Utilizando o select para formatar dados em relatórios – Parte 01
Resumo
Alguns relatórios gerados a partir de instruçőes SELECT permitem a apresentaçăo dos dados para os usuários na forma de lista, onde os valores das colunas săo colocados linha a linha. Em determinadas situaçőes a quantidade dos dados precisa ser divida em colunas com o objetivo de facilitar a leitura do relatório. Este artigo apresenta uma maneira de dividir os dados entre as colunas apresentando-os alternadamente.
Duplicando os dados
Quando temos que apresentar informaçőes na forma de lista, isto é, em linhas e colunas, geralmente utilizamos a instruçăo SELECT para retornar os dados completos da tabela. Podemos limitar a quantidade de dados retornados utilizando a cláusula WHERE com o objetivo de filtrar certas linhas para que possamos visualizar somente o que nos interessa. Temos ainda a cláusula ORDER BY da instruçăo SELECT que permite a ordenaçăo dos resultados retornados pela instruçăo.
A maioria dos relatórios exige que, após o filtro e a ordenaçăo dos dados, todas as linhas sejam dividias em colunas, com o objetivo de facilitar a leitura do relatório. Como exemplo, vamos trabalhar com a tabela chamada TB_SEPARA, que possui tręs colunas: uma coluna chamada ID, contendo uma numeraçăo seqüencial sem falhas, uma coluna chamada NOME que representa um atributo texto comum de uma tabela e uma terceira coluna chamada DATA que também representa um atributo comum. A Tabela 1 mostra quatro linhas desta tabela.
|
ID |
NOME |
DATA |
|
1 |
A |
16/09/2005 |
|
2 |
B |
15/09/2005 |
|
3 |
C |
17/09/2005 |
|
4 |
D |
14/09/2005 |
Tabela 1. Quatro linhas da tabela TB_SEPARA.
Neste artigo utilizaremos instruçőes SELECT baseadas no dialeto T-SQL utilizado pelo SQL Server, mas com poucas alteraçőes as instruçőes aqui apresentadas podem ser portadas para outros bancos de dados sem grandes dificuldades.
A primeira manipulaçăo que iremos fazer nestes dados é duplicá-los fazendo com que o relatório possua seis colunas. Para isso utilizaremos um inner join que relacionará a tabela TB_SEPARA com ela mesma, utilizando um alias chamado A e outra alias chamado B, ambos apontando para a tabela TB_SEPARA.
O SQL Server permite colunas com nomes iguais em uma instruçăo SELECT, mas vamos modificar o nome das novas colunas para facilitar a manipulaçăo delas por uma aplicaçăo. A instruçăo apresentada na Listagem 1 faz a duplicaçăo das colunas e dos dados:
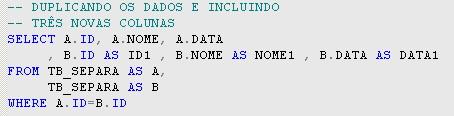
Listagem 1. Instruçăo SELECT que duplica os dados e as colunas.
O resultado da execuçăo da instruçăo apresentada na Listagem 1 pode ser visto na Tabela 2.
|
ID |
NOME |
DATA |
ID1 |
NOME1 |
DATA1 |
|
1 |
A |
16/09/2005 |
1 |
A |
16/09/2005 |
|
2 |
B |
15/09/2005 |
2 |
B |
15/09/2005 |
|
3 |
C |
17/09/2005 |
3 |
C |
17/09/2005 |
|
4 |
D |
14/09/2005 |
4 |
D |
14/09/2005 |
Tabela 2. Duplicaçăo dos dados em novas colunas.







