Como o próprio nome já diz, săo coleçőes nomeadas de arquivos e săo usados para simplificar o posicionamento de dados.
E afinal de contas, pra que controlar o posicionamento de dados?
Os filegroups melhoram o desempenho distribuindo dados por um ou mais discos e usando threads paralelos para processamento de consultas. Os filegroups também podem facilitar a manutençăo do banco de dados.
Ponto de vista do desempenho
O desempenho das consultas melhora quando se tem o mesmo banco de dados distribuido em vários filegroups em discos ou array de discos diferentes. Uma prática bastante recomendada é separar as tabelas mais acessadas em filegroups distintos localizados em controladoras e discos diferentes, assim năo há concorręncia de I/O, otimizando tanto consultas quando escritas no banco. Vocę também pode usar vários filegroups para separar tabelas de seus índices no cluster, o que pode otimizar o acesso a dados em alguns casos.
Ponto de vista de gerenciamento
Os filegroups podem ser usados para separar dados com diferentes exigęncias de capacidade de gerenciamento, separando dados atualizados freqüentemente de dados relativamente estáticos. Com base nisso, também é possível usar estratégias diferentes de backup.
Vocę também pode separar os índices mais prováveis de fragmentaçăo dos índices modificados com menos freqüęncia para otimizar tarefas de desframentaçăo de índices.
Tipos de filegroups
Um banco de dados SQL Server tem um filegroup principal e também pode conter vários filegroups definidos pelo usuário. O filegroup principal contém o arquivo de dados principal com as tabelas do sistema, e, também contém arquivos secundários definidos pelo usuário que năo estăo alocados para outros filegroups.
Vale a pena lembrar que o arquivo de LOG é único e năo pode estar dividido em filegroups ou arquivos secundários. O que se pode fazer é separar o arquivo LDF do disco em que está arquivo de dados principal, o que evita concorręncia de gravaçăo/consulta.
Ao criar o banco de dados, na janela New Database veja que a parte em destaque, se refere ao arquivo físico e em qual filegroup ele estará organizado.
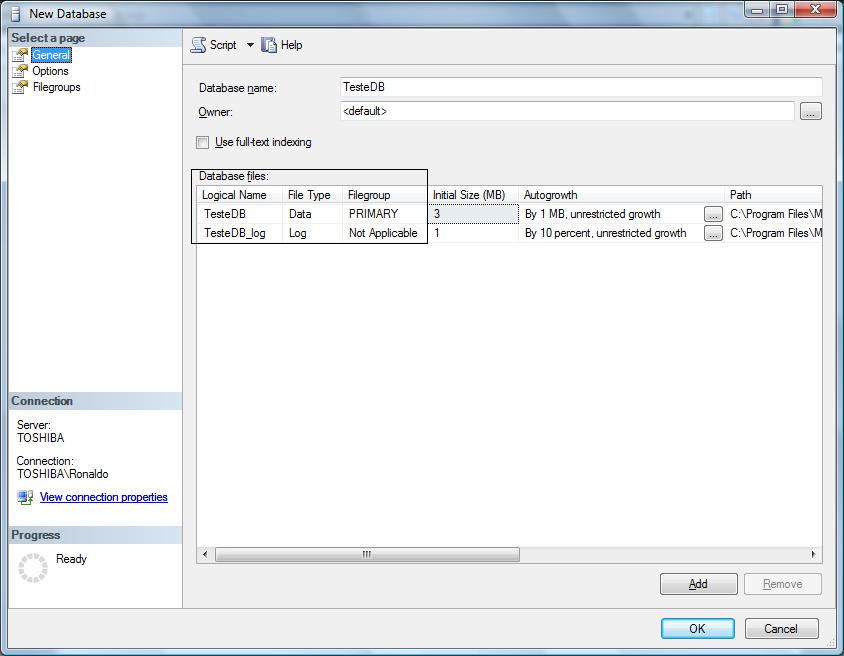
Figura1
Antes de criar o banco de dados, clique no botăo Filegroups no canto superior esquerdo e crie os filegroups necessários observando as opçőes em destaque.
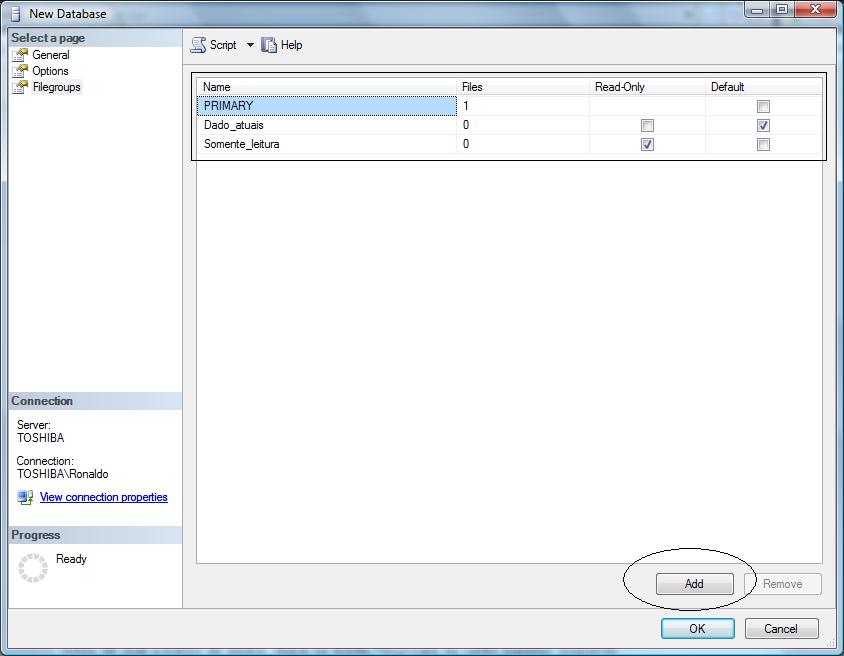
Figura2
Read-Only: năo permite gravaçăo de dados nos objetos gravados nesse filegroup.
Default: será o filegroup padrăo ja criaçăo e localizaçăo dos arquivos no disco.
Após criados os filegroups, clique no botăo General e especifique a localizaçăo do arquivo no sistema de arquivos e o posicionamento deles em relaçăo aos filegroups.
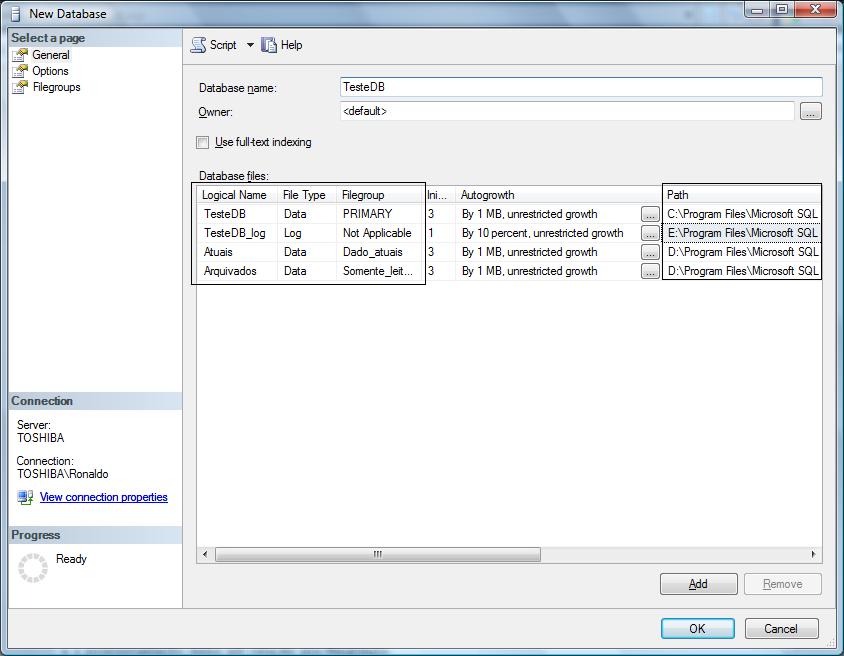
Figura3
Ao pressionar OK, os arquivos serăo criados nos caminhos específicos na coluna Path.
Daqui por diante, na criaçăo de suas tabelas, se vocę năo especificar o filegroup onde ela será criada, a tabela ficará localizada no filegroup definido com default (Dados_atuais conforme a Figura2).
CREATE TABLE Cliente
(ClienteID int IDENTITY PRIMARY KEY,
Nome nvarchar(50),
Cidade nvarchar(15),
UF nvarchar(2))
(ClienteID int IDENTITY PRIMARY KEY,
Nome nvarchar(50),
Cidade nvarchar(15),
UF nvarchar(2))
Criando tabela especificando o filegroup:
CREATE TABLE Cliente
(ClienteID int IDENTITY PRIMARY KEY,
Nome nvarchar(50),
Cidade nvarchar(15),
UF nvarchar(2))
ON filegroupname
(ClienteID int IDENTITY PRIMARY KEY,
Nome nvarchar(50),
Cidade nvarchar(15),
UF nvarchar(2))
ON filegroupname







