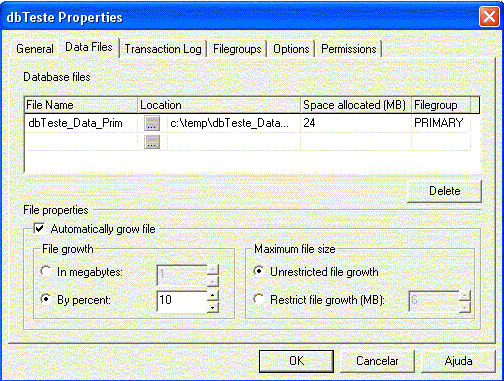
Filegroups s„o estruturas lÛgicas - ou se preferir unidades de gerenciamento - que d„o suporte aos arquivos de dados (=estruturas fÌsicas) de um database. Todo database possui pelo menos um filegroup ñ o filegroup prim·rio, gerado automaticamente no momento da criaÁ„o do database (ver Figura 1)
Pode-se juntar v·rios arquivos fÌsicos num mesmo filegroup, ou criar v·rios filegroups, mas qual a recomendaÁ„o? A resposta È: depende do que vocÍ pretende exatamente :
- Se o disco onde est· localizado o filegroup prim·rio ìestourouî, vocÍ poderia criar uma extens„o do filegroup prim·rio noutra unidade. Nesse caso, vocÍ criaria outro arquivo fÌsico, mas associaria esse arquivo na mesma unidade de gerenciamento ñ PRIMARY ;
- Se vocÍ n„o possui um sistema de RAID de discos, pode obter um significativo aumento de performance distribuindo tabelas e Ìndices em filegroups distintos, localizados em unidades com controladoras especÌficas ñ por exemplo, as tabelas ficam no filegroup PRIMARY na unidade C: e os Ìndices no filegroup FG_Indice na unidade D:. Assim, vocÍ estar· viabilizando threads paralelas para busca nas p·ginas de dados e Ìndices, melhorando a performance como um todo.
Como criar um filegroup secund·rio para armazenamento de Ìndices
Para criar outro filegroup, basta acessar a tela de propriedades do database (ver Figura 1) e adicionar outro filegroup (ver Figura 2).
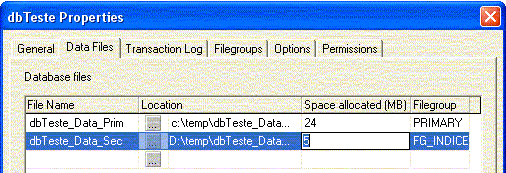
Uma vez adicionado, basta criar tabelas no filegroup PRIMARY e Ìndices no filegroup FG_INDICE. Para especificar o filegroup durante a criaÁ„o de objetos e Ìndices, utilize a cl·usula ON ao final dos comandos CREATE TABLE, CREATE INDEX e ALTER TABLE ... ADD ... PRIMARY-KEY (ver Listagem 1)
create table pedido
(
id_pedido int not null
,dt_emissao smalldatetime not null
,id_emitente int not null
)
ON 'PRIMARY'
go
alter table pedido add constraint pk_pedido primary key clustered (id_pedido) on 'PRIMARY'
go
create nonclustered index ix_pedido on pedido (dt_emissao) on 'FG_Indice'
go
ObservaÁıes:
- Se vocÍ n„o especificar o filegroup na criaÁ„o do objeto, o objeto ser· criado no filegroup default (=PRIMARY) ;
- Pode-se alterar o filegroup default com o comando ALTER DATABASE:
ALTER DATABASE MODIFY FILEGROUP DEFAULT - Como o leaf level do Ìndice cluster ordena as p·ginas de dados da prÛpria tabela, a primary key pk_pedido deve permanecer no filegroup PRIMARY
Conclus„o:
Para obter performance precisamos estar sempre atentos aos detalhes. Se vocÍ n„o possui um sistema de RAID e quer performance, armazene Ìndices n„o cluster numa unidade de disco e filegroup especÌficos - o resultado vale a pena.







