A suíte Pentaho de Inteligęncia de Negócios é um conjunto de softwares livres que serve para criar soluçőes de BI, de ponta a ponta, conforme mostrado na Figura 1.
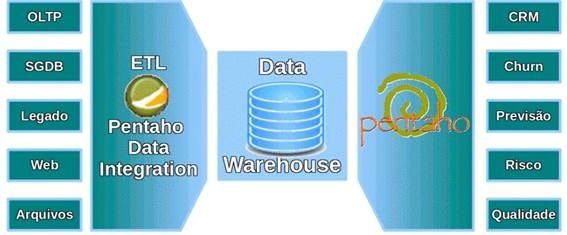
Figura 1: Soluçăo de BI com Pentaho Open BI Suite
Estăo disponíveis componentes para execuçăo de processos de ETL, que fazem carga de Data Warehouses, criaçăo de relatórios pré-formatados e ad hoc, cubos OLAP, painéis de instrumentos (Dashboards) e garimpagem de dados (Data Mining). Todos esses recursos podem ser combinados e acionados sequencialmente para criaçăo de soluçőes mais sofisticadas. Além disso, a plataforma executa todas as soluçőes de BI como serviços e, por isso, é possível prover acesso ŕs soluçőes para sistemas externos, via web services, através de um mecanismo baseado em SOAP/WSDL/UDDI.
A suíte se divide em duas partes: a Pentaho BI Plataform propriamente dita, implementada na forma de um servidor web, e clientes de desenvolvimento, que criam conteúdo para a plataforma.
O Pentaho é um software patenteado nos EUA: os fundadores da empresa queriam desenvolver um pacote Java que pudesse ser usado para construir qualquer soluçăo de BI. Eles queriam isso porque achavam que nenhuma ferramenta era flexível e poderosa o bastante para atender qualquer necessidade, de qualquer empresa. Eles acreditavam que devia haver uma maneira melhor de montar soluçőes de BI, e que seria possível fundar uma empresa sobre essa "maneira melhor". E foi o que eles fizeram.
Depois de desenvolver a primeira versăo desse pacote, eles montaram uma demonstraçăo de como usá-lo. Eles chamaram esse exemplo de "Pre-Configured Installation", ou PCI, mas ela fez tanto sucesso que a Pentaho foi forçada a adotá-la como produto e a evoluí-la. Essa trilha levou ao Pentaho BI Server, que contém o console de usuário (Pentaho User Console, PUC) e o console de administraçăo (Pentaho Administration Console, PAC). E hoje em dia, quando falamos a plataforma Pentaho estamos nos referindo indistintamente tanto ŕ esse "sub-produto" como a plataforma propriamente dita.
A Plataforma é uma aplicaçăo em JSP que roda sobre um servidor de aplicaçőes Java - até a versăo 1.7GA o default era JBoss; a partir da 2.0GA passou a ser Tomcat. A plataforma se divide em duas partes:
- O Solution Engine e seus componentes, săo responsáveis pela execuçăo e controle das soluçőes. A base de seu funcionamento é uma máquina de workflow interna, que sequencia as chamadas de cada componente para o resultado desejado.
- O Portal, a porçăo do Pentaho visível ao cliente final. Através dele o cliente navega entre as soluçőes e aciona a execuçăo de qualquer recurso, como um relatório ou dashboard.
A partir da versăo 2.0 algumas funçőes foram movidas do Portal para o Administration Console, uma outra aplicaçăo web e parte da suíte.
O BI Server oferece alguns serviços pré-configurados, como registro de soluçőes, controle de acesso, relatórios ad-hoc, agendamentos etc. Finalmente, a modularidade do portal permite que novos serviços sejam criados e implementados livremente.
A versăo 3.0 incorporou um mecanismo de plugins que tornou muito mais
fácil expandir as funcionalidades da plataforma, ela continua a mesma, em
essęncia, mas com a camada de conexăo de plugins. A plataforma opera através de
vários Servlets chamados Actions.
Todos os softwares da Suite Pentaho săo programas Java e rodam em qualquer
plataforma que tenha uma JVM padrăo.
Business Intelligence Server, a encarnaçăo mais famosa da plataforma, o BI Server, é uma aplicaçăo Java Web, montada sobre um Tomcat, pré-configurada com vários recursos:
- Controle de acesso ao ambiente por usuário e senha;
- Controle de acesso aos objetos (pastas, relatórios, painéis etc.) baseado em usuários e papéis;
- Controle de acesso aos dados, que diz quem pode ver que registro, de que tabela;
- Relatórios AdHoc;
- Visualizador/Navegador OLAP;
- Relatórios pré-configurados (a priori);
- Agendador de relatórios;
- Execuçăo de relatórios em background(plano de fundo);
- Envio de resultados por e-mail (bursting).
A interface visual do BI Server leva o nome de Pentaho User Console, ou PUC. Existe ainda uma outra aplicaçăo, baseada em Jetty, que faz a administraçăo da plataforma, com criaçăo e gestăo de usuários, papéis, fonte de dados e outros serviços como purga automática de conteúdo e controle de agendas públicas. Essa interface se chama Pentaho Administration Console, ou PAC.
O BI Server exibe os resultados - relatórios, visőes OLAP, painéis. Mas os recursos necessários para isso acontecer săo criados pelos clientes de desenvolvimento (Clientes Pentaho).
Pentaho Report Designer (PRD), é o gerador de relatórios stand-alone da suíte Pentaho, representante da categoria tornada famosa pelo Crystal Reports. Ele pode conectar-se a qualquer fonte de dados para qual exista um driver JDBC e criar relatórios pixel perfect, exibindo năo apenas lista de dados, mas também o resultado de fórmulas, subrelatórios, links, imagens, gráficos (pizza, barra, linha etc.), dentre outros recursos. A partir da versăo 3.5, o PRD passou a oferecer parametrizaçăo de relatórios na própria ferramenta. O PRD pode ser usado sozinho, ou publicar os relatórios diretamente no BI Server, para posterior acesso via web.
O Pentaho Metadata Editor (PME), permite que o arquiteto da soluçăo de BI agrupe os campos de tabelas que tenham alguma correlaçăo, criando visőes de negócios independentes, mesmo que campos de visőes distintas residam em uma mesma tabela. Ele é totalmente visual, e pode mapear qualquer fonte de dados que possua um driver JDBC.
O Pentaho Schema Workbench (PSW), cria os cubos OLAP que serăo exibidos na PUC. Ele tem uma interface visual para navegar entre as definiçőes do cubo, permitindo criar métricas, dimensőes e hierarquias.
Já o Pentaho Design Studio (PDS) é o ambiente de implementaçăo de Soluçőes de BI, que cria Actions Sequences e as combina em soluçőes mais complexas. Ele fornece ao desenvolvedor acesso de baixo nível aos recursos do Pentaho e é um plugin para a IDE Eclipse.
O Pentaho Weka é um ambiente gráfico para Data Mining. Permite ao usuário criar e testar hipóteses contra as bases de dados.
Pentaho Data Integration (PDI) é a ferramenta que realiza tanto a integraçăo de dados quanto os processos de ETL (Extraçăo, Transformaçăo e Carga), que alimentam Data Warehouses. Ele é capaz de ler e escrever mais de trinta formatos de SGDB, como Oracle, PostgreSQL, SQLServer, importar arquivos texto (csv ou fixo), planilhas Excel e base de dados ODBC. Ele é um ambiente gráfico no qual conexőes com fontes de dados săo estabelecidas e sequencia de passos executam a extraçăo de dados, sua modificaçăo e a carga desses em um destino. Pode integrar dados entre empresas e sistemas, substituindo a criaçăo de camadas de programas para integraçăo, por operaçőes visuais.
A versăo 4.0 implementa o conceito da Pentaho de AgileBI, no qual se combinam em uma interface a extraçăo de dados, sua modelagem e relatórios. Modelos e relatórios podem ser publicados diretamente no BI Server. Essa integraçăo permite que a equipe de BI gere resultados em dias ao invés de semanas.
A comunidade mundial Pentaho desenvolveu um número de outros recursos que podem ser adicionados ao Pentaho, notadamente ao BI Server.
Por definiçăo, a Suite Pentaho acessa (lę/grava) qualquer base de dados para qual haja um driver JDBC. Além disso, em ambiente Windows, a Suite consegue ler de qualquer base de dados que tenha driver ODBC, através do driver JDBC para ODBC. A capacidade de gravaçăo via ODBC năo é uniforme (algumas bases dispőem, outras năo). Na Figura 2 temos uma relaçăo dos bancos empacotados no Pentaho.
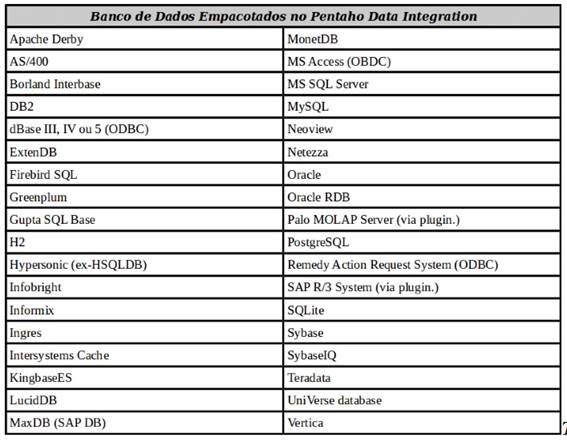
Figura 2: Lista de Banco de Dados PDI
A criaçăo de soluçőes de BI com a Plataforma Pentaho obedece a um fluxo simples, conforme mostrado na Figura 3:
- Os clientes, PDI, PRD, PSW, PDS, PDA, criam os artefatos da soluçăo;
- Esses artefatos săo publicados no BI Server;
- Os usuários acessam o BI Server para executar as soluçőes. Uma soluçăo de BI precisa de fontes de dados confiáveis e de alguma interface para seu cliente explorá-los. Algum tempo depois, a exploraçăo eventualmente amadurece em um processo, que pode ser automatizado, gerando valor para empresa.
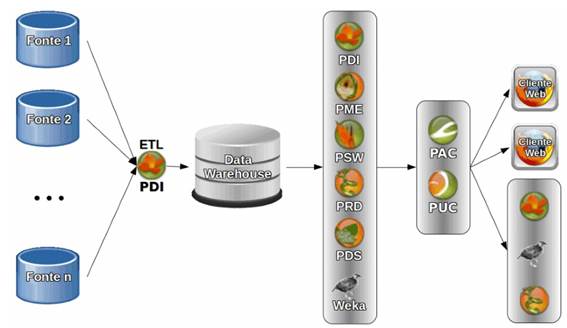
Figura 3: Processo de criaçăo de Soluçăo de BI Padrăo com Pentaho.
Os passos destacados correspondem ŕ:
- Criaçăo de Data Warehouse, Data Mart ou dump do banco de dados com o Pentaho Data Integration, a partir de fontes de dados que podem ser bancos relacionais, serviços de rede, páginas web e fontes desestruturadas (como e-mail e documentos texto), além de arquivos planos (CSV, Excel, Etc.).
- Criaçăo das soluçőes iniciais para exploraçăo do repositório de dados: Cubos OLAP, relatórios (com ou sem parâmetros), WAQR. Todos os clientes de desenvolvimento podem ser usados.
- Entrega da soluçăo com BI Server, com controle de acesso via web por seus clientes. Alguns clientes podem ter demandas especiais e optar por usar algum dos clientes de desenvolvimento, como PDI, Weka ou Report Designer para atendę-las.
Uma soluçăo de BI, qualquer que seja a ferramenta, sempre terá os mesmos elementos. Vamos examinar a arquitetura-padrăo de soluçőes de BI, algumas variaçőes e oferecer alguns parâmetros para ajudar a sua empresa a decidir em que modelo investir.
Toda soluçăo de BI sempre tem tręs partes:
- Data Warehouse: como năo existe BI sem DW, essa é uma peça indispensável em projetos de BI. Quando falamos de DW no contexto da arquitetura de BI invariavelmente estamos nos referindo ao servidor de banco de dados - hardware e software - que vai cumprir a funçăo de armazém de dados para a soluçăo de BI da empresa. Para definir esse componente é importante conhecer o volume de dados que será carregado inicialmente, a que velocidade (em bytes ou registros por męs) ele vai crescer, quanto usuários poderăo consultá-lo e quantas estrelas ele vai ter. Normalmente nenhuma dessas informaçőes é conhecida a priori, de modo que podemos quando muito fazer estimativas mais ou menos calibradas;
- Servidor de ETL: se DW na infraestrutura significa a máquina do banco de dados, ETL nesse contexto significa a máquina que vai executar o processo de extraçăo, transformaçăo e carga das fontes de dados para dentro do DW. De novo, como năo há BI sem DW, năo pode haver BI sem servidor de ETL porque a carga de um DW se dá por esse processo. Portanto, servidores de ETL também săo indispensáveis na arquitetura de uma soluçăo de BI;
- Servidor de Exploraçăo de Dados: uma vez que os dados estejam disponíveis no DW, os usuários começam a acessá-los e a explorá-los para resolver suas diversas necessidades: medir o desempenho da empresa, responder as perguntas estratégicas, táticas e até mesmo operacionais, planejar e avaliar o resultado das açőes e um inimaginável sem números de usos.
Alguns projetos de BI, como os que envolvem Data Mining, consomem os dados na forma de arquivos extraídos do DW especialmente para essas necessidades, e săo tratados com um rol bem particular de ferramentas - como o Weka ou SPSS.
Mas a maioria esmagadora de usos do DW na empresa depende de uma interface gráfica que esconda a complexidade das consultas através de uma interaçăo fácil e prazerosa com os dados. Consumir os dados do DW usando interfaces de texto para realizar consultas SQL que populam planilhas Excel simplesmente matam o interesse, năo pela falta de versatilidade, mas pela falta de usabilidade e de prazer em trabalhar com esses dados.
Por isso todo projeto de BI que se preze oferece aos usuários finais, seus clientes, um programa que dę essa interface gráfica. Até meados da década de 2000 ainda existiam softwares stand-alone, que eram instalados na estaçăo de cada usuário. Mas uma tendęncia nascida na década anterior estava atingindo a maturidade: interfaces para DW em ambientes web, ou cliente-servidor como eram chamados.
Esse é o terceiro componente indispensável de uma soluçăo de BI: um software que ofereça ao cliente uma poderosa e agradável interface gráfica para exploraçăo de dados do DW.
- Tudo-Em-Um
Hardcore, ideal para os projetos pilotos, pequenas empresas ou o início de
projetos ágeis. A combinaçăo de todos os servidores em uma só máquina física e
lógica é uma boa opçăo porque oferece menor complexidade e maior facilidade de
gestăo, preço reduzido e menor consumo de măo-de-obra especializada. É um ótimo
ambiente para experimentaçőes ou para projetos departamentais, conforme
mostrado na Figura 4.
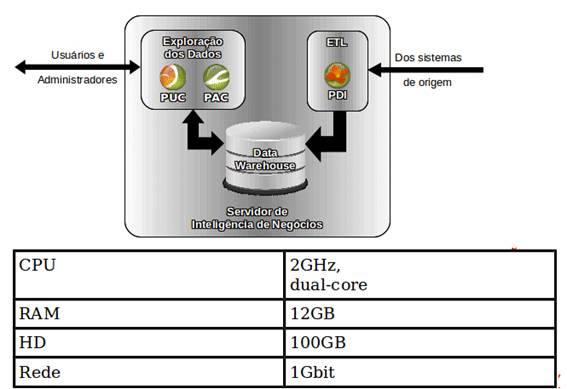
Figura 4: Esquema tudo-em-um, hardcore. - ·
Tudo-Em-Um
Softcore, a empresa que sabe que sua necessidade de BI vai crescer pode usar
uma variaçăo do modelo anterior: uma única máquina, mais parruda que a média,
mas com tręs máquinas virtuais, conforme mostrada na Figura 5.
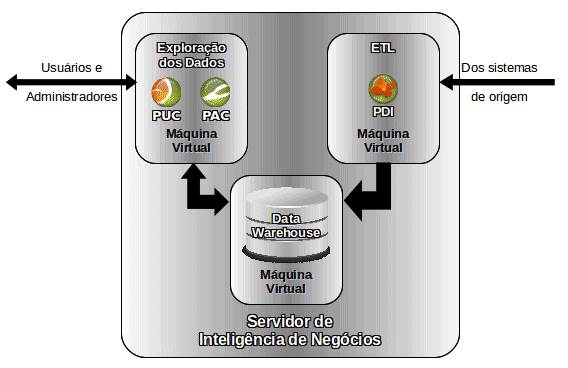
Figura 5: Esquema tudo-em-um, softcore.


Quando a necessidade de poder de processamento, memória, disco ou rede aumentar, a virtualizaçăo dá mais opçőes de reestruturaçăo. Por exemplo, separar os servidores por demanda em uma fazenda de servidores virtualizados.
Virtualizaçăo, com o barateamento do hardware de prateleira, torna-se possível criar ambientes virtualizados cada vez mais poderosos em máquinas cada vez mais baratas. A extrapolaçăo do modelo Tudo-Em-Um Softcore leva a uma estrutura de nuvem, conforme mostrado na Figura 6.
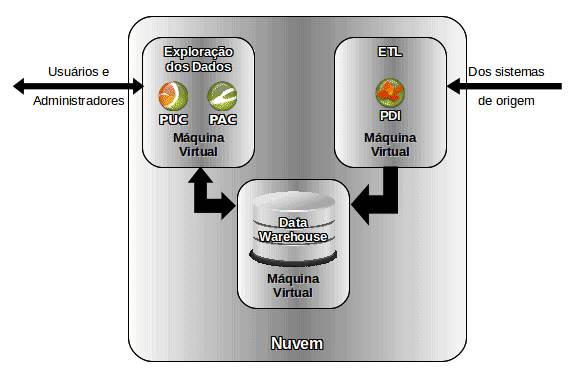
Figura 6: Virtualizaçăo total (nuvem).
A popularizaçăo e o barateamento de software de clusterizaçăo dinâmica (cloud computing) - permite que a empresa invista em um ambiente inicial e o expanda a medida que a demanda crescer.
A maior vantagem dessa arquitetura é a capacidade de expansăo praticamente ilimitada com um custo reduzido de manutençăo e gestăo. Além disso năo há impacto significativo para a equipe de desenvolvimento, já que ela vę máquinas distintas. O único senăo - e é senăo e tanto - é a transferęncia dos dados dos sistemas de origem para o servidor de ETL.
Servidores Independentes, organizaçőes que conseguem estimar com precisăo o crescimento da demanda sobre o ambiente de BI podem optar por um esquema no qual todos os servidores săo reais e separados, conforme mostrado na Figura 7.
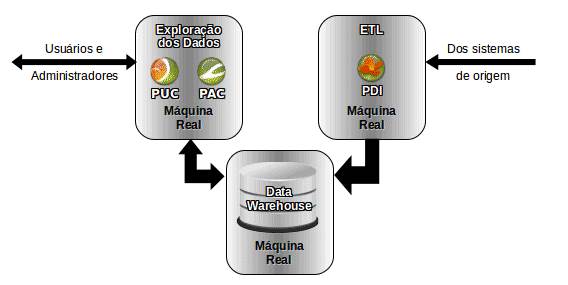
Figura 7: Servidores reais e independentes
A maior vantagem é a economia decorrente do autoconhecimento. Como a empresa conhece bem a própria demanda ela pode planejar a evoluçăo de cada ambiente e com isso espaçar mais as compras de hardware. Outro benefício colhido é a economia de gerenciar apenas tręs servidores físicos. Gerir esses servidores é mais barato que gerir uma nuvem pois năo requerem a administraçăo da arquitetura de nuvem além das instâncias de banco de dados e servidores, especialmente do ponto de vista de măo-de-obra. Finalmente, é possível crescer memória e CPU da máquina que se tornar um gargalo com alguns upgrades relativamente baratos, antes de trocar por máquinas mais potentes.
Servidores Combinados, quando a empresa năo está disposta a investir em uma nuvem particular, e nem dispőe de recursos para imobilizar em hardware potente, ela pode optar por combinar o ETL em um dos outros servidores (DW ou Interface) e assim aproveitar melhor os períodos ociosos, conforme mostrado na Figura 8.
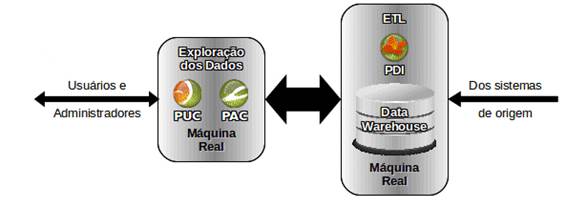
Figura 8: Servidores DW e ETL combinados.
O processo de ETL também pode ficar dentro do servidor de exploraçăo, conforme mostrado na Figura 9.
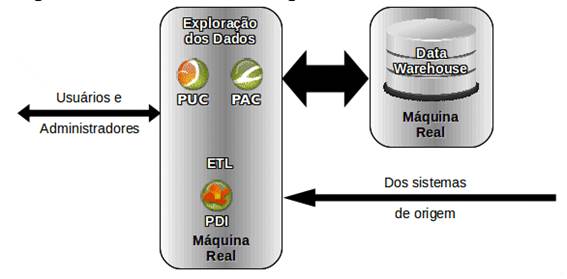
Figura 9: Processo ETL roda dentro do servidor de exploraçăo.
Essa combinaçăo é melhor que a anterior porque dá máquinas inteiras dedicadas a cada parte do processo, sem comprometer-se entre si. Na anterior, CPU, memória e disco usado pelo processo de ETL era subtraído do banco de dados, e vice-versa.
Softwares, hoje em dia, 100% das necessidades de um projeto de BI, de pequeno a grande porte, pode ser atendido com Software Livre(SL).
Sua necessidade de hardware vai depender diretamente do ambiente que vocę deseja implantar. Como linhas gerais, e em ordem decrescente de importância, busque:
- Maior capacidade de expansăo de memória;
- Maior capacidade de rede (para ambientes separados);
- HDs com maior vazăo;
- Maior capacidade de CPU;
- Isso
porquę:
o O maior gargalo na expansăo de usuários é espaço para todas as sessőes simultâneas;
o O maior gargalo para consultas simultâneas é a troca de dados entre o servidor DW e o de exploraçăo;
o O maior gargalo ŕ troca de dados é a velocidade de acesso aos dados em disco; - E só depois desses gargalos resolvidos é que vai adiantar aumentar o poder de processamento, pois sem dados prontamente disponíveis para todos os usuários năo adianta nada ter CPU potente.
Até a próxima! Um abraço.
Referęncias:
THOMSEN, ERICK. OLAP Solutions. 1a. Ed. EUA: Wiley Publishing, 1997.
SCHEPS, SWAIN. Business Intelligence for Dummies. 1a. Ed. EUA: Wiley
Publishing, 2008.
Pentaho na prática (Fábio, Caio & Cesar)
ISBN: 978-85-915459-0-2
WHITEHORN, MARK. Fast Track to MDX. 2a.
Ed EUA: Springer 2005.







