A necessidade por informaçőes de qualidade e com baixa latęncia – Real-Time Business Intelligence – é condiçăo cada vez mais premente na conduçăo dos negócios dentro de organizaçőes de vários segmentos. Responsável por atender a essa necessidade, os ambientes de suporte ŕ decisăo tornaram-se cada vez mais críticos concomitante ao desafio de TI retirar mais valor desses servindo-se de menos recursos.
A pressăo para responder a esse cenário, no caso das tecnologias de Sistemas de Bancos de Dados – SGBD –, levou ao aparecimento de uma nova abordagem que oferece melhor eficięncia de armazenamento atrelado a um melhor tempo de resposta nas consultas analíticas; os SGBD Orientado a Coluna – referenciados como Column Oriented ou Column Store.
SGBD e seu público no tempo
Na década de 70, os SGBD foram massivamente utilizados na automatizaçăo de processos operacionais crítico – Folha de Pagamento, Contabilidade, Conta Corrente, para citar alguns – que se caracterizam pela realizaçăo de transaçőes com curta duraçăo e pequeno volume de dados manipulados; as transaçőes OLTP.
A partir da década de 90, as organizaçőes perceberam o valor dos SGBD – e do grande volume de dados disponíveis – como instrumento de apoio a tomada de decisőes, ao planejamento do seu negócio e ao entendimento de seus Clientes, culminando no fortalecimento dos segmentos de Data Warehousing e Customer Relationship Management – CRM.
Esses dois públicos – transacional e analítico –, porém, apresentam características e requisitos fundamentalmente diferentes quanto ao uso do SGBD – ver quadro a seguir –, levando os fornecedores e pesquisadores a buscarem propostas para atender aos públicos divergentes. Desta necessidade surge a abordagem Orientada a Coluna.
Quadro 1 – Contraposiçăo das principais características do mundo transacional e analítico
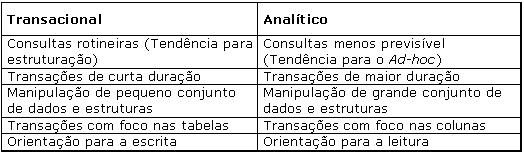
Distinçőes entre as abordagens
Muitas implantaçőes de Data Warehouse/Data Marts foram – e estăo sendo – concebidas com SGBD tradicionais – Oracle, Teradata, DB2, etc. – cujos núcleos focam no tratamento de linhas. Năo obstante esta característica ser adequada a sistemas OLTP, muitos dos seus representantes receberam vultosos investimentos para incrementar sua capacidade de apoio as necessidades analíticas, como incorporaçăo de índice Bit Map, visőes Materializadas e capacidade de configuraçăo.
Os SGBD com orientaçăo a coluna – Vertica, Sybase IQ, BigTable, Exasol, ParAccel, entre outras opçőes comerciais e open-source –, por sua vez, apoiaram a construçăo do seu núcleo sobre a constataçăo cujo Data Warehouse/Data Mart apresenta uma freqüęncia de leitura muito superior a de operaçőes de modificaçăo – insert, update e delete. Tal fato determina seu desempenho ótimo para leituras seletivas – pequeno conjunto de colunas – sobre extenso volume de dados.
As principais diferenças entre as duas abordagens săo:
Forma de Armazenamento
Na abordagem Orienta a Linha, cada coluna de uma linha é armazenada de forma contígua, ou seja, todas as informaçőes sobre uma entidade săo mantidas juntas, conforme figura abaixo. Na outra abordagem, os conteúdos de cada coluna de uma tabela é que săo dispostos em seqüęncia.

Figura 1 – Visăo geral de armazenamento na abordagem orientada a Linha e Coluna.
Evidentemente a questăo năo se resume a esse fato. Além desta segmentaçăo das colunas, alguns SGBD Orientados a Coluna – como o Vertica – organizam cada tabela em um conjunto de projeçőes, cada qual com uma porçăo de suas colunas e com os respectivos dados com alguma ordenaçăo (BURNS, 2007).
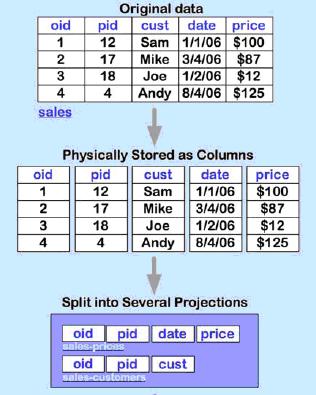
Figura 2 – Visăo esquemática da segmentaçăo das colunas em Projeçőes.
Compressăo dos dados
Apesar dos SGBD tradicionais disporem deste recurso, aqueles orientados a colunaobtém uma taxa significativamente maior, pois os algoritmos deste atuam melhor sobre dados de mesmo tipo de dado – menor entropia. Além dos benefícios diretos na reduçăo do espaço de armazenamento, verificam-se ainda vantagens de ordem de desempenho das operaçőes de consulta em razăo do menor tráfego de dados entre o disco e a memória.
Operaçőes de Leitura
A leitura direta das colunas desejadas – ver Figura 3 –, a compressăo dos dados e as projeçőes – para os SBGD que apresentam mecanismo semelhante – fazem com que o tempo de resposta de operaçőes de cálculo e/ou agregaçőes massivos seja inferior ŕquele da abordagem tradicional. Esta última, respeitando suas características, recupera todas as linhas desejadas para, entăo, proceder com a seleçăo das colunas requeridas.

Figura 3 – Visăo geral esquemática do plano de acesso aos dados no SGBD Orientado a Coluna
Operaçőes de Manutençăo
A abordagem Orientada a Coluna, ao satisfazer as operaçőes de leitura, cria um ponto de tensăo com relaçăo ao desempenho das operaçőes de atualizaçőes. Para năo provocarem a contençăo do ambiente, săo utilizados mecanismos de lock năo convencionais, acarretando um desempenho inferior dessas operaçőes em relaçăo ŕquele verificado na abordagem Orientada a Linha.
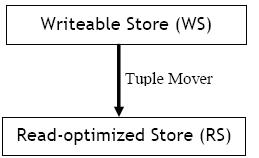
Figura 4 – Modelo de armazenamento híbrido
O C-Store (STONABRAKER, 2005) e o Vertica (BURNS, 2007), por exemplo, adotaram um modelo híbrido de armazenamento composto por duas áreas ou segmentos; uma que suporta as operaçőes de atualizaçăo dos dados – WS – e outra que suporta consultas de grandes quantidades de dados – RS –, como ilustrado na figura acima. A segunda área somente suporta operaçăo de atualizaçăo via o mecanismo assíncrono – denominado Tuple Mover – que efetua o merge de seus dados com aqueles disponíveis na área WS.







