Possibilitando alta performance na indexaçăo com o Apache Lucene - Parte I
A Apache desenvolveu uma API de nome Lucene que tem como utilidade recuperar informaçőes em aplicaçőes de arquivos. Esta funcionalidade se dá através de um engine de pesquisa, que permite a indexaçăo de textos com alta performance. Isso torna possível executar buscas de qualquer dado que possa ser transformado em texto. O recurso pode ser aplicado para, por exemplo, localizar palavras inclusive em documentos em PDF, que anteriormente foram transformados em textos e indexados pelo Lucene. Existe uma série de aplicativos desktops e web que utilizam o Lucene como engine de pesquisa, como mostra a lista a seguir:
Eclipse IDE – www.eclipse.org
DocJar - http://www.docjar.com/
Jira - http://www.atlassian.com/software/jira/
CNET Reviews - http://reviews.cnet.com/
JGuru - http://www.jguru.com/
JDK Search - http://jdk.representqueens.com/
SourceForge - http://www.sourceforge.net/
Wikipedia - http://en.wikipedia.org/wiki/Lucene
O Lucene oferece suporte para outras linguagens além do Java: Lucene4C – C, CLucene – C++, MUTIS – Delphi, Lucene.Net – C# .Net, Zend Framework – PHP e Ferret – Ruby. Para configurar o ambiente, acesse o site para fazer o download do Apache Lucene em http://www.apache.org/dyn/closer.cgi/lucene/java/. Vamos trabalhar com a versăo 2.1 neste artigo. O nome do arquivo executado é lucene-2.1.0.zip. Veja abaixo sua estrutura de pastas:
A pasta contrib contém alguns recursos externos do Lucene, como Analysers para diversos idiomas, como veremos mais adiante, além de benchmarks, highlighter, entre outros. No entanto, o foco desta vez será o Analyser. Vale lembrar que a pasta docs contém a documentaçăo da API e a SRC o código fonte da aplicaçăo de exemplo. Assim sendo, configure o classpath da sua aplicaçăo incluindo o arquivo lucene-core-2.1.0.jar.
Conferindo o funcionamento
A indexaçăo passa por um processo de análise do documento e, automaticamente, o converte para um texto simples. A extraçăo do texto é feita a partir de um Analyser, classe que contém as regras para a realizaçăo desse trabalho de retirada do conteúdo. No entanto, é preciso saber que existem diversas implementaçőes da classe Analyser que realizam essa mesma funçăo. Optamos entăo aqui o usa da BrazilianAnalyser que contém as stop_words da nossa língua. No exemplo inicial estaremos utilizando o Analyser padrăo para facilitar o aprendizado.
Stop words săo palavras irrelevantes para o nosso índice. Por isso, nada impede que vocę crie o seu Analyser com as suas próprias stop words. Veja alguns exemplos: "ambas", "ambos", "ano", "anos", "antes", "ao", "aonde", "aos", "apenas", "apos" etc.
O segundo passo
após a extraçăo do texto é organizar o índice, que pode ser acessado futuramente
em pesquisa, de maneira prática, já que o Lucene dispőe de classes que definem a
estrutura interna deste sumário a ser gerado.
Em definiçăo ŕs nomenclaturas do Lucene, a classe Document é uma unidade de indexaçăo e pesquisa que permite armazenar campos (Fields). Sobre a classe Field pode-se dizer que um field só pode ser armazenado em um Document, pois possui um nome e um valor. Năo é possível armazenar dois Fields com o mesmo nome em um documento. Mas um documento pode conter um ou mais Fields. A classe Directory é responsável por endereçar o índice. O armazenamento dos Documents é feito no Directory. Na ilustraçăo do fluxo do processo de indexaçăo no Lucene o processo fica mais claro:
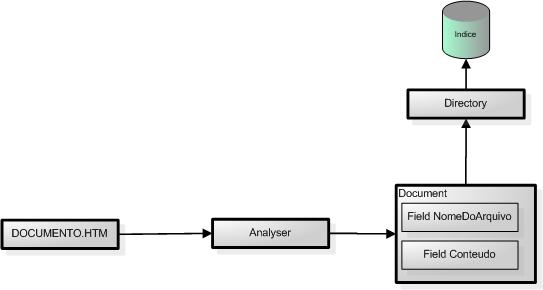
Fluxograma do Processo de Indexaçăo
O IndexWriter é o responsável pela criaçăo do índice, ao qual, através desta classe, pode-se adicionar Documents. Enquanto isso, o IndexSearcher tem o papel de executar a busca no índice. Os critérios de busca săo passados para a funçăo de busca do Searcher através do Objeto Query. Em seguida, o Objeto Query é construído através da TermQuery, para o qual passamos como parâmetro o nome do campo a ser procurado e o valor que possivelmente ele contém.
Veja exemplo de Indexaçăo conforme código abaixo:
package info.glaucioguerra.main;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Main {
public static void main(String[] args) {
Document document = new Document();
try {
FileInputStream arquivo = new FileInputStream("c:/arquivo.txt");
Directory directory = FSDirectory.getDirectory("c:/indice", true);
Analyzer analyzer = new StandardAnalyzer();
IndexWriter writer = new IndexWriter(directory, analyzer, true);
document.add(new Field("arquivo", "c:/arquivo.txt",Field.Store.YES, Field.Index.NO));
document.add(new Field("conteudo", new FileReader(arquivo.getFD())));
writer.addDocument(document);
writer.close();
arquivo.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Na primeira linha do código declara-se o Document que será armazenado no nosso índice. Carregamos o arquivo arquivo.txt pelo FileInputStream com o seguinte conteúdo:
“JDK 6 with Java EE
Java EE provides web services, component-model, management, and communications APIs that make it the industry standard for implementing enterprise-class service-oriented architecture (SOA) and Web 2.0 applications.
Build native code with easy Java Native Interface (JNI) connections, or accelerate your Java development by leveraging DTrace, Containers, and ZFS. Get Sun's latest development platform with Sun Studio compilers and tools for C/C++/Fortran, NetBeans IDE, and the next-generation Solaris operating system all in the Solaris Express, Developer Edition.”
A escolha deste texto para indexaçăo foi feita porque estamos utilizando o Analyser padrăo do Lucene, que reconhece as stop word’s no idioma Inglęs.
A classe Directory informa o diretório onde serăo armazenados os arquivos do Lucene. O parâmetro “true” informa que um novo índice será criado, ou destruído caso já exista algum. Logo em seguida temos a classe Analyser, responsável pela extraçăo do texto, como já mencionamos. A IndexWriter recebe como parâmetro o Directory e o Analyser para efetuar a gravaçăo do índice.
A parte do código que merece mais atençăo é a criaçăo do Document e a organizaçăo de seus Fields. No nosso exemplo estamos criando dois Fields, um para armazenar o nome do arquivo e o outro para guardar o conteúdo.
Analisando o trecho de código:
document.add(new Field("arquivo", "c:/arquivo.txt",Field.Store.YES, Field.Index.NO));
No caso supracidado, adiciona-se um Field para o Document com o nome arquivo e o seu conteúdo é o nome do arquivo do FileInputStream. O parâmetro Field.Store.YES define que o Field deve ser armazenado no Índice. Já o segundo parâmetro define que o Field năo deve ser indexado. Em outras palavras, o Field arquivo é armazenado no índice, mas năo é um campo indexado, servindo somente para informar o nome do arquivo que foi indexado.
Analisando a criaçăo do segundo Field no Document:
document.add(new Field("conteudo", new FileReader(arquivo.getFD())));
O primeiro parâmetro indica o nome do Field e o segundo um FileReader que fornece a leitura de uma cadeia de caracteres. Este Field será armazenado e indexado.
Ficamos por aqui com a primeira parte do artigo. Até o próximo artigo!







