Um diferencial significativo na arquitetura proposta para a plataforma J2EE foi a iniciativa de enfatizar a utilizaçăo de padrőes de projetos. Tais padrőes trazem inúmeras vantagens na modelagem e implementaçăo de um software:
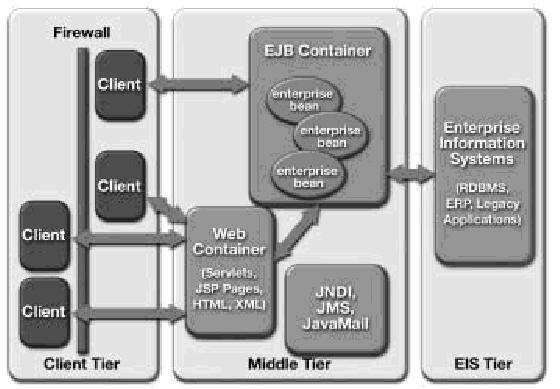
Os principais serviços disponibilizados pela plataforma J2EE destinam-se a suprir as necessidades de aplicaçőes empresariais distribuídas, isto é, aquelas que necessitam da flexibilidade de disponibilizar acesso ŕ sua lógica de negócio e dados para diferentes tipos de dispositivos clientes (navegadores, dispositivos móveis, aplicaçőes desktop, etc) e/ou para outras aplicaçőes residentes na mesma empresa ou fora desta. A Figura 1.1 ilustra um ambiente J2EE típico.
Aplicaçőes distribuídas săo comumente compostas de uma camada cliente, que implementa a interface com o usuário, uma ou mais camadas intermediárias, que processam a lógica do negócio e provęem serviços ŕ camada cliente, e outra, chamada de Enterprise Information System ou EIS, formada por sistemas legados e bancos de dados. A infraestrutura oferecida pela J2EE possibilita que estas camadas, possivelmente localizadas em máquinas diferentes, possam se comunicar remotamente e juntas comporem uma aplicaçăo.
Um componente criado numa aplicaçăo J2EE deve ser instalado no container apropriado. Um container é um ambiente de execuçăo padronizado que provę serviços específicos a um componente. Assim, um componente pode esperar que em qualquer plataforma J2EE implementada por qualquer fornecedor estes serviços estejam disponíveis.
Um web container destina-se a processar componentes web como servlets, JSP's, HTML's e Java Beans. Estes săo suficientes para criar aplicaçőes completas que năo necessitam ser acessadas por diferentes tipos de cliente nem tampouco tornar seus dados e lógica distribuídos. Já um EJB container destina-se a prover a infraestrutura necessária para a execuçăo de componentes de negócio distribuídos. Um EJB (Enterprise Java Bean) é um componente de software que estende as funcionalidades de um servidor permitindo encapsular lógica de negócio e dados específicos de uma aplicaçăo. Tal componente pode ser acessado de maneiras diferentes, por exemplo através de RMI, CORBA ou SOAP, o que possibilita que este seja utilizado por qualquer tecnologia que provę suporte a um destes padrőes de comunicaçăo e que seja localizado virtualmente a partir de qualquer rede TCP/IP.
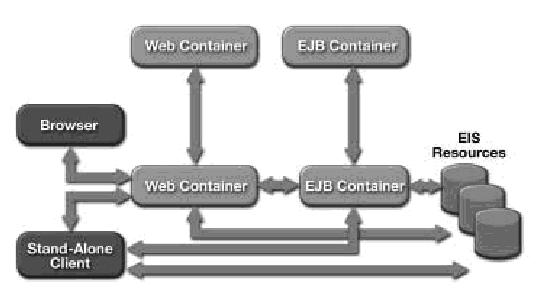
A plataforma J2EE permite uma arquitetura flexível sendo que tanto o web container quanto o EJB container săo opcionais. Alguns cenários possíveis podem ser observados na Figura 1.2.
O cenário que estaremos considerando neste trabalho é precisamente o ilustrado na Figura 1.3.
Como apresentado no livro [J2EETIP], uma aplicaçăo web em tręs camadas é na maioria das vezes a escolha inicial para uma aplicaçăo J2EE e é como implementar este tipo de aplicaçăo que estaremos discutindo aqui. Nesta configuraçăo, o container web encarrega-se de tratar tanto a lógica de apresentaçăo como a de negócios e veremos qual a melhor forma de organizarmos estas responsabilidades de forma a criarmos aplicaçőes modulares, organizadas, com reaproveitamento de código e mais manuteníveis e extensíveis, ou seja, como criar aplicaçőes profissionais neste cenário.
Neste artigo, discutiremos alguns padrőes e estratégias de projeto que consideramos necessários ŕ construçăo de aplicaçőes J2EE profissionais năo distribuídas. Basicamente, consiste num resumo de alguns dos padrőes encontrados no livro [ALUR] acrescido de comentários baseados em nossa experięncia prática no desenvolvimento destes tipos de aplicaçőes. Muitas referęncias săo feitas ŕ framework Struts e como esta implementa vários dos padrőes e estratégias aqui apresentados.
A correta utilizaçăo de arquiteturas e padrőes de projeto no desenvolvimento de softwares representa um importante ideal a ser alcançado por qualquer equipe que pretende produzir aplicaçőes computacionais profissionais. Năo basta aprender uma tecnologia, é necessário também conseguir projetar soluçőes com esta tecnologia. A definiçăo de uma arquitetura, por exemplo, permite que tenhamos uma visăo completa da aplicaçăo, de quais săo seus principais componentes, o objetivo de cada um deles e a maneira como se relacionam a fim de desempenharem suas funçőes. Quando utilizamos padrőes, estamos levando em conta experięncias de outros projetos de desenvolvimento, aumentando assim as chances de chegarmos em uma soluçăo correta pois erros passados poderăo ser evitados.
Em aplicaçőes sob a plataforma J2EE năo é diferente. Em geral estamos tăo atolados no processo de compreensăo dos serviços da plataforma, de suas APIs (Application Program Interface) e do negócio a ser resolvido que năo dedicamos o tempo necessário para aprender a projetar soluçőes com a tecnologia. Segundo Booch [ALUR] “existe um buraco semântico entre as abstraçőes e serviços que a plataforma J2EE oferece e a aplicaçăo final que será produzida com esta e os padrőes de projeto representam soluçőes que aparecem repetidamente para preencher este buraco”.
Um padrăo provę uma soluçăo para um problema comum baseado em experięncias anteriores comprovadamente eficazes. Dispor de um bom conjunto de padrőes é como ter um time de especialistas sentado ao seu lado durante o desenvolvimento, aconselhando-lhe com o melhor do seu conhecimento. Boas práticas de projeto săo descobertas pela experięncia e levam tempo até se tornarem maduras e confiáveis. Um padrăo captura essa experięncia e serve para comunicar, de forma padronizada, o conhecimento que trazem. Dessa forma, os padrőes, além de ajudarem os desenvolvedores e arquitetos a reutilizarem soluçőes tanto de projeto quanto de implementaçăo, ajudam também a criar um vocabulário comum na equipe, diminuindo assim o esforço de comunicaçăo.
Veremos agora um resumo dos mais relevantes padrőes e estratégias de projeto para a construçăo de aplicaçőes J2EE profissionais năo distribuídas.
A plataforma J2EE provę uma clara divisăo, tanto lógica quanto física, de uma aplicaçăo em camadas. O particionamento de uma aplicaçăo em camadas permite uma maior flexibilidade de escolha da tecnologia apropriada para uma determinada situaçăo. Múltiplas tecnologias podem ser utilizadas para proverem o mesmo serviço possibilitando escolher a que melhor se adeqüa baseado nas características do problema em questăo. Por exemplo, como pôde ser observado na Figura 1.1, é possível utilizar para a construçăo da camada cliente, quando um EJB container está sendo considerado, tanto páginas HTML e JSP como também um cliente desktop.
Como comentado anteriormente, existem situaçőes onde a utilizaçăo de EJBs é desnecessária, a aplicaçăo năo necessita ser distribuída e apenas um subconjunto dos serviços disponíveis na plataforma atende aos seus requisitos. Dessa forma, nosso foco está na construçăo de aplicaçőes web em tręs camadas, sendo a camada dos EJBs desconsiderada. Cada camada e suas responsabilidades săo:
A camada responsável pelo processamento dos EJBs é a Enterprise JavaBeans Tier. Esta fornece serviços, implementados por um EJB container, para os EJBs. Alguns deles săo: controle de transaçăo, mecanismos de segurança, persistęncia, dentre outros. Estes serviços disponíveis facilitam a vida do programador, que fica livre da obrigaçăo de ter que tratá-los, podendo se concentrar mais na implementaçăo das funcionalidades inerentes ao seu negócio. Quando esta camada está presente, a lógica de negócio (toda ou parte desta) pode passar a ser implementada nos componentes de negócio distribuídos, ficando a camada web assim mais voltada ŕ exibiçăo dos dados.
Por fim, mantenha em mente que estas săo divisőes lógicas que servem principalmente para melhor estruturar uma aplicaçăo. Com exceçăo talvez da camada cliente, năo está implícito que cada camada esteja em localizaçőes físicas diferentes. Nada impede por exemplo que o banco de dados esteja localizado no mesmo servidor que hospeda um web container numa arquitetura em tręs camadas, ou que tanto o web container e o EJB container estejam rodando na mesma máquina virtual Java. O importante é a divisăo de responsabilidades que resulta das tecnologias separadas.
Um dos principais padrőes que utilizaremos para construçăo de nossas aplicaçőes é o padrăo MVC ou Modelo-Vista-Controlador (do inglęs Model-View-Controller). Este padrăo separa tręs formas distintas de funcionalidades em uma aplicaçăo. O modelo representa a estrutura de dados e operaçőes que atuam nestes dados. Em uma aplicaçăo orientada a objetos, constitui as classes de objetos da aplicaçăo que implementam o que quer que a aplicaçăo tenha que fazer. Visőes implementam exclusivamente a lógica de apresentaçăo dos dados em um formato apropriado para os usuários. A mesma informaçăo pode ser apresentada de maneiras diferentes para grupos de usuários com requisitos diferentes. Um controlador traduz açőes de usuários (movimento e click de mouse, teclas de atalho, etc) juntamente com os valores de entrada de dados em chamadas ŕ funçőes específicas no modelo. Além disso, seleciona, baseado nas preferęncias do usuário e estado do modelo, a vista apropriada. Essencialmente, estas tręs camadas abstraem: dados e funcionalidades, apresentaçăo e comportamento de uma aplicaçăo
Os benefícios em usar o padrăo MVC săo:
Mais uma vez, a divisăo de responsabilidades que resulta deste particionamento lógico possibilita uma melhor compreensăo e organizaçăo dos requisitos da aplicaçăo e facilita a implementaçăo, manutençăo e extensăo dos mesmos. Nossas aplicaçőes obedecerăo a divisăo dessas tręs camadas lógicas da seguinte forma:
Em geral qualquer aplicaçăo, independente de plataforma, é projetada com um determinado fluxo de operaçăo em mente. Esperamos que os usuários interajam com a aplicaçăo seguindo este fluxo, pois cada etapa de uma operaçăo tem um propósito a ser cumprido para que toda ela complete com sucesso. Năo podemos, por exemplo, exibir detalhes do perfil de um usuário sem antes este ter sido selecionado.
Diferentemente das aplicaçőes desktop, os programas baseados na web estăo sujeitos a interrupçőes que podem ocorrer no fluxo esperado de operaçăo. O usuário pode pressionar o botăo de “Voltar” ou “Recarregar” do navegador, abortar prematuramente uma solicitaçăo em andamento, abrir novas janelas a qualquer momento, resubmeter uma operaçăo, etc. Nada disso ocorre numa aplicaçăo tradicional desktop, onde o programador tem controle muito maior sobre o fluxo de operacionalizaçăo do programa. É de responsabilidade da aplicaçăo web tratar estes inconvenientes e garantir que o fluxo e estado adequado da aplicaçăo sejam mantidos.
Uma das maneiras de fazer isso é inserir o código necessário para efetuar esse controle em cada uma das páginas JSP. Esta abordagem tem dois sérios problemas. Primeiro, o código referente ŕ lógica de controle é misturado com o código da lógica de apresentaçăo, dificultando a manutençăo destas páginas. Outro problema está relacionado ao fato de que a disseminaçăo da lógica de controle em múltiplas páginas JSP requer também manutençăo em cada uma das páginas. Numa aplicaçăo com dezenas ou centenas de páginas, sempre que essa lógica for alterada ter-se-á um grande trabalho para executar uma simples manutençăo, já que o código de controle foi reaproveitado numa abordagem copia-cola.
Uma soluçăo mais adequada para implementaçăo da lógica de controle é a utilizaçăo de um ponto centralizado para receber e tratar as solicitaçőes dos usuários. Isto é feito adicionando-se um controller ao projeto das aplicaçőes. Um controlador, além de prover os benefícios comentados no contexto do padrăo MVC, possibilita a centralizaçăo do código referente ao controle do fluxo de execuçăo de uma aplicaçăo reduzindo a quantidade de código Java (scriptlets) embutido nas páginas JSP. Isto promove a reutilizaçăo de código e melhora o desenvolvimento e manutençăo das páginas JSP, que passam a conter apenas código relativo a apresentaçăo de dados.
Além destes benefícios, a centralizaçăo do acesso provida por um controlador ajuda na implementaçăo dos seguintes ítens:
Cabe neste momento comentarmos sobre a framework Struts. Esta é uma implementaçăo bastante completa e flexível de um front controller e MVC, além de disponibilizar recursos que ajudam na construçăo da camada de visăo e aplicar vários dos padrőes e estratégias que discutiremos a seguir.
Um dos principais objetivos que desejamos alcançar no desenvolvimento de nossas aplicaçőes é a clara divisăo de responsabilidades. No modelo MVC vimos que a camada de visăo (view) é responsável pela apresentaçăo dos dados. Quando lógica de negócio e lógica para formataçăo dos dados estăo inseridas nesta camada, o sistema torna-se menos flexível, reutilizável e suscetível ŕ mudanças. Isto também prejudica a clara separaçăo do trabalho de web designers e programadores.
Como vimos, todo o processamento da lógica de negócio deve estar centralizado na camada modelo do MVC. Isto implica que năo haverá scriptlets com regras de negócio em nenhuma parte das páginas JSP, que irăo somente apresentar o estado do modelo que chega encapsulado em helpers denominados value objects (que nada mais săo do que Java Beans que representam uma porçăo dos dados do modelo num dado instante). Procedendo desta forma, estaremos prezando pelo reaproveitamento de código e manutenibilidade, já que porçőes de códigos que fazem a mesma coisa foram retirados dos scriptlets e inseridos em classes Java que fazem parte do modelo.
Devemos evitar também a inclusăo de código para formataçăo dos dados nas páginas JSP, tais como código para controle de fluxo ou iteraçăo. Nesses casos a melhor opçăo é utilizar custom tag helpers, que encapsulam estas funcionalidades que, de outra forma, seriam embutidas diretamente no JSP como scripts, reduzindo a modularidade e manutenibilidade. Veja abaixo o trecho de código que mostra a apresentaçăo de dados de um empregado feita com e sem custom tags:
Agora a versăo usando custom tag:
A framework struts disponibiliza uma vasta biblioteca de tags que desempenham inúmeras funçőes que facilitam a inclusăo de lógica de formataçăo em páginas JSP.
Os dados que vęm do modelo săo expostos ŕ camada de visăo através de DTOs (Data Transfer Objects) que podem ser Value Objects. Um value object é um objeto Java arbitrário que encapsula os valores de retorno dos componentes de negócio, como por exemplo o retorno de um método de um DAO. Geralmente seus atributos săo feitos públicos e o construtor recebe cada um de seus valores. O nome das classes Java que representam value objects podem receber um “VO” para identificar que participam deste padrăo.
A maioria das aplicaçőes J2EE necessitam, num dado momento, acessar algum tipo de informaçăo persistente. Estas informaçőes podem estar nos mais diversos dispositivos de armazenamento, como servidores mainframes, repositórios LDAP (Lightweight Directory Access Protocol), banco de dados relacionais e orientado a objetos, ou mesmo dados provenientes de serviços disponibilizados por sistemas externos, como quando há integraçăo business-to-business (B2B).
Estes dispositivos săo acessados por diferentes APIs, muitas vezes proprietárias e específicas. Por exemplo, um banco de dados relacional pode ser acessado pela API JDBC. Esta API possibilita ŕs aplicaçőes emitir comandos SQL que săo a maneira padrăo para interaçăo com as tabelas contidas nestes bancos. Ainda assim, mesmo que estejamos considerando apenas o ambiente de sistemas gerenciadores de banco de dados relacionais (SGBD), a sintaxe dos comandos SQL pode variar dependendo do SGBD em particular.
Esta diversidade de fontes de dados pode criar uma dependęncia da aplicaçăo em relaçăo ao código de acesso aos dados, uma vez que os componentes de negócio conterăo código específico das APIs e dispositivos de armazenamento sendo utilizados. Isto introduz um alto acoplamento entre a lógica de negócio e a implementaçăo do acesso ŕs fontes de dados, tornando mais difícil migrar a aplicaçăo de uma fonte de dados para outra.
A soluçăo é abstrair e encapsular o acesso a fontes de dados através de Data Access Object (DAO). Um DAO implementa o mecanismo de acesso para se trabalhar com uma fonte de dados específica. Um componente de negócio fica exposto apenas ŕ interface do DAO, que esconde toda a complexidade relativa ŕ interaçăo com a fonte de dados sendo utilizada. Como a interface de um DAO năo se altera quando sua implementaçăo precisa ser modificada, este padrăo permite alterar a fonte de dados sendo utilizada numa aplicaçăo sem afetar os componentes de negócios que fazem uso deste.
Quando utilizamos DAO é comum utilizarmos também o padrăo Abstract Factory. Uma fábrica de objetos tem a funçăo de criar objetos de um determinado tipo e, quando uma existe, devemos utilizá-la para criar determinados objetos ao invés de fazę-lo explicitamente através do comando new. Pense no seguinte, uma vez que nossa aplicaçăo está cheia de DAOs, cada um com os métodos apropriados para acessar uma determinada fonte de dados, como fazer para substituir um DAO por outro quando a fonte de dados precisar ser alterada? Bom, uma alternativa é remover todas as classes que representam DAOs na aplicaçăo e substituí-las por classes com o mesmo nome (e é claro mesma interface) porém projetadas para acessar a nova fonte de dados. Uma opçăo mais profissional e flexível é criar uma classe abstrata que representa uma fábrica de DAOs. Nesta classe estarăo definidos os métodos para criaçăo de todos os DAOs que a aplicaçăo precisa. Quando o dispositivo de armazenamento persistente é passível de mudança, deve-se criar uma fábrica concreta de DAOs, derivada da classe abstrata, específica para cada fonte de dados a ser utilizada. Assim, é possível, por exemplo, definir uma variável global na aplicaçăo do tipo DAOFactory e inicializá-la com a fábrica concreta necessária num dado momento. Quando a fonte de dados precisar ser alterada, basta inicializarmos a variável com outra fábrica capaz de construir DAOs aptos a interagir com a nova fonte. Em qualquer parte da aplicaçăo onde um DAO está sendo criado, e isto certamente está sendo feito utilizando-se a variável global com a fábrica de DAOs corrente, nada precisará ser modificado. A figura 2.1 apresenta o diagrama de classes deste esquema.
A camada cliente pode interagir diretamente com os serviços disponibilizados pela camada responsável por implementar a lógica do negócio. Esta interaçăo direta expőe sobremaneira a API destes serviços de negócio, tornando a camada de apresentaçăo mais vulnerável ŕs mudanças efetuadas nos métodos de negócio. Dito isso, pode-se concluir que é desejável reduzir o acoplamento entre estas duas camadas, escondendo ao máximo detalhes de implementaçăo.
O padrăo para resolver este problema é o business delegate que age como uma abstraçăo, no lado cliente, para os métodos de negócio. Um business delegate pode esconder, por exemplo, a complexidade da busca por recursos como EJBs, numa aplicaçăo distribuída, ou data sources, que possibilitam obter conexőes a fontes de dados. Sua utilizaçăo torna transparente aos usuários dos serviços de negócio detalhes sobre serviços de nome e diretório e a busca nestas estruturas. Outro benefício é o tratamento das exceçőes que podem ser lançadas pelos serviços de negócio, o qual pode ser efetuado antes que uma delas chegue ŕ camada de apresentaçăo. Assim, caso realmente o problema ocorrido năo seja recuperável, uma mensagem mais amigável pode ser produzida e apresentada ao usuário.
Aplicaçőes J2EE distribuídas interagem com componentes como EJB e JMS os quais provęem variados serviços. Geralmente estes componentes precisam ser localizados através de mecanismos de busca em serviços de nome e diretório. Aplicaçőes năo distribuídas também precisam localizar recursos, tal como data sources afim de estabelecerem conexăo com dispositivos de armazenamento.
Para gravar, localizar e criar recursos de forma padronizada, as aplicaçőes J2EE utilizam as facilidades providas pela API JNDI (Java Naming and Directory Interface). Esta API possibilita mapear nome de componentes aos objetos que estes representam. Quando é preciso recuperar um componente, a aplicaçăo deve primeiramente obter um contexto inicial e entăo prover um nome JNDI previamente registrado para que a busca possa ser efetuada. Recursos precisam ser obtidos repetidamente desta maneira através de uma aplicaçăo, conseqüentemente fazendo com que o código JNDI apareça múltiplas vezes. Isto resulta numa desnecessária duplicaçăo de código e, como a criaçăo de um contexto inicial é dependente de fabricante, introduz também dificuldades de manutençăo.
A soluçăo é utilizar um objeto service locator que abstrai todas as chamadas JNDI e esconde as complexidades inerentes ŕ criaçăo de um contexto inicial e busca dos componentes. Este objeto pode ser utilizado em toda parte de uma aplicaçăo que precisa acessar um recurso gerenciado por JNDI, reduzindo a complexidade do código, provendo um ponto único de controle e, em determinados casos, melhorando a performance através de mecanismos de cache.
Uma única página web pode ser composta por múltiplas subvisőes, isto é, a página é dividida em porçőes, cada uma com um conteúdo específico. Por exemplo, uma página pode conter um cabeçalho, um rodapé, uma porçăo destinada ao menu e outra para apresentar o conteúdo do que foi escolhido num determinado momento. Algumas subvisőes, como o cabeçalho e rodapé, săo reaproveitadas em várias outras visőes. Se páginas com estas características săo construídas acrescentando-se o conteúdo de cada porçăo diretamente na página, a aplicaçăo será mais propícia a erros, devido ŕ duplicaçăo de código, e mudanças de layout serăo bem mais difíceis de serem executadas.
A soluçăo para isso é utilizar composite views, ou seja, visőes compostas de múltiplas subvisőes atômicas. Cada componente independente pode ser incluído dinamicamente e o layout da página passa a ser mais facilmente gerenciável independentemente do conteúdo. Esta abordagem promove a reutilizaçăo de porçőes atômicas da visăo e facilita em muito a alteraçăo do layout.
Uma das formas mais simples de se implementar composite views é através de tags JSP, como a açăo ou a diretiva <\%@include file="localURL"\%>. A utilizaçăo destas tags para gerenciamento do layout e composiçăo das visőes é bastante simples de implementar. Porém, esta estratégia năo provę a mesma flexibilidade da abordagem com custom tags, pois o layout de cada página permanece embutido dentro da própria página. Ou seja, apesar das tags possibilitarem a inclusăo dinâmica de conteúdo e conseqüentemente o reaproveitamento de porçőes comuns a várias páginas, a estruturaçăo do layout (a divisăo da página em tabelas ou frames por exemplo e o posicionamento de cada porçăo atômica dentro desta divisăo) continua contida em cada página.
Existem duas possibilidades para inclusăo dinâmica de conteúdo - a inclusăo em tempo de compilaçăo ou em tempo de execuçăo. A primeira é obtida usando-se a diretiva <\%@include file="localURL"\%> e a última através da açăo . Os pontos positivos e negativos de cada uma destas abordagens săo discutidos a seguir:
A implementaçăo do padrăo composite view através de custom tags possibilita uma flexibilidade superior. Contudo, requer maior esforço de programaçăo e gerenciamento, tendo em vista os inúmeros artefatos que precisam ser criados e configurados no ambiente de execuçăo.
A framework Tiles, que pode ser utilizada em conjunto com Struts, é uma implementaçăo de composite view que faz uso de custom tags e provę toda a flexibilidade de reaproveitamento e gerenciamento de layout que o padrăo propicia. Com Tiles, além do reuso das “partes” é possível também definir um padrăo para a disposiçăo destas nas páginas, ou seja, definir o layout que as organizam. Basicamente, define-se uma template com o layout padrăo que um conjunto de páginas terá. Este molde representa um esqueleto HTML e especifica onde serăo inseridas as partes menores. O código abaixo define uma template JSP para a tela de abertura de um portal:
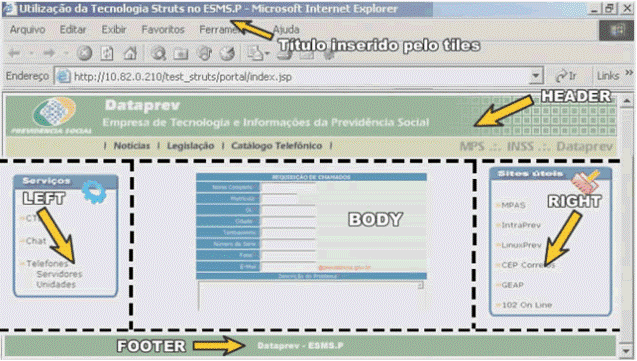
A Figura 2.2 mostra o layout padrăo gerado pela template. Supondo que o arquivo com a template chama-se layoutAbertura.jsp, é preciso agora criar uma definiçăo para cada página na aplicaçăo que será construída seguindo o molde padrăo. Nesta definiçăo estará especificado o que irá conter cada porçăo variável, ou seja, o que cada página deve apresentar. O código abaixo é um exemplo de definiçăo.
Pode-se verificar que para quase todas as porçőes foram especificadas as visőes apropriadas. No entanto, para a porçăo body nada foi definido. Isto por que esta é uma definiçăo padrăo para várias telas da aplicaçăo. Ou seja, năo existirá uma página criada a partir dela, mas sim de alguma outra que derive da definiçăo padrăo. As porçőes comuns a todas as páginas já foram definidas e apenas a variável foi deixada em branco. Assim, quando for preciso criar uma página específica, pode-se fazer como abaixo:
E criar uma nova definiçăo que estenda da primeira e defina o que deve conter o corpo. Por fim, basta criar a página que irá materializar esta definiçăo:
Perceba que se for preciso alterar o layout básico das páginas na aplicaçăo é suficiente que se altere apenas o arquivo layoutAbertura.jsp que todas as páginas automaticamente passarăo a respeitá-lo.

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.