Motivaçăo
Mecanismos de busca săo encontrados com frequęncia em sites e aplicativos mobile que trabalham com grandes quantidades de dados, como blogs e catálogos de músicas, filmes, etc. Por meio desse recurso a aplicaçăo permite ao usuário localizar o conteúdo desejado de forma simples: inserindo alguns termos chave para a busca (partes do título, da categoria, etc.), que lhes retornará uma lista de resultados que atendem ŕquele critério.
Implementar esse tipo de funcionalidade, no entanto, pode se mostrar uma tarefa complexa, dependendo da quantidade e do formato dos dados tratados. Para auxiliar no atendimento a esse requisito, algumas ferramentas, como o Apache Lucene, oferecem poderosos algoritmos de busca textual e os expőem na forma de bibliotecas ou APIs. Com esse tipo de soluçăo a aplicaçăo deixa de ser responsável pela parte mais complexa da busca e passa apenas a consumir os resultados.
Neste artigo veremos como implementar um serviço de pesquisa desse tipo, utilizando o Azure Search para consultar dados armazenados no Azure DocumentDB, ambas soluçőes otimizadas para lidar com grandes volumes e formatos de dados na nuvem.
Contextualizando: Azure Search e DocumentDB
O Azure Search é um mecanismo de busca ofertado na plataforma de cloud computing da Microsoft que pode ser integrado ŕ sua aplicaçăo na forma de um serviço, ou seja, vocę consumirá dele apenas o necessário e quando precisar. Com esse tipo de recurso, toda a camada de infraestrutura fica a cargo do provedor de serviço (o Microsoft Azure, neste caso), e a aplicaçăo cliente (a que desenvolveremos) apenas enviará as requisiçőes e receberá os resultados esperados.
Para efetuar as consultas o Azure Search naturalmente precisa que lhe seja fornecida uma fonte de dados, que pode ser um banco relacional, como o SQL Server, ou mesmo soluçőes NoSQL. Caberá a nós prover os dados que serăo utilizados para a consulta; neste caso, optamos por um banco NoSQL.
Nesse ponto entra o Azure DocumentDB, um sistema de banco de dados NoSQL orientado a documentos que, semelhante ao MongoDB, utiliza o formato JSON para armazenar os dados. Nesse tipo de armazenamento temos coleçőes (comparáveis ŕs tabelas em bancos relacionais) que contęm documentos (semelhantes ŕs linhas das tabelas), que, por sua vez, contęm todas as informaçőes referentes a um determinado objeto, como clientes, produtos, vendas, etc.
Por se tratarem de serviços baseados na nuvem, tanto o Azure Search quanto o DocumentDB săo otimizados para trabalhar com grandes volumes e tráfego de informaçőes. Ademais, devido ŕ facilidade de alterar a infraestrutura dedicada a uma aplicaçăo, esse modelo computacional também é ideal para lidar com picos de demanda, pois permite alocar os recursos que precisarmos apenas durante o período em que forem necessários.
Criando o banco de dados
Caso vocę já possua uma base de dados no Azure DocumentDB, poderá utilizá-la como fonte de dados para o serviço de pesquisa que desenvolveremos. Aqui, no entanto, criaremos uma nova base para testes.
O primeiro passo para isso é criar uma nova conta do DocumentDB a partir do Portal do Azure, clicando em New > Data + Storage > DocumentDB. Na guia que será aberta, basta indicar um nome no campo ID, selecionar sua assinatura, o grupo de recursos no qual o banco será alocado e a sua localizaçăo (datacenter).
Quando o deploy da DocumentDB Account for concluído, acesse-a e clique em Add Database. Neste momento, informe um nome para esse banco de dados no campo ID e clique em OK. Com isso, o novo banco aparecerá na lista de Databases. Clique, entăo, sobre ele e no topo da janela clique em Add collection, para criar uma nova coleçăo de documentos. Agora, informe novamente um nome no campo ID e clique em OK. Ao fim desse processo a coleçăo aparecerá na lista Collections, e clicando sobre ela poderemos adicionar os documentos.
Para criar novos registros, clique em Document Explorer. Nessa janela teremos duas opçőes: adicionar manualmente um documento, clicando em Create, ou fazer o upload de arquivos JSON contendo os documentos. Na Listagem 1 temos um exemplo de documento que será utilizado nesse artigo para testes. Nesse caso, trabalharemos com uma coleçăo de álbuns musicais, que poderiam ser utilizados em uma loja online de música.
{
"id": "386",
"albumTitle": "For Those About To Rock We Salute You",
"albumUrl": "/content/images/ForThoseAboutToRockWeSaluteYou.jpg",
"genre": "Rock",
"genreDescription": "Rock and Roll is a form of rock music developed in the 1950s and 1960s. Rock music combines many kinds of music from the United States, such as country music, folk music, church music, work songs, blues and jazz.",
"artistName": "AC/DC",
"orderableOnline": true,
"tags": ["AC/DC", "Rock"],
"price": 6.21,
"margin": 10,
"rating": 2,
"inventory": 869,
"lastUpdated": "2012-12-03T02:42:17Z"
}
Após inserir alguns documentos, nossa base de dados estará pronta para ser consultada.
Criando o serviço de busca
Para criar um novo serviço de busca, acesse, no portal do Azure, o menu New > Data + Storage > Azure Search. Na guia que será aberta, basta informar a URL do serviço e preencher os demais campos como na DocumentDB Account.
Após alguns instantes o depoly do serviço será concluído. Quando isso acontecer, devemos acessá-lo e no topo da guia clicar em Import data, para adicionar os dados a serem consultados. Na próxima guia, devemos clicar em Connect to your data e selecionar DocumentDB, que será nossa fonte de dados. Em seguida, em New data source será necessário preencher o nome do data source, clicar em Select an account e selecionar a conta recém-criada. Logo, os campos Database e Collection serăo habilitados, restando apenas selecionar o banco de dados e a coleçăo que foi criada e clicar em OK.
O próximo passo será configurar um índice de busca, que reunirá as regras a partir das quais esses dados serăo consultados. Deste modo, clique em Customize target index na guia Import data e, em seguida, informe um nome para o índice e qual atributo do documento será a chave dessa coleçăo (geralmente um ID).
Na sequęncia, nessa mesma guia, precisaremos definir algumas características para cada atributo dos documentos em questăo, como mostra a Figura 1.
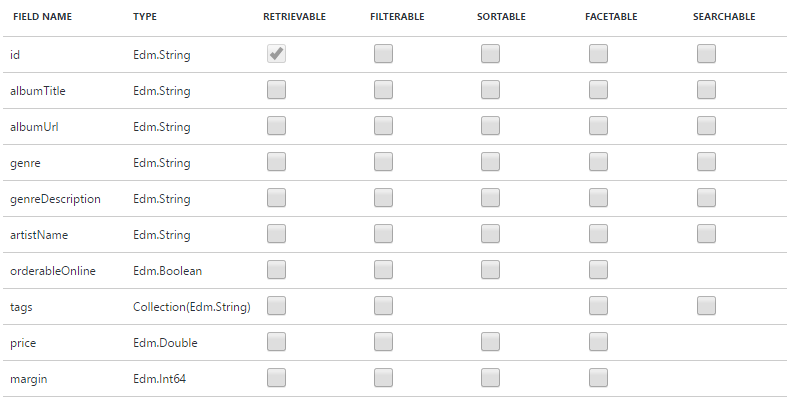
Figura 1. Atributos de busca do documento
Nessa parte serăo listados os atributos dos documentos, e precisaremos marcar (ou manter desmarcadas) os checkboxes que indicam se eles săo:
- Retrievable: o campo será retornado na busca. Em alguns casos, para tornar os resultados mais leves (já que trafegarăo via web), é interessante desmarcar campos secundários e que năo serăo utilizados na tela em que os resultados serăo exibidos;
- Filterable: será possível fazer filtros sobre esse campo nas consultas;
- Sortable: será permitido ordenar os resultados por esse campo;
- Facetable: os resultados poderăo ser categorizados ou agrupados por esse campo. No caso dos álbuns de música, por exemplo, poderíamos agrupá-los por categoria, preço, tags, etc.;
- Searchable: o campo poderá ser usado como alvo de filtros para a consulta.
Sabendo disso, configure seu índice de acordo com a estrutura dos seus documentos. Nesse exemplo a configuraçăo deve ser feita conforme a Figura 2, com apenas alguns campos sendo retornados pela pesquisa.

Figura 2. Configuraçőes do índice
Nosso próximo passo será criar um indexador, objeto responsável por importar os dados do banco configurado para o serviço de busca, mantendo-os indexados e prontos para consulta. Esse processo pode ser configurado para executar periodicamente, mas nesse momento precisaremos apenas que ele rode uma única vez. Para isso, na guia Import data, clique em Indexer, defina um nome para ele e clique em OK, mantendo os demais campos com os valores iniciais. Por fim, clique em OK novamente na guia anterior para finalizar a configuraçăo.
Realizando consultas
Com o serviço configurado e os dados prontos para serem consultados, podemos testar nossa estrutura de busca. Para isso, na guia inicial do serviço de busca, clique em Search explorer, mantenha o campo Query string em branco e pressione o botăo Search. Isso executará uma busca sem filtros, que deve retornar todos os registros, apenas com os campos que selecionamos anteriormente, como podemos confirmar na Figura 3.
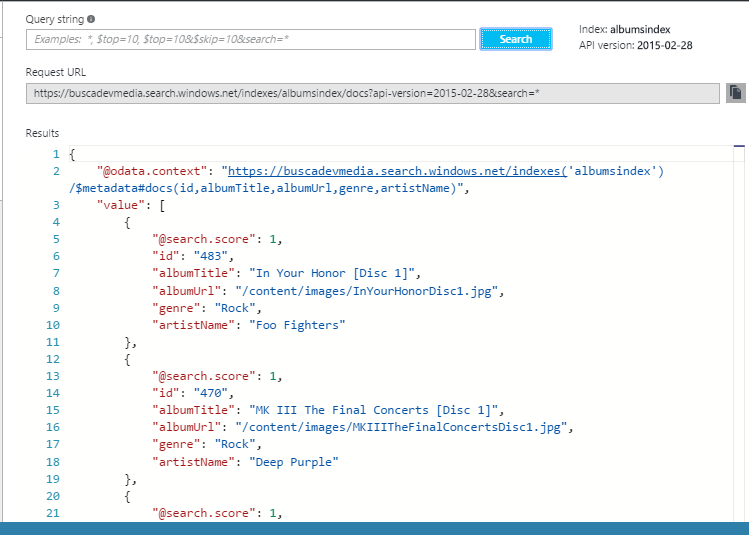
Figura 3. Registros retornados pela busca
A guia Search explorer nos permite efetuar consultas diversas e analisar seu resultado. Na prática, no entanto, esse serviço de busca será consumido por meio de uma API RESTful cujo endereço podemos ver na figura acima, no campo Request URL. Esse endereço pode ser utilizado nas aplicaçőes que adotarăo o serviço de busca, passando os argumentos já presentes nesse exemplo e no cabeçalho da requisiçăo, uma chave que autorizará o acesso ao serviço.
Para obter uma chave de acesso, devemos voltar ŕ guia principal do Search service, clicar em All settings e depois em Keys. Na nova guia, poderemos obter as chaves de administrador, ou criar novas.
De posse dessas informaçőes, o teste inicial do serviço pode ser feito por meio de algum utilitário capaz de enviar requisiçőes HTTP (ou diretamente na aplicaçăo cliente). Aqui utilizaremos o Postman, extensăo do navegador Google Chrome que oferece essa e outras funcionalidades. Nele, devemos inserir o endereço da API, adicionar um campo com a chave no headers da requisiçăo, que deve ser do tipo GET, e pressionar o botăo Send. O resultado da consulta será exibido logo abaixo, como mostra a Figura 4.
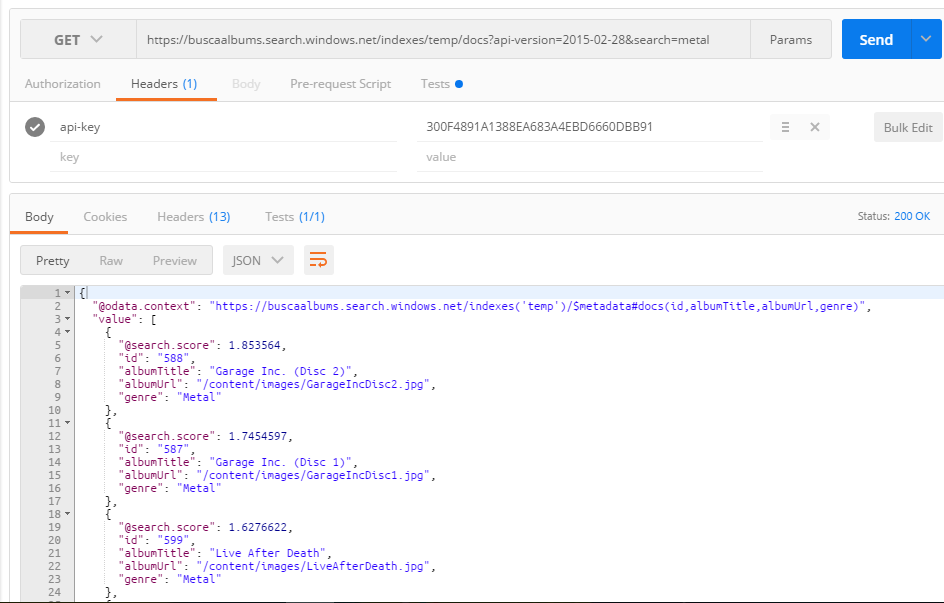
Figura 4. Requisiçăo ao serviço de busca feito no Postman
A partir do retorno do serviço podemos, por exemplo, exibir uma lista para o usuário com links para páginas de detalhes que exibam fotos e outras informaçőes adicionais. Ou seja, ŕ aplicaçăo cliente caberá utilizar esses dados da forma mais adequada para o usuário, livrando-se da responsabilidade de processar todo o algoritmo de busca, que foi executado na nuvem.







