Este artigo tem como objetivo apresentar o processo de otimizaçăo do banco de dados MySQL, bem como introduzir os aspectos que devem ser considerados durante o ajuste deste SGBD (Sistema Gerenciador de Banco de Dados). Este é o primeiro artigo de uma série que discutirá possibilidades de otimizaçăo do MySQL, abordando a otimizaçăo de consultas, a otimizaçăo do SGBD propriamente dito, e o ajuste do Sistema Operacional (SO) e do hardware que suportarăo o seu sistema como um todo. Os artigos seguintes apresentarăo os detalhes envolvidos em cada uma das partes apresentadas anteriormente.
Para a otimizaçăo de um SGBD precisamos eliminar os possíveis problemas de desempenho existentes em todos os níveis do sistema, isto é, precisamos identificar as consultas lentas que eventualmente săo submetidas ao banco. Precisamos ainda melhorar as configuraçőes do servidor de banco de dados, do sistema operacional, e finalmente o hardware que suportará toda o sistema. Alguns aspectos da otimizaçăo năo se aplicam somente ao MySQL, e sim a todos os SGBDs, por isto algumas metodologias apresentadas aqui podem, em alguns casos, ser aplicadas também a outros SGBDs disponíveis no mercado.
Antes de explorarmos os itens apresentados anteriormente é necessário ressaltar que o processo de otimizaçăo năo é trivial, visto que é preciso medir todos os aspectos do seu sistema para o entendimento preciso do funcionamento da sua aplicaçăo. Assim, pode-se obter o ajuste que seja mais adequado ŕ sua necessidade, por exemplo, o ajuste do SGBD para aplicaçőes de leitura é diferente daquele onde prevalecerăo escritas. Além disto, as mediçőes de desempenho do seu sistema săo imprescindíveis dado que estas servirăo de referęncia para determinar se uma alteraçăo realizada no SGBD teve efeitos positivos ou năo.
O primeiro ponto a ser discutido é a otimizaçăo das consultas SQL. A interface da aplicaçăo com o SGBD é feita a partir de consultas SQL, ou seja, esta é a linguagem que permite a extraçăo das informaçőes armazenadas pelo SGBD. Portanto, durante o processo de projeto da sua base de dados, é preciso vislumbrar os tipos de consultas que serăo mais comuns e criar a base de forma que o processo de extraçăo de dados seja facilitado. Além disto, é preciso escrever as consultas de forma que as mesmas sejam executadas no menor tempo possível. Mas, também é preciso monitorar as consultas lentas que eventualmente existam, e eliminá-las, seja pela reescrita da consulta ou até mesmo através da alteraçăo da sua aplicaçăo de forma a fazer um acesso mais eficiente ao banco. Este deve ser um ponto de averiguaçăo constante, já que em ambiente onde há um número elevado de consultas e estas consomem muito tempo de serem processadas, isto criará uma deficięncia considerável em termos de desempenho. Para a otimizaçăo de consultas é preciso entender a forma como as mesmas săo processadas pelo MySQL, e assim, deve-se tentar atuar em cada etapa visando a reduçăo do tempo de processamento das mesmas, gerando um ganho global considerável. No próximo serăo discutidas as etapas de execuçăo de uma consulta, bem como técnicas para o monitoramento destas consultas e da visualizaçăo do plano de execuçăo das mesmas.
Uma vez eliminados os problemas relativos ŕs consultas SQL, pode-se modificar as configuraçőes do MySQL de forma a fazer um uso mais apropriado dos recursos disponíveis no SO, melhorando assim o desempenho do banco. Para isto é preciso entender como o MySQL funciona internamente, isto significa dizer que precisamos entender como o MySQL utiliza memória e disco, bem como quais săo os principais parâmetros que podemos alterar para atingir este ganho. O MySQL apresenta um conjunto de ferramentas para o monitoramento do servidor de forma a detectar quais săo os gargalos do seu sistema, e assim permitindo a eliminaçăo dos mesmos. Estes aspectos serăo abordados em detalhes nos terceiro artigo referente ŕ otimizaçăo do MySQL.
Finalmente, precisamos aferir e monitorar o desempenho do SO que suportará todo o sistema, além do hardware e suas configuraçőes. No sistema operacional podemos utilizar recursos mais apropriados para o banco, tais como sistema de arquivos mais eficientes, processos e threads nativas, além da escolha de um SO mais apropriado ao MySQL. Esta escolha pode, em alguns casos, gerar ganhos de desempenho em torno de 50%. Por último, mas năo menos importante, é a escolha do hardware adequado. Por exemplo, ao utilizar-se de um processador de 64 bits é possível a utilizaçăo de arquivos grandes, além de permitir a alocaçăo de uma quantidade maior de memória. Isto, possibilita a configuraçăo de buffers de memória maiores para o MySQL, melhorando consideravelmente o desempenho.
A seguir vamos conhecer o processo de execuçăo de consultas no MySQL, visando assim possibilitar a elaboraçăo das consultas SQL de forma a serem executadas no menor tempo possível.
O processo de execuçăo de uma consulta no MySQL consiste de várias etapas que săo o parser, otimizaçăo, execuçăo e retorno dos dados. A Figura 1 apresenta uma visăo geral deste processo.
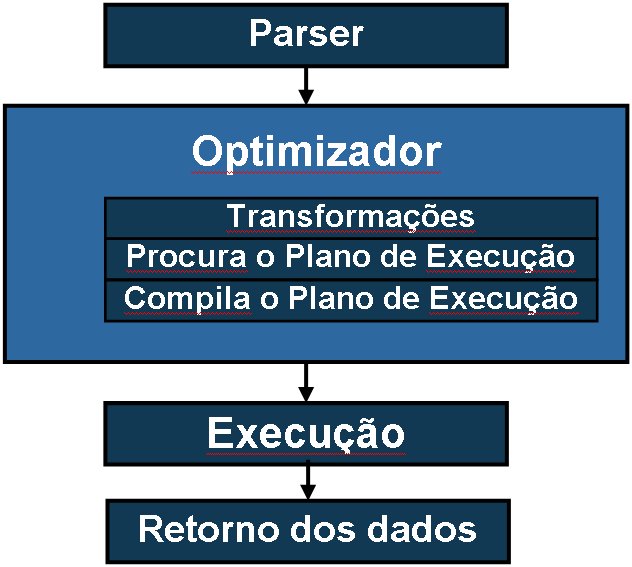
Figura 1: Etapas da execuçăo de consultas SQL
Durante o parser o MySQL faz a leitura do comando SQL enviado pelo cliente, converte o comando para um formato binário interno e entăo o envia ao otimizador. Neste caso, este processo será executado para cada consulta enviada ao servidor, portanto, é necessário reduzir este tempo para produzir um ganho de desempenho. Uma alternativa interessante é a utilizaçăo dos Prepared Statements, disponíveis a partir da versăo 4.1. Este recurso permite a criaçăo de um comando no qual será realizado o parser e o binário dele será armazenado no servidor. Desta forma, este comando poderá ser executado várias vezes tendo sido feito apenas um procedimento de parser, o que certamente implicará em reduçăo no tempo de execuçăo. Os Prepared Statements năo serăo abordados neste artigo, ficando fora do escopo deste texto.
A segunda etapa é a otimizaçăo da consulta, onde o otimizador decide a ordem de leitura das tabelas, qual o índice ele irá utilizar, caso exista o índice, e finalmente o tipo de leitura que será realizada na tabela, ou seja, o algoritmo de busca dos dados. As decisőes tomadas pelo otimizador săo baseadas em estatísticas que o próprio servidor armazena. Por exemplo, ele avalia a quantidade de registros por tabela, a quantidade de dados duplicados para cada chave existente, e assim optará pelo plano de execuçăo que gerar o menor custo e tempo para ser executado. Vale ressaltar, que o processo de otimizaçăo se baseia em heurísticas e nem sempre o caminho percorrido é o melhor. Por isto, existem dicas que podem ser dadas para o otimizador de forma a induzir o MySQL a escolher o plano de execuçăo que vocę desejar. Por exemplo, se vocę sabe que as tabelas devem ser lidas na ordem A,B e năo B,A, vocę pode utilizar o STRAIGHT_JOIN para forçar a ordem de leitura. A mesma lógica pode ser utilizada para os índices, vocę pode forçar o MySQL a utilizar ou ignorar um determinado índice. Portanto, se vocę conhece qual a melhor forma de executar a sua consulta informe isto para o otimizador e desta forma vocę minimizará o tempo para a geraçăo do plano de execuçăo, já que nenhuma decisăo será delegada para o otimizador, isto novamente acarretará um ganho no tempo de resposta.
Uma vez determinado o plano de execuçăo, o MySQL deverá extrair os dados armazenados no disco. Portanto, se vocę possui áreas de memória grandes, os dados poderăo ser mantidos nestes buffers e o acesso aos discos, que em geral é mais lento, será evitado e o tempo para a busca da informaçăo será reduzido. Vale lembrar que o MySQL trabalha com o esquema de Storage Engines (Tipos de tabelas), e para cada tabela utilizada caberăo otimizaçőes específicas. Estas configuraçőes serăo abordadas com mais detalhes em outro artigo.
Finalmente, uma vez que os dados foram recuperados da memória ou disco, estes devem ser enviados para o cliente através da conexăo que foi estabelecida entre ele e o servidor. Neste caso, quanto maior o seu resultado maior será o tempo para envio dos dados. Assim, algumas práticas podem ajudar a minimizar este tempo, por exemplo, evitar o uso de SELECT *. Liste somente os dados necessários, caso vocę precise de duas colunas especifique-as em seu comando, assim nenhuma informaçăo desnecessária será enviada. Além disto, vocę poderá reduzir o tamanho dos dados através do uso do LIMIT, que permite obter apenas as primeiras linhas de dados ou até mesmo deslocamentos no resultado. Por exemplo, um SELECT ... LIMIT 10, 20 retornará 20 registros a partir do décimo primeiro registro do seu conjunto resultante. Por último, no MySQL 4.1 vocę poderá fazer uso do protocolo binário, que permite o tráfego de informaçőes compactadas entre o cliente e o servidor, reduzindo o volume a ser transmitido através desta conexăo, reduzindo assim o tempo para envio do resultado e por conseqüęncia o tempo de execuçăo do comando.
Veremos agora técnicas para a detecçăo das consultas lentas e métodos para a avaliaçăo do plano de execuçăo de uma consulta.
O MySQL possui um log chamado “slow log”, onde săo armazenadas todas as consultas cujo tempo de execuçăo seja maior que o parâmetro long-query-time, que por padrăo é 10 segundos. Além disto, pode-se configurar este log para armazenar também as consultas que năo utilizam índices ou que realizam um SELECT *. Por padrăo este log vem desabilitado, e pode ser ativado através do parâmetro log-slow-queries. Ao executar o comando STATUS, o MySQL irá exibir dentre outras informaçőes o SLOW QUERIES, que é o número de consultas lentas recebidas pelo servidor, contado desde um o início da execuçăo do MySQL, ou desde o último FLUSH STATUS. Caso o slow log esteja ativo, o que é recomendado, estas consultas serăo gravadas neste arquivo e possibilitarăo a identificaçăo dos comandos que săo os gargalos do seu sistema.
Uma vez detectadas as consultas lentas é preciso avaliar como o MySQL está executando estes comandos. Para isto faz-se uso do comando EXPLAIN, que deve ser colocado antes do comando SELECT a ser estudado. Este comando irá exibir o plano de execuçăo escolhido pelo otimizador. O exemplo da Listagem 1 ilustra este recurso para avaliar uma consulta que lista os países da regiăo Nórdica e suas respectivas capitais.
Listagem 1: EXPLAIN de uma consulta feita no MySQL
mysql> EXPLAIN SELECT co.name, ci.name FROM City AS ci, Country AS co WHERE ci.id = co.capital
-> AND co.region LIKE 'Nordic%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: co
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 239
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: ci
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: world.co.Capital
rows: 1
Extra:
2 rows in set (0.01 sec)As tabelas săo lidas pelo otimizador na ordem em que elas aparecem no retorno do EXPLAIN. No exemplo da Listagem 1, o MySQL optou por ler primeiro a tabela Country e depois a tabela City, perceba que a ordem em que as tabelas aparecem no FROM năo foi seguida pelo otimizador. Por isto, quando for desejado que a ordem do FROM seja preservada, é preciso utilizar-se o STRAIGHT_JOIN para induzir o otimizador neste sentido.
Existem diversas informaçőes apresentadas pelo EXPLAIN, a primeira delas é o SELECT_TYPE que mostra o tipo de consulta que está sendo processada. Estas podem ser consultas simples ou sem sub-consultas (SIMPLE) e SUB_QUERY ou UNION para comando que possuem consultas aninhadas. Além disto, o EXPLAIN fornece quais os índices estăo disponíveis para a execuçăo do comando (coluna POSSIBLE_KEYS), e o índice que ele está utilizando para a leitura do dados aparece na coluna KEY (NULL, caso năo esteja fazendo uso de índices).
Vale destacar, que será utilizado apenas um índice para cada tabela lida pelo MySQL, por isto a criaçăo do índice deve ser feita com critério, isto é, sempre compondo as colunas que serăo empregadas no WHERE.
A coluna ROWS fornece o número de linhas lidas pelo MySQL para buscar o resultado, idealmente este número deve ser igual ao número de linhas retornadas pelo comando. A coluna REF indica a coluna utilizada para referenciar tabelas em JOIN (perceba a tabela City), e o EXTRA fornece informaçőes adicionais sobre a execuçăo, tais como, o uso de tabelas temporárias, ordenaçăo, dentre outros.
A coluna TYPE exibe o algoritmo de busca utilizado para a leitura dos dados, a Tabela 1 apresenta os valores possíveis para esta coluna, indo do melhor para o pior tipo.
| Type | Significado |
| System | Tabela apresenta apenas 1 registro. |
| Const | Leitura de apenas um registro da tabela (busca pela chave primária). |
| Eq_ref | Apenas uma linha desta tabela será lida para cada linha da tabela anterior (JOIN de tabelas 1:1). |
| Ref ou Ref_or_null | Leitura de vários registros desta tabela para cada registro lido da tabela anterior (JOIN 1:N), ou pesquisas por faixas de dados utilizando a chave primária. |
| Unique_subquery | Sub-consulta utilizada dentro do IN e esta retorna apenas valores únicos na tabela externa. |
| Index_subquery | Mesmo que o anterior, mas os valores retornados năo săo únicos na tabela externa. |
| Range | Leitura de faixas de dados (>, <, BETWEEN, etc.). |
| Index | Leitura completa nos índices. |
| ALL | Leitura completa dos dados da tabela. |
Tabela 1: Valores possíveis para a coluna TYPE
Percebe-se que no exemplo da Listagem 1, o MySQL está fazendo um ALL (leitura completa) na tabela de países, e entăo faz um EQ_REF com a tabela de cidades, indicando um relacionamento 1:1. Precisamos evitar sempre o ALL, já que a leitura completa na tabela pode ser muito lento e oneroso, especialmente se a tabela contém muitos registros. Além disto, se queremos apenas os países de uma regiăo temos que ler apenas estes dados e năo a tabela inteira. Na verdade o ALL ocorre por que năo há um índice na coluna region da tabela de países, assim para resolver o problema desta consulta seria necessário criar um índice nesta coluna, fazendo com que o MySQL faça um RANGE, o que seria mais rápido.
Abaixo estăo algumas dicas de otimizaçăo que devem estar sempre ŕ mente durante um processo de melhoria de planos de execuçăo de consultas:
- Reescreva a sua consulta de forma a percorrer um menor caminho, por exemplo, utilize as dicas para o otimizador ou sempre utilize campos indexados na cláusula WHERE, ou ainda evite SELECT *;
- Altere a ordem de leitura das tabelas de forma a ler sempre a tabela com menos registros;
- Induza o MySQL a sempre utilizar um índice;
- Indexe novos campos se necessário;
- Compare sempre as colunas indexadas com valores constantes e nunca aplique funçőes ou expressőes ao índice, pois desta forma ele năo será utilizado.
Esta foi uma visăo geral do mecanismo de otimizaçăo de consultas do MySQL, maiores informaçőes a respeito do comando EXPLAIN e do uso de índices podem ser encontradas em www.mysql.com/documentation.
Este é o processo de execuçăo do MySQL, podemos ver que é possível reduzir o tempo de execuçăo através de pequenas alteraçőes em nosso processo de elaboraçăo de consultas.
Abraços e até breve!







