O artigo é
útil principalmente para estudantes e profissionais de mineraçăo de dados, que
buscam uma ferramenta gratuita para implementaçăo e uso prático de algoritmos
que possam auxiliar na busca de respostas em bases de dados usando mineraçăo.
Autores: Adriano Geraldo Dias Ferreira e Larissa Pereira
A mineraçăo de dados é por definiçăo o método utilizado para a descoberta de conhecimento em grandes bases de dados, convencionais ou năo, e faz uso de algoritmos diversos, utilizando estatística e técnicas de inteligęncia artificial na busca de relaçőes de similaridade ou mesmo discordância entre dados.
O resultado final deste processo tem por objetivo principal descobrir informaçőes relevantes que possam auxiliar os gestores nas suas decisőes.
A tarefa de mineraçăo de dados pode ser vista como um processo de exploraçăo e análise, por meio automático ou semiautomático, de grandes quantidades de dados, com o objetivo de descobrir padrőes que sejam significativos.
Além disto, o processo de minerar dados possui duas vertentes principais, onde em uma delas se pretende “analisar o passado” e na outra “predizer o futuro”.
A mineraçăo de dados envolve vários objetos de estudo, combinando disciplinas tăo diversas quanto estatística, inteligęncia artificial, aprendizagem de máquina, banco de dados e data warehouse.
Na maioria das vezes, o processo de mineraçăo de dados possui um alto custo de implementaçăo, muitas vezes pelo tamanho do projeto proposto que precisa explorar volumosas bases de dados, acumuladas ao longo dos anos de operaçăo de uma empresa.
O início histórico da mineraçăo de dados acontece a partir dadécada de 90, com sua utilizaçăo em pesquisas científicas, com o interesse e crescimento evidenciado mais especificamente a partir de 1997, com cases e ocorręncias em grandes atacadistas, no mercado financeiro, governamental e industrial.
Vários tęm sido os motivadores para o uso comercial e científico da mineraçăo de dados em diferentes áreas de estudo e mesmo cięncias aplicadas.
Na área comercial, o uso da mineraçăo é evidenciado principalmente pelo crescimento no número de dados armazenados pelas empresas. Săo dados de compras e navegaçăo pela internet, dados de transaçőes bancárias, ou do uso de cartőes de crédito. Pode-se considerar também a pressăo por competiçăo nas empresas e o barateamento e potęncia cada vez maior dos computadores.
Para as cięncias, a coleta e armazenamento de dados a altas velocidades (Gb/hora) e os resultados da produçăo científica gerando terabytes de dados, provenientes de telescópios, sensores remotos em satélites, microarrays que podem gerar dados de expressőes de genes, sendo que muitas vezes as técnicas tradicionais năo săo hoje apropriadas para analisar tais dados, gerando ruídos e grande dimensionalidade nos resultados produzidos.
Se forem consideradas as leis, como motivadores para o desenvolvimento desta cięncia ainda temos a Lei de Moore e sua capacidade de processamento que dobra a cada 18 meses, em termos de CPU, memória, cachę e a capacidade de armazenamento que dobra a cada 10 meses. Se combinarmos as duas leis (processamento e armazenamento), produziríamos um ‘Gap’ cada vez mais crescente entre nossa capacidade de gerar dados e nossa habilidade de fazer uso eficiente deles.
Um exemplo deste crescimento constante no número de dados armazenados seria o da Biblioteca do Congresso (EUA), que possui aproximadamente 10 terabytes de texto e aproximadamente 3 petabytes (vídeos, áudio, etc.) e isto em pesquisa de 2007. Se considerarmos que a maior parte dos dados no qual falamos nunca foi vista por um ser humano, estes motivadores aumentam mais ainda.
Săo exemplos de tarefas abordadas em mineraçăo de dados: modelagem preditiva (classificaçăo, regressăo), segmentaçăo (clustering), afinidade (sumário/resumo dos dados), relaçőes (entre campos, associaçăo e visualizaçăo).
Na maioria dos casos, a mineraçăo tem processo baseado em OLAP (On-Line Analytical Process) e năo mais no tradicional SQL (Structured Query Language). Săo, portanto, etapas de seu processo a seleçăo e depuraçăo dos dados, transformaçăo dos dados, o próprio processo de mining (Mineraçăo), interpretaçăo, avaliaçăo e por fim, a integraçăo final e resultado.
Estas etapas fazem parte do KDD (Knowledge Discovery in Databases), que será mais bem detalhado no próximo tópico deste artigo.
A mineraçăo e o processo KDD
O termo que representa o processo que transforma dados de baixo nível em conhecimento de alto nível é conhecido como KDD. A mineraçăo de dados é uma das etapas deste processo e que pode ser entendida como a extraçăo de padrőes ou modelos de dados observados para avaliaçăo e descoberta de conhecimento.
Para um projeto de mineraçăo eficiente e que consiga produzir conhecimento necessário e utilizável, săo necessários cuidados nas diversas etapas compostas pelo processo de descoberta de conhecimento em bases de dados, que descritos em fases seriam:
Fase 1: Definiçăo e compreensăo do domínio do problema a analisar. Esta fase representa o processo inicial da definiçăo de objetivos a serem atingidos e deve prever que profissionais que participam da equipe de projeto precisam ter conhecimentos prévios e relevantes sobre o que vai ser tratado e com qual informaçăo irăo trabalhar.
Esta é a fase em que se avaliam a viabilidade do projeto a partir da determinaçăo do escopo e custos. Năo faz parte das etapas descritas na Figura 1, pois deve acontecer antes do processo de seleçăo dos dados.
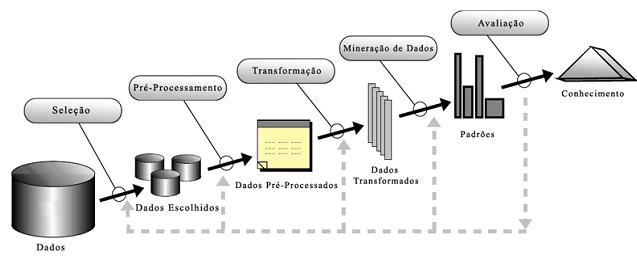
Figura 1. O Processo de KDD
Fase 2: Seleçăo e Amostragem. Esta é uma
fase de extrema importância para o projeto de mineraçăo e requer cuidados
extras, já que seria nesta fase que os dados văo ser selecionados para a
composiçăo do conjunto de dados, para a criaçăo de nova base de dados ou mesmo
para a definiçăo da amostra a ser uti ...







