Neste cenário, o tema discutido neste artigo é útil uma vez que a quantidade de dados presente nas organizaçőes nos dias atuais ultrapassou a capacidade humana de interpretar e compreender tanta informaçăo. Para isso, é importante conhecer e saber como utilizar técnicas de mineraçăo de dados, em específico, em ambientes educacionais.
Com a expansăo dos cursos ŕ distância e também daqueles com suporte computacional, muitos profissionais tęm aplicado as técnicas de mineraçăo de dados para investigar questőes como: quais săo os fatores que afetam a aprendizagem? Ou como desenvolver sistemas educacionais mais eficazes?. Dentro deste contexto, tem-se a área conhecida como “Mineraçăo de Dados Educacionais”. A MDE tem como objetivo desenvolver métodos para explorar conjuntos de dados coletados em ambientes educacionais. Compreender como os alunos aprendem, identificar em que situaçăo um tipo de abordagem instrucional como (aprendizagem individual ou colaborativa) proporciona melhores benefícios educacionais ao aluno. É possível verificar também se o aluno está desmotivado ou confuso e, assim, personalizar o ambiente e os métodos de ensino para oferecer melhores condiçőes de aprendizagem.
Os esforços em MDE estăo focados, principalmente, em tręs áreas:
- Desenvolver ferramentas e técnicas computacionais para definir que características incluir nos formulários de avaliaçăo da curva de aprendizado para tornar a MDE mais funcional e flexível;
- Definir quais perguntas se deve fazer aos dados para obter as respostas úteis na mineraçăo dos dados educacionais;
- Determinar quem săo os interessados (stakeholders) que poderiam se beneficiar dos resultados obtidos nos relatórios através das técnicas de MDE.
A utilizaçăo de técnicas de mineraçăo de dados sobre dados educacionais é relativamente recente. A maioria dos trabalhos nesta área tem o objetivo de identificar resultados para explicar o sucesso ou insucesso acadęmico de cursos năo presencial.
A partir de agora apresentaremos um estudo de caso do uso da mineraçăo de dados para a área educacional.
Estudo de caso de MDE
A partir da base de dados selecionada para o estudo de caso, foram seguidas todas as etapas do processo de KDD, ou seja, iniciou com pré-processamento dos dados, realizou-se a transformaçăo e enriquecimentos de alguns dados e aplicou-se a mineraçăo de dados. Em seguida, foi demonstrado o processo para o ETL (Extraçăo e Transformaçăo de carga), seguido da criaçăo de um Data Mart.
Seleçăo dos dados
Os dados utilizados neste trabalho foram provenientes de um questionário sócio econômico e cultural preenchidos no momento da inscriçăo pelos candidatos aos processos seletivos dos anos de 2012 e 2013 do Instituto Federal de Educaçăo, Cięncia e Tecnologia do Sul de Minas Gerais, Campus Muzambinho. Eles nunca haviam sido explorados para as atividades de Data Mining e encontravam-se armazenados nos servidores de banco de dados do Núcleo de Tecnologia da Informaçăo (NTI).
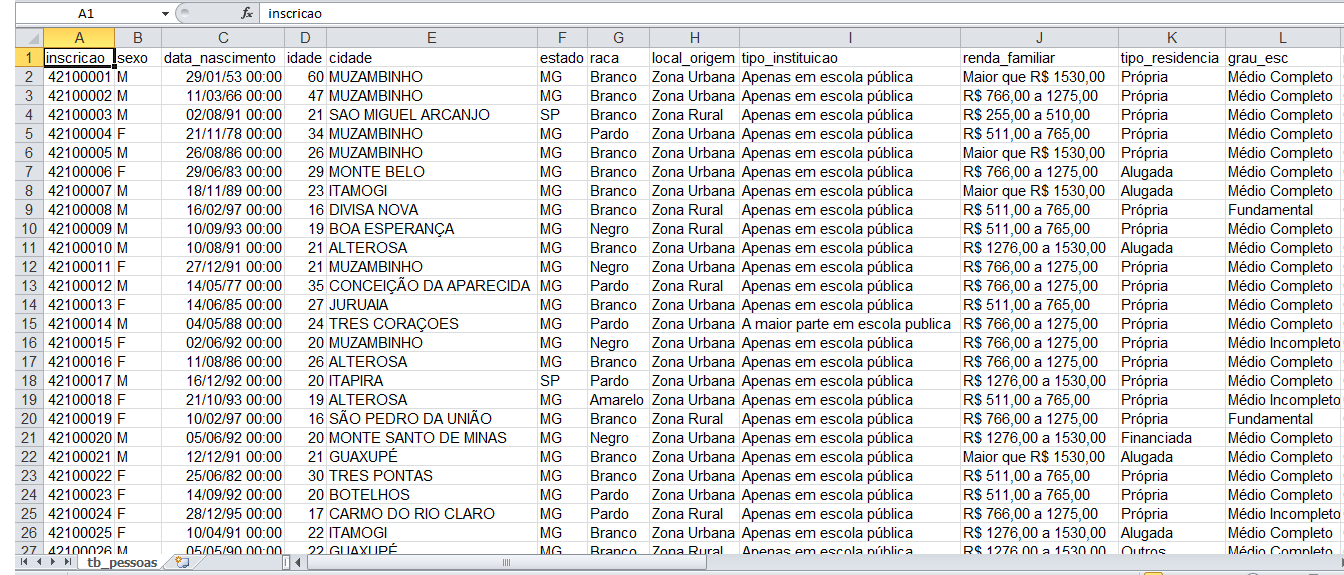
Estes dados foram disponibilizados em duas planilhas com o formato .xls, conforme a Figura 1, uma referente ao ano de 2012 e a outra referente ao ano de 2013. Tal formato possui cabeçalhos na estrutura compatível para a importaçăo das mesmas para o SQL Server 2008. Além destes dados, foram disponibilizados também alguns dados do cadastro geral dos candidatos, tais como: o sexo, a idade, a cidade e o total de pontos obtidos pelo candidato no vestibular.
Pré-Processamento dos Dados
Remoçăo de Dados
Foram excluídas da tabela as colunas inscriçăo e data_nascimento. A coluna inscriçăo foi excluída por possuir dados irrelevantes e a coluna data_nascimento por já existir uma coluna semelhante que é a coluna idade. Também foram retirados alguns registros que possuíam idades erradas, tais como, (-52, 3, 1015, 2007, 1032, 1017, 1018, 2013, 1, 1016, 2). Com o comando:
DELETE FROM socio_econ2012 WHERE idade <='valor da idade que está errada'Foi possivel remover todas as idades inadequadas.
Padronizaçăo dos Dados
Algumas cidades possuíam mais de uma forma de cadastro como, por exemplo: (Alpinopolis, Alpinópolis), (Conceicao da Aparecida, Conceiçao da Aparecida, Conceiçăo da Aparecida), (Divinolandia, Divinolândia), entre outras. Com o comando:
UPDATE socio_econ2012 SET cidade='alteraçăo_pretendida' WHERE cidade='condiçăo'Foi possivel padronizar os dados do atributo cidade.
Transformaçăo e Adequaçăo dos Dados
Os atributos das colunas idade, cidade, total pontos e curso foram transformados em conjuntos de dados com o objetivo de facilitar seu uso pelas técnicas de mineraçăo e enriquecer os resultados. As idades foram agrupadas da seguinte forma:
- A) Menos de 17 anos
- B) 17 anos
- C) Entre 18 e 22 anos
- D) Entre 23 e 30 anos
- E) Entre 31 e 40 anos
- F) Acima de 40 anos
Para que fosse possível preservar os dados no banco e ter os conjuntos de idades propostos, foi inserida uma nova coluna na tabela do banco de dados com o seguinte comando:
ALTER TABLE socio_econ2012ADD nova_idade varchar(50)Os dados foram transformados com os comandos apresentados na Listagem 1.
UPDATE socio_econ2012 SET nova_idade='MENOR_17' WHERE idade < 17
UPDATE socio_econ2012 SET nova_idade='17_ANOS' WHERE idade=17
UPDATE socio_econ2012 SET nova_idade='ENTRE_18-22'
WHERE idade BETWEEN 18 AND 22
UPDATE socio_econ2012 SET nova_idade='ENTRE_23-30'
WHERE idade BETWEEN 23 AND 30
UPDATE socio_econ2012 SET nova_idade='ENTRE_31-40'
WHERE idade BETWEEN 31 AND 40
UPDATE socio_econ2012 SET nova_idade='ACIMA_40'
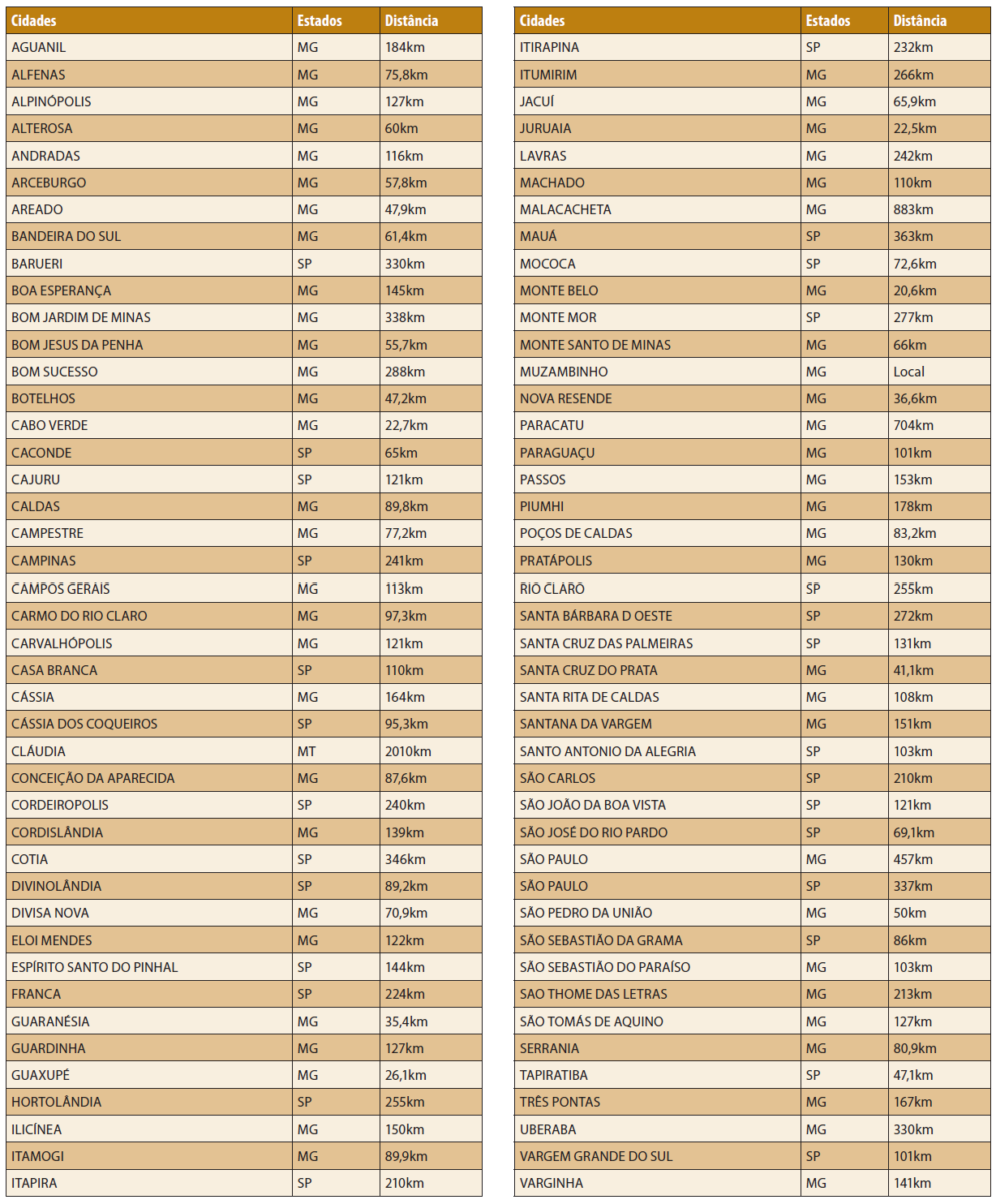
WHERE idade > 40No atributo cidades, a transformaçăo dos dados começou pela atribuiçăo das respectivas quilometragens de cada cidade em relaçăo ŕ cidade de Muzambinho-MG. Para realizar esta tarefa foi utilizado o Google Maps. O objetivo era obter informaçőes mais precisas em relaçăo aos candidatos, e a partir destas informaçőes, comparar o perfil dos candidatos que moram perto com os que moram longe do IFSULDEMINAS Câmpus Muzambinho (ver Tabela 1).
Com o comando SQL:
ALTER TABLE socio_econ2012 ADD km_cidade floatCriou-se uma nova coluna na tabela do banco de dados para receber a quantidade de quilômetro entre Muzambinho e a cidade de origem do candidato.
Os dados foram alterados no banco de dados com o comando:
UPDATE socio_econ2012 SET km_cidade='quantidade em quilômetro' WHERE cidade='nome da cidade'Além disso, com o comando:
ALTER TABLE socio_econ2012 ADD classe_cidade varchar(50)Criou-se também uma nova coluna na tabela do banco de dados para guardar as classes das cidades, como especificadas abaixo:
- a) Em Muzambinho
- b) Até 50km de Muzambinho
- c) Entre 50 e 100km de Muzambinho
- d) Entre 100 e 150km de Muzambinho
- e) Entre 150 e 200km de Muzambinho
- f) Acima de 200km de Muzambinho
Os dados foram transformados conforme a Listagem 2.
UPDATE socio_econ2012 SET classe_cidade='EM_MUZAMBINHO'
WHERE km_cidade='LOCAL'
UPDATE socio_econ2012 SET classe_cidade='ATE_50KM_MUZAMBINHO'
WHERE km_cidade < 50
UPDATE socio_econ2012 SET classe_cidade='ENTRE_50KM-100KM_MUZAMBINHO'
WHERE km_cidade BETWEEN 50 AND 100
UPDATE socio_econ2012 SET classe_cidade='ENTRE_100KM-150KM_MUZAMBINHO'
WHERE km_cidade BETWEEN 100.1 AND 150
UPDATE socio_econ2012 SET classe_cidade='ENTRE_150KM-200KM_MUZAMBINHO'
WHERE km_cidade BETWEEN 150.1 AND 200
UPDATE socio_econ2012 SET classe_cidade='ACIMA_200KM_MUZAMBINHO'
WHERE km_cidade > 200E para finalizar a transformaçăo e adequaçăo dos dados, foi criado uma nova coluna:
ALTER TABLE socio_econ2012 ADD classe_pontos varchar(50)Para receber as classes atribuídas para o total de pontos dos candidatos, como mostrado a seguir:
- a) Menos de 20 pontos no vestibular
- b) Entre 20 e 40 pontos no vestibular
- c) Entre 40 e 60 pontos no vestibular
- d) Entre 60 e 80 pontos no vestibular
- e) Acima de 80 pontos no vestibular
s dados foram transformados conforme Listagem 3.
UPDATE socio_econ2012 SET classe_pontos='MENOS_20_PONTOS'
WHERE total_pontos < 20.0
UPDATE socio_econ2012 SET classe_pontos='ENTRE_20-40_PONTOS'
WHERE total_pontos BETWEEN 20.0 AND 40.0
UPDATE socio_econ2012 SET classe_pontos='ENTRE_40-60_PONTOS'
WHERE total_pontos BETWEEN 40.1 AND 60.0
UPDATE socio_econ2012 SET classe_pontos='ENTRE_60-80_PONTOS'
WHERE total_pontos BETWEEN 60.1 AND 80.0
UPDATE socio_econ2012 SET classe_pontos='ACIMA_80_PONTOS'
WHERE total_pontos > 80.0Para transformar o atributo curso, criou-se primeiramente uma coluna para receber o nome de cada curso como: Engenharia Agronômica, Cięncia da Computaçăo, Informática, Cięncias Biológicas, entre outros. Os dados foram transformados de acordo com a Listagem 4.
ALTER TABLE socio_econ2012 ADD nome_curso varchar(50)
UPDATE socio_econ2012 SET nome_curso='ENGENHARIA AGRONÔMICA'
WHERE curso='ENGENHARIA AGRONÔMICA'
UPDATE socio_econ2012 SET
nome_curso='ENSINO MÉDIO E TÉCNICO EM AGROPECUÁRIA INTEGRADO'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM AGROPECUÁRIA'
UPDATE socio_econ2012 SET nome_curso='INFORMÁTICA'
WHERE curso='TÉCNICO EM INFORMÁTICA - NOTURNO'
UPDATE socio_econ2012 SET nome_curso='AGROPECUÁRIA'
WHERE curso='TÉCNICO EM AGROPECUÁRIA'
UPDATE socio_econ2012 SET nome_curso='CIĘNCIA DA COMPUTAÇĂO'
WHERE curso='CIĘNCIA DA COMPUTAÇĂO - BACHARELADO'
UPDATE socio_econ2012 SET
nome_curso='ENSINO MÉDIO E TÉCNICO EM INFORMÁTICA'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM INFORMÁTICA'
UPDATE socio_econ2012 SET nome_curso='CIĘNCIAS BIOLÓGICAS'
WHERE curso='CIĘNCIAS BIOLÓGICAS - LICENCIATURA'
UPDATE socio_econ2012 SET nome_curso='EDUCAÇĂO FÍSICA'
WHERE curso='EDUCAÇĂO FÍSICA - LICENCIATURA - VESPERTINO'
UPDATE socio_econ2012 SET nome_curso='EDUCAÇĂO FÍSICA'
WHERE curso='EDUCAÇĂO FÍSICA - BACHARELADO - NOTURNO'
UPDATE socio_econ2012 SET nome_curso='MEIO AMBIENTE'
WHERE curso='TÉCNICO EM MEIO AMBIENTE'
UPDATE socio_econ2012 SET nome_curso='ENFERMAGEM'
WHERE curso='TÉCNICO EM ENFERMAGEM - NOTURNO'
UPDATE socio_econ2012 SET nome_curso='EDUCACAO FÍSICA'
WHERE curso='EDUCAÇĂO FÍSICA - LICENCIATURA - NOTURNO'
UPDATE socio_econ2012 SET
nome_curso='ENSINO MÉDIO E TÉCNICO EM ALIMENTOS'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM ALIMENTOS'
UPDATE socio_econ2012 SET nome_curso='SEGURANÇA DO TRABALHO'
WHERE curso='TÉCNICO EM SEGURANÇA DO TRABALHO'
UPDATE socio_econ2012 SET nome_curso='EDUCAÇĂO FÍSICA'
WHERE curso='EDUCAÇĂO FÍSICA - BACHARELADO - VESPERTINO'
UPDATE socio_econ2012 SET nome_curso='INFORMÁTICA'
WHERE curso='TÉCNICO EM INFORMÁTICA - VESPERTINO'Além disso, criou-se outra coluna para receber os períodos, como: Noturno, Vespertino, Integral. Para isso, os dados foram transformados de acordo com a Listagem 5.
ALTER TABLE socio_econ2012 ADD periodo_curso varchar(50)
UPDATE socio_econ2012 SET periodo_curso='INTEGRAL'
WHERE curso='ENGENHARIA AGRONÔMICA'
UPDATE socio_econ2012 SET periodo_curso='INTEGRAL'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM AGROPECUÁRIA'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='TÉCNICO EM INFORMÁTICA - NOTURNO'
UPDATE socio_econ2012 SET periodo_curso='INTEGRAL'
WHERE curso='TÉCNICO EM AGROPECUÁRIA'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='CIĘNCIA DA COMPUTAÇĂO - BACHARELADO'
UPDATE socio_econ2012 SET periodo_curso='INTEGRAL'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM INFORMÁTICA'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='CIĘNCIAS BIOLÓGICAS - LICENCIATURA'
UPDATE socio_econ2012 SET periodo_curso='VESPERTINO'
WHERE curso='EDUCAÇĂO FÍSICA - LICENCIATURA - VESPERTINO'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='EDUCAÇĂO FÍSICA - BACHARELADO - NOTURNO'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='TÉCNICO EM MEIO AMBIENTE'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='TÉCNICO EM ENFERMAGEM - NOTURNO'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='EDUCAÇĂO FÍSICA - LICENCIATURA - NOTURNO'
UPDATE socio_econ2012 SET periodo_curso='INTEGRAL'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM ALIMENTOS'
UPDATE socio_econ2012 SET periodo_curso='NOTURNO'
WHERE curso='TÉCNICO EM SEGURANÇA DO TRABALHO'
UPDATE socio_econ2012 SET periodo_curso='VESPERTINO'
WHERE curso='EDUCAÇĂO FÍSICA - BACHARELADO - VESPERTINO'
UPDATE socio_econ2012 SET periodo_curso='VESPERTINO'
WHERE curso='TÉCNICO EM INFORMÁTICA - VESPERTINO'Por fim, criou-se mais uma coluna para receber o grau do curso: Superior e Técnico. Os dados foram transformados segundo a Listagem 6.
ALTER TABLE socio_econ2012 ADD grau_curso varchar(50)
UPDATE socio_econ2012 SET grau_curso='SUPERIOR'
WHERE curso='ENGENHARIA AGRONÔMICA'
UPDATE socio_econ2012 SET grau_curso='ENSINO MÉDIO E TÉCNICO'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM AGROPECUÁRIA'
UPDATE socio_econ2012 SET grau_curso='TÉCNICO'
WHERE curso='TÉCNICO EM INFORMÁTICA - NOTURNO'
UPDATE socio_econ2012 SET grau_curso='TÉCNICO'
WHERE curso='TÉCNICO EM AGROPECUÁRIA'
UPDATE socio_econ2012 SET grau_curso='SUPERIOR'
WHERE curso='CIĘNCIA DA COMPUTAÇĂO - BACHARELADO'
UPDATE socio_econ2012 SET grau_curso='ENSINO MÉDIO E TÉCNICO'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM INFORMÁTICA'
UPDATE socio_econ2012 SET grau_curso='LICENCIATURA'
WHERE curso='CIĘNCIAS BIOLÓGICAS - LICENCIATURA'
UPDATE socio_econ2012 SET grau_curso='LICENCIATURA'
WHERE curso='EDUCAÇĂO FÍSICA - LICENCIATURA - VESPERTINO'
UPDATE socio_econ2012 SET grau_curso='BACHARELADO'
WHERE curso='EDUCAÇĂO FÍSICA - BACHARELADO - NOTURNO'
UPDATE socio_econ2012 SET grau_curso='TÉCNICO'
WHERE curso='TÉCNICO EM MEIO AMBIENTE'
UPDATE socio_econ2012 SET grau_curso='TÉCNICO'
WHERE curso='TÉCNICO EM ENFERMAGEM - NOTURNO'
UPDATE socio_econ2012 SET grau_curso='LICENCIATURA'
WHERE curso='EDUCAÇĂO FÍSICA - LICENCIATURA - NOTURNO'
UPDATE socio_econ2012 SET grau_curso='ENSINO MÉDIO E TÉCNICO'
WHERE curso='ENSINO MÉDIO E TÉCNICO EM ALIMENTOS'
UPDATE socio_econ2012 SET grau_curso='TÉCNICO'
WHERE curso='TÉCNICO EM SEGURANÇA DO TRABALHO'
UPDATE socio_econ2012 SET grau_curso='BACHARELADO'
WHERE curso='EDUCAÇĂO FÍSICA - BACHARELADO - VESPERTINO'
UPDATE socio_econ2012 SET grau_curso='TÉCNICO'
WHERE curso='TÉCNICO EM INFORMÁTICA - VESPERTINO'Com as tabelas criadas e devidamente modificadas, foi finalizado o processo de pré-processamento. A partir dessa etapa, iniciou-se o uso da ferramenta Weka para a mineraçăo dos dados.
Mineraçăo de Dados
Importando os dados
Para iniciar o uso da ferramenta Weka, primeiramente deve-se escolher a opçăo de uso na tela inicial. Escolheu-se, para este artigo, a opçăo Explorer que permite obter os dados por quatro formas: Open file, Open URL, Open BD ou Generate. Para essa aplicaçăo foi usada a opçăo Open BD, que permitiu o acesso aos dados diretamente no banco.
Após escolhida a opçăo Open BD, é aberta uma nova janela com as opçőes de conexăo com o banco. Deve ser informada a URL do banco ao qual será feita a conexăo. Por padrăo, aparece no campo URL o endereço: “jdbc:idb=experiments.prp”. Porém, com esta opçăo năo foi possível conectar-se ao banco. Foi necessária a modificaçăo no arquivo de fonte de dados de sistema no administrador de fonte de dados ODBC, que se encontra no menu Ferramentas Administrativas, no painel de controle do Windows. Esta modificaçăo é uma etapa importante, pois é por meio dela que se torna possível a conexăo entre a ferramenta Weka e o SQL Server.
Nessa opçăo é configurada uma nova fonte de dados de sistema. Foi utilizado o Windows 8, com 4 GB de memória e processador Core i3. A seguir, será descrito um passo a passo da configuraçăo.
Inicialmente acesse a Fonte de dados ODBC, digitando na tela inicial -> PAINEL DE CONTROLE, e logo após clicando em -> FERREMENTAS ADMINSTRATIVAS. Feito isso, escolha a aba Fonte de dados de sistema, clique em adicionar, e escolha a opçăo que melhor se encaixar no BD utilizado. No caso deste artigo, a opçăo é SQL Server. Depois, clique em Concluir.
Na janela que aparecerá, coloque o nome da fonte de dados no campo Nome. O campo Descriçăo é opcional. Em seguida, adicione o caminho do servidor (o mesmo servidor utilizado no banco de dados), conforme está apresentado na Figura 2. Clique em Avançar para continuar a configuraçăo.
Na próxima janela, selecione a opçăo “Com autenticaçăo do SQL Server usando ID de logon e senha inseridos pelo usuário.”, adicione o ID de logon e senha (o mesmo usuário e senha utilizados no banco de dados). Clique em Avançar para continuar a configuraçăo.
Agora selecione a opçăo “Alterar o banco de dados padrăo para:” e escolha o banco no qual está a tabela dos dados que serăo minerados. No caso deste artigo, a opçăo é Questionario. Depois, clique em Avançar. Na próxima janela, nenhuma alteraçăo foi feita. Apenas, clique em Concluir. Na sequęncia, serăo apresentadas todas as configuraçăo de instalaçăo da nova fonte de dados ODBC que esta sendo criada. Clique em Testar fonte de dados. Tendo o teste sido realizado com sucesso, clique na opçăo Ok para finalizar o processo.
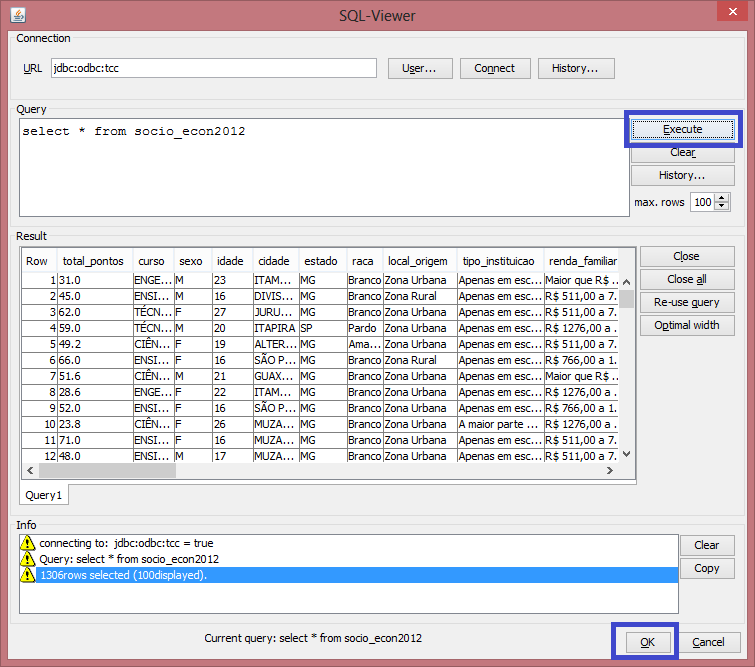
Ao voltar ŕ ferramenta Weka, é possível fazer a conexăo com o banco, utilizando o endereço jdbc:odbc:tcc. Clique em User e informe o Usuário e senha. Logo após clique no botăo Connect to data base. Aparecerá uma mensagem no campo Info informando que a conexăo foi feita.
No campo Query é informado o comando para uso dos dados no banco. No caso, um SELECT, para trazer todos os dados da tabela. Em seguida, clique em Execute e os dados aparecerăo no campo Result. Para usar os dados no Weka, selecione a opçăo um OK (Figura 3).
Trabalhando os dados
Com os dados na ferramenta, já é possível tratá-los para o uso adequado do algoritmo escolhido. A tela apresenta as informaçőes dos dados separados por algumas seçőes como veremos a partir de agora.
Na seçăo Attributes, săo descriminados todos os atributos do banco. A janela destacada através da Figura 4 apresenta os botőes para que se possam trabalhar tais atributos. Săo eles:
- ALL: seleciona todos os atributos;
- NONE: desmarca a seleçăo dos atributos selecionados;
- INVERTE: inverte a seleçăo dos atributos, os que estăo marcados passam a năo ficarem mais marcados, e os năos marcados ficam com a marcaçăo;
- PATTERN: habilita o usuário a selecionar atributos baseados em expressőes regulares;
- REMOVE: remove os itens selecionados.
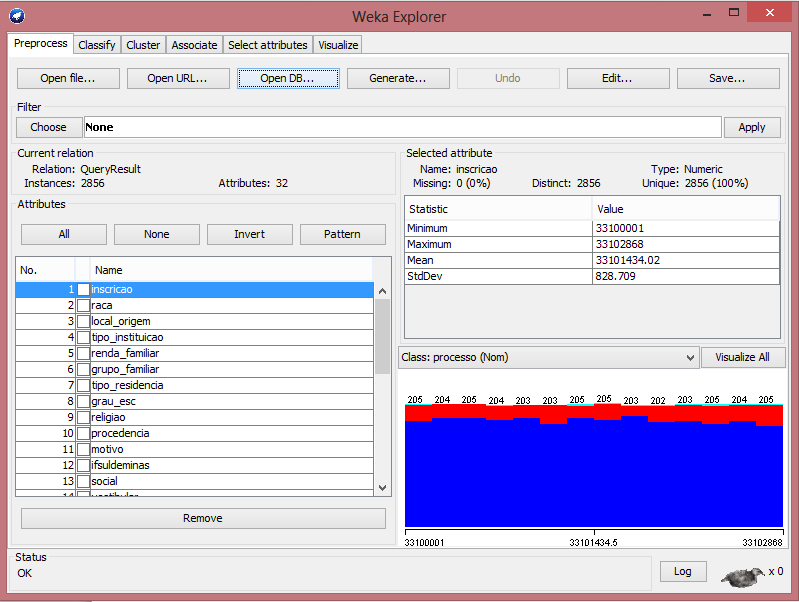
Já a seçăo current relation mostra as informaçőes da relaçăo atual dos dados. Nela pode-se observar o nome do arquivo que será minerado (através do atributo Relation), o número de instâncias que serăo analisadas neste arquivo (pelo atributo Instances) e o número de atributos analisados (pelo atributo Attributes).
Existe também a seçăo Selected atribute, que mostra os detalhes do atributo selecionado na janela Attributes. Nela encontram-se informaçőes como (ver Figura 5):
- Name: o nome do atributo selecionado;
- Type: tipo do atributo, que normalmente é nominal ou numérico;
- Missing: o número ou porcentagem de instâncias, para este atributo, que năo foram especificadas;
- Distinct: o número de valores distintos para este atributo;
- Unique: especifica o número ou porcentagem de instâncias únicas, ou seja, valores que nenhuma outra instância possui.
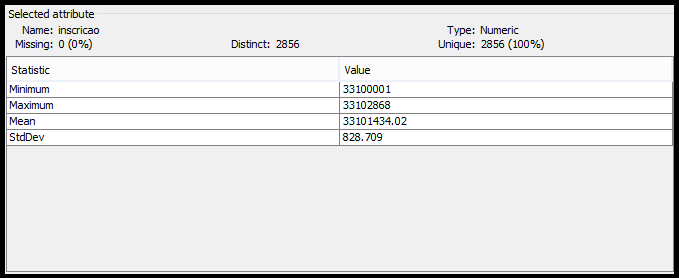
Os valores estatísticos presentes nesta janela dependem do tipo do atributo. Se ele for numérico como no exemplo da Figura 5, os valores especificados săo: minimum (mínimo), maximum (máximo), mean (média) e StdDev (desvio padrăo). Se for nominal, como no exemplo da Figura 6, a lista conterá os valores permitidos para o atributo e suas respectivas quantidades.
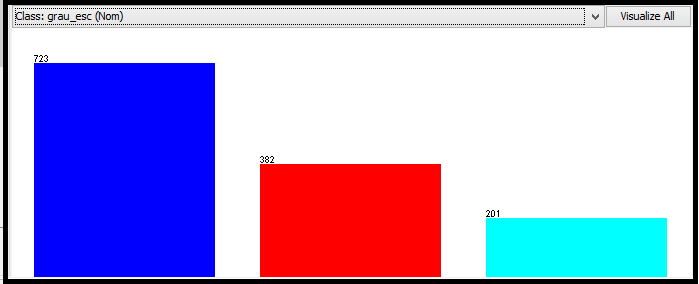
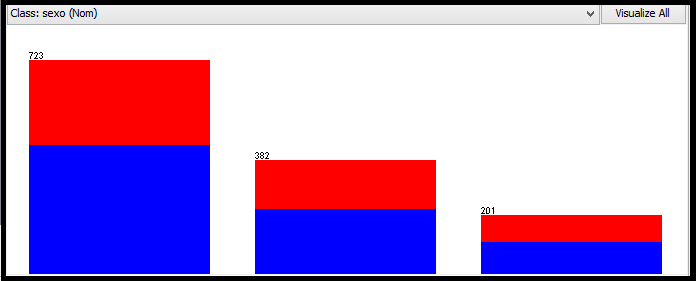
A seguir, é apresentada a janela com a classe selecionada para análise. Por padrăo, ela estará com o último atributo da janela de atributos. Porém, pode ser mudado a qualquer momento. Juntamente, é mostrado um gráfico em que o atributo selecionado e classe escolhida săo os mesmos. O atributo escolhido para esta demonstraçăo foi o grau de escolaridade do candidato, o qual possui tręs opçőes de respostas: Fundamental, Médio Completo, e Médio Incompleto. Sendo assim, cada cor e cada coluna representam as opçőes de resposta do atributo em questăo e quantidade de reposta que cada uma obteve. Neste caso, a cor azul escuro está representando o Médio Completo, que foi a opçăo escolhida por 723 candidatos; o vermelho está representando o Fundamental, opçăo escolhida por 382 candidatos e, por último a cor azul claro, que representa o Médio Incompleto, sendo a opçăo de 201 candidatos (ver Figura 7).
No exemplo da Figura 8, o atributo selecionado continuou sendo o grau de escolaridade, porém a classe agora é referente ao sexo do candidato. Podemos notar que a ferramenta Weka representa através do gráfico a relaçăo que existe entre o atributo e classe selecionada. As tręs colunas agora possuem as mesmas cores, porém com nível diferente, onde o azul representa o sexo masculino e vermelho o sexo feminino.
Como os dados vęm diretamente do banco, é necessário, para uso de alguns algoritmos, modificar seu tipo de atributo. Essa modificaçăo pode ser feita através da guia Filter do Weka.
Depois de feitas as modificaçőes, é interessante salvar os dados no formato .ARFF, padrăo utilizado pela ferramenta Weka. Para isso, basta clicar no botăo Salvar da janela principal.
Usando Associaçăo
Foi utilizado o algoritmo Apriori para obter as regras de associaçăo dos dados informados. O uso desse algoritmo na ferramenta Weka dá-se utilizando os passos a seguir. Inicialmente clica-se na guia Associate. Na janela Associator na opçăo Choose, escolha Apriori (se a opçăo Apriori năo estiver disponível, é sinal que o tipo de atributo deve ser mudado).
A ferramenta Weka oferece a opçăo de alterar os parâmetros para mineraçăo. Para isso, basta um duplo clique na descriçăo do Apriori e será aberta uma nova janela, com os campos a serem modificados. Para esse trabalho, modificaremos somente os campos (ver Figura 9):
- lowerBoundMinSupport - é o limite para o suporte mínimo. Săo consideradas apenas regras com contagens mais altas que o valor estabelecido neste campo. Suporte de um itemset é definido como sendo a porcentagem de transaçőes onde este itemset aparece;
- minMetric - pontuaçăo mínima métrica. Devem-se considerar apenas regras com confiança superiores a este valor. A toda regra de associaçăo A -> B associamos um grau de confiança, denotado por conf(A -> B). Este grau de confiança é a porcentagem das transaçőes que suportam B dentre todas as transaçőes que suportam A;
- numRules - número de regras ŕ encontrar.
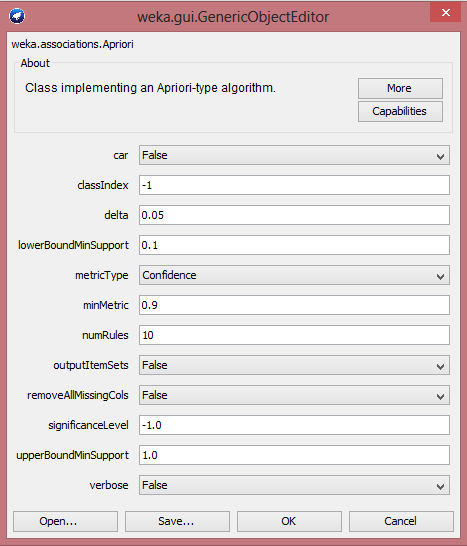
Foi escolhida a seguinte classificaçăo para essa demonstraçăo:
- lowerBoundMinSupport: 0.1 (10%);
- minMetric: 0.5 (50%);
- numRules: 100.
Estas configuraçőes variarăo de uma regra para outra. Como as características dos candidatos em geral săo bem diversificadas, para que fosse possível analisar um conjunto razoável de regras, foi necessário estabelecer um suporte mínimo baixo.
Feito isso, selecione a opçăo Start para que seja iniciado o algoritmo.
As regras săo geradas no seguinte formato:
internet=Diariamente classe_pontos=ENTRE_60-80_PONTOS 145 ==> micro=Tem em casa e usa regularmente 135 conf:(0.93)O símbolo ==> faz a divisăo entre o antecedente e o consequente. O número que aparece antes do símbolo ==> indica o suporte da regra, neste caso é o 145. O número que aparece no final da regra indica quantas vezes o consequente aparece para cada ocorręncia do antecedente, ou seja, 135. E o número final, entre paręnteses, é o valor da confiança, que é calculado a partir das transaçőes em comum, ou seja, 135/145= 0,93, representando 93%.
Pós-Processamento
Interpretaçăo
Nessa etapa, é importante a visăo do especialista no domínio, ou seja, pessoas que conhecem o assunto no qual está sendo aplicado o KDD. Geralmente, săo pessoas interessadas em identificar novos conhecimentos que possam ser utilizados em sua área de atuaçăo. Costumam deter o chamado conhecimento prévio sobre o problema. As informaçőes prestadas pelas pessoas deste grupo săo de fundamental importância no processo de KDD, pois influenciam desde a definiçăo dos objetivos do processo até a avaliaçăo dos resultados.
Algumas questőes foram levantadas diante do problema em questăo, que é delinear o perfil do candidato, como por exemplo:
- Qual o motivo que leva o candidato a preencher a inscriçăo para o processo seletivo e năo efetuar o pagamento, ou entăo pagar mas năo comparecer no dia do vestibular? Essa é uma situaçăo preocupante, pois uma quantidade razoável de inscritos se encaixa nesse item.
- Dentro do curso, qual área especifica influencia mais o aluno e que poderá futuramente gerar novos cursos de pós-graduaçăo ou até mesmo novos cursos de graduaçăo?
- Qual o objetivo dos candidatos que já fizeram vários cursos dentro do IFSULDEMINAS?
- Qual a visăo das pessoas (comunidade em geral) diante do IFSULDEMINAS?
- Como mudar a cultura do aluno, ou seja, como fazę-lo se interessar pelo lado empreendedor?
- Os alunos que estăo no ensino médio procuraram o IFSULDEMINAS por causa do ensino médio, do técnico, ou pela possibilidade de cursar os dois paralelamente?
- Qual o principal motivo em relaçăo ŕs dificuldades encontradas nas matérias pelos alunos? O aluno sabe estudar? Como o aluno aprende?
- Qual a visăo dos egressos diante do IFSULDEMINAS, o curso respondeu as expectativas diante do mercado de trabalho?
- Quais motivos levam os alunos ŕ evasăo?
Criaçăo de um Data Mart
Como visto anteriormente, é possível utilizar-se do próprio modelo transacional (banco de dados usado para capturar as informaçőes dos candidatos ao processo seletivo) para analisar os dados e transformá-los em informaçőes úteis, porém existe uma maneira mais indicada de se armazenar os dados antes de iniciar o processo de busca das informaçőes.
Trata-se da criaçăo de um Data Mart, que organiza melhor os dados e traz maior velocidade de acesso as informaçőes, possibilitando consolidar os dados de forma que eles prestem informaçőes para os níveis gerencial e estratégico do negocio em questăo; ou seja, passa a disponibilizar dados históricos, de forma a viabilizar consultas, descoberta de tendęncias e análises a partir dos dados. Além disso, evita a perda de performance no processo operacional da empresa, pois os dados estăo sendo analisados em um repositório separado.
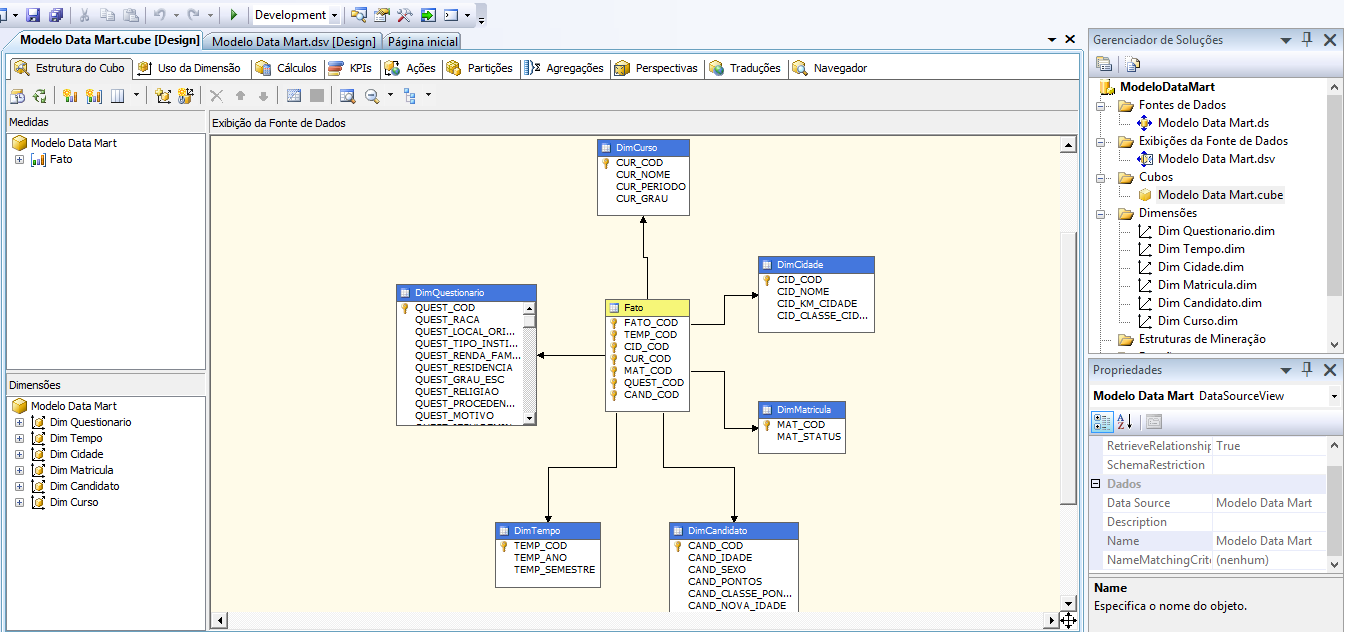
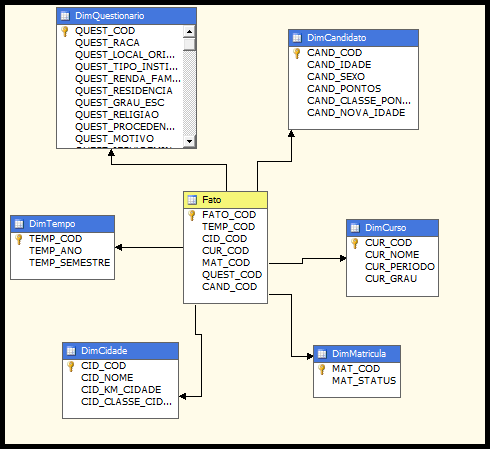
Foi utilizado o modelo estrela para a criaçăo dessa estrutura. Este modelo possui uma tabela chamada fato no centro do modelo e algumas tabelas de dimensőes. A tabela fato possui a chave estrangeira de todas as dimensőes, conforme a Figura 10.
Foram construídas seis dimensőes:
- DimCandidato;
- DimCurso;
- DimMatricula;
- DimCidade;
- DimQuestionario;
- DimTempo.
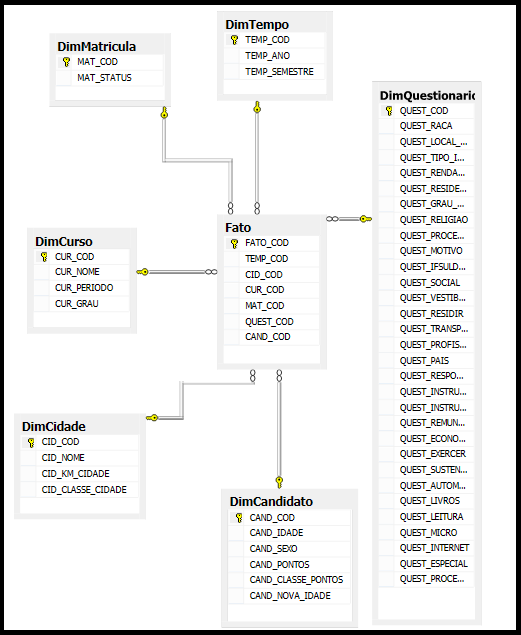
A dimensăo DimQuestionario é a principal, nela estăo contidos os 31 atributos referentes ŕs perguntas do questionário sócio econômico. A dimensăo DimCandidato possui os dados pessoais de cada candidato e o pontos obtidos no vestibular. A Dim Curso possui o nome do curso, o período (noturno, vespertino, integral) e o grau (superior, técnico, ensino médio e técnico integrado) . A DimMatricula possui o status da matrícula do candidato, ou seja, se ele ainda está cursando, se está com a matrícula trancada, se desistiu do curso, entre outros. A DimCidade possui o nome da cidade dos candidatos, a distância em km de cada cidade até Muzambinho, e a classe de pontos entre as cidades envolvidas. A DimTempo possui o ano e o semestre do Processo seletivo. E a tabela fato possui relaçăo com todas as demais tabela do Data Mart.
O Integration Services, presente no
pacote de aplicativos do SQL Server 2008, permite que os dados de um banco de
dados sejam transferidos para outra fonte de dados.
O fluxo
de controle é responsável pelo fluxo de tarefas do ETL (Extract Transform and
Load), isto é, realizar a extraçăo dos dados armazenados no banco de dados
transacional e inseri-los no modelo estrela. No fluxo de controle, arraste o
item Tarefas do Fluxo de Dados, conforme a Figura
11.
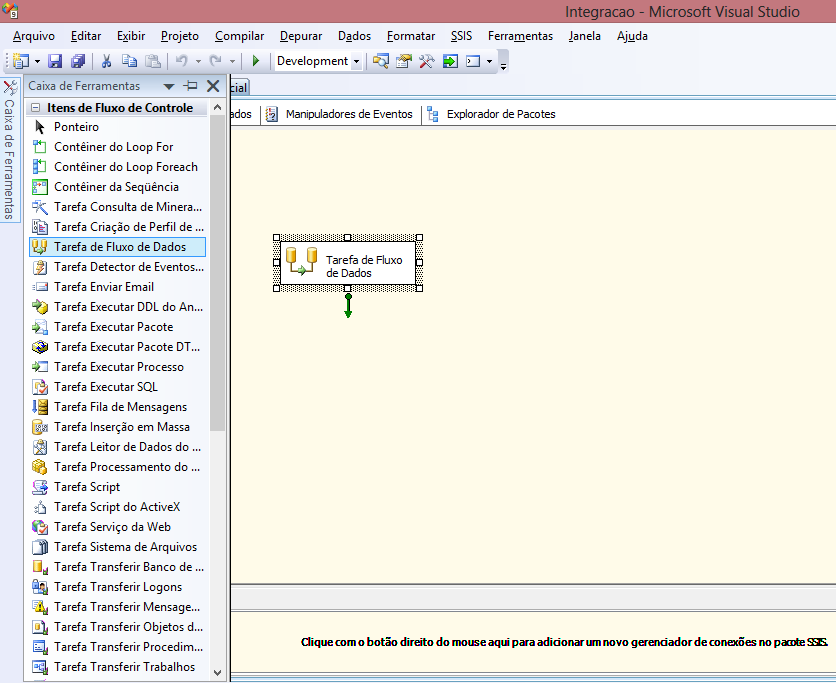
Clicando duas vezes no nome do objeto, é possível renomear a Tarefa de Fluxo de Dados. Foi necessário criar sete Tarefas de Fluxo de Dados, seis para as dimensőes e uma para a tabela fato, conforme a Figura 12. As sete Tarefas de Fluxo de Dados criadas foram:
- Import Candidato;
- Import Curso;
- Import Cidade;
- Import Matricula;
- Import Questionario;
- Import Tempo;
- Import Fato.
Já o Fluxo de Dados é responsável por extrair dados e realizar sua transformaçăo para dar carga em tabelas destino. Para que seja possível dar carga nas tabelas do modelo estrela, entre no modo de ediçăo do Fluxo de Dadosda Tarefa “Import Candidatos”. Arraste o item Origem OLE DB conforme Figura 13. Esse componente será usado para conectar a base de dados transacional. Essa base contém os dados do questionário sócio econômico que estăo sendo usados no projeto.
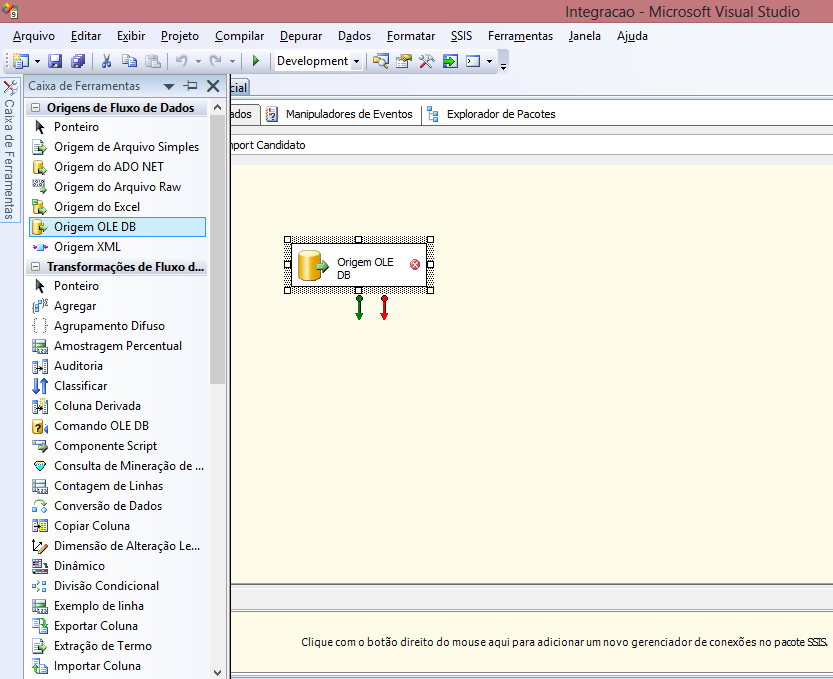
O “x” em vermelho que aparece na Origem OLE DB (Figura 13) é porque ainda năo foi realizada a conexăo e, portanto, o componente sinaliza que alguma coisa está errada. Para resolver esta questăo, basta clicar duas vezes em Origem OLE DB para acessar o editor de origem, em seguida clicar em Novo para configurar uma nova conexăo.
Preencha os dados do servidor (Server name, username, e senha) e em seguida selecione o esquema do banco de dados, neste caso “Questionario” e clique em OK.
Em Gerenciador de Conexőes é possível escolher o modo de acesso aos dados, que podem ser provenientes de uma tabela ou exibiçăo, ou um comando SQL. Selecione Tabela ou exibiçăo. No campo “Nome da Tabela ou exibiçăo”, selecione o nome da tabela no qual possui os dados de origem.
Na aba coluna, serăo exibidos todos os campos da tabela selecionada. Deixe selecionados apenas os campos que serăo necessários para dar carga na dimensăo editada, logo após clique em OK, e dessa forma o objeto Origem OLE DB está configurado para se conectar aos dados provenientes da base de dados transacional.
Arraste o objeto Destino OLE DB para o Fluxo de Dados e ligue a Origem OLE DB nele por meio da seta verde. O objeto Destino OLE DB será responsável por realizar a conexăo dos dados com as tabelas do modelo estrela. Confira na Figura 14 como o Fluxo de Dados deve ficar.
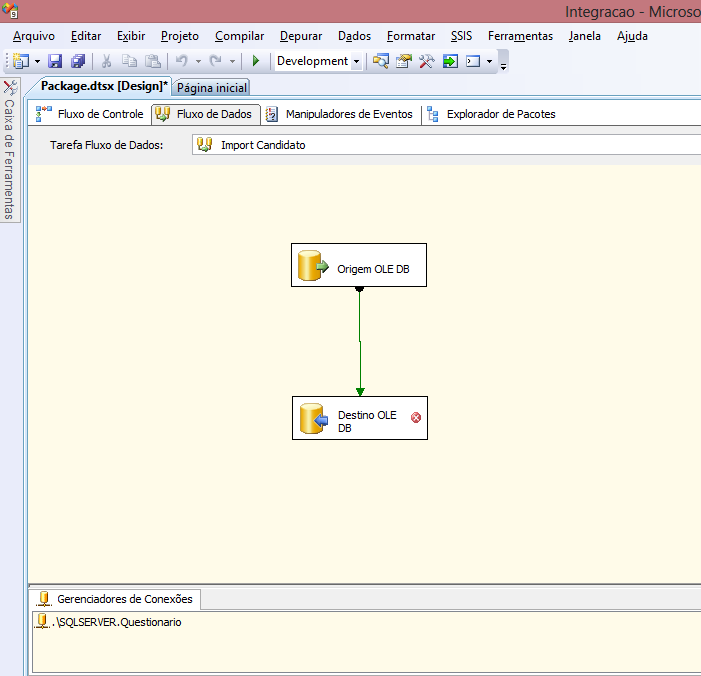
A configuraçăo do componente Destino OLE DB é praticamente a mesma do Origem OLE DB.
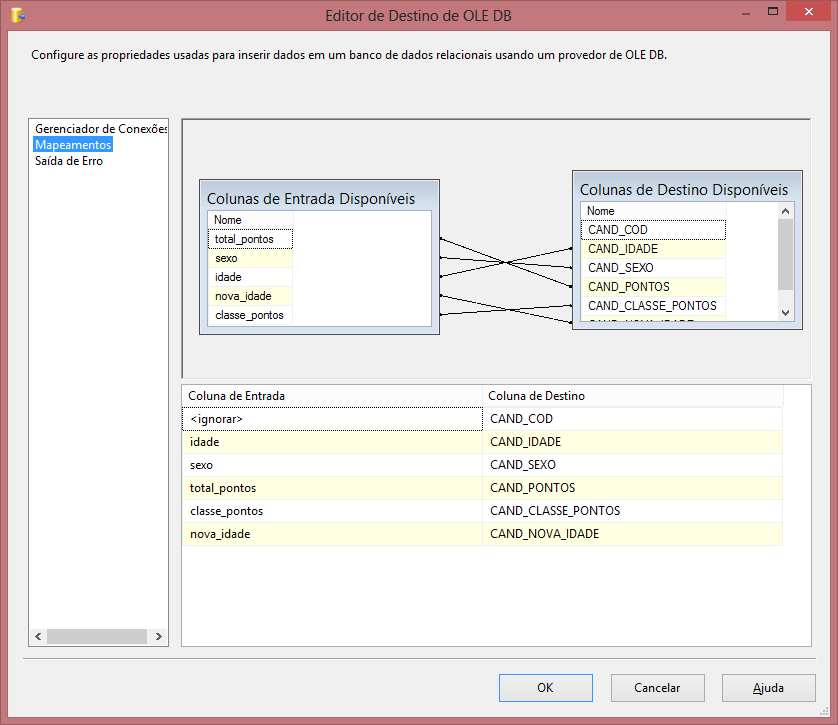
Uma vez selecionada a tabela de destino, é necessário mapear as colunas de destino com as colunas da fonte dos dados. Arraste as colunas de entrada para as colunas de destino conforme a Figura 15. Depois de mapeadas as colunas, clique em OK e o Fluxo de Dados estará completo.
Os mesmos procedimentos realizados até aqui para “Import Candidatos” foram realizados com os Fluxos de Dados “Import Curso”, “Import Cidade”, “Import Matricula”, “Import Questionario” e “Import Tempo”. Com isso completamos a configuraçăo do processo de ETL para as seis dimensőes.
Após terem sido feitas todas as configuraçőes é hora de depurar o projeto. Para isso, clique em Iniciar Depuraçăo. Se o processo for executado com sucesso, os itens ficarăo verdes, e caso haja alguma falha, vermelho (Figura 16).
Depois da tabela fato e tabelas dimensőes terem sido criadas e populadas, foi criado um projeto no Analysis Services.O Analysis Services é responsável pela criaçăo do cubo e pelas análises que podem ser realizadas sobre ele.
Primeiramente é necessário criar a Fonte de Dados para acessar o banco ModeloDataMart que foi criado e populado anteriormente. Para isso, clique com o botăo direito em Fonte de Dados, disponível na janela do Gerenciador de Soluçőes, e selecione Nova Fonte de Dados.
O Assistente de Fonte de Dados irá abrir e será necessário configurar a conexăo clicando em Novo. Defina as configuraçőes do servidor selecionando a base de dados. Selecione as configuraçőes de credenciais necessárias para o Analysis Services se conectar ao Modelo de Data Mart criado na base de dados.
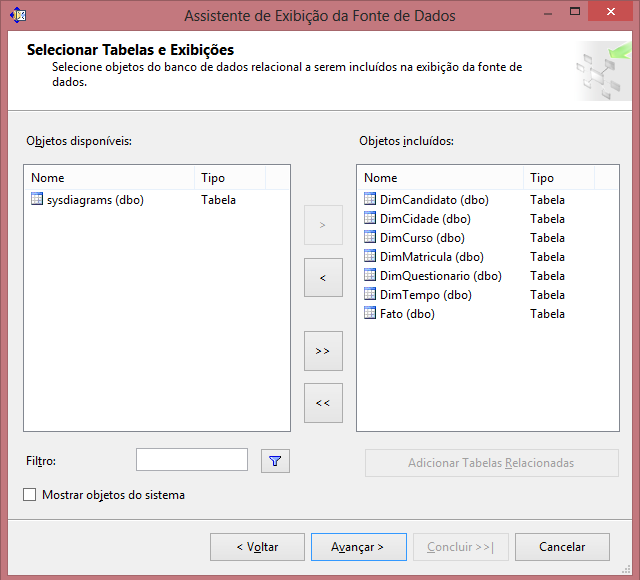
O próximo passo será criar a Exibiçăo da Fonte de Dados, localizado abaixo da Fonte de Dados. Nesta etapa é necessário selecionar as tabelas desejadas conforme Figura 17.
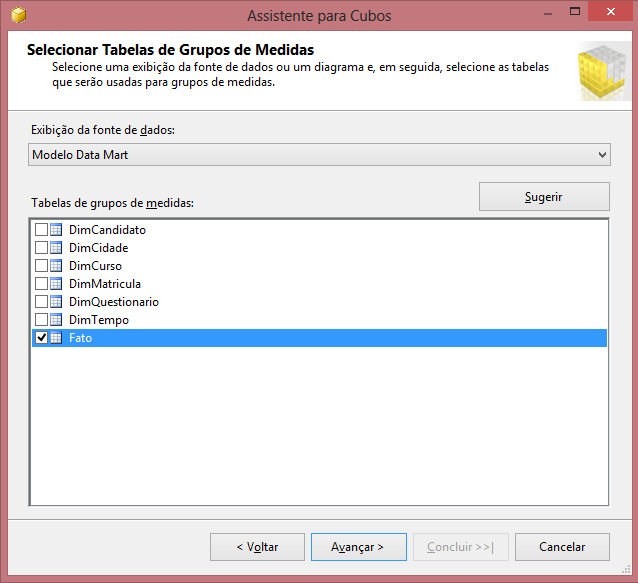
O próximo passo é criar um cubo no Analysis Services, localizado abaixo de Exibiçőes da Fonte de Dados na janela do Gerenciador de Soluçőes. Defina entre as tabelas qual será a tabela fato que será usada como grupos de mediçăo, conforme a Figura 18.
O próximo passo é selecionar os campos que serăo utilizados como medida. Uma vez selecionados esses campos, clique em Avançar.
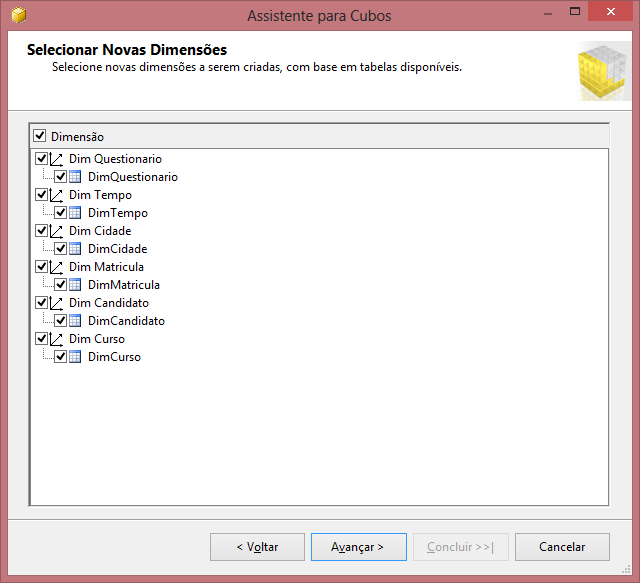
Por fim, selecione as dimensőes do cubo. Essas dimensőes săo sugeridas automaticamente pela ferramenta e, neste caso, săo DimCandidato, DimCurso, DimCidade, DimMatricula, DimQuestionario e DimTempo, conforme a Figura 19.
Ao clicar em Avançar surgirá um resumo das escolhas realizadas e é possível definir um nome para o Cubo. O cubo e as dimensőes serăo criados conforme a Figura 20.
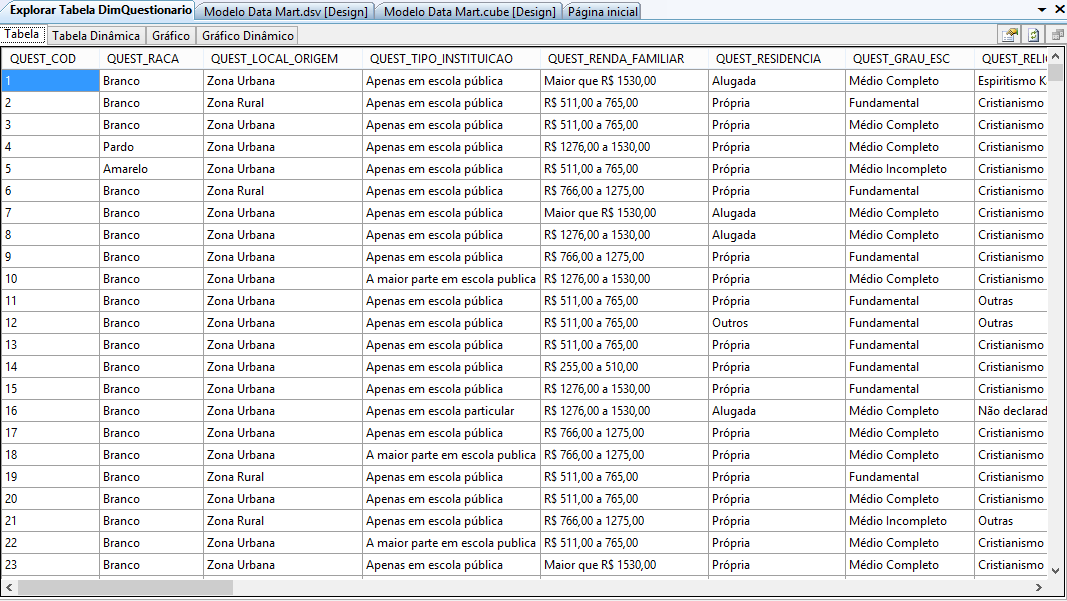
Os dados contidos em cada tabela do Data Mart podem ser visualizados de forma simples e rápida. Basta clicar com o botăo direito em cima da tabela que deseja visualizar e escolher a opçăo “Explorar Dados”. Os dados serăo carregados e exibidos em forma de tabela, conforme a Figura 21.
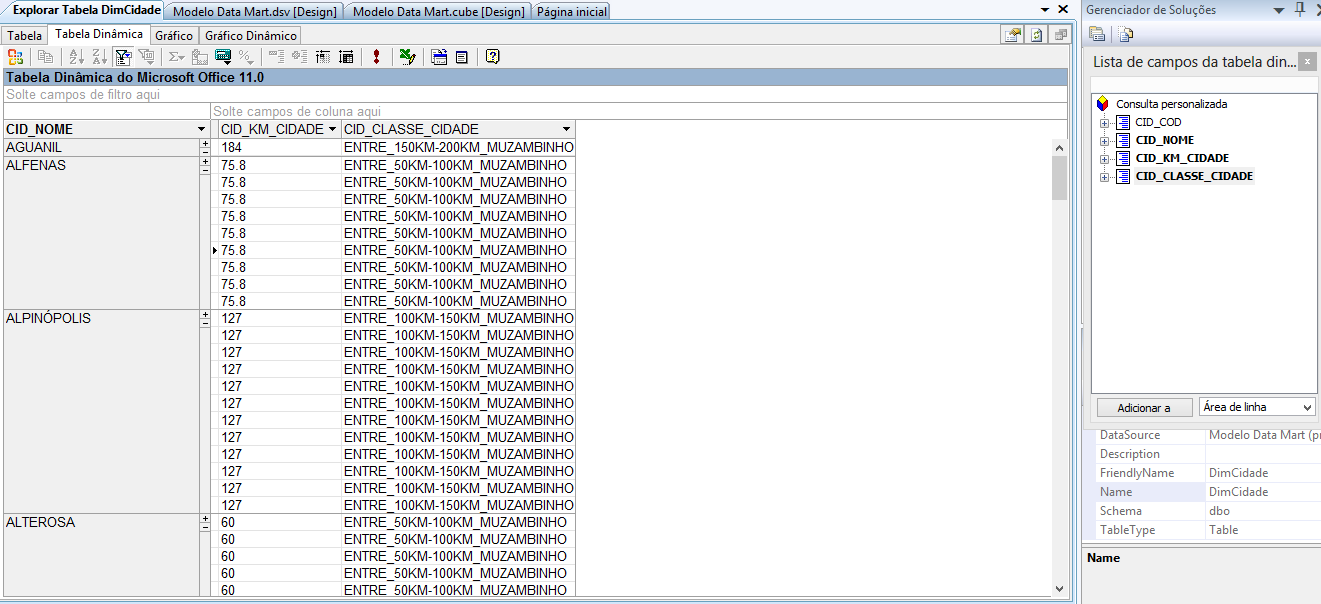
Além da visualizaçăo dos dados pela tabela, também é possível visualizar estes dados através de Tabela Dinâmica, Gráficos e Gráficos Dinâmicos. Na Tabela Dinâmica é necessário arrastar e soltar no local desejado os atributos da tabela que deseja comparar, conforme a Figura 22.
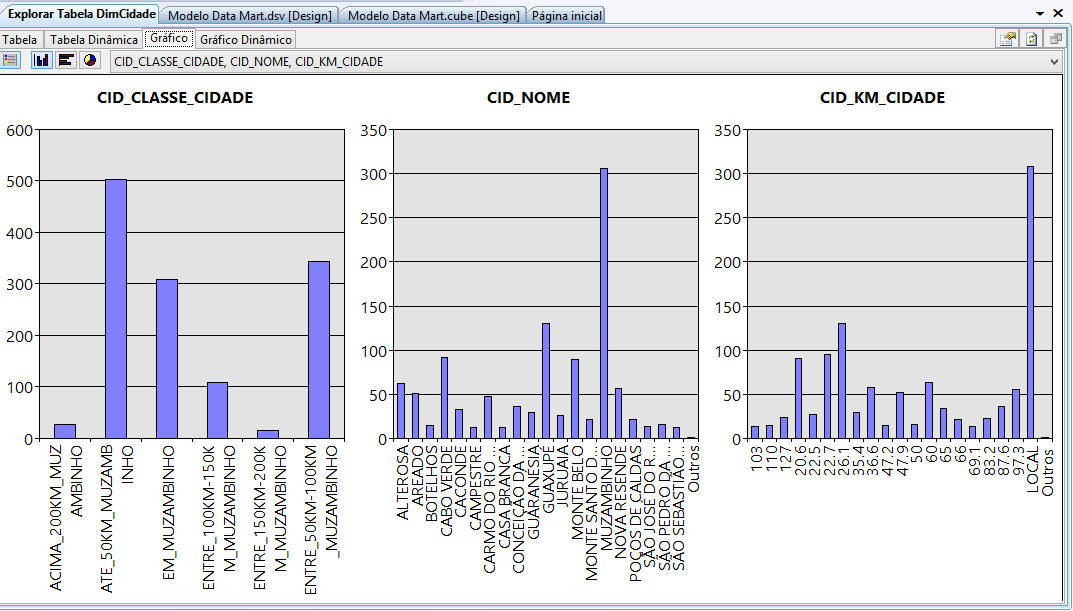
A visualizaçăo pelo Gráfico pode ser realizada, pelo Gráfico de Coluna, Gráficos de Barra e Gráficos de Pizza, conforme as Figuras 23, 24 e 25.
Resultados e discussăo
A partir de agora serăo demonstrados os resultados obtidos na mineraçăo de dados através da ferramenta Weka, e de forma simples serăo interpretados os padrőes encontrados. Também será discutida a proposta do modelo de Data Mart.
Resultados da mineraçăo dados aplicando a técnica de associaçăo
Inicialmente, foram seleciononados os atributos necessários para gerar regras que pudessem ser analisadas, e a partir delas, delinear o “perfil dos candidatos” ao processo seletivo do IFSULDEMINAS Câmpus Muzambinho.
Em testes iniciais, foram selecionados os atributos referentes ŕs seguintes questőes do Questionário Sócio Econômico aplicado em 2012:
- Quanto ao uso de microcomputador:
- Tem em casa e usa regularmete;
- Tem em casa e năo usa;
- Usa no trabalho;
- Usa de parentes ou amigos;
- Lan House;
- Nunca usou;
- Com que Frequęncia vocę utliza a Internet ?
- Diariamente;
- Semanalmente (algumas vezes);
- Quinzenalmente;
- Mensalmente;
- Somente nos Finais de Semana;
- Năo Utiliza;
Juntamente com essas duas perguntas, foi selecionado o atributo classe_pontos, que foi criado a partir do total de pontos dos candidatos.
Para os resultados obtidos, será dado destaque a algumas regras das quais vamos obter informaçőes gerais sobre os dados:
- internet=Diariamente classe_pontos=ACIMA_80_PONTOS 17 ==> micro=Tem em casa e usa regularmente 16 conf:(0.94)
- micro=Tem em casa e usa regularmente internet=Somente nos Finais de semana 32 ==> classe_pontos=ENTRE_40-60_PONTOS 20 conf:(0.63)
- micro=Lan House internet=Somente nos Finais de semana 26 ==> classe_pontos=ENTRE_20-40_PONTOS 15 conf:(0.58)
- internet=Mensalmente classe_pontos=ENTRE_20-40_PONTOS 23 ==> micro=Lan House 13 conf:(0.57)
- micro=Usa de parentes ou amigos internet=Semanalmente (algumas vezes) 56 ==> classe_pontos=ENTRE_40-60_PONTOS 30 conf:(0.54)
Com essas regras podem-se observar características interessantes:
- a regra 1 indica que 94% dos candidatos que responderam que usam a internet diariamente e obtiveram acima de 80 pontos no vestibular também responderam que tęm computador em casa e usam regularmente.
- a regra 2 indica que 63% dos candidatos que responderam que possuem computador em casa e usam regularmente, e acessam a internet apenas nos finais de semana; entăo tiraram entre 40 e 60 pontos no vestibular.
- a regra 3 indica que 58% dos candidatos que responderam que utilizam computador em Lan House e acessam a internet apenas nos finais de semana; entăo tiraram de 20 a 40 pontos no vestibular.
- a regra 4 indica que 57% dos candidatos que utilizam a internet mensalmente, e obtiveram entre 20 e 40 pontos no vestibular também responderam que utilizam o computador em Lan House.
- a regra 5 indica que 54% dos candidatos que utilizam o computador de parentes ou amigos e acessam a internet semanalmente, entăo obtiveram entre 40 e 60 pontos no vestibular.
Com base nessas regras e dentro deste contexto, pode-se concluir que o uso do computador e da internet influenciam diretamente no resultado do candidato no vestibular. Uma boa soluçăo seria implantar alguns centros de inclusăo digital para que as pessoas que năo possuem computador e năo tęm acesso ŕ internet possam ter um local para fazer suas pesquisas. Além disso, percebe-se com as regras acima, que o candidato que utiliza o computador e acessa a internet em Lan House possui uma nota menor do que os candidatos que utilizam o computador de parentes e amigos. Talvez isso ocorra pelo fato de que a maioria das pessoas utilizam os computadores em Lan House mais pra jogos do que para pesquisa, e até mesmo os que utilizam os computadores especificamente para pesquisa devem encontrar dificuldade de se concentrar diante da movimentaçăo que geralmente possui este tipo estabelecimento.
Outro teste realizado foi utilizando a base de dados de 2012, e selecionado o atributo classe_cidade, que foi transformado a partir da relaçăo de cidade de cada candidato, juntamente com as seguintes perguntas:
-
Qual
o motivo principal da escolha do curso para o qual vocę se inscreveu?
- Realizaçăo pessoal;
- Resultados de testes vocacionais;
- Prestígio social da profissăo;
- Possibilidades no mercado de trabalho;
- Influęncia da família e/ou amigos;
- Contribuiçăo para a sociedade;
- Baixa concorręncia no vestibular;
- O curso só existe neste Instituto;
- Outro Motivo.
-
Por
que escolheu o IFSULDEMINAS?
- Realizaçăo pessoal;
- Resultados de testes vocacionais;
- Prestigio social da profissăo;
- Possibilidades no mercado de trabalho;
- Influęncia da família e/ou amigos;
- Contribuiçăo para a sociedade;
- Baixa concorręncia no vestibular;
- O curso só existe neste Instituo;
- Outro motivo.
As principais regras geradas foram:
- ifsuldeminas=Realizaçăo pessoal classe_cidade=ENTRE_100KM-150KM_MUZAMBINHO 41 ==> motivo=Realizaçăo pessoal 36 conf:(0.88)
- ifsuldeminas=Realizaçăo pessoal classe_cidade=ENTRE_50KM-100KM_MUZAMBINHO 115 ==> motivo=Realizaçăo pessoal 96 conf:(0.83)
- ifsuldeminas=Possibilidades no mercado de trabalho classe_cidade=EM_MUZAMBINHO 73 ==> motivo=Possibilidades no mercado de trabalho 50 conf:(0.68)
- ifsuldeminas=Possibilidades no mercado de trabalho classe_cidade=ATE_50KM_MUZAMBINHO 120 ==> motivo=Possibilidades no mercado de trabalho 78 conf:(0.65)
Com essas regras pode-se observar que:
- as regras 1 e 2 indicam que de 83 a 88% dos candidatos que escolheram o IFSULDEMINAS por realizaçăo pessoal e que moram entre 50 e 150 km de Muzambinho também escolheram o curso por realizaçăo pessoal.
- a regra 3 indica que 68% dos candidatos que escolheram o IFSULDEMINAS por possibilidade no mercado de trabalho, moram em Muzambinho e escolheram o curso também por possibilidade no mercado de trabalho.
- a regra 4 indica que 65% dos candidatos que escolheram o IFSULDEMINAS por possibilidade no mercado de trabalho, moram até 50km de Muzambinho e escolheram o curso também por possibilidade no mercado de trabalho.
-
Como pretende residir na cidade do campus no
qual se inscreveu?
- Com parentes;
- Com amigos (compartilhando despesas);
- Sozinho(a);
- Com os pais;
- Somente com a măe;
- Somente com o pai;
- Internato;
- Com esposo(a) e/ou filho;
- Outra forma;
- Năo morarei na mesma cidade mais viajarei todos os dias.
- residir=internato classe_pontos=ENTRE_60-80_PONTOS 46 ==> curso=ENSINO MÉDIO E TÉCNICO EM AGROPECUÁRIA 39 conf:(0.85)
- curso=EDUCAÇĂO FÍSICA - LICENCIATURA - NOTURNO classe_pontos=ENTRE_20-40_PONTOS 46 ==> residir=năo morarei na mesma cidade mas viajarei todos os 35 conf:(0.76)
- curso=TÉCNICO EM ENFERMAGEM - NOTURNO classe_pontos=ENTRE_40-60_PONTOS 45 ==> residir=năo morarei na mesma cidade mas viajarei todos os 34 conf:(0.76)
- curso=TÉCNICO EM SEGURANÇA DO TRABALHO 45 ==> residir=năo morarei na mesma cidade mas viajarei todos os 33 conf:(0.73)
- curso=CIĘNCIA DA COMPUTAÇĂO - BACHARELADO classe_pontos=ENTRE_20-40_PONTOS 43 ==> residir=năo morarei na mesma cidade mas viajarei todos os 30 conf:(0.7)
- curso=TÉCNICO EM AGROPECUÁRIA residir=internato 31 ==> classe_pontos=ENTRE_40-60_PONTOS 21 conf:(0.68)
- residir=com amigos (compartilhando despesas) classe_pontos=ENTRE_20-40_PONTOS 66 ==> curso=ENGENHARIA AGRONÔMICA 43 conf:(0.65)
- curso=TÉCNICO EM INFORMÁTICA - NOTURNO residir=com os pais/um dos pais - qual? _____ 31 ==> classe_pontos=ENTRE_60-80_PONTOS 20 conf:(0.65)
- a regra 1 indica que 85% dos candidatos que pretendem residir no internato e obtiveram entre 60 e 80 pontos no vestibular entăo optaram pelo curso Ensino Médio e Técnico em Agropecuária integrado.
- com as regras 2, 3, 4 e 5, percebe-se que no intervalo entre 70 e 76%, os candidatos que optaram pelos cursos Educaçăo Fisica, Técnico em Enfermagem, Técnico em Segurança do Trabalho e Cięncia da Computaçăo, independente da nota obtida no vestibular, responderam que iriam residir em suas cidades e viajariam todos os dias.
- a regra 6 indica que 68% dos candidatos que escolheram o curso Técnico em Agropecuária e que pretendem residir no internato tirarăo entre 40 e 60 pontos nos vestibular.
- a regra 7 indica que 65% dos candidatos que pretendem residir com os amigos (compartilhando despesas) e tiveram entre 20 e 40 pontos no vestibular entăo escolheram o curso de Engenharia Agronômica.
- a regra 8 indica que os candidatos que optaram pelo curso Técnico em Informática e irăo residir com os pais tiraram entre 60 e 80 pontos no vestibular.
- curso=EDUCAÇĂO FÍSICA - BACHARELADO - NOTURNO ifsuldeminas=Realizaçăo pessoal 29 ==> motivo=Realizaçăo pessoal 27 conf:(0.93)
- curso=TÉCNICO EM AGROPECUÁRIA ifsuldeminas=Realizaçăo pessoal 26 ==> motivo=Realizaçăo pessoal 23 conf:(0.88)
- curso=ENGENHARIA AGRONÔMICA ifsuldeminas=Realizaçăo pessoal 81 ==> motivo=Realizaçăo pessoal 64 conf:(0.79)
- curso=TÉCNICO EM MEIO AMBIENTE motivo=Realizaçăo pessoal 17 ==> ifsuldeminas=Realizaçăo pessoal 13 conf:(0.76)
- curso=ENSINO MÉDIO E TÉCNICO EM ALIMENTOS ifsuldeminas=Realizaçăo pessoal 17 ==> motivo=Realizaçăo pessoal 13 conf:(0.76)
- curso=ENSINO MÉDIO E TÉCNICO EM INFORMÁTICA ifsuldeminas=Possibilidades no mercado de trabalho 38 ==> motivo=Possibilidades no mercado de trabalho 29 conf:(0.76)
- curso=CIĘNCIA DA COMPUTAÇĂO - BACHARELADO ifsuldeminas=Realizaçăo pessoal 33 ==> motivo=Realizaçăo pessoal 25 conf:(0.76)
- curso=CIĘNCIA DA COMPUTAÇĂO - BACHARELADO ifsuldeminas=Possibilidades no mercado de trabalho 28 ==> motivo=Possibilidades no mercado de trabalho 21 conf:(0.75)
- curso=ENSINO MÉDIO E TÉCNICO EM AGROPECUÁRIA motivo=Influęncia da família e/ou amigos 28 ==> ifsuldeminas=Influęncia da família e/ou amigos 16 conf:(0.57)
- as regras 1, 2, 3, 4 e 5 estăo numa faixa de confiança entre 76 a 93%, na qual a opçăo pelos cursos foram: Educaçăo Física, Técnico em Agropecuária, Engenharia Agronômica, Técnico em Meio Ambiente, e Técnico em Alimentos integrado ao Ensino Médio, escolherem o curso e o IFSULDEMINAS por realizaçăo pessoal.
- a regra 6 indica que 76% dos candidatos que optaram pelo curso de Técnico em Informática integrado ao Ensino Médio e escolheram o IFSULDEMINAS por possibilidade no mercado de trabalho, entăo escolheram o curso por possibilidade no mercado de trabalho.
- a regra 7 indica que 76% dos candidatos que optaram pelo curso de Cięncia da Computaçăo e escolheram o IFSULDEMINAS por realizaçăo pessoal, entăo escolheram o curso por realizaçăo pessoal.
- a regra 8 indica que 75% dos candidatos que optaram pelo curso de Cięncia da Computaçăo e escolheram o IFSULDEMINAS por possibilidade no mercado de trabalho, entăo escolheram o curso por possibilidade no mercado de trabalho.
- a regra 9 indica que 57% dos candidatos que optaram pelo curso de Técnico em Agropecuária integrado ao Ensino Médio e escolheram o curso por influencia da família e/ou amigos, entăo escolheram o IFSULDEMINAS por influęncia da família e/ou amigos.
Com base nessas regras, conclui-se que os candidatos que vęm de longe, numa distância de 50 a 150 km, vęm pela qualidade do IFSULDEMINAS. Já os que moram em Muzambinho ou em até 50 km de distância, procuram o IFSULDEMINAS por possibilidade no mercado de trabalho.
Foi selecionada também na base de dados de 2012, junto com os atributos classe_pontos, e o curso escolhido pelo candidato, a seguinte pergunta:
As principais regras geradas foram:
Com base nestas regras, pode-se observar que:
Com base nestas regras, nota-se que o curso que exige mais demanda em relaçăo ao internato é o curso Técnico em Agropecuária integrado ao Ensino Médio com Técnico em Agropecuária. Tendo isso em vista, poderăo ser verificadas se as vagas que estăo disponíveis no internato săo suficientes para atender essa demanda, garantido assim que o candidato classificado no processo seletivo consiga sua vaga no internato e efetue a sua matricula.
Outro teste realizado foi utilizando os atributos curso, motivo (motivo pela escolha do curso), ifsuldeminas (motivo pela escolha do ifsuldeminas) da base de dados de 2012. As principais regras identificadas foram:
Com base nas regras acima, pode-se observar que
Com base nas regras acima, percebe-se que grande parte dos candidatos que optaram pelos cursos de Educaçăo Física, Técnico em Agropecuária, Engenharia Agronômica, Técnico em Alimentos, Técnico em Alimentos integrado ao Ensino Médio, escolheram o curso e o IFSULDEMINAS por gostar de ambos. Já os candidatos que optaram pelo curso Técnico em Informática integrado ao Ensino Médio escolheram o curso e o IFSULDEMINAS por achar que é uma boa opçăo para o mercado de trabalho.
Nota-se também que os candidatos que optaram pela Cięncia da Computaçăo, possuem uma porcentagem bem próxima dos que escolheram o curso e o IFSULDEMINAS por gostar de ambos e dos que escolheram os curso e o IFSULDEMINAS por possibilidade no mercado de trabalho. Percebe-se também que os candidatos que optaram pelo curso de Técnico em Agropecuária integrado ao Ensino Médio, escolheram o curso e o IFSULDEMINAS por influęncia de família e/ou amigos, este caso provavelmente acontece, pois na regiăo, a agropecuária é o que prevalece, e muitos candidatos procuram o curso e a instituiçăo, năo por gostar ou nem por possibilidade que curso proporciona no mercado de trabalho, mas por terem na família alguém envolvido com a área agrícola.
Data Mart construído
A proposta do Data Mart construído neste artigo objetivou manter os dados mais organizados, possibilitar consultas rápidas e manter um histórico dos dados inseridos, além de possibilitar que novas técnicas de descoberta de conhecimento ou de B.I (Business Intelligence) sejam aplicadas sobre os dados armazenados neste repositório.
O Data Mart construído é o resultado da integraçăo das tabelas que constituem a base operacional do questionário sócio econômico e algumas informaçőes do candidato, tais como, o sexo, a cidade e a idade, e também algumas informaçőes do Processo Seletivo, como o total de pontos e o curso escolhido pelo candidato, conforme Figura 26.
Como os dados contidos no banco transacional já haviam sido limpos e formatados de acordo com as especificaçőes da Etapa de Pré-Processamento do KDD, o Data Mart que foi construído já recebeu os dados tratados.
A partir deste Data Mart, foi possível analisar o perfil dos candidatos ao processo seletivo de várias maneiras, através da visualizaçăo das tabelas dinâmicas, pelos diversos tipos de gráficos gerados e também aplicando a mineraçăo de dados para encontrar mais relaçőes interessantes sobre este perfil, visto que o processo de mineraçăo a partir do data mart é o mesmo processo feito com dados vindos do banco transacional.
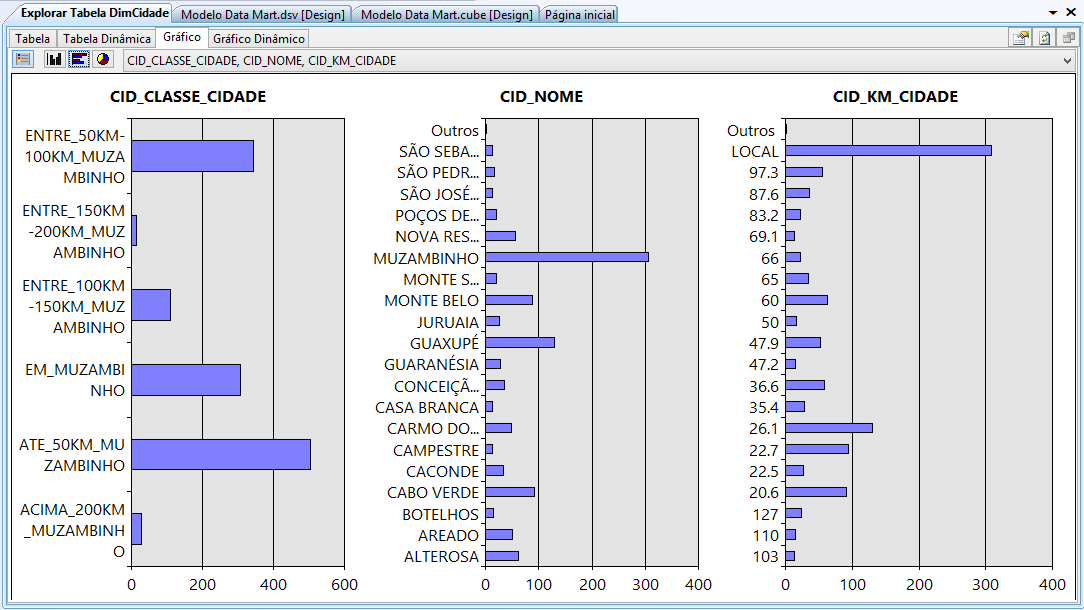
As Figuras 27, 28 e 29 ilustram a facilidade de analisar os dados a partir de um gráfico gerado com os dados provenientes do data mart.
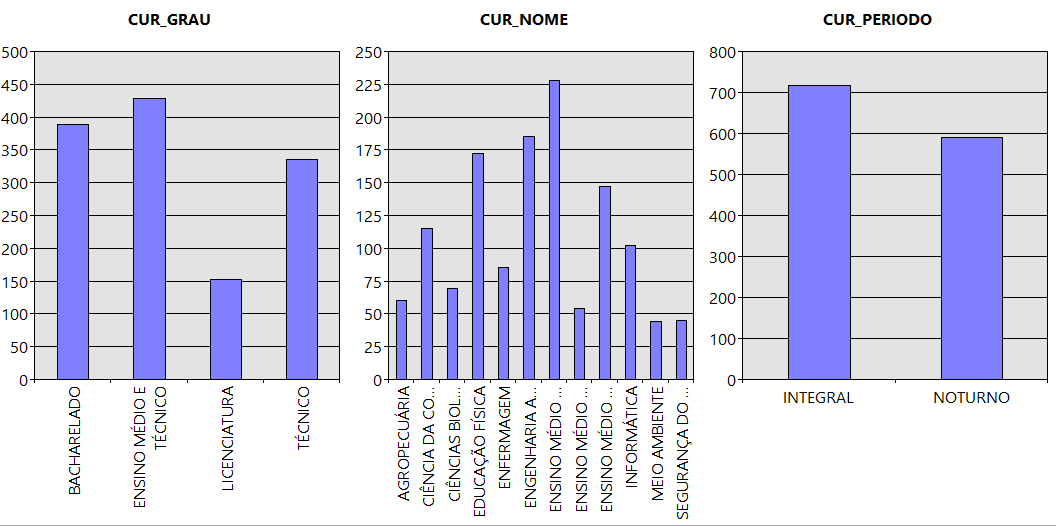
Com base nos gráfico de colunas, percebe-se que a demanda maior de vagas é do Ensino Médio com o Técnico integrado, seguido dos cursos de Bacharelado, Técnico e Licenciatura, levando em consideraçăo que esses dados săo referentes aos candidatos que estăo concorrendo aos 30% das vagas, pois 70% das vagas săo reservadas para o SISU. Analisando pelo nome do curso, nota-se que o Técnico em Agropecuária integrado ao Ensino Médio é o que mais possui candidatos no processo seletivo, seguido pela Engenharia Agronômica, Educaçăo Física, Técnico em Informática integrado ao Ensino Médio, Cięncia da Computaçăo, Técnico em Informática, Enfermagem, Cięncias Biológicas, Técnico em Agropecuária, Técnico em Alimentos integrado Ensino Médio, Meio Ambiente e Segurança do Trabalho. Percebe-se, também, que a quantidade de candidatos que procuram por curso em período integral săo maiores do que para os cursos noturnos.
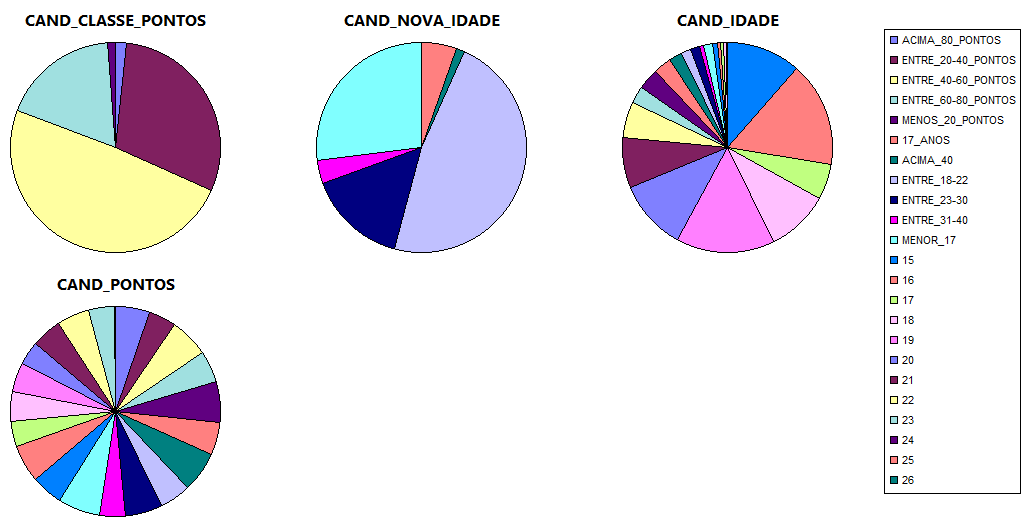
Os gráficos de pizza indicam que 49% dos candidatos ao processo seletivo obtęm entre 40 e 60 pontos, 30% obtęm entre 20 e 40 pontos, 18% obtęm entre 60 e 80 pontos, 1% tira menos de 20 pontos e 2% obtęm acima de 80 pontos. Nota-se também que 48% dos candidatos possuem idades entre 18 e 22 anos, 27% possuem menos de 17 anos, 15% entre 23 e 30 anos, 5% possuem exatamente 17 anos, 4% de 31 a 40 anos, 1% acima de 40 anos. Em geral, o público atual do processo seletivo do IFSULDEMINAS é bastante jovem.
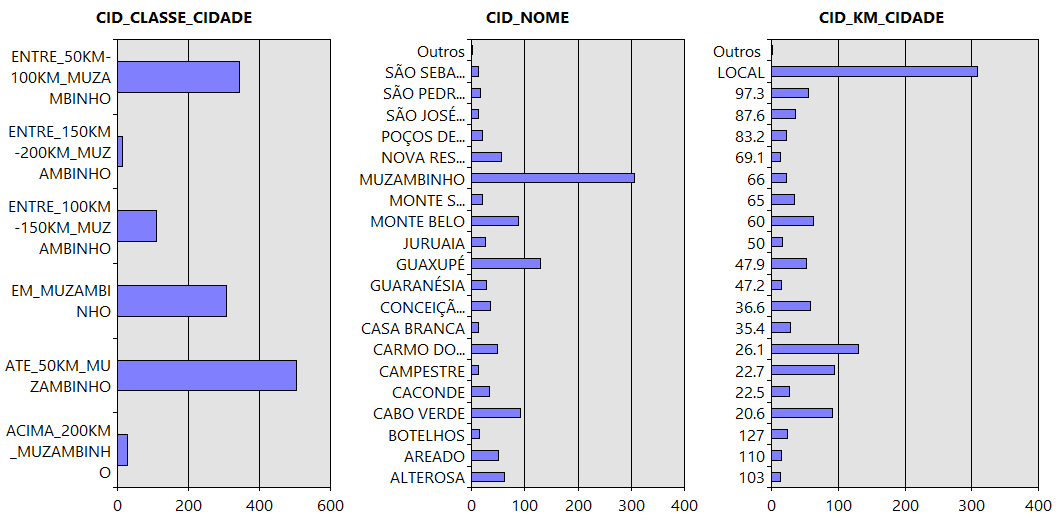
Por fim, os gráficos de barras mostram que a maioria dos candidatos está localizada a uma distância de até 50 km de Muzambinho – MG. Logo em seguida vęm os que estăo de 50 a 100 km, com um porcentagem bem próxima dos candidatos que săo de Muzambinho-MG. Depois se tem os que estăo entre 100 e 150 km, e depois uma porcentagem próxima, porém pequena săo dos candidatos que estăo entre 150 e 200 e acima de 200 km. Comparado por cidades individuais, nota-se que grande parte dos candidatos săo de Muzambinho-MG, as outras cidades com quantidade razoável de candidatos săo Guaxupé, Monte Belo, Cabo Verde, Areado, Alterosa, Nova Resende e Carmo do Rio Claro.
Conclusăo
Neste artigo, observamos que a primeira etapa no processo de descoberta de conhecimento em banco de dados, que é o pré-processamento, é de extrema importância e exige uma atençăo especial. Ela irá influenciar diretamente no sucesso das etapas posteriores. Quanto mais os dados forem transformados e enriquecidos, mais padrőes de associaçőes săo encontrados.







