Data Deduplication
O crescente aumento do volume de dados das organizaçőes é um assunto pertinente ŕs equipes de infraestrutura de TI. Devido a esse aumento, torna-se necessário oferecer uma capacidade de storage com um volume cada vez maior.
Para o usuário, é imprescindível dispor de um bom volume de espaço disponível para armazenar os arquivos utilizados no dia-a-dia de suas atividades. Porém, grande parte do armazenamento consumido está relacionado a arquivos duplicados e outros dados redundantes armazenados pelos usuários em um ambiente de rede.
Pensando em solucionar esse problema, este artigo apresentará, na teoria e na prática, o Data Deduplication, sendo útil para os administradores de TI que pretendem implantar tal tecnologia em seu ambiente, tendo como principal objetivo a economia de espaço utilizado e a consequente reduçăo dos custos de armazenamento.
Um dos grandes desafios da administraçăo de TI nos dias atuais é atender as crescentes demandas de armazenamento de dados dentro de uma organizaçăo. Hoje os usuários necessitam armazenar milhares de arquivos texto, planilhas, imagens, vídeos, músicas, e-mails, entre outros tipos de dados.
Há anos essa situaçăo também já existia, em uma proporçăo menor, porém, com o avanço tecnológico, os arquivos e processos ficaram maiores. Assim, para que a TI possa atender as novas demandas de negócio, é necessário investimento em várias frentes, e no armazenamento é uma delas.
Contudo, năo bastasse o grande desafio de fornecer armazenamento para os usuários, lidando com altos volumes de dados e alto investimento em hardware, é necessário entender também como os usuários armazenam estes dados nos servidores.
Năo é incomum verificar diversos tipos de arquivos duplicados em um servidor de arquivos. Por exemplo, um grupo de usuários do departamento de Contabilidade recebe por e-mail a ata de reuniăo realizada por eles.
Supondo que este grupo tenha 30 pessoas, este mesmo arquivo poderá ser armazenado até 30 vezes em locais diferentes em um compartilhamento de rede, já que, além de pastas departamentais, os usuários possuem também pastas pessoais.
Neste exemplo, uma ata de reuniăo pode significar pouco espaço. Porém, dependendo do tipo de arquivo (apresentaçőes de slides, vídeos, músicas, etc.) esse volume desperdiçado pode ser muito maior. Assim, seria de grande ajuda se estes dados duplicados pudessem ser eliminados, sem atrapalhar as atividades dos usuários.
Pensando nisso, neste artigo será abordado o conceito de Data Deduplication no Windows Server 2012, ferramenta poderosa que auxilia os administradores de TI a eliminar os dados duplicados no seu ambiente.
O que é o Data Deduplication?
Data Deduplication é um recurso disponível no Windows Server 2012 e Windows Server 2012 R2 utilizado para maximizar o espaço de armazenamento de dados.
O conceito de eliminaçăo de dados duplicados năo é novo. Atualmente existem diversas ferramentas (em formato de appliance de hardware ou software) que realizam esta funçăo, porém, por apresentarem um alto custo e uma alta curva de aprendizado, năo săo adotadas pelas empresas.
Até que tivemos o lançamento do Windows Server 2012, que trouxe como uma de suas principais novidades uma nova funçăo, chamada de Data Deduplication. O Data Deduplication é uma tecnologia baseada em software que permite maximizar o uso da capacidade de armazenamento de dados da organizaçăo, e o seu o princípio básico é a năo necessidade de armazenamento do mesmo arquivo várias vezes.
Como funciona a eliminaçăo dos dados duplicados?
Quando configurada a ferramenta Data Deduplication, o primeiro passo efetuado é uma varredura no volume em busca dos dados duplicados.
Durante este processo, o Data Deduplication simplesmente identificará os dados que estăo em duplicidade. Após identificados, a ferramenta irá manter apenas uma cópia do mesmo, e as demais serăo substituídas por uma referęncia ŕ cópia principal.
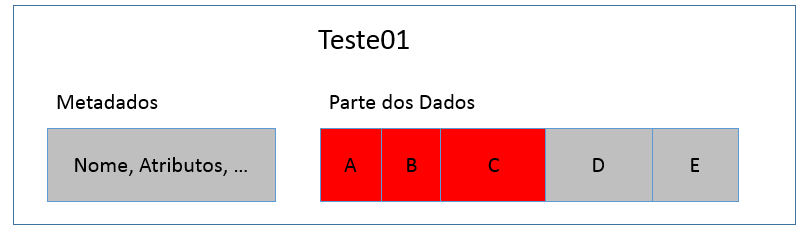
Todos sabem que os arquivos săo formados por metadados, que contęm informaçőes sobre o nome do arquivo, atributos, entre outras. Além disso, também sabemos que um arquivo é composto por diversos pedaços. Na Figura 1 temos o exemplo do arquivo Teste01 no formato NTFS. Note que este arquivo possui diversos “pedaços”, descritos como A, B, C, D e E.
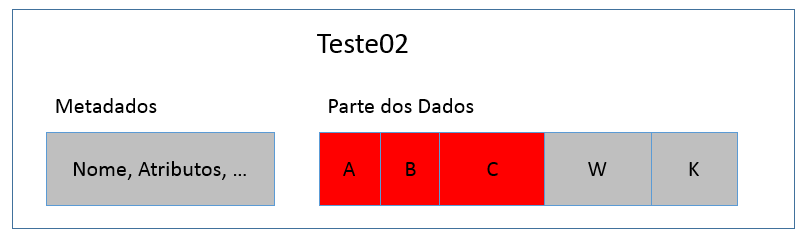
Já a Figura 2 mostra o arquivo Teste02, que possui também diversos pedaços, assim como o arquivo Teste01, descritos como A, B, C, W e K.
Durante o processo de análise, o Data Deduplication irá analisar os arquivos do volume em que está configurado e irá encontrar os dados que estăo em duplicidade.
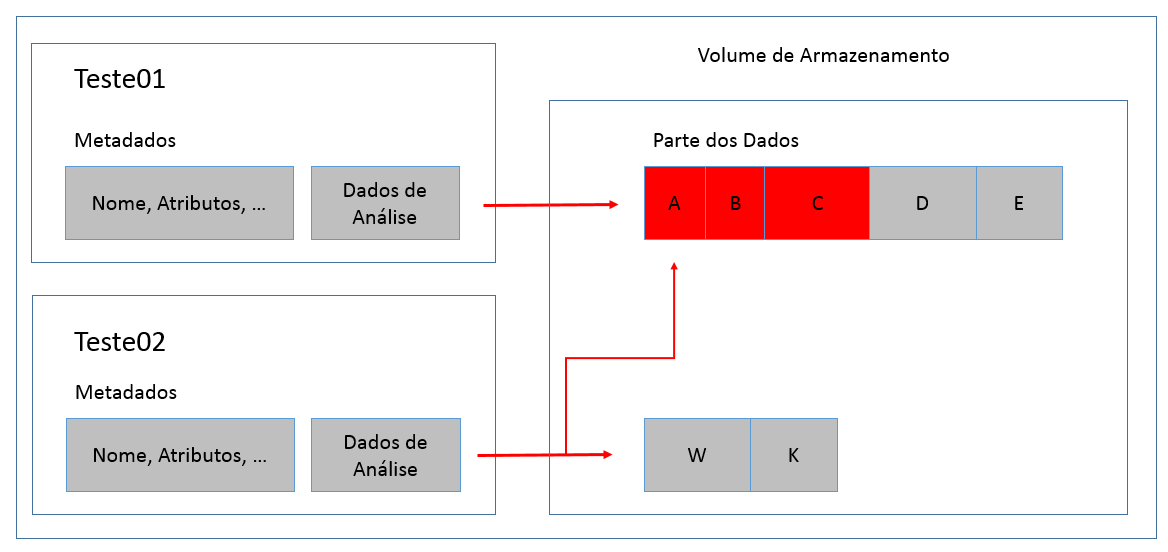
Nesse momento, o Data Deduplication identificará que os arquivos Teste01 e Teste02 possuem dados em comum (duplicados). Entăo, serăo gerados dados de análise na estrutura dos dois arquivos, como indicado na Figura 3. Estes dados de análise armazenarăo informaçőes sobre a identificaçăo dos dados do arquivo e também dos links de apontamento para os blocos da cópia principal, eliminando assim o dado duplicado.
Quais resultados esperar com Data Deduplication?
Para que se possa realizar uma avaliaçăo dos resultados a serem alcançados com a utilizaçăo do Data Deduplication, devemos primeiro avaliar os dados que estăo dentro do volume que será afetado.
A eficięncia da eliminaçăo dos dados duplicados será diretamente proporcional ao tipo de arquivo que o volume possui. As taxas de economia de espaço podem variar de 30% a 90%, segundo dados da própria Microsoft.
A Tabela 1 apresenta a relaçăo de economia de volume de acordo com o tipo de conteúdo dos arquivos.
|
Cenário do Volume de dados |
Conteúdo |
Economia de espaço (variaçăo) |
|
Documentos diversos |
Texto, imagem, áudio e vídeo |
30-50% |
|
Arquivos compartilhados pelo sistemas |
Binários de software, arquivos de sistema, arquivos de símbolo |
70-80% |
|
Volumes de virtualizaçăo |
Arquivos de disco rígido virtual |
80-95% |
Tabela 1 Reduçăo variável de dados em um volume com Data Deduplication.
Como a eliminaçăo dos dados também exige tempo de leitura, processamento e gravaçăo de dados, é necessário avaliar os recursos do servidor onde este recurso será aplicado. Um servidor que sempre estiver utilizando sua capacidade máxima terá falta de recursos para realizar a eliminaçăo dos dados.
Podemos exemplificar essa situaçăo com um servidor de arquivos que utiliza todos os seus recursos durante o período comercial (08h00 as 18h00). Em casos como este, onde o consumo de memória, de processamento e de disco săo elevados, o Data Deduplication poderá ser configurado para ser executado em um período no qual a demanda é praticamente nula (fora do horário comercial), e desta forma, irá aumentar a eficięncia do Data Deduplication.
Segundo a Microsoft, os tipos de servidores candidatos ŕ eliminaçăo de dados podem ser classificados a partir da análise da economia de espaço adquirida e dos recursos utilizados (memória, processamento, etc.).
De acordo com exaustivos testes e laboratórios por ela realizados, os candidatos săo divididos em tręs categorias:
- Ótimos candidatos para eliminaçăo de duplicaçăo:
- o Servidores de redirecionamento de pastas;
- o Repositório de virtualizaçăo ou biblioteca de provisionamento;
- o Compartilhamentos de implantaçőes de software;
- o Volumes de backup do SQL Server e do Exchange Server.
- Candidatos que devem ser avaliados com base no conteúdo dos dados a serem eliminados:
- o Servidores de linha de negócios (servidores que hospedam aplicaçőes críticas para o negócio);
- o Provedores de conteúdo estático;
- o Servidores Web.
- Candidatos ruins para a eliminaçăo de duplicaçăo:
- o Hosts de Hyper-V;
- o WSUS (Windows Server Updates Services) – Servidor de atualizaçőes do Windows;
- o Servidores que executam SQL Server ou Exchange Server;
o Arquivos com tamanho próximo a 1 TB ou que sejam maiores que isso.
Além das informaçőes citadas anteriormente, outros fatores devem ser levados em consideraçăo antes da implementaçăo do Data Deduplication. Săo eles:
- O volume a ser configurado năo pode ser o de inicializaçăo de sistema. O Data Deduplication năo suporta configuraçăo em volumes que contenham a instalaçăo do sistema operacional;
- A partiçăo pode ser MBR (Master Boot Record) ou GPT (GUID Partition Table), e devem estar formatadas em NTFS;
- Os arquivos com atributos estendidos, arquivos criptografados e arquivos menores que 32KB năo săo processados pelo Data Deduplication;
- Arquivos que săo abertos ou alterados constantemente năo terăo economia (como máquinas virtuais, bancos de dados, etc.), já que, como os dados estăo em uso, năo será possível realizar a eliminaçăo dos dados duplicados;
- Năo suporta dispositivos removíveis.
Backup e Restore
Um recurso que é bastante impactado (de forma positiva) pelo uso de Data Deduplication é o backup dos dados da organizaçăo, visto que, com o aumento crescente da quantidade de dados sendo armazenados, consequentemente necessita-se de mais espaço para realizaçăo do backup.
Dito isso, atualmente, quais săo os fatores que influenciam a realizaçăo de uma política de backup em uma organizaçăo?
- Investimento: Compra de hardware para backup. Se a empresa pretende gravar os dados em fitas, é necessário um hardware específico para que a gravaçăo seja realizada;
- Volume: Quanto maior o volume de dados, maior será a quantidade de fitas necessárias para realizaçăo do backup;
- Janela de Backup: A junçăo do volume de dados ao hardware
utilizado irá influenciar diretamente na janela de backup, já que quanto maior
o volume de dados, maior será o tempo necessário para gravaçăo.
Para diminuir essa janela, é necessário hardware com velocidade maior para acelerar o processo. Consequentemente, a janela de backup também é importante, porque ela deve estar alinhada ŕs necessidades da política de backup da empresa.
Por exemplo, caso a empresa tenha necessidade de garantir uma retençăo de dados que foram salvos nas fitas por uma semana, esta janela năo pode ter um período maior do que sete dias para ocorrer, caso contrário, năo atenderá ŕ política adotada; - Restore: Quanto tempo seria necessário para restauraçăo dos dados em caso de um desastre? Se por algum motivo acontecer um problema e a restauraçăo dos dados se torna necessária, o tempo do restore será proporcional ao volume de dados persistido no backup, ou seja, quanto maior o volume, mais tempo será gasto para executar a restauraçăo.
Um volume com os dados duplicados eliminados irá proporcionar a realizaçăo de um backup mais rápido, consumindo um menor número de fitas e otimizando o tempo de restore.
A funçăo Windows Backup, nativa no Windows Server, possui suporte para realizaçăo de backups de volumes que estejam com o recurso de Data Deduplication ativado. E além da Microsoft, existem outros fornecedores que disponibilizam ferramentas de backup com suporte a esta funçăo (HP, CA, etc). Deste modo, antes de adquirir uma destas soluçőes, é aconselhável consultar a documentaçăo de cada produto.
Com isso, podemos afirmar que além do benefício da economia de espaço em disco gerado pela eliminaçăo dos dados duplicados, o ganho com a performance do backup também é muito válido e deve ser analisado no momento da implantaçăo desse recurso.
Data Deduplication no Windows Server 2012 R2
Neste tópico será demonstrado como implementar a funçăo de Data Deduplication no Windows Server 2012 R2. Para isto, existem duas opçőes: através do Server Manager e através do Powershell.
O Server Manager é uma ferramenta que tem como funçăo auxiliar os administradores de TI, centralizando diversas opçőes para instalaçăo, configuraçăo e gerenciamento de funçőes e recursos de servidores. Quando um usuário faz logon em um servidor, por padrăo, a janela do Server Manager é iniciada, conforme demonstra a Figura 4.
Para realizar a instalaçăo do Data Deduplication através do Server Manager, na tela inicial, clique em Add roles and features. Feito isso, será carregada a tela inicial para instalaçăo e configuraçăo de Roles (Funçőes) e Features (Recursos).
A primeira tela mostra uma visăo geral do assistente e lista algumas informaçőes antes de prosseguir com a instalaçăo. Esta lista destaca algumas boas práticas ao administrar servidores, a saber: ter uma senha de administrador forte; que as configuraçőes de rede, como os endereços IP estáticos, já estejam definidas; e ter as atualizaçőes do Windows Update instaladas (ver Figura 5). Para confirmar estas informaçőes, basta clicar em Next. Neste ponto vale ressaltar que esses itens năo săo pré-requisitos, portanto, mesmo năo sendo atendidos, a instalaçăo poderá continuar sem problemas.
A segunda janela do assistente irá definir o tipo de instalaçăo, fornecendo duas opçőes: Instalaçăo baseada em Role ou Feature ou Instalaçăo para Serviços de Desktop Remoto. Neste caso, utilizaremos a primeira opçăo, como indica a Figura 6. Feito isso, clique mais uma vez em Next.
No terceiro passo deve-se selecionar o servidor ou o disco virtual onde desejamos implantar o Data Deduplication. Neste caso, marque a primeira opçăo e depois selecione o servidor SRVDC01, conforme indica a Figura 7. Em seguida, clique em Next.
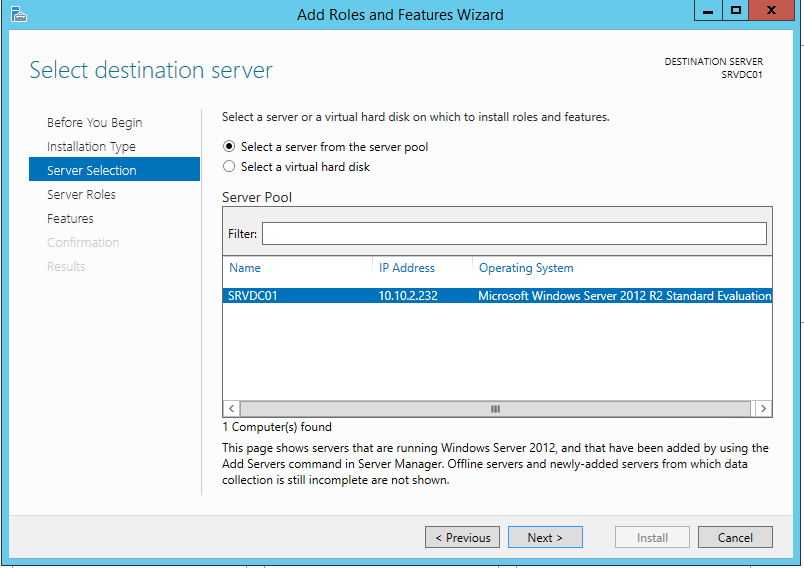
No quarto passo, devemos selecionar quais Roles serăo instaladas. O assistente irá listar as Roles disponíveis para instalaçăo no servidor (como DNS Server, Hyper-V, DHCP Server, entre outros). Para tanto, expanda a opçăo File and Storage Services, depois File and iSCSI Services e selecione Data Deduplication, conforme a Figura 8. Logo após, clique novamente em Next.
No quinto passo, deve-se selecionar as Features que serăo instaladas. Neste laboratório, năo iremos instalar nenhuma Feature. Portanto, podemos avançar neste passo. O sexto passo, que é o final, irá mostrar um resumo do que será instalado.
Nesta janela também há uma opçăo que, ao ser marcada, reiniciará o servidor destino assim que a instalaçăo for concluída, caso seja necessário. Observe a Figura 9.
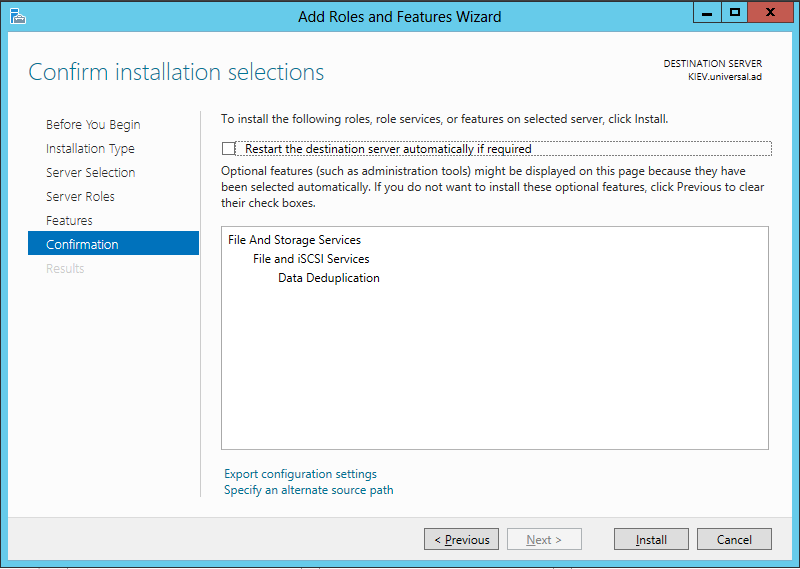
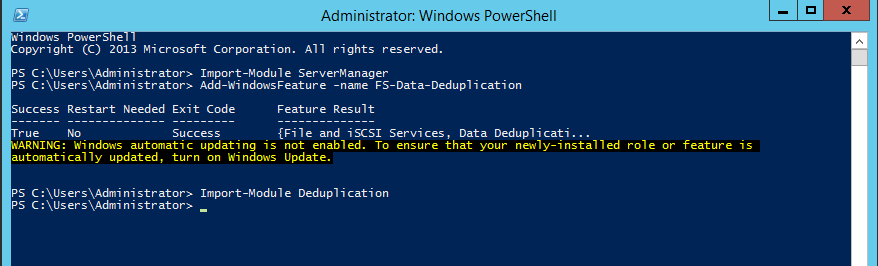
A segunda forma para instalaçăo do Data Deduplication é através do PowerShell. Para tanto, abra o Windows Powershell e execute os comandos apresentados a seguir, que também podem ser analisados na Figura 10:
Import-Module ServerManager
Add-WindowsFeature –name FS-Data-Deduplication
Import–Module Deduplication
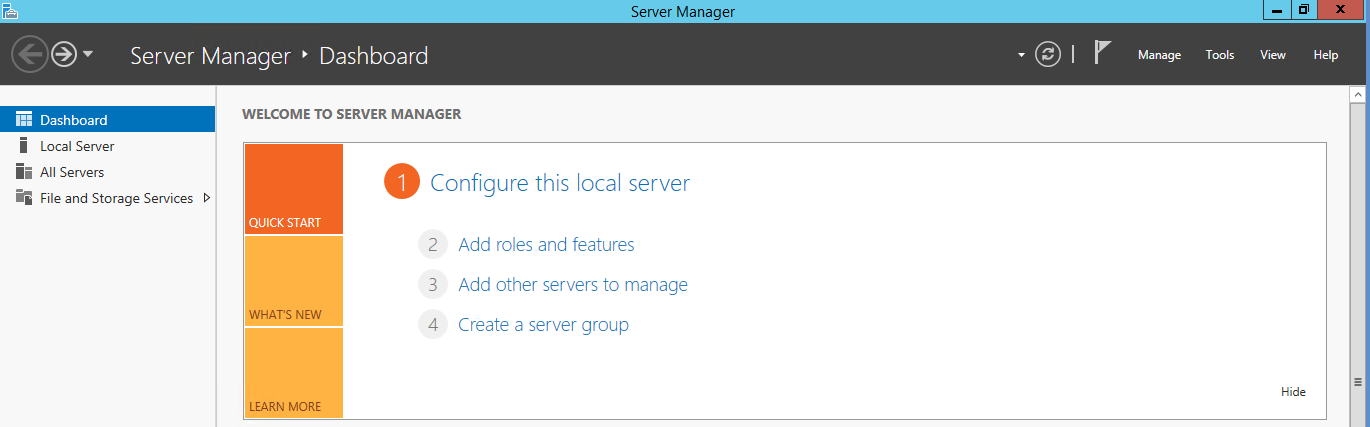
Após completar a instalaçăo do Data Deduplication, podemos verificar no Server Manager uma nova guia de navegaçăo, denominada File and Storage Services (veja a Figura 11). Será esta guia que será utilizada para realizar as configuraçőes deste recurso.
Agora que a funçăo está instalada, o próximo passo é habilitá-la e configurá-la nos volumes de dados desejados. Para esta demonstraçăo, foi criada uma partiçăo de 30 GB, denominada Teste_Dedup, conforme a Figura 12, que pode ser analisada através do Computer Management, localizado junto ŕs ferramentas administrativas do Windows.

Para iniciar a configuraçăo do Data Deduplication, no Server Manager, acesse a guia File and Storage Services e depois a guia Disk, para exibir os discos e os volumes existentes no servidor (veja a Figura 13).
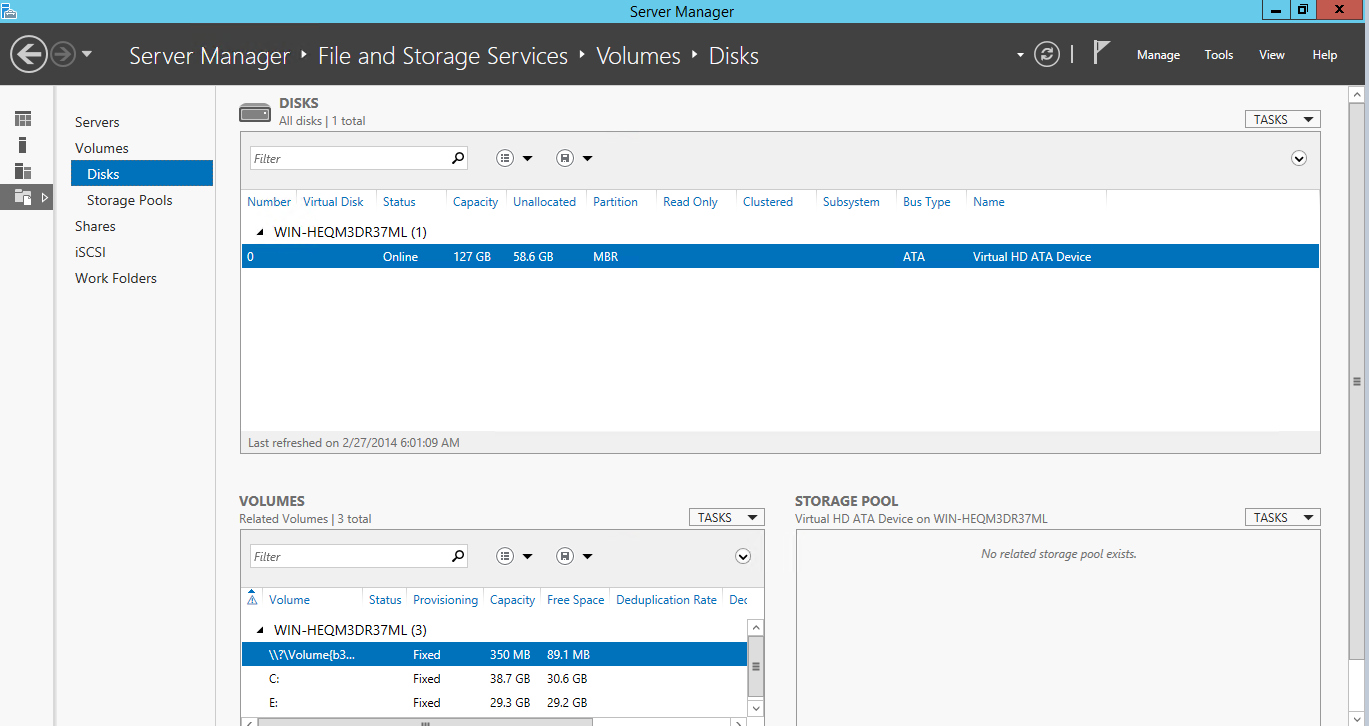
No espaço Volumes, visualizado na parte inferior da janela, săo exibidos os volumes disponíveis. Conforme comentado anteriormente, foi criado um volume para realizaçăo desta demonstraçăo, representado pela unidade E.
Assim, clique com o botăo direito do mouse sobre este volume e selecione a opçăo Configure Data Deduplication, de acordo com a Figura 14.
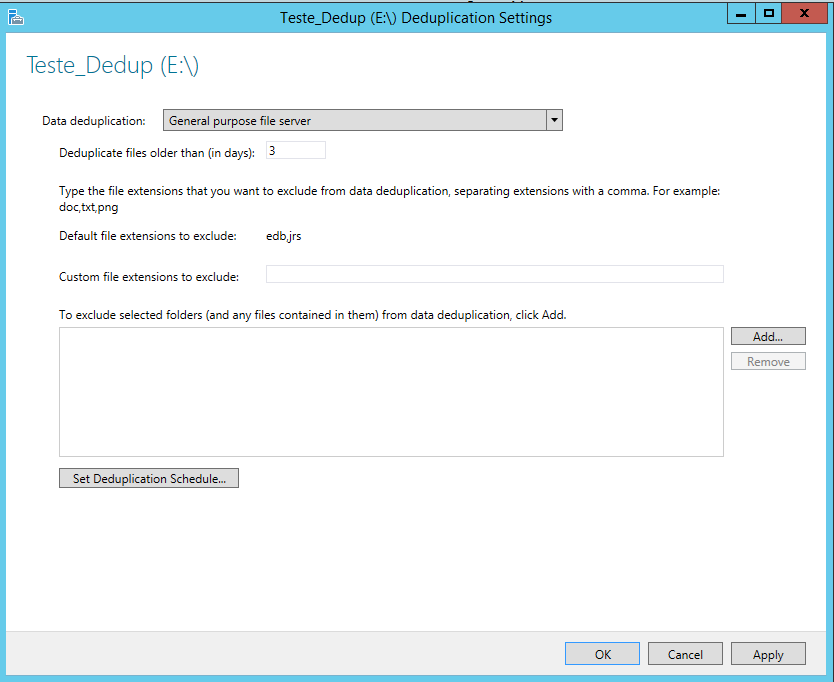
Na janela Deduplication Settings, é necessário selecionar algumas opçőes para configurar o Data Deduplication, a saber:
· Em Data deduplication, podemos definir o tipo do volume a ser utilizado, que pode ser General Purpose file server (Servidor de Arquivos de Uso Geral) ou Virtual Desktop Infrastructure (VDI) Server (Servidor para infraesturtura virtual VDI);
· Em Deduplicate files older than (in days), podemos definir a partir de quantos dias o arquivo será eliminado. Caso informe 3, os dados que forem gravados só serăo analisados após o terceiro dia;
· Em Custom file extensions to exclude, podemos definir extensőes de arquivos a serem excluídas do processo de eliminaçăo de dados duplicados;
· Por fim, em To exclude selected folders from data deduplication, podemos definir pastas que devem ser excluídas da verificaçăo para eliminaçăo de dados duplicados.
Na Figura 15 apresentamos as configuraçőes que realizamos para o nosso exemplo.
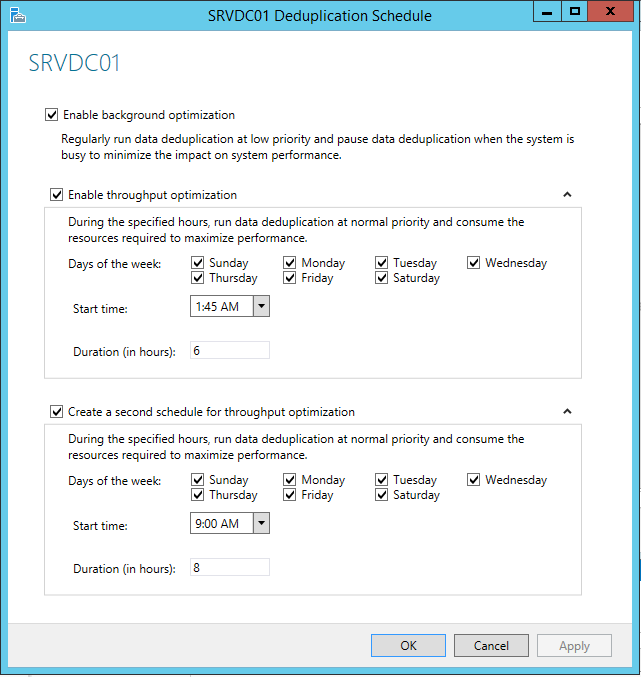
Nesta janela também é possível clicar no botăo Set Deduplication Schedule..., que permite configurar a opçăo Enable background optimization (Otimizaçăo de Desempenho em Segundo Plano), onde o Data Deduplication irá utilizar o sistema de forma a minimizar o impacto no desempenho do servidor, e também a opçăo Enable throughput optimization (Habilitar a otimizaçăo do rendimento), que possibilita agendar as datas e horários específicos para rodar o Data Deduplication, podendo assim consumir o máximo de recursos disponíveis no servidor (veja a Figura 16).
Verificando o desempenho do Data Deduplication
Para demonstrar a execuçăo deste recurso, foram gravados neste disco de teste aproximadamente 25 GB de dados variados, contendo documentos de texto, imagens, arquivos de áudio, vídeos, entre outros, como pode ser verificado na Figura 17.
Neste ambiente de teste, após 48 horas, já é possível verificar e analisar os resultados obtidos com a utilizaçăo do Data Deduplication. O tempo necessário para realizaçăo da eliminaçăo de dados duplicados varia de acordo com o tipo de dado armazenado, o volume total de dados, entre outros fatores, como a utilizaçăo da otimizaçăo em segundo plano e a otimizaçăo de desempenho.
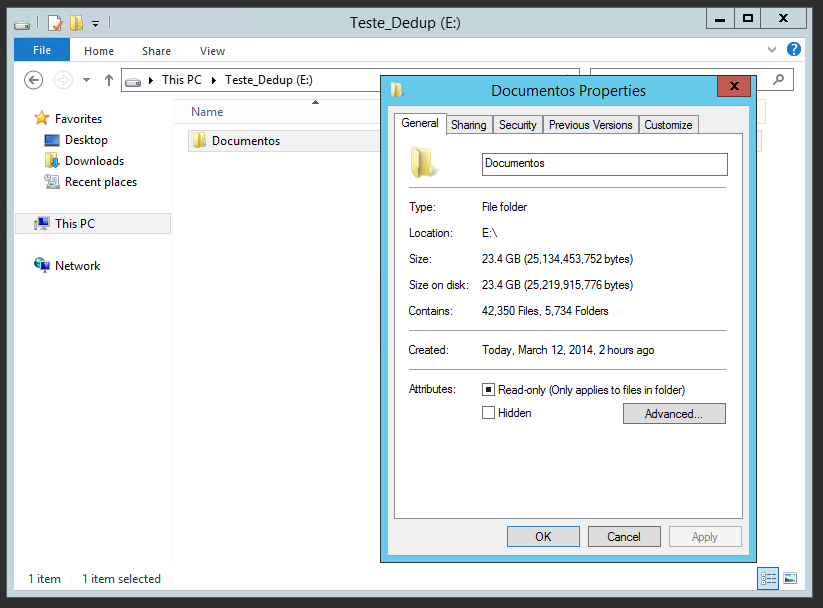
Analisando as propriedades da pasta Documentos, conforme a Figura 18, pode-se verificar que o volume possui um total de dados de 23,4 GB, informado no campo Size, e após a realizaçăo da eliminaçăo dos dados duplicados, passa a apresentar um volume gravado no disco (Size on Disk) de 187 MB. Como pode-se notar, neste exemplo a economia de armazenamento de disco gerada pelo Data Deduplication foi de 23 GB.
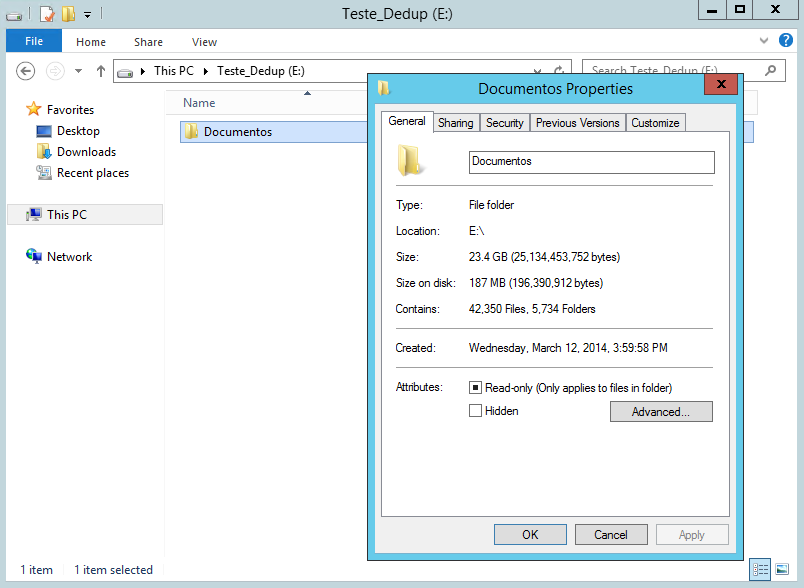
Também é possível verificar nas propriedades do disco a economia gerada pelo Data Deduplication, como demonstra a Figura 19.
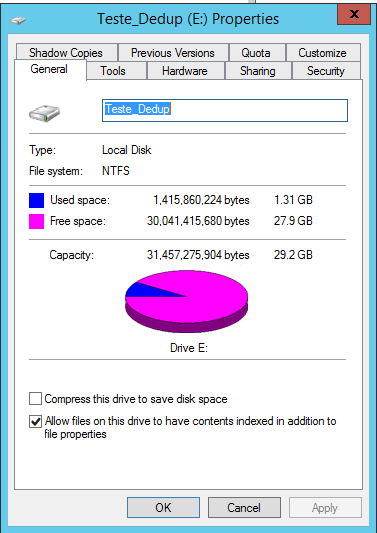
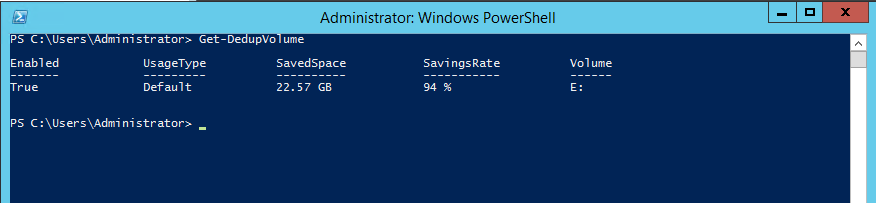
Outra forma de validar os ganhos com Data Deduplication é através do PowerShell. Com dois comandos podemos analisar o status da eliminaçăo dos dados e diversas outras informaçőes.
O primeiro comando mostra um resumo do volume que teve os dados duplicados eliminados (ver Figura 20). Para verificar esses dados, abra o PowerShell e digite o seguinte comando: Get-DedupVolume.
O segundo comando também mostra um resumo, porém mais detalhado (ver Figura 21). Para verificar esses dados, com o PowerShell aberto, execute o seguinte comando:
Get-DadepVolume |fl.
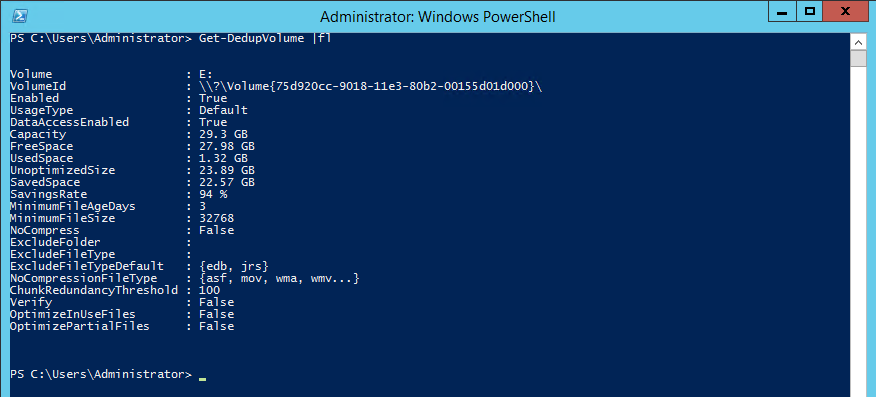
Em ambos os casos é possível constatar que, no laboratório realizado, o Data Deduplication economizou 94% do espaço no volume (informaçăo indicada no campo SavingsRate).
A utilizaçăo da ferramenta Data Deduplication pode trazer muitos resultados positivos para as organizaçőes. Dentre eles, podemos destacar a reduçăo do espaço utilizado para armazenamento de dados, maior agilidade na realizaçăo e restauraçăo de backups, e reduçăo do custo de investimento em TI.
Assim, com a realizaçăo de um planejamento para implantaçăo deste recurso, a administraçăo de TI terá uma poderosa ferramenta que proporcionará tanto benefícios de economia de espaço em disco, como benefícios financeiros, já que, com a reduçăo de consumo, năo será necessário o investimento recorrente em hardware para armazenamento de dados.
Links Úteis
- O que é .NET Core?:
Neste curso aprenderemos o que é o .NET Core, uma plataforma para desenvolvimento de aplicaçőes desenvolvida e mantida pela Microsoft. - 6 Dicas para melhorar seu código:
Para um bom programador năo basta apenas funcionar, o código precisa atender a alguns requisitos mínimos de qualidade. Confira neste DevCast 6 dicas para tornar o seu código mais legível e organizado. - Como tratar exceçőes na linguagem Java:
Aprenda o que é o mecanismo de exceçőes do Java, conheça as suas categorias e saiba como desenvolver programas que consigam tratar suas próprias exceçőes.
Saiba mais sobre Administraçăo de TI ;)
- Guias Engenharia de Software:
Encontre aqui os Guias de estudo sobre os principais temas da Engenharia de Software. De metodologias ágeis a testes, de requisitos a gestăo de projetos! - Gestăo de Projeto:
Neste guia vocę encontrará o conteúdo que precisa para saber como gerenciar projetos de software. Confira abaixo a sequęncia de posts que te guiarăo do básico ao avançado em Gestăo de Projetos. - Testes de Software:
Neste guia de consulta vocę encontrará diversos artigos e vídeos que podem ser usados ao longo dos seus estudos sobre Testes de Software, abordando diversas técnica e ferramentas.
Referęncias:
Visăo Geral de Eliminaçăo de Duplicaçăo de Dados
Microsoft Press blog - Windows Server 2012’s Data Deduplication feature
Step-by-Step: Reduce Storage Costs with Data Deduplication in Windows Server 2012







