Um dos pilares do novo sistema operational da Microsoft, codename Longhorn, È o novo sistema de arquivos chamado WinFS. OPath È uma linguagem de consulta utilizada por WinFS para recuperar e selecionar objetos a partir de uma fonte de dados. Este artigo apresenta as razıes para a criaÁ„o de uma nova linguagem de consulta e introduz seus conceitos b·sicos. Ser„o apresentados tambÈm exemplos simples de filtros OPath que resultam em consultas de complexidade mÈdia.
Linguagem de Consulta
A OPath È chamada linguagem de consulta (Query Language), e n„o uma linguagem genÈrica de programaÁ„o. O objetivo da linguagem OPath È permitir que o programador expresse com exatid„o quais objetos deseja recuperar de uma base de dados. A OPath n„o apresenta, pelo menos por enquanto, nenhuma sintaxe para controle de fluxo (comandos do tipo IF, WHILE, entre outros) ou para criaÁ„o de novos tipos e classes, aspectos tÌpicos de uma linguagem de programaÁ„o.
O membro mais famoso das linguagens de consulta È a linguagem SQL (Structured Query Language), amplamente adotada pela maioria dos bancos de dados relacionais. Um dos benefÌcios da linguagem SQL È possibilitar que o gerenciador de banco de dados receba um comando semelhante a Select ClienteID, Nome from Clientes e recupere as informaÁıes desejadas sem que o cliente tenha conhecimento dos detalhes de como tais informaÁıes foram armazenadas em disco ou recuperadas, qual o formato fÌsico dos registros de cada tabela, qual a representaÁ„o bin·ria dos tipos de cada coluna e outras caracterÌsticas que sÛ importam ao gerenciador de banco de dados.
O propriet·rio da tabela Clientes tem a flexibilidade de adicionar ou remover colunas da tabela (exceto as colunas ClienteID e ClienteName), sem prejudicar a execuÁ„o do comando. Cabe ao gerenciador de banco de dados encapsular toda a complexidade envolvida na persistÍncia dos dados num disco rÌgido. Da mesma forma, a linguagem OPath possibilita encapsular toda a complexidade envolvida na persistÍncia de objetos na camada de persistÍncia de objetos, o que permite maior flexibilidade para o programador. Na seÁ„o abaixo, veremos no que consiste esta complexidade.
Classes e Tabelas
A adoÁ„o de linguagens de programaÁ„o orientadas a objeto È inquestion·vel. Linguagens tradicionalmente n„o orientadas a objeto, por exemplo, Visual Basic ou Cobol, j· apresentam versıes que usufruem dessa tÈcnica, ajudando a disseminar tal tecnologia para um p˙blico antes restrito a pr·ticas consideradas ultrapassadas. Uma maneira comum de o sistema orientado a objetos resolver um problema È atravÈs de projeto de classes ou hierarquias de classes, definindo os relacionamentos corretos entre as inst‚ncias destas e persistindo as informaÁıes ali armazenadas em tabelas num banco de dados relacional. Mover os dados do mundo orientado a objeto para o mundo relacional pode parecer uma tarefa trivial, mas na realidade È um antigo problema, que pode ser bastante complexo. O .Net Framework tornou este problema ainda mais complexo j· que orientaÁ„o a objetos È o conceito fundamental no cÛdigo gerenciado. … muito f·cil encontrarmos profissionais de inform·tica com d˙vidas do gÍnero ìpor onde comeÁo o projeto de um sistema multicamadas, pela modelagem das classes ou pela modelagem das tabelas do banco de dados?î. Independentemente de onde vocÍ comeÁar, com certeza precisar· gastar um bom tempo fazendo o mapeamento de um modelo para outro. E qual o mapeamento adequado entre as classes e tabelas: uma classe para cada tabela ou v·rias tabelas para cada classe? Ser· que as regras de normalizaÁ„o de um banco de dados relacional devem ser mantidas?
N„o seria interessante se existisse uma camada de software que encapsulasse essa complexidade de mapeamento de classes e tabelas e que possibilitasse ao programador mudar radicalmente o mapeamento, sem que o cÛdigo cliente sofresse algum impacto? A Microsoft vem trabalhando continuamente para disponibilizar essa infra-estrutura para o desenvolvedor, e a linguagem de consulta para interagir com esta camada ser· a OPath.
OPath
OPath È o meio pelo qual vocÍ expressa critÈrios de seleÁ„o para a camada de persistÍncia de objetos e como resultado recebe os objetos que satisfazem tal critÈrio. Para os que conhecem a linguagem XPath, n„o ser· difÌcil aprender a OPath, pois ela baseia-se nos conceitos de navegaÁ„o da linguagem XPath, j· que as arvores semi-estruturadas XML s„o semelhantes aos grafos de objetos.
Veja um exemplo: imagine o seguinte conjunto de classes apresentado na Listagem 1 em C#. Suponha que vocÍ queira recuperar todos os clientes que possuem ordens de compra. Em OPath vocÍ escreve a seguinte express„o:
Exists(Clientes.Compras)
Vamos restringir ainda mais a seleÁ„o para os clientes que possuem compras entre 10 e 20 de fevereiro.
Exists(Clientes.Compras[DataCompra>='10/02/2004' and DataCompra < ='20/02/2004'])
Podemos restringir ainda mais os clientes para apenas aqueles clientes que compraram produtos com preÁo superior a 100 reais.
Exists(Clientes.Compras[DataCompra>='10/02/2004' and DataCompra<='20/02/2004'].Items[Preco>100])
As trÍs expressıes s„o exemplos b·sicos que n„o exigiram nenhuma construÁ„o mais complexa. Para acessar a propriedade de um objeto, o desenvolvedor deve utilizar o operador '.', ou seja, para acessar a lista de compras dos clientes escreve-se a express„o Clientes.Compras. Uma vez selecionada a lista desejada, podemos adicionar critÈrios de seleÁ„o, conhecidos tambÈm como predicados, utilizando os colchetes. Todas as expressıes dentro dos colchetes tÍm como escopo o objeto especificado ý esquerda do colchete esquerdo. Quando escrevemos Clientes.Compras[DataCompra ='17/02/2004'], a propriedade DataCompra se refere ao objeto especificado ý esquerda do colchete, neste caso, a lista de objetos do tipo OrdemCompra. Portanto s„o dois os conceitos essenciais que vocÍ precisa apreender para escrever expressıes OPath; o primeiro consiste em como navegar a partir de um objeto para outro, utilizando o operador '.'; e o segundo em como descrever critÈrios de seleÁ„o para filtrar apenas os objetos desejados, utilizando os predicados dentro dos colchetes.
Agora vamos traduzir estas expressıes OPath para a linguagem SQL. Veremos que os comandos SQL equivalentes n„o s„o t„o simples assim. Como nosso modelo de classe È simples, adotaremos o mapeamento de um para um, conforme mostrado na Figura 1. Cada classe ser· armazenada em uma tabela.
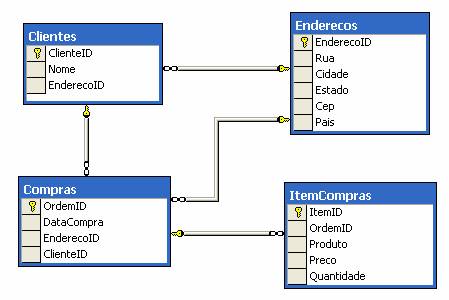
O primeiro filtro pode ser traduzido para SQL como:
Select Clientes.* From Clientes
Where exists(
select 1 from Compras
Where Clientes.ClienteID=Compras.ClienteID)
Para o segundo filtro, temos:
Select Clientes.* From Clientes
Where exists(
select 1 from Compras
where Clientes.ClienteID=Compras.ClienteID
and Compras.DataCompra between '10/02/2004'
and '20/02/2004')
E, para o terceiro filtro, temos:
Select Clientes.* From Clientes
Where exists(
select 1 from Compras
join Items on Compras.OrdemID = Items.OrdemID
where Clientes.ClienteID=Compras.ClienteID
and Compras.DataCompra between '10/02/2004'
and '20/02/2004' and Item.Preco > 100)
Esses comandos SQL podem ser reescritos de forma semelhante a exposta. Observe o terceiro filtro e compare com a express„o OPath equivalente. A express„o OPath È bem mais simples, j· que ela oculta a complexidade de fazer os joins entre as trÍs tabelas envolvidas e coloca os critÈrios de seleÁ„o na posiÁ„o correta. Cabe ý camada de persistÍncia de objetos traduzir as expressıes OPath nos comandos SQL equivalentes (tanto semanticamente como da maneira mais otimizada possÌvel), eliminando a necessidade de se escrever manualmente tais comandos SQL. Para traduzir uma express„o OPath, a camada de persistÍncia necessita do mapeamento entre as classes e seus relacionamentos, e entre as tabelas e seus relacionamentos. O fato de esse mapeamento poder ser alterado durante o ciclo de desenvolvimento, sem nenhum ou praticamente nenhum impacto no cÛdigo cliente, proporciona ao desenvolvedor a rapidez e agilidade necess·rias para atender ýs constantes mudanÁas nos requisitos de um projeto.
Public class Cliente
{
Public string Nome;
Public Nullable Endereco;
Public Collection Compras;
}
Public class Endereco
{
Public string Rua;
Public string Cidade;
Public string Estado;
Public string Cep;
Public string Pais;
}
Public class OrdemCompra
{
Public DateTime DataCompra;
Public Nullable EnderecoEnvio;
Public Collection Items;
}
Public class ItemCompra
{
Public string Produto;
Public decimal Preco;
Public int Quantidade;
}
Conclus„o
Este artigo apresentou os conceitos fundamentais da nova linguagem de consulta OPath, sua relaÁ„o com outras linguagens (como SQL) e exemplos b·sicos de sua sintaxe. Saber escrever consultas em OPath È requisito b·sico para desfrutar dos benefÌcios do novo sistema de arquivos denominado WinFS, um dos pilares do prÛximo sistema operacional da Microsoft (codenome Longhorn). O cronograma do sistema operacional Longhorn prevÍ o lanÁamento da vers„o Beta ainda no ano 2004, e a vers„o final ao tÈrmino do ano 2005.








