Neste artigo iremos fazer uma introduçăo ao DB2 – este poderoso banco de dados que infelizmente ainda é muito desconhecido aqui no Brasil, tendo em contrapartida um mercado de trabalho destinado a DBAs bastante aquecido. O DB2 năo é um sistema de difícil administraçăo. Ele dispőe de muitas ferramentas para a administraçăo do banco, como o Control Center. O DB2 conta ainda com o tradicional Command Line Editor para a operaçăo via linha de comando.
O Control Center e o Command Line Editor estăo disponíveis nas versőes Windows, Linux e Unix do DB2.
Instalaçăo
A instalaçăo do DB2 é muito simples, existem apenas alguns detalhes a serem vistos durante a instalaçăo.
A versăo que eu utilizo é Personal Edition, que tem as mesmas funcionalidades de outras versőes maiores do DB2, mais com o fator de ser uma versăo para single-user, ou seja, ela năo permite que várias pessoas se conectem remotamente nele, é uma versăo ideal para desenvolver e estudar o DB2.
Figura 1: Instalaçăo
Ao iniciar a instalaçăo, a primeira coisa com que nos deparamos é com uma lista de pré-requisitos para instalaçăo do produto. O item de Instalation Pre-requisites pode ser visto como curiosidade para conhecermos os pré-requisitos de hardware e software necessários para utilizaçăo ideal do DB2 (ver Figura 1).
Siga a instalaçăo normalmente até chegar ŕ seleçăo de tipo de instalaçăo (ver Figura 2). Nesta tela, apenas escolha a instalaçăo Typical, mas selecione o Additional functions Data warehousing que vai servir para ativar o suporte a Data warehousing no DB2.
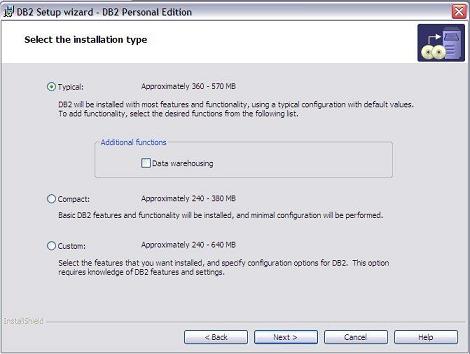
Figura 2: Adicionar Datawarehousing
Na próxima tela (ver Figura 3) informamos o usuário e senha a ser utilizado pra inicializaçăo do DB2. Este usuário será também o usuário interno dele, aqui, temos que informar um usuário e senha local já existente na sua maquina.
Vale ressaltar aqui alguns detalhes sobre a definiçăo da senha. Esta deve ser uma senha válida para o DB2, ou seja, tem que seguir as seguintes regras:
- conter entre 1 a 30 caracteres;
- incluir letras, números, @, #, ou $;
- năo pode começar com IBM, SYS, SQL, ou um número;
- năo pode ser uma palavra reservada do DB2 (USERS, ADMINS, GUESTS, PUBLIC, LOCAL), ou uma palavra reservada de SQL;
- năo pode terminar com $;
- năo pode incluir caracteres acentuados.
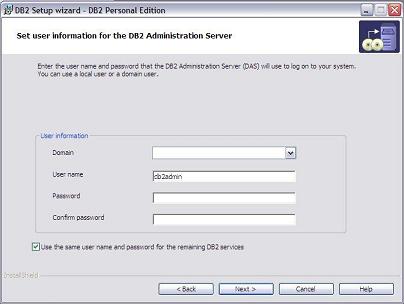
Figura 3: Usuário e senha
Agora siga normalmente a instalaçăo até chegar ŕ tela mostrada na Figura 4. Ela apresenta informaçőes sobre o Health Monitor. Este irá verificar se o DB2 esta “saudável”, rodando corretamente, etc. Caso algo aconteça com o DB2, como travar ou cair por algum motivo, será enviado um e-mail para a pessoa especificada nestes campos informando a situaçăo do banco. Na nossa instalaçăo podemos ou preencher o campos com algum dado ou, como na Figura 4, escolher a segunda opçăo para preenche-los depois. Agora é só continuar a instalaçăo até o fim.
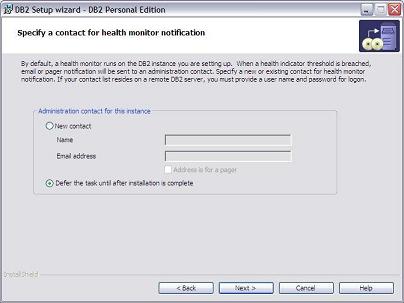
Figura 4: Health Monitor
Algumas informaçőes adicionais, inclusive versőes de avaliaçăo podem ser encontradas no site http://www.ibm.com/software/data/db2/ para download gratuito.
Procedimento pós-instalaçăo
Ao final da instalaçăo do DB2, o sistema pergunta se usuário deseja criar um banco de dados e um data warehouse como exemplos. Esta etapa normalmente passa despercebida pelo usuário. Portanto, năo se preocupe! Mesmo que vocę năo tenha percebido a ferramenta First Steps (Figura 5), é possível fazer a criaçăo dos exemplos posteriormente através dos seguintes passos:
- Abra o First Steps, que fica no menu de Iniciar / Programas / IBM DB2 / Set-up Tools / First Steps.
- Clique em Create Sample Databases. Logo em seguida selecione DB2 UDB sample e Data Warehousing sample.
- Clicando neles aparecerá a tela de login. Entre como usuário administrador, digitando a senha que foi criada durante a instalaçăo (o usuário padrăo chama-se db2admin).
O sistema procederá entăo com a criaçăo do banco de dados. Este processo pode levar até cinco minutos, em média. Agora, com o banco de dados de exemplo criado, vamos ver como é a sua estrutura utilizando o Control Center (Figura 6).
Figura 5: Tela do DB2 First Steps
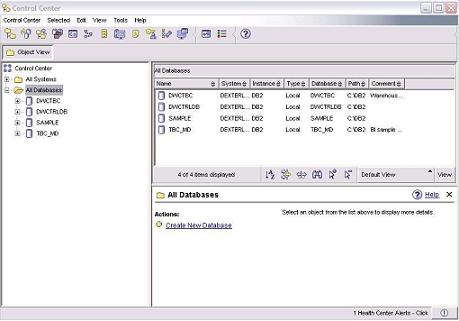
Figura 6: Tela do Control Center
Neste exemplo, os bancos de dados de exemplo que foram criados săo: DWCTBC e TBC_MD. Ambos estăo relacionados ao data warehouse SAMPLE que iremos analisar na terceira parte deste artigo.
Abrindo o database SAMPLE (o data warehouse de exemplo), vocę poderá verificar toda a estrutura associada a um banco de dados DB2. Atençăo particular deve ser dada ŕ estrutura de tabelas auxiliares que săo criadas. Estas tabelas auxiliares, também conhecidas como tabelas Catálogo, săo as tabelas internas que contęm todas as informaçőes criadas sobre tudo no DB2, como usuários, as tabelas criadas, índices, etc. Nas versőes de alta plataforma (MAINFRAME), a única forma de vocę conseguir, por exemplo, ver os índices criados em uma tabela é consultando a tabela SYSIBM.SYSINDEXES. Sendo assim, é muito importante conhecer e consultar sempre estas tabelas, pois elas săo de grande auxilio para um DBA e até mesmo para um desenvolvedor que utiliza DB2 como base de dados. Estas tabelas săo criadas utilizando um SCHEMA chamado SYSIBM. Este SCHEMA é basicamente o nome do usuário responsável pela criaçăo da tabela. Como veremos como proceder para a criaçăo de tabelas mais a fundo no próximo artigo, abordaremos melhor o assunto SCHEMAS também na próxima matéria já que este será muito utilizado na criaçăo de tabelas.
Criando o seu primeiro banco de dados
Vamos agora criar nosso primeiro banco de dados. Para isso usaremos o Control Center, embora a mesma operaçăo também possa ser realizada utilizando o Command Line Editor. Nossa opçăo se dá pela facilidade de uso dos assistentes de criaçăo do Control Center como veremos adiante. O código equivalente no Command Line Editor será exibido ao final do processo.
Passo 1
Antes de abrir o Control Center é necessário verificar se o DB2 esta ativo. Isto pode ser percebido através do ícone verde que fica no System Tray do Windows.
Para acessar a ferramenta Create Database, clique na pasta All Databases dentro do Control Center, e depois com o botăo direito do mouse, clique em Create Database | Standard. O primeiro passo será preencher o database name. Este deve possuir de 1 a 8 caracteres (que năo podem ser caracteres especiais). A mesma regra deve ser seguida para o Alias, que é um “apelido” pelo qual o banco de dados será reconhecido na rede, tanto local como remota. O ideal é usar o mesmo nome para o Alias, como apresentado na Figura 7.
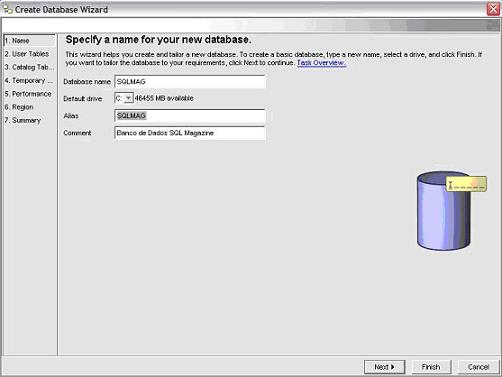
Figura 7: Tela Name do Database Wizard
Passo 2
Na segunda etapa examinaremos a forma de armazenamento e gerenciamento das tabelas no banco de dados. Existem dois tipos de gerenciamento de espaço para as tabelas: System-Managed Space (SMS) e DataBase-Managed Space (DMS).
Como o leitor já deve suspeitar, há vantagens e desvantagens que devem ser consideradas ao se optar por um tipo de gerenciamento para armazenar os dados.
Vantagens de um espaço de tabelas SMS (System-Managed Space):
- O espaço năo é alocado pelo sistema até que seja solicitado;
- A criaçăo de um banco de dados requer menos trabalho inicial do que o trabalho necessário para pré-definir os containers. Um container é uma localizaçăo física de armazenamento dos dados. Ele é associado a um espaço de tabela e pode ser um arquivo, diretório ou um dispositivo.
Vantagens de um espaço de tabelas DMS (Database-Managed Space):
- O tamanho de um espaço de tabelas pode ser aumentado pela adiçăo de containers utilizando a instruçăo ALTER TABLESPACE;
- Uma tabela pode ser dividida em múltiplos espaços com base no tipo de dados que estăo sendo armazenados: Campo extensor; Índices; Dados de tabela regular.
Num cenário provável, podemos ter a separaçăo dos dados da tabela por motivos de desempenho ou para aumentar a quantidade de dados armazenados para uma tabela. Por exemplo, uma tabela com 2 GB de dados de tabela regular, 2 GB de dados de índice e 10 TB de dados longos.
- A localizaçăo dos dados no disco pode ser controlada se o sistema operacional permitir;
- Se todos os dados da tabela estiverem em um único espaço de tabelas, um espaço de tabelas poderá ser eliminado e redefinido com menos sobrecarga do que o necessário para eliminar e redefinir uma tabela;
- Em geral, um conjunto bem afinado de espaços de tabela DMS supera os espaços de tabela SMS.
Prosseguimos com o nosso exemplo selecionando a opçăo SMS (ver Figura 8). Năo iremos ainda trabalhar com contęineres, assunto de um próximo artigo.
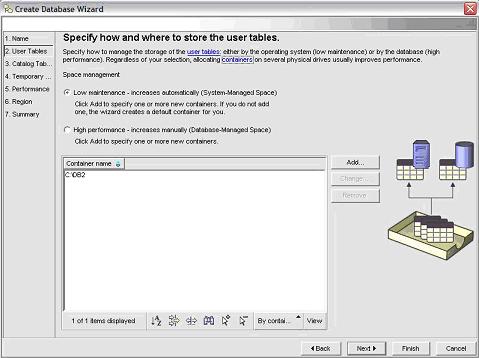
Figura 8: User Tables
Passo 2
Nesta etapa vamos examinar como será a forma de armazenamento das tabelas de catálogo do sistema. Seguiremos exatamente as mesmas regras da etapa anterior.
Catálogos do sistema săo tabelas especiais que contęm informaçőes sobre todos os objetos em um banco de dados. Eles incluem as tabelas, telas e índices, além de controles de segurança como restriçőes e níveis de autorizaçăo específicos para os bancos de dados. Estas tabelas de catálogo de sistema săo criadas no momento da criaçăo do banco de dados.
Quando um objeto é criado, alterado ou eliminado, o DB2 insere, atualiza ou exclui linhas do catálogo que descrevem o objeto e como este se relaciona a outros objetos. Os catálogos servem principalmente para fins de leitura, e săo mantidos pelo DB2. Além disso, esses dados estăo disponíveis para consulta, utilizando SQL.
Vamos especificar o container novamente como a pasta C:\DB2 e utilizar o gerenciamento SMS para este exemplo como mostra a Figura 9.
Figura 9: Armazenamento das tabelas de catalogo
Passo 4
Agora faremos algumas configuraçőes para a performance do banco de dados. Temos duas configuraçőes básicas: uma para deixar o DB2 atualizar o tamanho do tablespace automaticamente, e outra para especificar os tamanhos para os tablespaces.
Caso opte pela configuraçăo personalizada, vocę poderá especificar todos os tamanhos para o banco de dados.
O valor padrăo dos buffers atribuídos pelo DB2 é ideal para uma base de dados média de 25 MB até 250MB. Este range de valores é ideal para o exemplo exposto. Para bancos maiores, o DB2 também possui padrőes pré-definidos, sendo que estes valores podem ser alterados a qualquer hora no banco.
Para este exemplo, escolheremos a primeira opçăo “Allow DB2 to update table space preferch size automatically” como mostra a Figura 10.
Figura 10: Performance do banco de dados
Passo 5
Prosseguiremos com a escolha da localidade em que o banco de dados se encontra. Esta etapa também é importante năo só para a geraçăo de logs com o fuso horário correto, mas também para a compatibilizaçăo dos caracteres especiais. Exatamente nestes logs é que definimos a codepage do banco de dados, sendo que o padrăo para Brasil é o Code set 1252 (ver Figura 10).
É importante ressaltar que estes dados năo podem ser alterados depois da criaçăo do banco. Caso estas configuraçőes estejam erradas, será necessário excluir este banco de dados e criá-lo novamente.
Figura 11: Localizaçăo do banco de dados
Passo 6
Nesta etapa final, o DB2 exibe um sumário básico do que foi feito para a criaçăo do banco de dados. O botăo Finish finaliza o processo de criaçăo do banco de dados. É importante enfatizar que o código SQL para a criaçăo do banco de dados pode ser obtido pressionando-se o botăo Show Command (este SQL poderá ser executado pelo Command Line Editor).
Apresentamos abaixo o código SQL gerado pelo exemplo:
CREATE DATABASE SQLMAG ON 'C:' ALIAS SQLMAG USING CODESET 1252 TERRITORY BR WITH 'Banco de Dados SQL Magazine';Design Advisor
Logo após o término da criaçăo do banco de dados, o assistente do Design Advisor será exibido. O Design Advisor năo é obrigatório para o seu banco, contudo faremos um comentário breve a respeito.
A funçăo do Design Advisor é otimizar as cargas de trabalho do banco de dados. A carga de trabalho consiste no número de instruçőes SQL executadas contra um banco de dados. Cada instruçăo SQL na carga de trabalho recebe uma freqüęncia. O Design Advisor utiliza a carga de trabalho especificada para determinar quais índices serăo recomendados e criados. Com o Design Advisor podemos trabalhar os seguintes recursos:
Índices
Conceitualmente, um índice é uma ajuda de acesso a dados que pode ser criado em uma tabela. Fisicamente, ele é um conjunto ordenado de ponteiros para linhas em uma tabela.
Cada índice é baseado nos valores de dados de uma ou mais colunas em uma tabela, sendo que cada índice é um objeto separado dos dados na tabela. Quando um índice é criado, o gerenciador de banco de dados construirá a estrutura e a manterá automaticamente. A criaçăo de um índice atende aos seguintes fins:
- oferecer uma maneira rápida de localizar linhas em uma tabela baseada em seus valores nas colunas chave. Em alguns casos, todas as informaçőes necessárias para uma consulta poderăo ser encontradas no índice, tornando desnecessária a leitura da tabela;
- reforçar as regras de exclusividade, definindo uma coluna ou grupo de colunas como índice exclusivo ou chave principal;
- oferecer uma ordenaçăo lógica das linhas de uma tabela baseada nos valores de coluna chave;
- criar clusters das linhas de uma tabela no armazenamento físico de acordo com a ordem do índice definido.
Tabela de consulta materializada
As MQTs (Materialized Query Tables) constituem uma maneira poderosa de melhorar o tempo de resposta de consultas complexas, especialmente aquelas que possam envolver alguns dos seguintes itens:
- dados agregados em uma ou mais dimensőes;
- junçőes e dados agregados em um grupo de tabelas;
- dados de um subconjunto de dados comumente acessado, isto é, a partir de uma partiçăo horizontal ou vertical "ativa";
- dados reparticionados de uma tabela ou de parte de uma tabela em um ambiente de banco de dados particionado.
O conhecimento das MQTs é integrado ao compilador SQL. No compilador SQL, a fase de regravaçăo da consulta e o otimizador correspondem a consultas ŕs MQTs, e determinam se uma MQT deve ser substituída por uma consulta que acesse as tabelas básicas. Se uma MQT for utilizada, o recurso EXPLAIN poderá fornecer informaçőes sobre qual MQT foi selecionada.
Embora traga consigo alguns benefícios, é importante destacar também que as MQTs incorrem em custos para espaço de armazenamento e em sobrecarga envolvida nas atualizaçőes. Isto ocorre pois os dados de uma MQT săo armazenados de forma redundante: uma vez na MQT e outra na tabela ou tabelas básicas subjacentes. Isso significa que sempre que os dados das tabelas básicas forem atualizados, serăo necessárias duas atualizaçőes para REFRESH IMMEDIATE MQTs. Em uma carga de trabalho com muitas atualizaçőes, esse custo pode exceder os benefícios de desempenho de candidatos ŕ MQT.
Também haverá sobrecarga administrativa associada ŕs MQTs sempre que utilitários como LOAD, BACKUP, RESTORE ou RUNSTATS forem executados.
Para determinar se as MQTs oferecem vantagens significativas no desempenho, o Design Advisor considera os custos associados ŕs MQTs juntamente com as características da carga de trabalho especificada.
Multidimensional Clustering
O MDC (Multidimensional Clustering) permite fazer um cluster físico dos dados de uma tabela em mais de uma chave ou dimensăo, simultaneamente. Ele pode aprimorar significativamente o desempenho da consulta. Além disso, pode reduzir igualmente a sobrecarga da manutençăo de dados, como operaçőes de manutençăo de reorganizaçăo e índice durante as operaçőes de inserçăo, atualizaçăo e exclusăo. O Multidimensional Clustering é destinado principalmente para data warehousing em grandes ambientes de banco de dados, mas também pode ser utilizado em ambientes OLTP (Online Transaction Processing).
Antes da versăo 8, o DB2 UDB suportava apenas single-dimensional clustering de dados por meio do uso de índices de cluster. Utilizando um índice de cluster, o DB2 UDB tenta manter a ordem física de dados nas páginas na ordem principal do índice, conforme os registros săo inseridos e atualizados na tabela. Os índices de cluster aprimoram enormemente o desempenho das consultas de alcance que possuem predicados contendo a chave (ou chaves) do índice de cluster, visto que uma parte da tabela precisa ser acessada. Quando as páginas săo subseqüentes, uma pré-busca mais eficiente pode ser executada.
O MDC estende esses benefícios para mais de uma dimensăo ou chave de cluster. No caso do desempenho de consultas, as consultas de alcance que envolvam qualquer combinaçăo das dimensőes de tabelas especificadas se beneficiarăo com o cluster. Essas consultas năo irăo acessar apenas as páginas contendo registros com os valores corretos de dimensăo, como também essas páginas de qualificaçăo serăo agrupadas pelas extensőes. Além do mais, embora uma tabela com um índice de cluster possa ficar sem cluster com o tempo, conforme a tabela for sendo preenchida com espaços, uma tabela MDC pode manter seu cluster em todas as dimensőes automática e continuamente, eliminando assim a necessidade de reorganizar a tabela para restaurar a ordem física dos dados.
Embora traga consigo alguns benefícios, é importante destacar também que a implementaçăo das recomendaçőes de tabelas MDC requer a eliminaçăo e recriaçăo das tabelas, além da criaçăo de espaço de armazenamento adicional para armazená-las. Se tiver certeza de que năo deseja fazer isso, năo selecione esse recurso.
Até a próxima.







