Modelagem e projeto de banco de dados com o DBDesigner – Parte 02
Por Willian Bolzan
Dando continuidade aos artigos que tratam de ferramentas de modelagem e projeto de banco de dados, onde foram discutidas as ferramentas ERwin e PowerDesigner, o objetivo deste artigo é apresentar a ferramenta DBDesigner.
Gerando o modelo físico com o DBDesigner
Para implementarmos o banco de dados, devemos elaborar o que chamamos de modelo físico de banco de dados. Para gerarmos o modelo físico, devemos primeiramente criar uma conexăo com o SGBD, no caso, o MySQL. Isso pode ser feito da seguinte forma: escolha o menu Database | Connect to Database, será aberta a janela de diálogo apresentada pela Figura 1.
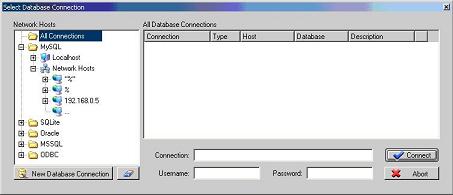
Figura 1. Janela de conexăo ao banco de dados.
A janela de conexăo com o SGBD é dividida em duas principais áreas, ŕ esquerda visualizamos a estrutura de hosts e á direita as conexőes com os banco de dados. Como ainda năo temos um banco de dados, temos que criá-lo, para depois fazermos a conexăo com ele. Isso pode ser feito da seguinte forma:
1. clique em Localhost para criarmos um banco de dados na máquina local. Veja na Figura 2 onde aparecem os banco de dados existentes e uma opçăo para criá-lo.
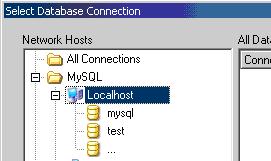
Figura 2. Exibindo/criando banco de dados.
2. Clique no ícone rotulado com [...];
3. Será apresentada uma tela para a entrada do nome do banco de dados. Digite o nome do banco e confirme. No nosso exemplo, definimos o nome do banco como sendo LOCADORA.
Com o banco criado, podemos nos conectar a ele. Para criar uma nova conexăo, basta arrastar o banco de dados LOCADORA para o lado direito da janela, onde definimos as conexőes. Feito isto, teremos um resultado como o apresentado na Figura 3.
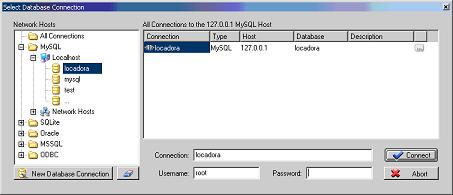
Figura 3. Estabelecendo conexăo ao banco.
Tendo definido o banco de dados e sua conexăo, basta clicar no botăo Connect para conectarmos ao SGBD MySQL e ao banco de dados LOCADORA. Para se certificar que a conexăo foi estabelecida, verifique a extremidade inferior direita da barra de status.
Após essa fase de conexăo podemos realizar uma importante funçăo da ferramenta DBDesigner, a sincronizaçăo.
Sincronizaçăo
Até aqui criamos um banco de dados (LOCADORA) e estabelecemos uma conexăo com ele. Para realizarmos a implementaçăo do banco propriamente dita, ou seja, a criaçăo das tabelas, relaçőes, etc, temos que efetuar o processo chamado sincronizaçăo (Sysnchronisation). Ela permite que todas as alteraçőes feitas no modelo sejam refletidas no banco de dados.
Para realizar a sincronizaçăo com o banco de dados, basta escolher o menu Database | Database Sysnchronisation. Se já estivermos conectados ao SGBD, a tela apresentada pela Figura 4 surgirá.
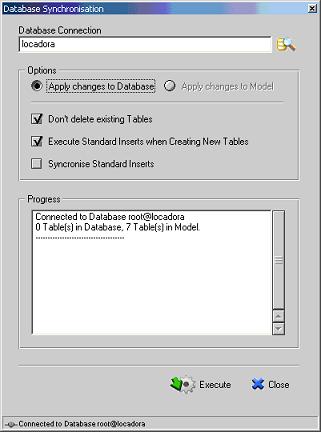
Figura 4. Sincronizaçăo com o banco de dados.
Clicando no botăo Execute, todas as tabelas, campos, índices, relaçőes serăo implementados no banco de dados LOCADORA.
Exportando o script
Uma opçăo interessante da ferramenta DBDesigner é a possibilidade de exportarmos o script gerado. Para fazę-lo, escolha o menu File | Export | SQL Create Script. A Figura 5 apresenta as opçőes para a exportaçăo.
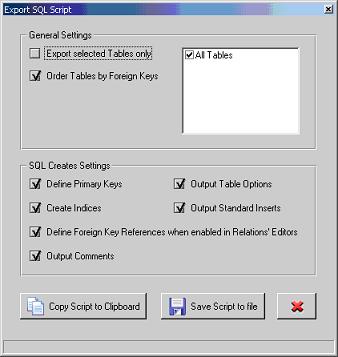
Figura 5. Opçőes de exportaçăo.
Após salvar o script clicando no botăo Save Script to file, podemos visualizar o conteúdo do arquivo para analisar como a ferramenta gerou o script de nosso projeto. A Listagem 1 apresenta parte do script gerado referente ŕ tabela FILME.

Listagem 1. Script para criaçăo da tabela FILME.
Manipulaçăo de dados
Para manipularmos os dados em nosso banco de dados, devemos clicar no botăo correspondente na paleta de ferramentas, para trocar do modo de projeto (Designer Mode) para o modo de consultas (Query Mode). Veja a Figura 6. Nesta tela, consultas podem ser facilmente construídas por apenas comandos de arrastar e soltar.
Figura 6. Modo de manipulaçăo de dados (Query Mode)
Inserindo dados
A maneira mais fácil para realizarmos a inserçăo de dados é a seguinte: clique com o botăo direito do mouse sobre a tabela na qual deseja inserir dados e escolha a opçăo Edit Table Data. Surgirá a janela apresentada na Figura 7 na qual será possível escolher a tabela e inserir os dados, sem o uso de instruçőes SQL.
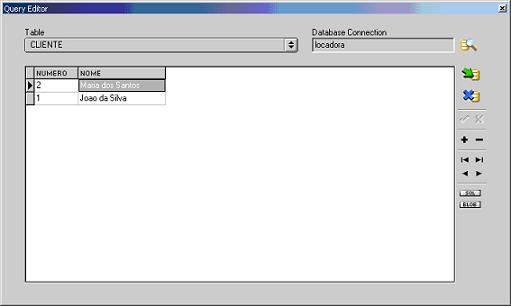
Figura 7. Janela de manipulaçăo de dados.
Uma outra forma de inserir dados é construindo comandos em SQL. Vamos considerar neste exemplo a tabela CLIENTE. Clique e segure o botăo sobre a tabela desejada (CLIENTE) e em seguida mova o cursor para baixo. Dessa forma surgirá um menu onde várias instruçőes SQL estarăo disponíveis, como mostra a Figura 8.
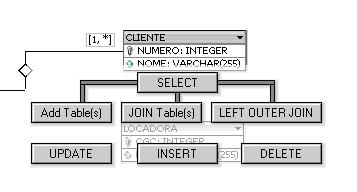
Figura 8. Menu para manipulaçăo de dados.
Assim que o cursor do mouse estiver sobre a instruçăo desejada, no caso a instruçăo INSERT, libere o botăo e veja que a estrutura da instruçăo INSERT será visualizada na área de ediçăo de comando. Com isso, podemos inserir os dados desejados. Após digitarmos o comando, devemos clicar no botăo Execute SQL Query para que a instruçăo seja aplicada ao banco de dados.
Consultando dados
Veremos agora como consultar os dados existentes em nosso banco de dados. Proceda da mesma forma explicada na seçăo anterior, ou seja, clicando sobre a tabela e mantendo o botăo pressionado, em seguida mova o cursor para baixo até que o menu apareça. Solte o botăo sobre a instruçăo desejada, no caso a instruçăo SELECT.
Engenharia reversa
Até aqui, estamos seguindo o processo normal de desenvolvimento de banco de dados, ou seja, a construçăo do modelo conceitual, lógico e físico. No processo de engenharia reversa, a seqüęncia é inversa, ou seja, a partir do modelo físico chega-se ao modelo lógico.
Para exemplificar, vamos criar um banco de dados chamado LIVRARIA através do script da Listagem 2, no qual temos a definiçăo de tręs tabelas: EDITORA, AUTOR e LIVRO.
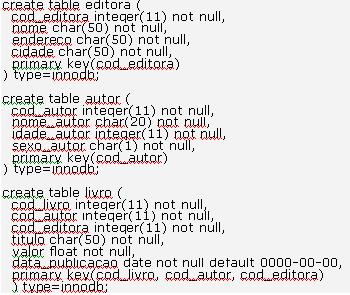
Listagem 2. Script para a criaçăo das tabelas EDITORA, AUTOR e LIVRO.
Para que as relaçőes entre as tabelas sejam também definidas no modelo lógico, devemos criar os respectivos campos que săo estrangeiros ŕ tabela como sendo chaves primárias, que é o caso, no nosso exemplo, dos campos cod_autor, cod_editora da tabela LIVRO que referenciam as respectivas tabelas AUTOR e EDITORA, além, é claro do campo cod_livro que identifica a tabela LIVRO, mas NĂO devemos especificar que săo chaves estrangeiras com a clausula FOREIGN KEY (<NOME_CAMPO>) REFERENCES <NOME_TABELA>, dessa forma, deixamos para a ferramenta, durante o processo de reengenharia, definir as relaçőes baseando-se nas chaves primarias das tabelas.
Tendo o script para a criaçăo das tabelas de nosso banco, podemos fazer a implementaçăo de duas formas:
· digitarmos o script na área destinada ŕ codificaçăo de comandos SQL e o executarmos, ou;
· criando um arquivo com o script acima utilizando qualquer editor de texto simples e depois carregando-o.
Utilizando qualquer uma das formas de criaçăo do banco listadas acima, o processo de engenharia reversa pressupőe os seguintes passos:
1. Geralmente o processo de engenharia reversa deve ser feito partindo-se de um modelo vazio, ou seja, devemos criar um novo modelo e entăo dar início ao processo;
2. Altere para o modo de consulta, clicando no botăo Change Query Mode na barra de ferramentas;
3. Digite ou carregue (clique com o botăo direito do mouse sobre área de codificaçăo e escolha a opçăo Load SQL Script From File) o script criado anteriormente referente ŕ criaçăo das tabelas do banco de dados LIVRARIA. Feito isto, clique no botăo Execute SQL Query (ver Figura 9);
4. A janela Connection Database será visualizada. Crie um novo banco de dados e defina sua conexăo. Neste exemplo, vamos criar um banco de dados novo com o nome de LIVRARIA (conforme explicado anteriormente na seçăo). Após criarmos o banco de dados e definirmos suas tabelas, devemos, entăo, escolher menu Select | Reverse Engineering. A janela de diálogo Database Connection será apresentada. Selecione a conexăo com o banco de dados a partir da qual será feita a reengenharia e estabeleça a conexăo;
Figura 9. Criando o modelo físico.
5. Após estabelecer a conexăo com o banco de dados, vocę verá uma janela conforme a Figura 18.
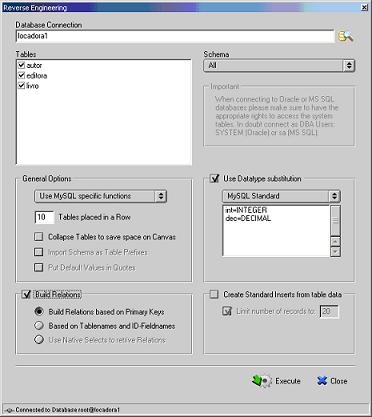
Figura 10. Janela com opçőes para engenharia reversa.
Esta janela oferece algumas opçőes para realizar o processo. Considerando os mais importantes neste pequeno exemplo, marque as tabelas (Tables) que serăo convertidas (por padrăo todas já săo automaticamente marcadas) e sobretudo, a opçăo denominada Build Relations e em seguida, marque também, a opçăo Build Relations base don Primary Keys. Essa opçăo estabelece que as relaçőes entre as tabelas serăo criadas conforme as chaves primárias das tabelas, conforme dito anteriormente.
Após clicar no botăo Execute teremos o resultado da engenharia reversa como podemos ver na Figura 11.
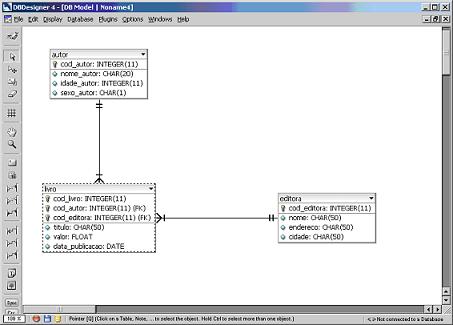
Figura 11. Resultado da engenharia reversa.







