrona é apropriada em aplicaçőes comerciais onde é exigido um nível de atualizaçăo muito preciso em todos os servidores envolvidos.
Desvantagem
Existem algumas desvantagens neste tipo de replicaçăo. Mas, dentre as principais, podemos citar:
· Perda sensível da performance;
Uma das grandes explicaçőes para isso é que ao executar uma açăo na base “central”, ela irá instantaneamente replicar para as demais dentro da mesma transaçăo do usuário, ou seja, a açăo năo retorna o “ok final” para o usuário que executou a açăo sem que as demais bases estejam atualizadas. Veja o exemplo na Listagem 1.
# Cliente executando um insert:
Insert into teste(1,2,3);
#SGBD replicando o comando no modelo síncrono:
Begin
Insert into teste(1,2,3);
Replicar();
end;
Listagem 1. Representaçăo de replicaçăo síncrona.
Replicar() é um comando de replicaçăo interno hipotético. O importante é imaginar aqui que o cliente fica esperando o “end.” da transaçăo para obter novamente o controle da aplicaçăo. Isso porque a maioria das ferramentas de replicaçăo síncrona utiliza triggers para chamar o agente replicador.
· Exige um meio de transmissăo de dados de alta velocidade com padrăo de qualidade superior ao modelo de replicaçăo assíncrona;
Como dá para imaginar, o sucesso deste modelo exige métodos de transmissăo de dados de grande eficácia e eficięncia. Dificilmente será possível, por exemplo, utilizar uma assinatura ADSL “padrăo” oferecido pelas empresas de telefonia brasileiras. Serăo necessários serviços específicos e, dependendo muito do “volume diário de dados replicado”, uma grande quantidade de banda.
Replicaçăo assíncrona (năo sincronizada)
Neste modelo a replicaçăo năo é instantânea. O replicador monta um histórico das açőes a serem replicadas e em um determinado momento é feita a replicaçăo entre as bases de dados relacionadas. A alteraçăo será propagada e aplicada para outra base em um segundo passo, dentro de uma transaçăo separada. Esta poderá ocorrer em segundos, minutos, horas ou até dias depois, dependendo da configuraçăo pré-estabelecida.
Desvantagem
· Consumo de recursos das máquinas envolvidas acima do normal no momento da replicaçăo;
Isso é um fator negativo, pois o SGBD perde o poder de resposta nos momentos que está replicando. Logicamente, esta é uma verdade apenas para grandes volumes de dados.
· As informaçőes nas máquinas envolvidas năo estarăo o tempo todo atualizadas.
Este é um dos grandes problemas da replicaçăo, as máquinas envolvidas na replicaçăo ficarăo desatualizadas até que o processo de replicaçăo seja iniciado.
Soluçőes de replicaçăo no PostgreSQL
Vamos estudar um pouco de cada soluçăo de replicaçăo. Conhecer cada ferramenta é importante no mundo open source devido ao amadurecimento rápido (ou ŕs vezes demorado) do código. O que há em comum nas ferramentas que serăo aqui apresentadas é que săo recém nascidas, mas muito poderosas.
PgCluster
O primeiro a analisarmos rapidamente é o PgCluster. O grande diferencial deste sistema é a replicaçăo baseada na query, ou seja, o cliente executa uma instruçăo SQL e esta instruçăo pode ser executada nos demais clusters. Abaixo alguns pontos sobre o produto:
· Replicaçăo síncrona incluindo balanceamento de carga;
· Pode ser encontrado em http://pgcluster.projects.postgresql.org;
· Năo se tem conhecimento da estabilidade e desempenho.
PgPool
PgPool é um connection pool server para PostgreSQL, ou seja, é uma camada entre o cliente (front end) e o servidor (back end). Assemelha-se com o PgCluster porém, como Pool, faz caches das conexőes com o PostgreSQL reduzindo o overhead e aliviando assim o banco. É possível também usá-lo para prover alta disponibilidade já que o pgpool foi projetado năo somente para fazer cache, mas também replicaçăo. Veja abaixo algumas de suas possíveis implementaçőes:
· Implementa Pool de conexăo sem alterar a aplicaçăo cliente;
· Balanceamento de carga;
· Cache de conexőes;
· Replicaçăo síncrona;
· Transfere as conexőes para um segundo servidor caso o primeiro caia;
· Pode ser encontrado em http://pgpool.projects.postgresql.org/.
pgReplicator
pgReplicator é uma ferramenta de replicaçăo assíncrona. O pgReplicator é baseado na linguagem procedural interpretada TCL com o PostgreSQL como contęiner. Como características do produto, posso citar:
· “Armazena e encaminha” – replicaçăo assíncrona (via script.sql);
· Projeto parado;
· Pode ser encontrado em http://pgreplicator.sourceforge.net.
Daffodil Replicator
Daffodil Replicator é um software de replicaçăo com suporte bidirecional (Figura 1): sincronizaçăo de todas as mudanças feitas pelos subscritores (Slave) e pelo publisher (master) periodicamente ou on-demand (quando necessitar das informaçőes). Para resolver conflitos, săo predefinidos algoritmos entre o publisher e os subscritores. A replicaçăo bi-direcional é usada, por exemplo, em uma rede de lojas no qual existe a necessidade de compartilhamento de informaçőes. O grande diferencial do Daffodil Replicator é a replicaçăo de SGBDs heterogęneos/homogęneos. Ele permite a replicaçăo entre Oracle, SQL Server, DB2, Daffodil DB, PostgreSQL e Derbv (Figura 2).
O Daffodil Replicator é baseado no conceito de “Publish and Subcribe” (na arquitetura cliente servidor). O publish é a coleçăo de uma ou mais tabelas necessárias para a replicaçăo. Já o subscription é a cópia das tabelas envolvidas no publish em uma camada cliente. Basicamente podemos dizer que o publish é o MASTER e o subscribe é o SLAVE.
Na Figura 2, vemos o servidor Publisher (MASTER), que pode ser um Oracle, SQL Server, PostgreSQL, Daffodil DB, Derby, enviando dados para todos os servidores subscriber (Slave). Observe que cada servidor possui uma API Daffodil. No caso dos Subscriber, a API CLIENT e no Publisher, a API MASTER. Outro ponto que vale destacar é que cada Subscriber está usando um SGBDs diferente.
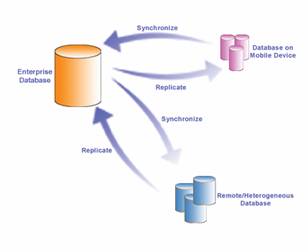
Figura 1. Diagrama da replicaçăo do Daffodil Replicator.
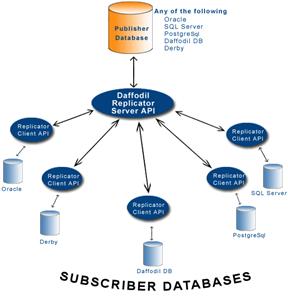
Figura 2. Diagrama de funcionamento da API Java do Daffodil Replicator.
Dentre as características do Daffodil Replicator, posso citar:
· Replicaçăo entre os principais SGBDs do mercado;
· Replicaçăo bidirecional (Figura 1);
· Desenvolvido em JAVA (Figura 2);
· Pode ser encontrado em http://www.daffodildb.com/replicator/dbreplicator.html.
Slony - I
Slony-I é um software de replicaçăo que segue o modelo “master para múltiplos slaves” com “cascateamento” de slaves e failover. Isto significa que no caso da queda de um MASTER, um dos SLAVEs assume como novo MASTER e caso um dos SLAVEs responsável pela transmissăo dos dados para outros SLAVEs também “caia”, o SLONY-I pode usar uma rota alternativa (Figuras 3 e 4). Vejamos a baixo algumas características do SLONY - I:
· Replicaçăo Master para múltiplos Slaves (Figura 3);
· Replicaçăo assíncrona;
· É possível criar vários níveis de Slave (Figura 3);
· Mecanismo para promover um Slave para um Master se este cair (Figura 4);
· Backup e point-in-time;







