Veja nesse artigo um exemplo do uso da mineraçăo de dados para análise do problema de evasăo em cursos universitários. Será apresentada a aplicaçăo de duas técnicas de mineraçăo: agrupamento e árvore de decisăo.
Por que eu devo ler este artigo:A mineraçăo
de dados apoia a descoberta de informaçőes úteis que normalmente estăo ocultas
em bases de dados com grande quantidade de registros. Neste artigo
apresentaremos dois casos práticos do uso de técnicas de mineraçăo para análise
do problema de evasăo em cursos universitários utilizando duas técnicas
distintas: agrupamento e árvore de decisăo. Esta discussăo é útil pois mostra
na prática como problemas reais podem ser tratados com o uso de técnicas de
mineraçăo. Autores: Péricles Magalhăes e Rodrigo Oliveira Spínola
Neste artigo, os arquivos gerados para
a mineraçăo de dados (apresentados na primeira parte) serăo utilizados em
estudos de caso em uma aplicaçăo de algoritmo de clustering e em uma aplicaçăo
de algoritmo de classificaçăo.
Caso 1 – Aplicaçăo de Algoritmo de Clustering
O agrupamento
ou clustering identifica similaridades entres os valores dos atributos
analisados e, a partir dessa análise, particiona a base de dados em grupos.
Para a execuçăo da técnica, no estudo de caso, foi selecionado o algoritmo
SimpleKMeans que, a partir da indicaçăo da quantidade (k) de clusters desejada,
divide a base de dados de forma que a similaridade dos elementos de cada
cluster seja alta e, entre os clusters seja baixa.
O
arquivo de entrada de dados gerado para essa aplicaçăo, descrito no artigo
anterior, foi carregado no WEKA onde algumas análises e consideraçőes foram
realizadas sobre a distribuiçăo dos valores dos atributos e seu impacto na
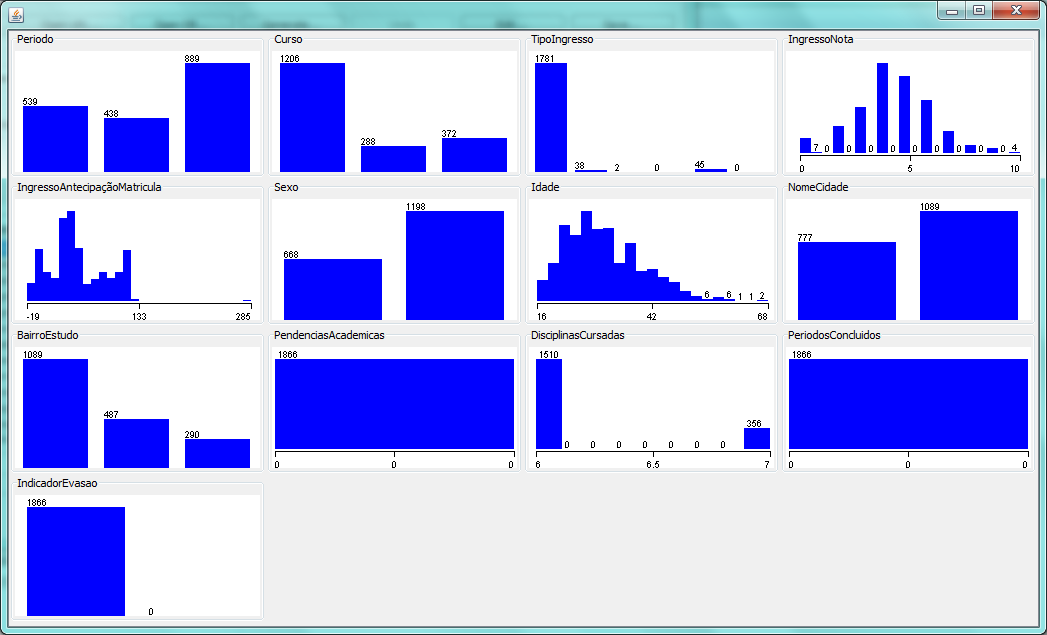
atividade. A Figura 1 apresenta as
distribuiçőes dos valores de cada atributo da base de dados carregada. Como
pode ser observado, os atributos PendenciasAcademicas, PeriodosConcluidos e
IndicadorEvasao apresentam apenas um valor, cada, em toda a base utilizada.
Dessa forma, năo possuem nenhuma interferęncia na criaçăo dos agrupamentos.
Figura 1. Representaçăo gráfica da distribuiçăo dos valores do
arquivo de entrada para o caso 1
O
algoritmo simpleKmeans apresenta algumas variáveis de configuraçăo para a sua
execuçăo:
·
displayStdDevs:
indica a exibiçăo de desvios padrăo dos atributos numéricos e contagens de
atributos nominais. Seu valor padrăo é false;
·
distanceFunction:
determina a funçăo de distância a ser usada para comparaçăo das instâncias.
Como padrăo, é utilizada a weka.core.EuclideanDistance;
·
dontReplaceMissingValues:
indica se os valores faltantes devem ser ...
<Saiba por que programar é uma questão de sobrevivência e como aprender sem riscos/>
Perguntas frequentes
Quem somos?
A DevMedia é uma escola de formação de programadores com mais de 20 anos de mercado. Já formamos mais de 100 mil programadores. A DevMedia ensina programação web, (desenvolvimento de site e aplicativos para celulares). A programação web é a área que mais contrata programadores em todo o mundo, sendo a maior porta de entrada para a área da tecnologia.
Por que a programação se tornou a profissão mais promissora da atualidade?
Nunca o mundo necessitou tanto de programadores como atualmente. Com a quarentena estabelecida pela Covid-19, lojas, restaurantes, escritórios e escolas, que tiveram suas atividades paralisadas, perceberam a urgente necessidade de adaptar seus negócios para o mundo digital.Em contrapartida as empresas de tecnologias, durante esse período, cresceram como nunca tanto em faturamento quanto em número de usuários.Com isso a necessidade de programadores cresceu muito. Empresas de grande e pequeno porte estão com vagas abertas e não conseguem contratar por falta de profissionais qualificados. No momento estima-se que o número de oportunidades no Brasil seja acima de 200 mil!
Como faço para começar a estudar?
Programação é um universo amplo, existem muitos caminhos e por isso é muito fácil se perder. Nosso conselho é: NÃO ESTUDE SOZINHO. Infelizmente 78% das pessoas que começam a estudar sozinhas desistem da profissão por não conseguirem aprender. Com uma boa orientação elas teriam conseguido!Se você tomou a decisão de entrar nesse mercado, faça um investimento no seu futuro e busque aprender com quem sabe. Isso vai triplicar suas chances de dominar a programação e conquistar uma vaga no mercado.
Em quanto tempo de estudo vou me tornar um programador?
O tempo depende, claro, da dedicação de cada estudante. A DevMedia ensina programação há 20 anos e com toda essa experiência montamos uma metodologia que tem como objetivo principal acelerar os seus estudos.Você terá um Plano de Estudo para te orientar em todos os passos do aprendizado. Desenvolverá diversos projetos reais para colocar em prática os conhecimentos e contará com o melhor suporte ao aluno da web. Todas as suas dúvidas serão respondidas de imediato.Seguindo nossa metodologia e se dedicando, entre 6 meses e um ano você já estará programando.
Sim, você pode se tornar um programador e não precisa ter diploma de curso superior!
Ser programador é uma das maiores oportunidades que o Brasil oferece para quem não tem condições de fazer uma faculdade. Muitas empresas contratam sem fazer questão de diploma, o que importa para elas é que o candidato seja um bom técnico e consiga atender suas necessidades.Os salários iniciais para programadores são de R$2.500 mil, podendo chegar aos R$15 mil para aqueles que se dedicam.Com disciplina e um estudo correto, que não te faça perder tempo, é possível se tornar um programador em menos de um ano de estudo.Quando você já estiver empregado, aí sim você pode se aprimorar ainda mais fazendo uma faculdade na área.
O que eu irei aprender estudando pela DevMedia?
Nossas trilhas de estudo te permitem virar um programador Full Stack, que é aquele programador mais completo, ele domina o desenvolvimento Front-end, Back-end e Mobile.Você ficará apto para criar sistemas para computadores e aplicativos para celulares. Utilizamos como base a linguagem JavaScript que é a linguagem mais utilizada no mundo. Outra vantagem do JavaScript é a quantidade de oportunidades no mercado de trabalho. É sem dúvida a linguagem que mais possui vagas e a que mais dá oportunidade para os iniciantes.
Principais diferenciais da DevMedia
Suporte ao aluno - O aluno conta com a ajuda de professores para tirar dúvidas durante toda a jornada de ensino. As perguntas são respondidas em menos de uma hora por professores experientes e atuantes no mercado.Gamificação - A plataforma de ensino é divertida e motivante. É como se o aluno estivesse dentro de um game. Ele terá seu card pessoal, que poderá ser customizado utilizando as moedas que ele ganha quando acerta os exercícios. Ele poderá também trocar suas moedas por outros produtos dentro da plataforma. Além disso, seus acertos contam pontos no ranking mensal dos alunos. Tudo isso deixa os estudos mais leves e motivantes.Didática - A DevMedia já ensina programação há mais de 20 anos. Desenvolvemos ao longo desse tempo uma metodologia que ensina a programar de verdade, com menos aulas e mais prática, são dezenas de projetos e exercícios que desenvolvem a mente programadora no aluno.Projetos reais - Durante os estudos os alunos irão desenvolver dezenas de projetos em cada uma das carreira (front-end, back-end e mobile). Mas o principal é que os projetos da DevMedia não são “copia e cola” como se encontra por aí. Aqui o aluno vai desenvolver os projetos de forma autônoma, recebendo claro a nossa mentoria e suporte, mas o aluno terá condições para desenvolvê-los sozinho.Milhares de exercícios - Programação é prática, por isso a cada nova matéria o aluno passará por um bloco de exercícios para fixar o conteúdo e cada acerto será bonificado com pontos e moedas e valem uma posição no ranking dos alunos.
Qual o investimento financeiro que preciso fazer para me tornar um programador?
Na internet é possível encontrar cursos de todos os preços, desde 50,00 a R$15.000,00.Os cursos de 50,00 são cursos avulsos, que explicam apenas pedaços de uma determinada matéria. Para criar um conhecimento completo você precisaria comprar no mínimo de 15 a 20 cursos avulsos e correria o risco deles não se complementarem tão perfeitamente e seu conhecimento ficaria cheio de "buracos".Os cursos de R$15.000,00 não fazem nenhum sentido. Deixe para investir em cursos caros quando quiser se especializar. Por esse preço você pode inclusive estudar fora do pais. Na DevMedia, você terá um plano de estudo montado por quem já formou mais de 100 mil alunos, e já está nesse mercado há mais de 20 anos. Somos a única plataforma que oferece Suporte ao Aluno em tempo real e uma experiência de estudos gamificada para te manter motivado durante todo o período de estudo. E o melhor, nosso pagamento é recorrente, você não precisa usar o limite do seu cartão de crédito para investir no seu futuro. Aproveite para se matricular agora mesmo.
Como funciona a forma de pagamento da DevMedia?
Para que você possa investir nos seus estudos sem complicar sua vida financeira, a DevMedia cobra o valor da assinatura de forma recorrente, Igual o Netflix. Todos os meses debitamos o valor da parcela em seu cartão de crédito, sem comprometer o limite total do cartão. :)As primeiras 3 parcelas custam R$89,90 e a partir do 4o mês sua parcela diminui para R$49,90! Assim ela pesa cada vez manos no seu bolso!Nesse modelo, a gente te ajuda a pagar seus estudos, mas você precisa ajudar a gente a pagar nossos custos. Por isso a assinatura recorrente tem uma fidelidade de um ano. Essa fidelidade também vai te ajudar a se manter comprometido com os seus estudos.Temos um trato?
Eu sabia pouquíssimas coisas de programaçăo antes de começar a estudar com
vocęs, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa
bagagem consegui um estágio logo no início do meu primeiro
período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo. Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento! Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a
pena, pois a plataforma é bem intuitiva e muuuuito
didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito
obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento
front-end, tinha coisas que eu ainda năo tinha visto. A
didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado,
adorando demais.
Adquiri o curso de vocęs e logo percebi que săo os melhores do Brasil. É
um passo a passo incrível. Só năo aprende quem năo quer.
Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido
bastante com a plataforma. Vocęs estăo fazendo parte da minha jornada nesse mundo da
programaçăo, irei assinar meu contrato como programador
graças a plataforma.
Wanderson Oliveira
Comprei a assinatura tem uma semana,
aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que năo tem
como năo aprender, estăo de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tăo presente na vida acadęmica de
seus alunos, parabéns!
Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com
React!
Adauto Junior
Já fiz alguns cursos na área e nenhum é tăo bom quanto o de vocęs. Estou aprendendo
muito, muito obrigado por existirem. Estăo de parabéns... Espero um dia conseguir um emprego na
área.