A linguagem de montagem de consultas SQL é uma linguagem com alto poder de expressăo, ou seja, com ela podemos fazer manipulaçőes complexas nos dados utilizando poucos comandos. A linguagem SQL, que trabalha com as tabelas definidas no modelo físico de banco de dados, possui várias funcionalidades. Uma das funcionalidades mais complexas e poderosas săo os joins, que permitem manipulaçőes nos dados contidos em mais de uma tabela ao mesmo tempo, sempre de acordo com algum relacionamento entre as tabelas. Estes relacionamentos devem ser definidos no modelo lógico do banco de dados, durante a modelagem do mesmo.
Neste artigo vamos discutir a atualizaçăo automática de mais de uma tabela e o uso de joins em instruçőes UPDATE e DELETE através de exemplos práticos.
Atualizaçăo automática
Os joins săo aplicados, na maioria das vezes, durante uma instruçăo SQL chamada SELECT, que faz o retorno de dados. Na instruçăo SELECT devemos definir as tabelas nas quais os dados estăo armazenados assim como quais os valores de colunas văo ser retornados, além das condiçőes necessárias para o retorno dos dados. Como mais de uma tabela vai ser utilizada na instruçăo, devemos representar a relaçăo entre as colunas das tabelas através das opçőes da cláusula join, aplicada ŕ instruçăo SELECT.
A utilizaçăo de join em instruçőes SELECT é o uso mais comum do join. Mas existem situaçőes onde queremos modificar, ou mesmo apagar, dados de determinadas tabelas com bases nas suas relaçőes com outras tabelas. Como as relaçőes entre as tabelas săo especificadas no modelo lógico do banco de dados, e reforçadas pela implementaçăo de constraints, existem casos em que certas açőes săo propagadas automaticamente, o que chamamos de açőes em cascata.
Vamos ver um exemplo. Suponham que temos o diagrama Entidade Relacionamento apresentado na Figura 1, criado em um banco de dados do SQL Server 2000. A tabela ITENSPEDIDOS possui uma chave primária composta nas colunas PED_COD e PROD_COD. Existem duas chaves estrangeiras na tabelas ITENSPEDIDO. A primeira chave estrangeira relaciona a coluna PROD_COD da tabela ITENSPEDIDOS com a coluna PROD_COD da tabela PRODUTOS. A segunda chave estrangeira relaciona a coluna PED_COD, da tabela ITENSPEDIDOS, com a coluna PED_COD da tabela PEDIDOS.

As chaves estrangeiras da tabela ITENSPEDIDOS foram criadas com a opçăo de atualizaçăo e deleçăo em cascata. Esta opçăo funciona da seguinte maneira: se alguma instruçăo UPDATE alterar o valor da coluna PED_COD, em alguma linha da tabela PEDIDOS, este novo valor vai ser alterado nas linhas correspondentes (que possuem o mesmo valor) da tabela INTENSPEDIDOS, desde que năo haja violaçăo da chave primária composta da tabela ITENSPEDIDOS.
Mas o inverso năo é verdadeiro, ou seja, se o valor da coluna PED_COD da tabela ITENSPEDIDOS for alterado para um valor que năo existe na coluna PED_COD, da tabela PEDIDOS, teremos um erro de violaçăo de chave estrangeira. Esta regra funciona de maneira análoga para a coluna PROD_COD, da tabela PRODUTOS e da tabela ITENSPEDIDOS.
Relacionando tabelas
Discutimos até agora a atualizaçăo automática em duas colunas de tabelas distintas com uma única instruçăo. Esta atualizaçăo foi feita nas colunas que săo responsáveis pelo relacionamento entre as tabelas e que fazem parte da chaves primárias e das chaves estrangeiras. Mas, e se desejarmos atualizar os valores de uma coluna que năo faz parte dasconstraints, levando em consideraçăo as relaçőes da tabela que contém a coluna? Para estes casos podemos utilizar duas abordagens: o uso de subquerys ou o uso de joins.
Utilizando como exemplo as tabelas do diagrama da Figura 1, vamos supor que, por um erro de sistema, todos os produtos que foram utilizados em algum pedido possuem o valor com 10% a mais. Devemos retirar 10% do valor de cada produto que esteja em algum pedido. Para atualizar a tabela PRODUTOS vamos fazer um relacionamento na instruçăo UPDATE, de modo a obter somente os produtos que constam em algum pedido. A Listagem 1 mostra primeiro a instruçăo UPDATE que faz a atualizaçăo na tabela PRODUTOS utilizando uma subquery. Na seqüęncia, a instruçăo UPDATE utiliza um join que relaciona as tabelas PRODUTOS e ITENSPEDIDOS.
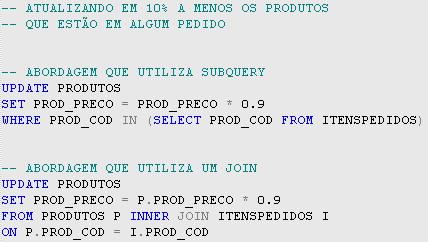
Notem que na abordagem que utiliza a subquery a funçăo IN() verifica se o valor de uma coluna está contido em um conjunto de valores, retornados por um SELECT na tabela ITENSPEDIDOS.
Na abordagem que utiliza join o relacionamento entre as tabelas PRODUTOS e ITENSPEDIDOS foi feito pelo tipo de join chamado equi-join, onde somente as linhas que possuírem valores idęnticos para as colunas PROD_COD serăo retornadas.
Comparando as duas abordagens, podemos dizer que a utilizaçăo de subquerys torna a instruçăo mais fácil de ser lida e compreendida. Se desejarmos referenciar mais de duas tabelas na instruçăo UPDATE, a complexidade da instruçăo vai aumentar, pois para cada tabela devemos inserir uma nova subquerys e, em alguns casos, relacionar o conteúdo de cada subquery com a instruçăo UPDATE para alinhar todas as linhas das tabelas. Para utilizarmos colunas de outras tabelas na cláusula SET devemos criar mais subquerys que, dependendo da situaçăo, devem ser relacionadas com a tabela que está sendo alterada. A abordagem que utiliza subquerys é considerada compatível com o padrăo SQL-92 por utilizar somente recursos que podem ser executados em qualquer banco de dados que siga o padrăo.
A abordagem que utiliza o join facilita o uso de mais de uma coluna para fazer a relaçăo com as tabelas, nos casos de chaves primárias compostas, e também a utilizaçăo de colunas de qualquer tabela que for referenciada na cláusula SET da instruçăo. Para simplificar, utilizamos o alias P para a tabela PRODUTOS e o alias I para a tabela ITENSPEDIDOS, facilitando a identificaçăo de qual coluna pertence a qual tabela na instruçăo. A abordagem que utiliza o join faz uso de extensőes do Transact-SQL, um dialeto do SQL-92 utilizado pelo SQL Server.
No que diz respeito ao desempenho, tanto para o acesso aos dados como para o tempo de execuçăo, geralmente recomenda-se a abordagem que utiliza join, pois isso indica para o otimizador de consultas que ele pode fazer uso de algoritmos e heurísticas mais apropriadas para a obtençăo de um plano de execuçăo melhor. Esta recomendaçăo pode ser comprovada através de experimentos.
É importante notar que, nas duas abordagens, somente a tabela PRODUTOS foi alterada. Esta é uma característica da instruçăo UPDATE: mesmo com várias tabelas sendo utilizadas na instruçăo, somente colunas de uma tabela podem ser alteradas. A instruçăo DELETE permite que as linhas de uma única tabela sejam apagadas, quando utilizamos join na instruçăo DELETE.
Vamos ver agora um exemplo de instruçăo DELETE que relaciona mais de uma tabela. Vamos supor que desejamos apagar todos os produtos que năo estejam em nenhum pedido. A Listagem 2 apresenta as duas abordagens para apagar os produtos.

A abordagem que utiliza subquerys agora faz uso da negaçăo do resultado da funçăo IN(), que vai indicar se o valor de uma coluna năo pertence a uma lista de valores.
Para a abordagem que utiliza join, foi feito o uso de um LEFT OUTER JOIN, tipo de join que relaciona todas as linhas da tabela ŕ esquerda do comando JOIN mesmo que năo haja correspondęncia dos valores com a tabela ŕ direita do comando JOIN. Para obter somente os produtos que năo fazem parte da de nenhum pedido, um filtro na coluna PROD_COD, da tabela ITENSPEDIDO, foi feito utilizando o operador IS NULL.
Uma dica: antes de executarem instruçőes UPDATE ou DELETE que relacionam tabelas, façam o teste em instruçőes SELECT, pois assim podemos testar se o conjunto de linhas que queremos alterar ou apagar está sendo selecionado corretamente.
Neste artigo discutimos a atualizaçăo de dados com base no relacionamento entre tabelas. As atualizaçőes automáticas de linhas, através deconstraintsque permitem modificaçőes em cascata, foram apresentadas assim como a utilizaçăo de relacionamentos entre tabelas nas instruçőes UPDATE e DELETE. Duas abordagens para a modificaçăo em tabelas relacionadas foram apresentadas: a que utiliza join e a que utiliza subquery. As abordagens foram apresentadas e comparadas através de exemplos práticos.







