A produçăo e interpretaçăo de dados relacionados ŕs atividades humanas sempre fomentou a evoluçăo da tecnologia que atualmente constitui como um dos pilares da civilizaçăo moderna. Na década de 70, no séc. XX, năo era diferente. Os setores comercial e industrial da época já manifestavam o interesse em obter acesso mais rápido aos seus registros em decorręncia do armazenamento convencional de arquivos, bem como reduzir a redundância e inconsistęncia dos dados até que fosse possível compartilhá-los, garantindo certo nível de segurança. Apostando nesse mercado, a IBM (International Business Machines) iniciou suas pesquisas determinada a oferecer uma ferramenta que atendesse ŕ nova demanda. Durante as pesquisas, alguns modelos de bancos de dados foram explorados, dentre eles, o hierárquico, de rede e relacional. Nesse contexto, o modelo de dados deve ser entendido como o conjunto de ferramentas conceituais para a descriçăo de dados, seus relacionamentos, semântica e restriçőes que mantenham a consistęncia. Esses modelos se subdividem em tręs grupos: lógicos baseados em objetos, lógicos baseados em registros e modelo físicos de dados.
Retornando ŕ pesquisa da IBM, ela batizou o resultado do projeto inicial com o nome System R, visionário na implementaçăo de sistemas de bancos de dados relacionais e na implementaçăo da SQL (Structured Query Language), embora năo fosse integralmente fiel ao proposto por Codd em suas regras para o modelo relacional. Na época seus autores divulgaram generosamente os detalhes de seu objeto de estudos ŕ comunidade por meio de artigos, o que encorajou dois pesquisadores de Berkley, os cientistas Michael Stonebraker e Eugene Wong, a desenvolverem o próprio projeto de banco de dados relacional. Ambos já haviam arrecadado fundos com o projeto INGRES (Interective Graphics Retrieval System) – um banco de dados geográfico que fora desenvolvido para um grupo econômico, implementado por um grupo de estudantes e financiado por órgăos de pesquisa do governo norte-americano – o que garantiria subsídio ao início do projeto. Do projeto “INGRES” derivaram outros sistemas de bancos de dados, tais como SQL Server, Sybase e o próprio PostgreSQL.
O projeto Postgres foi iniciado em 1986 na Universidade de Berkley, e sua proposta era suprir as dificuldades impostas pelo INGRES, como a manipulaçăo de tipos definidos pelo usuário (hoje conhecidos como objetos) pelo sistema relacional e a de grande volume de armazenamento. Através dessa lógica, o nome PostgreSQL veio da aglutinaçăo de “post-INGRES” (após o INGRES).
Em 1994 o PostQUEL, que era a linguagem nativa para interpretaçăo de consultas implementada pelo Postgres, foi substituída pelo interpretador SQL. Esse foi um marco importante na história do projeto, que após isso passou a ser chamado PostgreSQL.
PostgreSQL
O PostgreSQL utiliza o modelo lógico baseado em registros através do modelo relacional. Adicionalmente, o projeto atual permite manipulaçőes diretas análogas ao conceito da orientaçăo a objetos, como herança, polimorfismo e o uso de objetos. É distribuído sob a licença BSD (Berkley Software Distribution), que caracteriza o software como pertencendo ao domínio público e, portanto, livremente personalizável, exigindo somente o reconhecimento autoral para a distribuiçăo do binário, versăo original ou alterada. Essa licença é muito permissível e viabiliza o funcionamento de softwares em diferentes formatos de licença trabalhando juntos. Năo se pode dizer que a licença BSD é necessariamente melhor que a licença “concorrente”, GPL (Gnu General Public License). A questăo é que a primeira é menos restritiva. Note que tanto a licença BSD quanto o Postgres tiveram origem no mesmo local, a Universidade de Berkley.
A norma ACID, acrônimo para os conceitos de Atomicidade, Consistęncia, Isolamento e Durabilidade, que representam os critérios básicos para transaçőes e recuperaçőes a falhas, é integralmente implementada pelo PostgreSQL. Essas propriedades asseguram aspectos essenciais para a qualidade das operaçőes, tais como controle de integridade referencial e de concorręncia de multi-versăo, ou MVCC (Multiversion Concurrency Control), além de ser premissa do modelo relacional.
Existem muitas implementaçőes maduras no PostgreSQL, tais como replicaçăo síncrona e assíncrona, segurança SSL(Secure Socket Layer) e criptografia nativos, utilizaçăo de clusters de dados, operaçăo com multithreads, multiplataforma, suporte a 24 idiomas, backups PITR (Point-In-Time Recovery), áreas de armazenamento (tablespaces), pontos de salvamento (savepoins), subconsultas e visőes atualizáveis, controle de locking, suporte ŕ definiçăo de funçőes em PL/PgSQL, Perl, Python, Ruby, dentre outras linguagens de programaçăo, foreign data-wrappers, alerta e failover automatizado para ambientes de missăo crítica, além de inúmeras características vantajosas. Existe também o interesse crescente da comunidade em apoiar o desenvolvimento do software através de contribuiçőes e patrocínios, como é o caso da Hewlett-Packard, VMware, EnterpriseDB, Fujitsu, Google, Skype e RedHat, para citar algumas. Por isso, o PostgreSQL é frequentemente apontado como ótima opçăo em projetos que demandem estabilidade e facilidade de uso conjugada a boa curva de aprendizado, visto que ostenta a reputaçăo de ser o sistema gerenciador de banco de dados de código livre mais sofisticado disponível. Como dito anteriormente, o PostgreSQL é um projeto comunitário, open source, coordenado pelo PostgreSQL Global Development Group, e que năo limita o escopo de suas capacidades, recursos e funcionalidades aos usuários, ou seja, está totalmente ŕ disposiçăo para qualquer um, a qualquer momento.
Um aspecto que corrobora o alinhamento ŕs demandas mais atuais, como a disponibilidade de serviços em nuvem e a escalabilidade vertical, é o fato de que o PostgreSQL năo é somente relacional: é multi-paradigma, agregando também funcionalidades No-SQL (Not Only SQL). Aqui temos um bom exemplo de como o uso de extensőes pode ampliar a gama de possibilidades do sistema. O PGXN (PostgreSQL Extension Network) é um sistema de distribuiçăo central para bibliotecas open source de extensăo para o PostgreSQL. De forma similar, também existe o pgFoundry, que reúne diversos projetos relativos ao PostgreSQL.
A maioria das linguagens de programaçăo modernas proveem interface nativa para conexőes com o PostgreSQL. Como alternativa em caso de ausęncia, há disponibilidade de acesso através da interface ODBC (Open Database Connectivity), que permitiriam acesso por produtos da Microsoft como Access e Excel. Aplicaçőes desenvolvidas em Java contam com o suporte oferecido pelo driver JDBC (Java Database Connectivity). Já para o PHP, teríamos o PDO (PHP Data Objects) como opçăo. O acesso aos dados ocorre de várias formas, podendo ser através de linha de comando (psql), pelo código SQL embutido na aplicaçăo/framework, por cliente gráfico (pgAdmin III) ou via navegador web (phpPgAdmin), por exemplo.
Arquitetura e versionamento
Outro ponto forte do projeto é a sua arquitetura cliente-servidor (ver Figura 1), fazendo com que o acesso aos dados seja distribuído a clientes que năo os acessam diretamente mas via processo no servidor (postmaster), mesmo que o cliente esteja acessando na mesma máquina onde o serviço está instalado. A seguir, uma forma simplificada de como esse acesso se dá, através de TCP/IP (Transfer Control Protocol/Internet Protocol) ou Internet, via tunelamento.
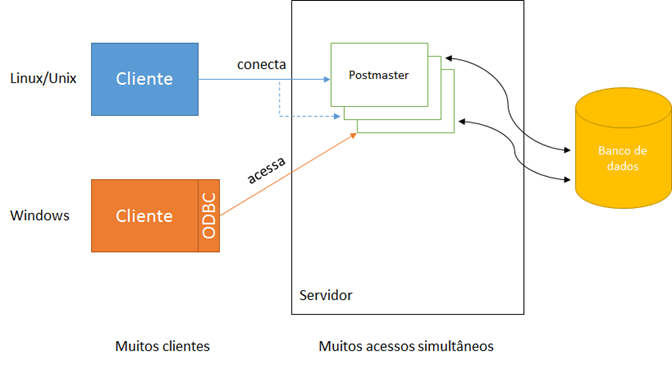
Figura 1. Arquitetura cliente-servidor implementada no PostgreSQL.
A Tabela 1 indica algumas das limitaçőes para as capacidades de armazenamento.
|
Tamanho máximo de um banco |
Ilimitado |
|
Tamanho máximo de uma tabela |
32 TB |
|
Tamanho máximo de uma linha |
1,6 TB |
|
Tamanho máximo de um campo |
1 G ... |



Confira outros conteúdos:



Perguntas frequentes

Nossos casos de sucesso
Eu sabia pouquíssimas coisas de programaçăo antes de começar a estudar com vocęs, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda năo tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocęs e logo percebi que săo os melhores do Brasil. É um passo a passo incrível. Só năo aprende quem năo quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocęs estăo fazendo parte da minha jornada nesse mundo da programaçăo, irei assinar meu contrato como programador graças a plataforma.
Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que năo tem como năo aprender, estăo de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tăo presente na vida acadęmica de seus alunos, parabéns!
Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!
Adauto Junior
Já fiz alguns cursos na área e nenhum é tăo bom quanto o de vocęs. Estou aprendendo muito, muito obrigado por existirem. Estăo de parabéns... Espero um dia conseguir um emprego na área.
