Migrando do InterBase para o Firebird 1.5 no Linux e Estabelecendo Conexăo com Java
O Firebird é um gerenciador de banco de dados relacional open source e multi-plataforma desenvolvido por uma comunidade independente de programadores a partir do código fonte do InterBase 6.0, liberado pela Inprise Corp (hoje Borland Software Corp) sob a licença InterBase Public License V.1.0. É um banco de dados simples de ser instalado e manipulado, robusto, com alta performance e excelente suporte a triggers e stored procedures.
A versăo 1.0, lançada em meados de março de 2002, e demais da série 1.0.x, năo trouxeram muitas inovaçőes, destinando-se a uma extensa “limpeza” do código fonte, migraçăo de C para C++ e eliminaçăo de "bugs". A versăo 1.5 é a primeira a conter mudanças mais profundas como otimizaçăo de consultas e versőes de Classic Server e Embedded Server para windows, além desta ser a primeira versăo que servirá de base para o Firebird 2.
Neste tutorial, mostraremos como migrar de um banco InterBase para o mais novo Firebird 1.5 e como estabelecer conexőes a este banco através do Java. Como o Firebird 1.0 é um InterBase melhorado, todo o esquema de migraçăo também serve para quem quer migrar deste para a versăo mais recente do Firebird. As principais fontes de consulta săo os sites http://www.ibphoenix.com e http://firebird.sourceforge.net.
1 - Breve Histórico
O banco de dados “Groton Database System” (daí o nome dos utilitários começarem com “g”) que, por questőes evidentes de marketing, logo veio a se chamar InterBase, foi originalmente criado por Jim Starkey e Ann Harrison, em 1980, numa intrigante e destemida iniciativa[1] de criar um banco de dados simples, com pouca ou nenhuma necessidade de administraçőes sofisticadas, porém, robusto o suficiente para ser utilizado em aplicaçőes reais.
A Borland assumiu o desenvolvimento do Interbase em Outubro de 1991, o qual se encontrava na versăo 3. As principais contribuiçőes da Borland naquela época foram:
· implementaçăo de stored procedures,
· arquitetura SuperServer,
· versăo Windows e
· aumento da popularidade devido sua inclusăo nas suas ferramentas RAD.
O InterBase 6.0 tornou-se um produto open source em Julho de 2000, depois de inúmeros conflitos entre o time de desenvolvimento do InterBase e os executivos da Borland. Surge entăo a InterBase Company, formada pelos idealizadores do InterBase e seus colaboradores iniciais, com o objetivo de dirigir o novo projeto de software livre com respaldo da Borland. Aparentemente arrependida do que fez, a Borland forneceu, de muito mau grado, o código fonte do InterBase. Demorou semanas até que todas as partes do código estivessem disponíveis num único download. A comunidade de desenvolvedores do InterBase passou um bom tempo com a tarefa de concertar todas as partes faltantes do código fonte e também compreendendo como o InterBase funciona internamente para só entăo poder contribuir com melhorias.
Apesar de năo mais receber apoio da Borland, que restabeleceu o desenvolvimento comercial do InterBase, a comunidade de software livre rapidamente organizou o projeto denominado Firebird, na sourceforge.net, com o intuito de dar continuidade ao desenvolvimento baseado no código fonte do InterBase 6.0.
2 - Instalaçăo no Linux
Antes de fazer qualquer instalaçăo é necessário decidir sobre qual arquitetura vocę pretende utilizar. Existem dois modelos: a arquitetura Classic e a SuperServer. A Classic, remanescente da versăo 4 do InterBase, é baseada em processos, isto é, para cada conexăo cliente um novo processo servidor é disparado para atendę-la. Cada processo é totalmente independente e possui um cache de memória dedicado. A arquitetura SuperServer é uma implementaçăo multi-cliente e multi-tarefa que substitui a implementaçăo clássica. Um servidor SuperServer pode atender vários clientes ao mesmo tempo usando threads ao invés de processos separados. Múltiplas threads compartilham o acesso a recursos compartilhados de um único processo servidor. Para maiores informaçőes técnicas a respeito das diferenças entre as arquiteturas Classic e SuperServer veja em http://www.ibphoenix.com/main.nfs?a=ibphoenix&page=ibp_ss_vs_classic.
A arquitetura Classic é mais limitada e destina-se especialmente a plataformas que năo suportam processamento através de threads. Sendo assim, mostraremos como instalar a opçăo SuperServer do Firebird 1.5 no Linux, tendo em vista este prover suporte nativo a aplicaçőes multi-tarefas. Supondo que a instalaçăo será feita num Linux box com glibc igual ou superior a 2.2.5 e libstdc++.so igual ou superior a 5.0 (rpm –qa | grep para descobrir), os passos săo estes:
- Instalaçăo via pacote RPM:
- Baixar a última versăo do pacote FirebirdSS-1.5.X-xxxx.i686.rpm no endereço http://firebird.sourceforge.net/index.php?op=files&id=engine. Durante a confecçăo deste material a área de dowload encontrava-se da seguinte forma:
· 25th December 2004 SuperServer for Linux V1.5.2 (.rpm) (3.0mb)
· 25th December 2004 SuperServer for Linux V1.5.2 (.tar.gz) (2.8mb)
- Como root, executar: rpm -ivh FirebirdCS-1.5.X-xxxx.i686.rpm
2. Instalaçăo através de tar.gz:
- Baixar a última versăo do arquivo FirebirdSS-1.5.X-xxxx.tar.gz
- Como root, executar:
tar –zxvf FirebirdSS-1.5.X-xxxx.tar.gz
cd FirebirdSS-1.5.X-xxxx.i686
./install.sh
O que o instalador faz é:
- Termina qualquer processo servidor ativo.
- Adiciona o usuário firebird e o grupo firebird.
- Instala o programa no diretório /opt/firebird, copia libs (libfbclient, libgds e libib_util) e cria links simbólicos no diretório /usr/lib e copia arquivos de cabeçalho no diretório /usr/include.
- Adiciona automaticamnete a porta 3050 no /etc/services.
- Adiciona automaticamnete a entrada localhost.localdomain and HOSTNAME ao /etc/hosts.equiv.
- A instalaçăo SuperServer também instala um script de inicializaçăo no /etc/rc.d/init.d.
- Inicializa o servidor.
- Gera uma password para o usuário SYSDBA e a armazena no arquivo /opt/firebird/SYSDBA.password.
Pronto!! Se nenhum erro ocorreu vocę já tem uma versăo rodando do servidor Firebird 1.5 na sua máquina. Para testar vocę pode utilizar o programa isql existente no diretório /opt/firebird/bin o qual permite conectar em um banco de dados e realizar consultas. Para maiores informaçőes, vide o diretório /opt/firebird/doc. Lembre-se que a password do usuário SYSDBA foi gerada aleatoriamente pelo instalador. Para alterá-la vocę pode usar o script changeDBAPassword.sh localizado em /opt/firebird/bin.
3 - Desinstalaçăo
- Para pacotes RPM:
- rpm -e FirebirdSS-1.5.X.xxxx-0
- Para instalaçăo via tar.gz:
- /opt/firebird/bin/uninstall.sh
4 - Migrando um banco do Interbase para o Firebird
Para migrar um banco do Interbase ou mesmo do Firebird 1.0.X para o Firebird 1.5 os passos săo os seguintes:
- Faça um backup, utilizando o utilitário gbak da sua instalaçăo do InterBase, do banco de dados que pretende migrar. Para isso, entre como root na máquina onde o banco a ser migrado se encontra e execute o comando:
gbak –b –v nome_banco_origem.gdb nome_banco_destino.gbk
- Recupere este backup utilizando o gbak do Firebird 1.5. Como root, execute:
gbak -C -v -r -n -i nome_backup.gbk nome_destino.fdb
Uma operaçăo de backup e recuperaçăo em geral melhora a performance do banco de dados pois elimina registros expletivos, balanceia os índices, recupera espaço liberado por registros deletados e realiza a atualizaçăo do ODS (on-disk structure) caso seja necessário. A sintaxe completa dos comandos para backup e recuperaçăo pode ser obtida no Operations Guide constante no conjunto de documentaçăo da instalaçăo do InterBase para windows ou no site
http://firebird.sourceforge.net/download.php?op=file&id=Firebird_v1_ReleaseNotes_Pt.pdf
5 - O driver JDBC JayBird
O JayBird (http://jaybirdwiki.firebirdsql.org/JayBirdHome) é um driver JCA/JDBC para conexăo com o banco de dados Firebird. Este baseia-se no novo padrăo JCA para conexăo de servidores de aplicaçăo a sistemas legados e banco de dados e também no padrăo JDBC. O padrăo JCA especifica uma arquitetura onde um servidor de aplicaçăo pode cooperar com um driver de tal forma que este gerencie transaçőes, segurança, pool de conexőes e outros recursos e o driver provę apenas a funcionalidade de conexăo.
O novo JayBird 1.5 traz algumas melhorias e inovaçőes:
- Além da implementaçăo do tipo JDBC 4, este driver implementa também o tipo 2 e uma versăo embedded server, a qual permite criar aplicaçőes com todos os requisitos para conexăo a um servidor embutida na própria aplicaçăo.
- Suporte para IN e OUT stored procedures. O JayBird 1.0 provia suporte apenas a parâmetros IN enquanto esta nova versăo implementa todos os requisitos também a parâmetros OUT.
- Nova infraestrutura para pool de conexőes e prepared statements.
O tipo JDBC 4 é uma implementaçăo totalmente em Java que converte chamadas JDBC diretamente para o protocolo utilizado pelo banco de dados. Esta difere da implementaçăo de tipo 3, que converte uma chamada para um protocolo independente que depois é convertida, por um servidor intermediário, para o protocolo específico do banco em questăo. Enquanto o tipo 4 é preferido para configuraçőes onde o cliente localiza-se numa máquina diferente da do servidor, sua performance é prejudicada quando as conexőes săo feitas ao servidor Firebird a partir da mesma máquina onde este se encontra. Isto deve-se ao fato que o tipo JDBC 4 utiliza sockets para realizar conexőes, introduzindo um overhead adicional. Quando a comunicaçăo com o servidor de banco de dados será efetuada a partir da mesma máquina onde este está instalado, como pode ser o caso de aplicaçőes web em Java onde o container web roda na mesma máquina do banco de dados, é preferível utilizar o tipo JDBC 2. Este, utiliza uma biblioteca nativa JNI para efetuar as conexőes, possibilitando uma performance superior pois acessa o banco de dados diretamente.
Um pool de conexőes provę um meio de gerenciar e manipular conexőes a bancos de dados. Sua principal utilidade é minimizar o tempo necessário para uma aplicaçăo obter uma conexăo a um banco, tendo em vista que, em geral, esta é uma operaçăo que consome considerável tempo. Além disso, outras vantagens săo:
- Gerenciamento do número limite de conexőes. Uma aplicaçăo năo pode abrir mais conexőes do que o permitido pelo pool.
- Centralizaçăo do lugar onde conexőes a bancos de dados serăo obtidas.
- Possibilidade também de fazer pool de prepared statements.
Um prepared statement é uma instruçăo SQL compilada e otimizada apenas uma vez para ser utilizada várias vezes por uma aplicaçăo, reduzindo assim o tempo de execuçăo quando esta se encontra, por exemplo, num loop. Porém, o que acontece quando precisamos utilizá-la durante o ciclo de vida de um objeto? Devemos criar uma conexăo dedicada ao objeto, já que um prepared statement é intrinsecamente relacionado ŕ conexăo que o criou, ou preparar um cada vez que for necessário utilizá-lo? As duas opçőes săo insatisfatórias, a primeira por ser inviável no sentido de consumir uma conexăo para cada objeto instanciado que faz uso de prepared statement e a segunda por perder a principal vantagem que é a possibilidade de reutilizaçăo de consultas já compiladas e otimizadas.
Um pool de prepared statements resolve estes problemas. Veja o exemplo abaixo:
1 Connection connection = dataSource.getConnection();
2 try {
3 PreparedState ent ps = connection.prepareState ent(
4 “SELECT * FROM test_table WHERE id = ?”);
5 try {
6 ps.setInt(1, id);
7 ResultSet rs = ps.executeQuery();
8 while (rs.next()) {
9 // faz alguma coisa
10 }
11 } finally {
12 ps.close();
13 }
14 } finally {
15 connection.close();
16 }
As linhas 1 a 16 apresentam um código típico quando um pool de prepared statements está sendo utilizado. A aplicaçăo obtém uma conexăo através de um javax.sql.DataSource, prepara uma consulta como se esta fosse ser usada pela primeira vez, seta os parâmetros e a executa. A criaçăo do prepared statement na linha 3 é interceptada pelo pool o qual verifica se existe um prepared statement livre para o SQL especificado. Caso năo exista, um novo é criado. Na linha 12, o prepared statement năo é fechado mas sim devolvido ao pool. O mesmo acontece com a conexăo na linha 15.
5.1 – Instalando o driver e obtendo conexőes através do pool
Para instalar o driver JDBC JayBird 1.5 vocę deve:
- baixá-lo da página http://jaybirdwiki.firebirdsql.org/download/Downloads,
- descompactar o arquivo,
- copiar os .jar no diretório de bibliotecas do servidor web e NĂO no diretório WEB-INF da aplicaçăo.
Pronto!! A partir daí vocę já pode fazer uso das classes para obter uma conexăo a um servidor de banco de dados Firebird. Para quem estava acostumado ŕ instalaçăo do InterClient para conexăo ao Interbase onde fazia-se necessário a instalaçăo do programa interserver que roda em baixo do xinetd escutando os pedidos de conexăo na porta 3060, a instalaçăo do JayBird é muito mais simples. Uma vez que o servidor Firebird tenha sido instalado, o serviço gds_db é configurado por padrăo para ouvir a porta 3050. E, a năo ser que vocę precise alterar este valor de porta (o que pode ser feito editando-se o arquivo /etc/services), nada mais precisa ser feito e o JayBird irá se comunicar com o servidor através desta porta .
Mostraremos agora como obter uma conexăo usando o driver JDBC tipo 4 e tipo 2. Para conexăo usando embedded server vide seçăo 5.4.
Conexăo no modo JDBC 4
Como vimos, este é o driver puro Java que deve ser preferencialmente utilizado quando a estaçăo cliente localiza-se numa máquina distinta do servidor Firebird. A URL para conexăo é a seguinte:
jdbc:firebirdsql:host[/port]:/path/to/db.fdb
Como exemplo, veja o código abaixo que utiliza o pool de conexőes do JayBird:
public final class DataSourceExample
{
static public void main (String args[]) throws Exception
{
//Criando um DataSource manualmente
org.firebirdsql.pool.FBWrappingDataSource dataSource =
new org.firebirdsql.pool.FBWrappingDataSource();
//Configurando os parâmetros principais
dataSource.setDatabase("localhost/3050:c:/database/employee.gdb");
//Configurando parâmetros adicionais
dataSource.setCharSet(interbase.interclient.CharacterEncodings.NONE);
dataSource.setSuggestedCachePages(0);
dataSource.setSweepOnConnect(false);
//Isto năo precisa tendo em vista que a URL já identifica o tipo
dataSource.setType("TYPE4");
//parâmetros específicos do banco năo possuem métodos sertters
dataSource.setNonStandardProperty("isc_dpb_sweep", null);
dataSource.setNonStandardProperty("isc_dpb_num_buffers", "75");
try {
dataSource.setLoginTimeout(10);
java.sql.Connection c = dataSource.getConnection("sysdba",
"masterkey");
System.out.println ("conexăo estabelecida");
c.close ();
}
catch (java.sql.SQLException e) {
e.printStackTrace();
System.out.println ("sql exception: " + e.getMessage ());
}
}
}
Conexăo no modo JDBC 2
Estabelecer conexőes do tipo JDBC 2 requer a correta instalaçăo da biblioteca nativa JNI. Para isso, copie o arquivo libjaybird.so que consta no pacote de instalaçăo do JayBird para o diretório $JAVA_HOME/jre/bin. Uma vez feito isso, as conexőes podem ser obtidas como no exemplo anterior, porém, passando a URL com a sintaxe
jdbc:firebirdsql:native:host[/port]:/path/to/db.fdb
ou utilizando a URL do tipo 4 porém indicando que o tipo será 2 através do método dataSource.setType("TYPE2").
5.2 – Acessando um Data Source através de JNDI no JBoss
Para criar um alias JNDI apontando para um data source do Firebird no servidor de aplicaçőes JBoss, crie um arquivo chamado firebird-ds.xml com o seguinte conteúdo
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>nome_alias</jndi-name>
<connection-url>jdbc:host/3050:caminho_para_arquivo_fdb</connection-url>
<driver-class> org.firebirdsql.pool.FBWrappingDataSource</driver-class>
<user-name>SYSDBA</user-name>
<password>masterkey</password>
</local-tx-datasource>
</datasources>
e o copie no diretório deploy do tipo de servidor que vocę está usando (all, default, minimal, etc). Para acessar numa aplicaçăo o data source criado pode-se fazer
javax.naming.Context ctx = new javax.naming.InitialContext();
javax.sql.DataSource ds = (javax.sql.DataSource) ctx.lookup(“java:nome_alias”);
5.3 – Mais Informaçőes
Informaçőes detalhadas sobre o JayBird, suas classes, características específicas, utilizaçăo das diferentes versőes do driver, pool de conexőes, dentre outras podem ser obtidas no manual constante no diretório doc da instalaçăo.
6 – Ferramentas de Administraçăo
Uma lista com inúmeras ferramentas de administraçăo está disponível na página abaixo:
http://www.ibphoenix.com/main.nfs?a=ibphoenix&page=ibp_admin_tools
Algumas delas săo comerciais enquanto outras livres. Dentre estas, uma das mais promissoras é a FlameRobin (http://www.flamerobin.org/), uma ferramenta totalmente open source para administraçăo de bancos Firebird existente em várias plataformas. Apesar de ainda năo totalmente completa, já conta com várias funcionalidades úteis como execuçăo de comandos SQL, interface para backup, criaçăo e ediçăo de objetos do banco de dados, dentre outras. A Figura 1.0 mostra a tela principal extraída de sua execuçăo no Gnome ( Linux):
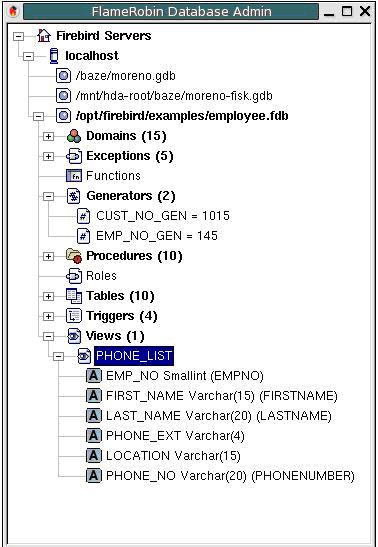
Figura 1.0: Tela principal do aplicativo FlameRobin
[1] Leia um pouco mais em http://firebird.sourceforge.net/index.php?op=history&id=ann_1







