pace=0 src="/loja/img/capa_java49_G.gif" border=0>
ft-com:office:office" />
Implemente recursos completos de pesquisa te
Nos últimos anos, os sites de busca se tornaram onipresentes em nossas vidas, ajudando-nos a lidar com o volume avassalador de informaçőes da web. Essa tecnologia de recuperaçăo de informaçőes tem ganhado espaço também no mundo corporativo, e existem hoje no mercado soluçőes em software (ex.: Ultraseek, Google Search Services) e em hardware (ex.: Google Mini e Google Search Appliance), que se propőem a pesquisar páginas em intranets e arquivos em diversos formatos.
Para o desenvolvedor Java, existe uma alternativa open source que năo deixa nada a dever a essas soluçőes proprietárias: o Apache Lucene, uma biblioteca de pesquisa textual extremamente poderosa incorporada como projeto da Apache Software Foundation em 2001.
Diversos projetos utilizam o Lucene. Exemplos săo o mecanismo de busca web Nutch (um subprojeto do Lucene), o sistema de geręncia de conteúdo Open- CMS, o IDE Eclipse (em seu help online) e o Hibernate Search. Veja nos links uma referęncia para a lista completa de projetos “Powered by Lucene”.
Neste artigo, veremos os conceitos básicos do Apache Lucene e como utilizá-lo através de uma aplicaçăo de exemplo.
Lucene numa casca de noz
A pesquisa textual, como sabemos, consiste em localizar documentos que contęm uma determinada palavra ou frase. O termo “documento” é usado neste artigo de maneira ampla, referindo-se a páginas
HTML, arquivos em vários formatos, enfim, a qualquer objeto que possua texto e seja relevante para o usuário.
Um dos conceitos centrais da pesquisa textual é a indexaçăo. De maneira simplificada, indexar é processar os documentos e colocar as suas palavras em estruturas de dados que possam ser pesquisadas rapidamente: os índices. Os índices de pesquisa textual quase sempre săo listas invertidas, em que cada palavra é uma chave que aponta os documentos nos quais ocorre. A Figura 1 ilustra esse conceito.
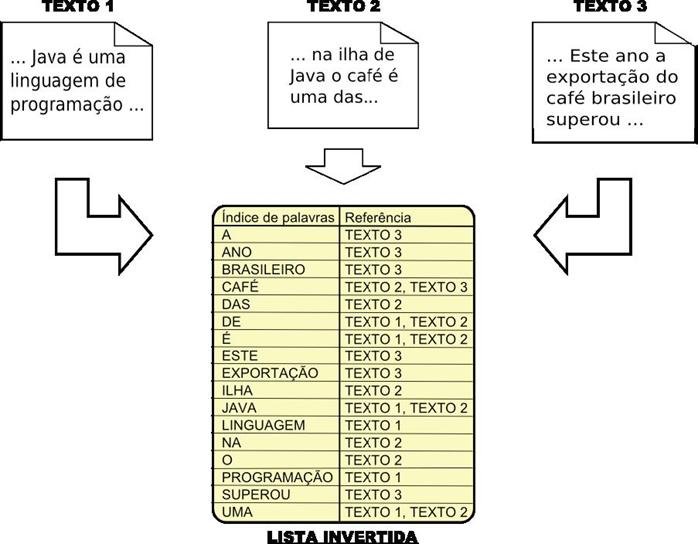
Figura 1. Esquema simplificado de uma lista invertida.
No Lucene, o índice é composto por duas estruturas lógicas principais: documentos e campos (fields). Cada entrada no índice corresponde a um documento (org.apache. lucene.document.Document) e cada documento possui um conjunto de campos (org.apache. lucene.document.Field). Fazendo uma analogia com um banco de dados relacional, os documentos seriam como linhas numa tabela e os campos seriam semelhantes ŕs colunas. Em outras palavras, para cada objeto que podemos pesquisar (um documento) existem diversos atributos pelos quais podemos pesquisar (campos).
Um aspecto importante da pesquisa textual é que normalmente estamos interessados apenas no conteúdo dos documentos e năo na sua formataçăo ou estrutura de arquivo específica. Por exemplo, se tivermos um conjunto de livros sobre Java em formato PDF, năo estaremos preocupados com os dados de controle e de formataçăo contidos nos arquivos, mas com os textos em si. Por isso é preciso extrair o texto de interesse antes de indexá-lo. (O Lucene năo inclui ferramentas para fazer a extraçăo de texto. Cabe ŕ aplicaçăo fazer isso antes de usar o Lucene.)
Analisando um pouco mais, veremos que mesmo o conteúdo textual de cada documento năo é inteiramente relevante. Por exemplo, palavras muito comuns como “de”, “a” e “o” năo precisam ser indexadas, pois ocorrem em praticamente 100% dos documentos em língua portuguesa. Além disso, algumas características da pesquisa, por exemplo discriminar maiúsculas e minúsculas e considerar caracteres acentuados, exigem o tratamento do texto antes da indexaçăo. Este processo é chamado análise e é realizado após a extraçăo do texto. No Lucene, a análise é feita pelas implementaçőes da classe abstrata org. apache.lucene.analysis.Analyzer.
O Lucene fornece uma implementaçăo default bastante razoável para a classe Analyzer, o StandardAnalyzer. Entretanto, para textos em língua portuguesa recomen- damos usar uma implementaçăo específica. Criamos para este artigo a classe PortuguesAnalyzer, que contém uma lista de palavras comuns da nossa língua e pode ser configurada para diferenciar ou năo caracteres acentuados (veremos adiante este analisador em uso). Temos assim uma visăo em passos do processo de indexaçăo:
1. Acessar os documentos originais e extrair o texto relevante para o usuário. 2. Processar o texto (análise). 3. Indexar.
Veja na Figura 2 uma visăo esquemática desse processo e onde o Lucene se insere nele.
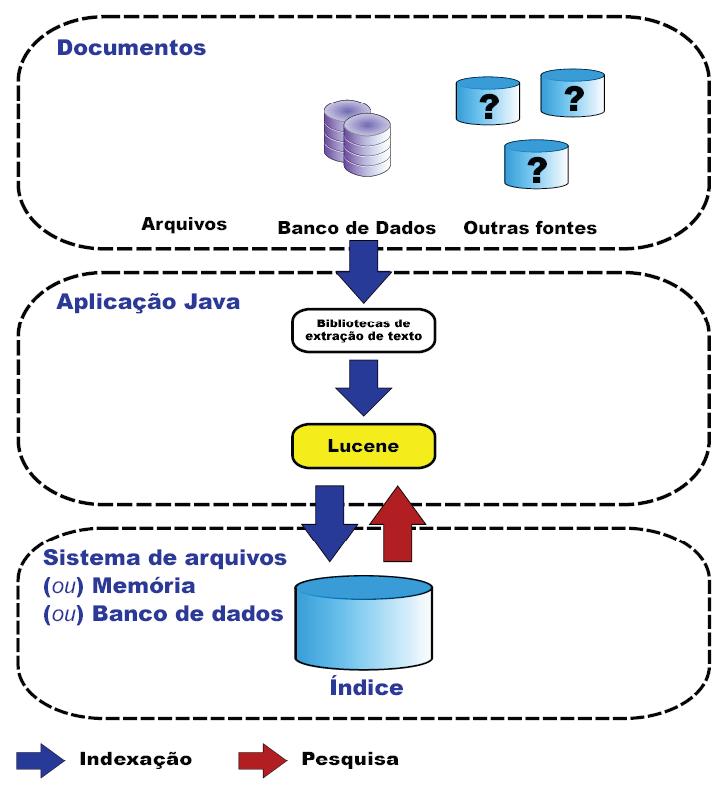
Figura 2. Visăo esquemática de uma aplicaçăo Java usando o Lucene.
Aplicaçăo de exemplo: pesquisa textual no desktop
Vamos agora demonstrar na prática alguns dos conceitos apresentados, através de uma aplicaçăo de exemplo que permite realizar a pesquisa em arquivos de forma interativa. A aplicaçăo gráfica que criamos ilustra o uso básico do Lucene, sendo capaz de indexar arquivos nos formatos mais utilizados: MS Office (Word, Excel e PowerPoint), PDF, RTF, HTML e XML.
Sobre a extraçăo
...







